はじめに
Orbiticsデータサイエンス部の渡邉です!
- RAGチャットボットを構築する上で、LLM(大規模言語モデル)に与えるデータをいかに理解しやすい形式で整えるかは、チャットボットが実務に使えるものかを決定づける非常に重要な要素です。
- 本記事では、私たちOrbiticsがRAGチャットボットを開発する中で得られた、非構造データの「構造化」に関する知見を共有します。
背景
RAGチャットボットの開発
Orbiticsでは、社内リソースの活用を促進するため、様々な社内ドキュメントをデータソースとしたRAGチャットボットを開発・運用しています。
一例として、ANAグループのデータに関するテーブル定義情報をデータソースとして与えたRAGチャットボットがあります。
これにより、分析時に必要なデータがDB内のどのスキーマ・テーブルにあるかを、膨大なテーブル定義書の中から、チャットで簡単に調査できるようになりました。
RAGチャットボットの品質評価
RAGチャットボット開発後の導入において、信頼できる回答をユーザーに提供することは最重要課題です。そこで、Orbiticsではチャットボット開発時に品質評価を実施することで、信頼性を担保しました。
チャットボットの品質評価については「RAG品質評価の具体的な方法の実践」で弊社の石原が紹介しています!本記事と合わせてRAGチャットボットの開発の一助となりましたら幸いです。
品質評価に合格するためのデータ加工の重要性
データソースは、Excel(.xlsx)ファイルやPowerPoint(.pptx)ファイルといった非構造データのドキュメントが多くを占めます。
xlsxファイルやpptxファイルといった非構造データのデータソースをLLMに直接与える場合、内部のテキスト情報が単に上から読み込まれている場合が多く、人間が目で見て得られる「表やスライドの構造」がそのままLLMに伝わっているとは限りません。
品質評価を合格するべく試行錯誤していく中でデータ加工の有無は評価の合否に大きく寄与しました。
RAGチャットボット開発で活用したデータ加工例
RAGの品質評価に合格するためには、単にテキストを抽出するだけでなく、情報が持つ意味や構造を損なわない形でテキスト化することが重要です。
1. 表形式データ(Excel/CSV)の加工
Excelファイルのように表形式で情報が整理されているデータは、そのままテキストに変換すると情報の対応関係が崩れやすいです。
例えば、以下のような簡易的なテーブル定義書の例で考えます。
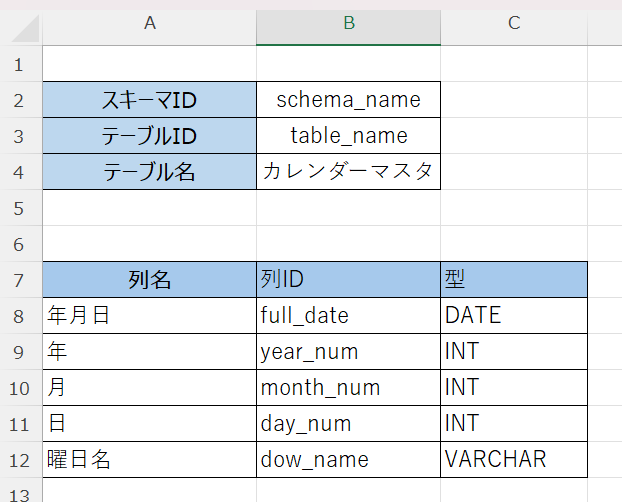
課題
単純なテキスト抽出では、各セルの情報を左上から順に読み込む形になり、ヘッダー情報とデータ行の紐づきが分かりにくくなることがあります。
以下は、各セルの情報を左上から順にテキスト抽出しつなげた例です。
スキーマIDschemanameテーブルIDtablenameテーブル名カレンダーマスタ列名列ID型年月日full_dateDATE年year_numINT月month_numINT日day_numINT曜日名dow_nameVARCHAR
これでは、full_date が 列ID なのか 型 なのかを判別することが難しく、チャットボットへの質問に対して参考資料として取得できても品質評価に合格する回答を生成できないことが多いです。
解決策
json形式に変換し、ヘッダーとデータの対応関係を明確にします。カラム名やデータ型定義内容をLLMが理解しやすいようにKey-Value形式で表現します。
これにより、RAGチャットボットが特定のカラムに関する質問を受けた際に、対応する定義内容をヘッダー情報とともに取得できるようになります。
テーブルが持つ情報について以下の通りに変換することで、どのセルの値が何を表すかを明確に表現できるようになりました。
弊社でのRAGチャットボット構築時では、同じフォーマットのテーブル定義書ファイルを一括で変換するため、変換用のスクリプトでテーブル定義書のExcelファイルからjsonファイルへの変換を実施しました。
{
"スキーマID": "schema_name",
"テーブルID": "table_name",
"テーブル名": "カレンダーマスタ",
"列ID": {
"full_date": {
"列名":"年月日",
"型":"DATE"
},
"year_num": {
"列名":"年",
"型":"INT"
},
"month_num": {
"列名":"月",
"型":"INT"
},
"day_num": {
"列名":"日",
"型":"INT"
},
"dow_name": {
"列名":"曜日名",
"型":"VARCHAR"
}
}
}
2. スライドデータ(PowerPoint)の加工
PowerPointファイルは、スライドタイトル、見出し、箇条書き、図表の説明といった階層的な構造を持っています。
例えば、以下のような、テーブル説明資料の例で考えます。
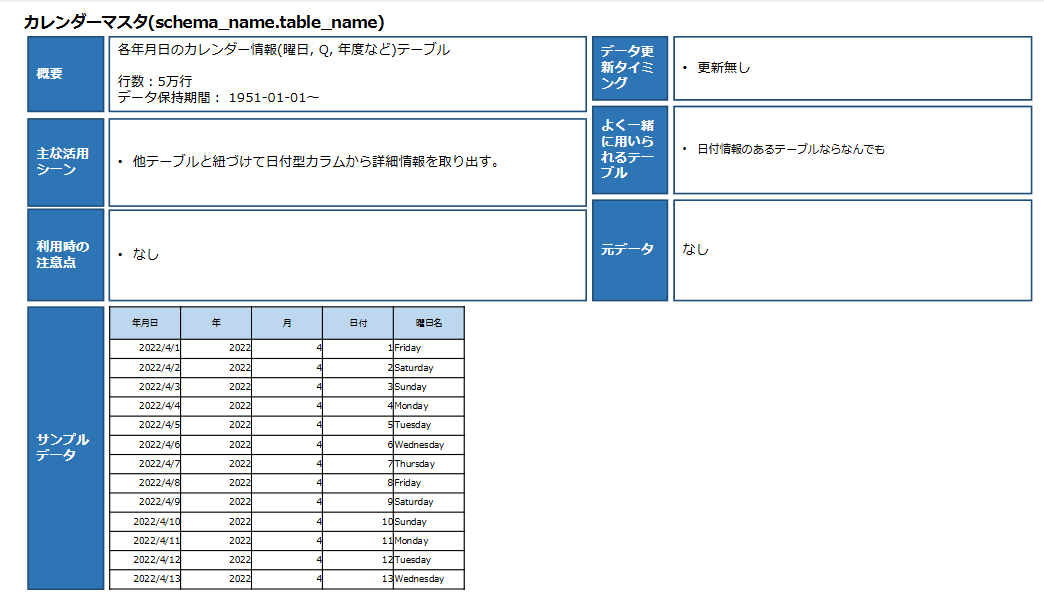
課題
単純なテキスト抽出では、各テキストボックスの情報を左上から順に読み込む形になり各項目の切れ目が分かりにくくなることがあります。
以下は、各テキストボックスの情報を左上から順にテキスト抽出しつなげた例です。
カレンダーマスタ(schema_name.table_name)概要各年月日のカレンダー情報(曜日,Q,年度など)テーブル行数:5万行データ保持期間:1951-01-01~データ更新タイミング・更新なしよく一緒に用いられるテーブル・日付情報のあるテーブルならなんでも主な活用シーン・他テーブルと紐づけて日付型カラムから詳細情報を取り出す。元データ・なし利用時の注意点・なしサンプルデータ...
これでは、項目間の切れ目を判別することが難しく、チャットボットへの質問に対して参考資料として取得できても品質評価に合格する回答を生成できないことが多いです。
解決策
スライド単位で情報を抽出し、テキストボックス間の位置関係をもとに各項目の情報をKey-Value形式で表現します。これにより、RAGチャットボットが特定のテーブルに関する質問を受けた際に、対応する情報がどの項目のものかとともに取得できるようになります。
テーブルが持つ情報について以下の通りに変換することで、どのテキストボックスの値が何を表すかを明確に表現できるようになりました。
弊社でのRAGチャットボット構築時では、同じフォーマットのテーブル説明書ファイルを一括で変換するため、変換用のスクリプトでテーブル定義書のPowerPointファイルからjsonファイルへの変換を実施しました。
{
"スキーマID": "schema_name",
"テーブルID": "table_name",
"テーブル名": "カレンダーマスタ",
"概要": "各年月日のカレンダー情報テーブル 行数:5万行 データ保持期間: 1951-01-01~",
"主な活用シーン": "他テーブルと紐づけて日付型から詳細情報を取り出す。",
"利用時の注意点": "なし",
"データ更新タイミング": "更新なし",
"よく一緒に紐づけられるデータ": "日付情報のあるテーブルならなんでも",
"元データ": "なし"
}
まとめ
RAGチャットボットの回答は、基盤となるLLMの性能だけでなく、LLMに与えるデータの質に大きく依存します。非構造データを扱う際は、単なるテキスト抽出ではなく、情報が持つ「構造」や「意味の対応関係」を考慮した前処理(データ加工)が品質評価を合格する上での鍵となります。本記事がRAGチャットボット開発時の参考となれば幸いです。