- Paxosとは何か、そしてOceanBaseがデータを失わない理由
分散システムにあまりなじみがないと、「Paxos」という言葉は少しとっつきにくく感じるかもしれません。まずは、これを「みんなで1つの結論を決めるためのルール」と捉えるとイメージしやすくなります。
たとえば、ある重要な判断を複数人で決める場面を考えてみましょう。参加者の中には、返事が遅れる人もいれば、途中で連絡が取れなくなる人、誤った情報を出してしまう人がいるかもしれません。それでもシステム全体としては、あとから覆らない唯一の決定を下さなければなりません。これが、分散システムにおける「分散合意」の基本的な課題です。
Paxos は、この分散合意を実現する代表的なアルゴリズムです。考え方の中心にあるのはとてもシンプルで、多数派の同意を得た結果だけを正しい決定として扱う、というものです。
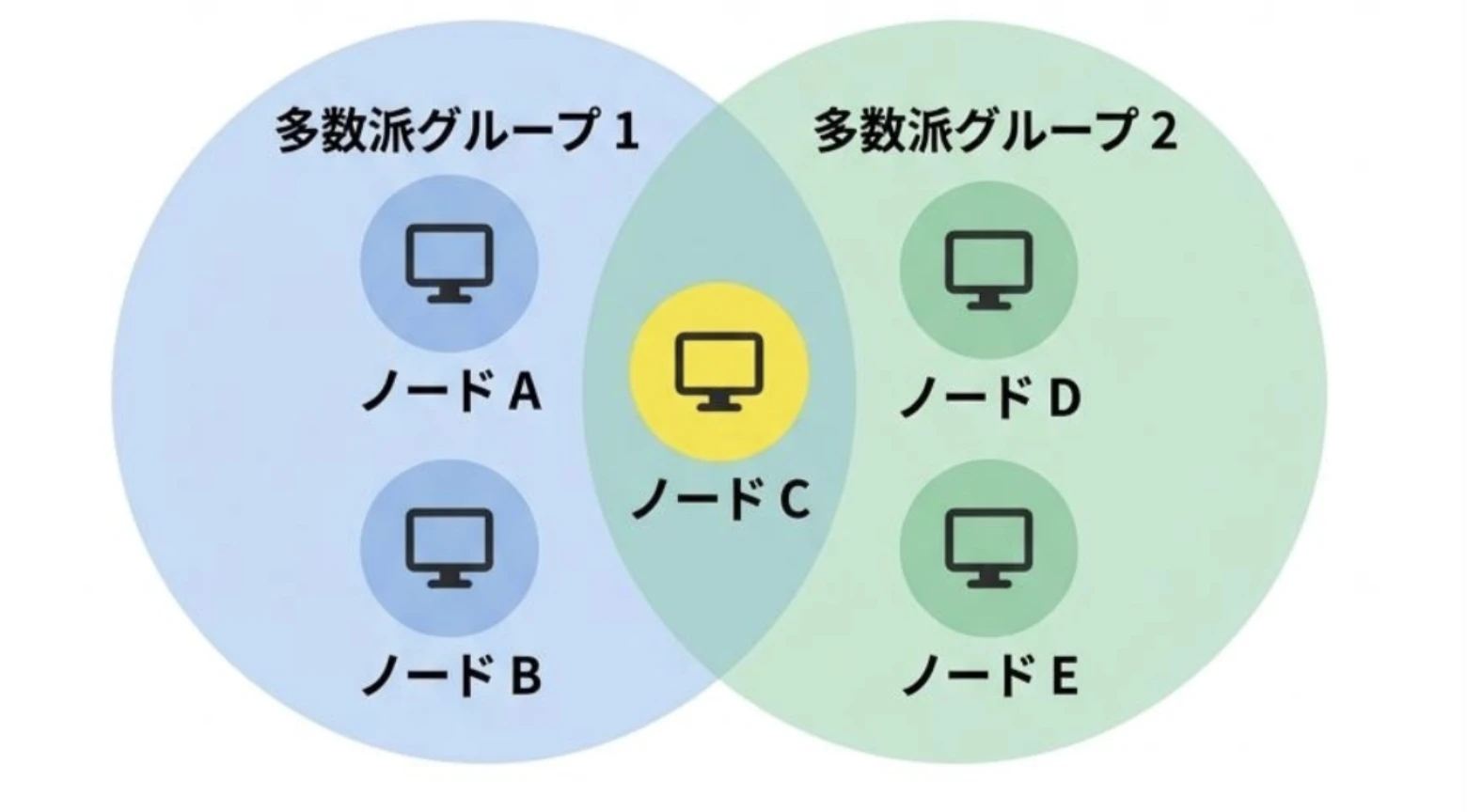
では、なぜ「多数派」である必要があるのでしょうか。ポイントは、任意の2つの多数派グループは、必ず少なくとも1つの共通メンバーを持つことです。これによって、「こちらのグループはAを正しいと判断し、あちらのグループはBを正しいと判断する」といった食い違いを構造的に起こしにくくできます。
この性質は、ネットワーク通信分断のような障害時に特に重要です。もし多数派の制約がなければ、分断されたそれぞれの側で「自分こそ Leader だ」と判断し、両方が同時に書き込みを受け付けてしまう可能性があります。いわゆるスプリットブレインです。Paxos による多数派ベースの合意は、こうした不整合を防ぐための土台になっています。
OceanBase は、この仕組みをデータの永続化に応用しています。データベース内のデータは、複数の「レプリカ」として保持されます。そして更新が発生してコミットログが生成されたときも、単にそのノードだけに書き込んで完了とはしません。多数派のレプリカにログが永続化されたことを確認して初めて、クライアントに「コミット成功」を返します。
たとえ1台のディスクが故障したり、あるノードが停止したりしても、多数派が生きている限り、データはすでに複数ノードに書き込まれています。つまり、単一ノードの障害でデータが失われることはありません。OceanBase が災害時でもデータ損失を防げる、いわゆる RPO=0 を目指せるのは、このためです。特定の高性能な1台に頼るのではなく、多数派による合意を前提に、クラスタ全体で信頼性を担保するのが基本設計になっています。
同期の単位は「ログストリーム」
ここで押さえておきたいのは、レプリカ間で「何を」同期しているのかです。OceanBase では、個々のデータ更新(トランザクション)ごとに毎回投票しているわけではありません。合意プロトコルが動作する単位は、ログストリーム(Log Stream) です。
ログストリームは、複数のデータパーティションに対する変更を、順序付けられた 1 本のログとしてまとめて扱う論理的な単位です。細かな変更をバラバラに同期するのではなく、ある程度まとまりのあるログの流れとして管理する仕組みです。
この設計のメリットは明確です。複数の変更をまとめて 1 回の Multi-Paxos(Paxosを実運用向けに最適化した方式)で同期できるため、変更のたびに細かく合意を取る場合に比べて、ネットワーク往復回数や通信コストを大きく抑えられます。その結果、整合性を維持しながら、システム全体の処理効率も高められるわけです。
OceanBaseアーキテクチャ構成
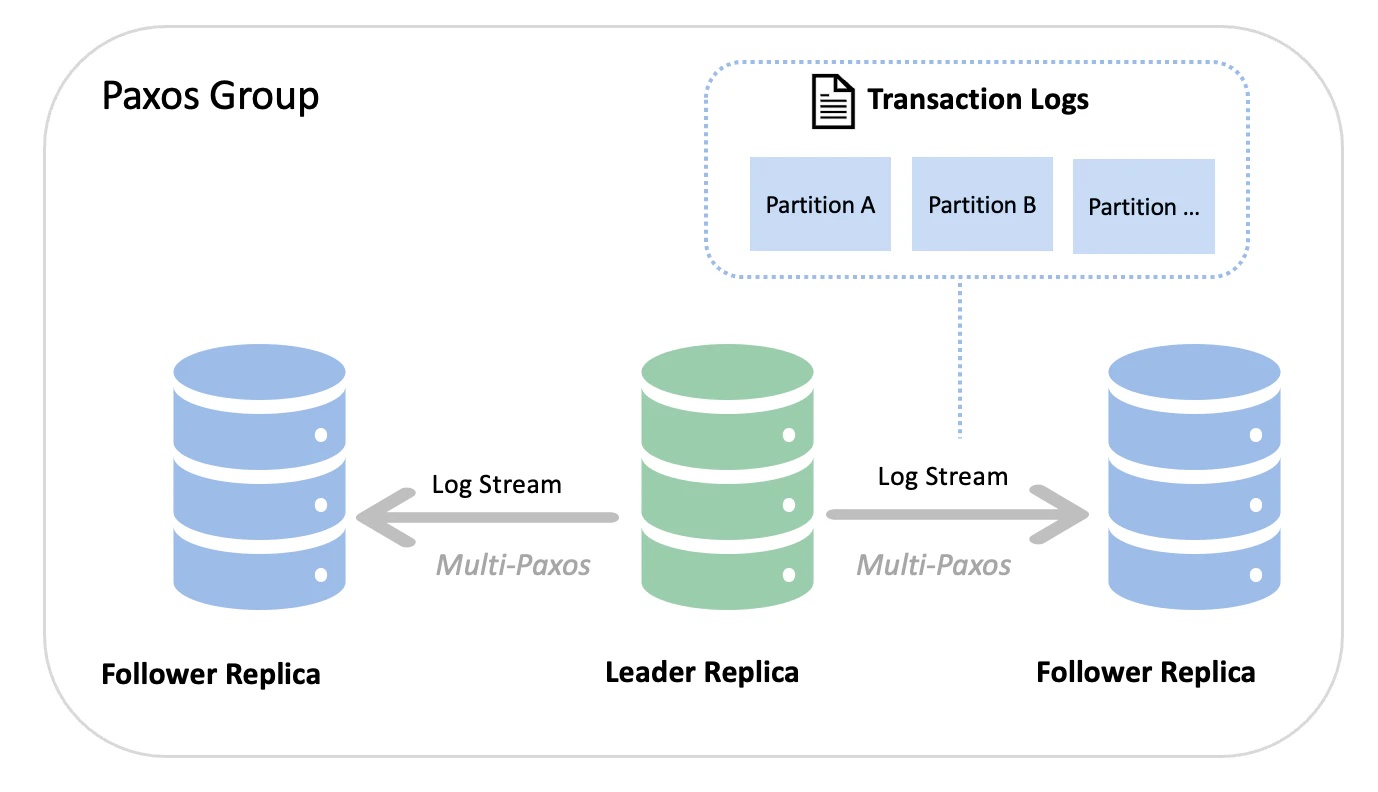
OceanBase は複数のアベイラビリティゾーンにまたがってレプリカを配置する構成を取ります。そして、それぞれのログストリームごとに、1つの Leader レプリカと複数の Follower レプリカが存在します。
書き込み要求を受け付けるのは Leader です。Leader は受け取った更新内容をログとしてまとめ、Follower に同期していきます。つまり、ログストリームごとに、Leader が同期の起点となり、レプリカ間の整合性を維持する役割を担っていることになります。
このログ同期には、Multi-Paxos ベースのプロトコルが使われています。通常の Paxos では、合意形成のためにログごとに複数フェーズの通信が必要になりますが、Leader が安定している状態では、そのやり取りを簡略化できます。OceanBase ではこの性質を活用し、本来は「2 往復」必要になる通信を実質「1 往復」に近い形まで最適化しています。その結果、多数派への確実な永続化という安全性を維持しながら、同時に高い書き込み性能も実現しています。
2.従来の完全同期レプリケーションや Raftとの違い
従来の完全同期レプリケーションとの違い
従来のプライマリ・セカンダリ構成では、データ保護のために「完全同期レプリケーション」がよく使われます。これは、プライマリが更新ログを書き込んだあと、セカンダリ側でそのログが確実に永続化されたことを確認してから、クライアントに成功を返す方式です。
この方式の利点は、仕組みがシンプルであり、プライマリに障害が発生してもセカンダリ側に常に最新のデータが保持されていることです。単純な構成でデータ保護の考え方を実現しやすいため、従来の高可用性構成では広く採用されてきました。ただし、その代償として弱点もあります。プライマリ、セカンダリ、あるいはその間のネットワークのどこか1か所でも不調になると、書き込みは停止するか、著しく遅くなります。データの信頼性を優先するあまり、サービスの可用性が犠牲になりやすい設計といえます。
これに対して、Multi-Paxos を用いた多レプリカ構成では、通常 3 台や 5 台のレプリカを前提に、多数派(過半数)が生存し、相互に通信できる限り、書き込みと合意形成を継続できます。 たとえば3台構成であれば、1台が故障しても残る2台で多数派を維持できるため、データ損失ゼロ(RPO=0)とサービス継続(高可用性)を高いレベルで両立できるのが大きな強みです。
Raft との違い
同じく多数派合意アルゴリズムとしてよく知られている Raft との違いも見ておきます。Paxos 系と Raft は、どちらも多数派で合意を取るという点では共通しています。ただし、設計思想には違いがあります。
Raft は、ログの連続性を強く重視するアルゴリズムです。各ノードでログインデックスや term(世代番号)の整合性を保ちながら、コミットを順序よく進めていくため、Leader 選出やログ同期の流れが比較的分かりやすくなっています。結果として、実装しやすく、挙動も理解しやすいのが大きな特徴です。
一方の Multi-Paxos は、ログに欠番、いわゆる歯抜けが生じることを許容しつつ、各ログを個別に確認・確定していくことができます。この柔軟性は、障害時や復旧時の挙動に強みをもたらしますが、そのぶん内部のロジックは複雑になります。たとえば Leader が切り替わる場面では、新しい Leader が未コミットのログを再確認し、必要に応じて学習・整理しながら整合性を回復していく必要があります。
OceanBase が Multi-Paxos を採用し、さらに実運用向けに最適化しているのは、この柔軟性が実環境の物理配置と相性がよいからです。たとえば「同一都市に 2 拠点、さらに遠隔地に 1 拠点」といったディザスタリカバリ(DR)構成では、常に全拠点を同じ重みで扱うより、低遅延な近距離拠点を優先しながら多数派を形成したほうが、性能と信頼性のバランスを取りやすい場面があります。
ざっくりまとめると、こうなります。Raft は整った形で扱いやすいアルゴリズムであり、OceanBase の Multi-Paxos は、より複雑なディザスタリカバリ構成の中で、性能と信頼性を高いレベルで両立させるための選択だと言えるでしょう。
3.OceanBase は Paxos をどう最適化したか?高パフォーマンスの源泉
分散合意アルゴリズムには、正しく動くことだけでなく、十分に速く動くことも求められます。どれだけ整合性を保てても、書き込みのたびに大きな遅延が発生していては、実用的なデータベースにはなりません。
OceanBase は、クラシック Paxos をそのまま使うのではなく、複数の実装レイヤーで最適化を加えています。これにより、高い可用性を維持しながら、実運用に耐える書き込み性能を実現しています。
安定時のログ同期を「1 ラウンドの RPC」に短縮
クラシック Paxos では、1 つのログを書き込むたびに Prepare と Accept という 2 段階の通信が必要です。つまり、ログごとに 2 ラウンドの RPC が発生し、これが遅延の原因になります。一方、OceanBase の Multi-Paxos では、Leader が安定して選出されたあとの通常時の書き込みを 1 ラウンドで処理できます。Leader が各 Follower にログを送り、多数派での永続化が完了した時点でコミットと見なす仕組みです。そのため、平常時の書き込み遅延は、基本的に 1 往復のネットワーク通信 + 多数派でのディスク書き込み に近い形まで抑えられます。
ログの確認とコミットを順不同で処理できる
前述の通り、OceanBaseの Multi-Paxos は「前のログが確定しないと、後続のログも確定できない」という連続性の制約に縛られません。
実際の運用環境では、瞬間的なネットワークの揺らぎやパケットロスは珍しくありません。順不同処理が可能な Multi-Paxos であれば、一部のログがパケットロス等で一時的に欠落しても、届いている後続のログを先に処理してコミットを進めることができます。これにより、一部の通信遅延がシステム全体のボトルネックになりにくく、ネットワーク品質が多少ぶれても性能が落ちない高い安定性を実現しています。
軽量な「アービトレーション・レプリカ」を使える
可用性を高めるためにレプリカ数を増やすと、インフラコストは重くなりがちです。そこで OceanBase では、アービトレーション・レプリカ(Arbitration Replica)という軽量な仕組みを活用できます。
このレプリカは、Leader 選出やログ同期の「投票」には参加しますが、業務データそのものは保持しません。そのため大容量ストレージが不要で、通常のデータレプリカよりもはるかに軽い構成で運用できます。
これにより、データ通信やストレージコストを抑えつつ、多数派形成を満たすことができます。たとえば「メインの2拠点にフルデータのレプリカを置き、第3の拠点にはこの軽量レプリカを置く」といったDR構成を組むことで、拠点間の通信コストを抑えながら高い可用性を確保できるため、実運用上で非常に大きなメリットになります。
4.高可用アーキテクチャを支えるその他の機能
データベースの高可用性は、ログ同期や多数派合意のアルゴリズムだけで完結するものではありません。OceanBase では、障害検知からアプリの接続経路の制御、復旧処理まで、アーキテクチャ全体が連携して高可用性を支えています。
Leader 障害時の自動フェイルオーバーとスプリットブレイン防止
OceanBaseでは、Leader選出に「リース(Lease:期限付きの権利)」の概念を導入しています。
これにより、ネットワーク分断等で旧Leaderが孤立して生き残っていたとしても、同じタイミングで複数のLeaderが存在してしまう(スプリットブレイン)状態を構造的に防いでいます。多数派は古いリースが切れるのを待ってから新Leaderを選出するため、データ不整合を起こすことなく数秒以内(RTO < 8秒)で安全にサービスを再開できます。
障害の影響を局所化する「ログストリーム単位」の切り替え
従来のデータベースでは「DBインスタンス単位」でフェイルオーバーを行うため、1台の障害でDB全体が切り替わる大きな影響が出がちでした。
一方、 OceanBase では、より細かい「ログストリーム単位」で同期とLeader選挙を行います。ある物理サーバーがダウンしても、影響を受けるのは「そのサーバーがLeaderを担当していた一部のデータ」のみ。その他のデータは稼働を続けられるため、障害の影響範囲を最小限に抑え、切り替え時間も秒単位まで短縮されています。
アプリケーション側は切り替えを意識しなくてよい
高可用性を実現できても、アプリケーション側で毎回接続先を切り替える必要があるようでは、運用負荷は大きくなります。
OceanBase では、アプリケーションは通常、バックエンドのデータベースノード(OBServer)に直接接続するのではなく、専用のルーティングプロキシである OBProxy を経由します。OBProxy はデータの分散状況や Leader の場所を把握しており、クエリを適切なノードに転送します。Leader の切り替えが発生した際も、OBProxy が新 Leader を自動で検知して経路を更新するため、アプリケーション側は設定変更や再起動をすることなく、透過的にデータベースへアクセスし続けることができます。
障害後の自己修復も全自動
OceanBase の障害対応は、フェイルオーバーして終わりではありません。その後の復旧処理も自律的に進みます。
クラスタ全体を管理する「Root Service」自体もMulti-Paxosのマルチレプリカ構成によって高可用化されており、各ノードは定期的にハートビートを送信して状態を報告しています。長時間応答しないノードは異常と判断され、Multi-Paxosのメンバーグループから切り離されます。そのうえで、失われたレプリカを他の健全なノードへ自動的に補充・再配置し、「常に多数派が完全な状態」を保つように自己修復を行います。単なるサーバー故障からデータセンターレベルの障害まで、「切り替えた後に、人手を介さず自律的に元の健全な状態へ戻す」ところまで一貫して設計されているのが OceanBase の強みです。
5.おわりに
OceanBase の高可用性設計を見ていくと、Paxos の多数派合意は単なる理論ではなく、「データを守りながら、できるだけサービスも止めない」ための実装原理として使われていることが分かります。
従来のプライマリ・セカンダリ型の同期レプリケーションでは、一部ノードやネットワークの不調が、そのまま全体の書き込み停止につながりやすいという課題がありました。これに対して OceanBase は、Multi-Paxos をベースにした合意形成によって、少数ノードの障害や一時的なネットワークの揺らぎがあっても、処理を継続しやすい構成を取っています。
さらに注目すべきは、Multi-Paxos による合意形成だけでなく、ログストリーム単位の切り替えや OBProxy、セルフヒーリングといった周辺の仕組みまで含めて、高可用性が設計されている点です。分散データベースの可用性は、単一のアルゴリズムだけで決まるものではなく、こうした全体設計の積み重ねで成り立っていることがよく分かります。
マルチAZ やマルチリージョンを前提にしたシステムでは、遅延と可用性、そして災害耐性のバランスをどう取るかが常に課題になります。その意味で、OceanBase の実装は、Paxos 系アルゴリズムを実サービスに適用したひとつのアーキテクチャ例として、読者の皆様の参考となれば幸いです。