はじめに
この記事は LLM Advent Calendar 2025 の23日目の記事です。
VRMキャラクターが3D空間を自由に歩き回り、出会ったエージェント同士で会話し、その内容を記憶として蓄積していくシステムを作りました。
スタンフォード大学の「Generative Agents」論文で提唱された記憶アーキテクチャを参考に、Unity + FastAPI + LLMの3層構成で自律エージェントシステムを実装しています。本記事では、アーキテクチャ設計と記憶システムの実装について解説します。
本プロジェクトで使用しているUnity Assetsのライセンス制約により、ソースコードの公開は行っていません。本記事では実装のアプローチと設計思想を共有し、同様のシステムを構築する際の参考にしていただければ幸いです。
開発環境
| 項目 | スペック |
|---|---|
| OS | Windows 11 |
| CPU | AMD Ryzen 5 5600 |
| RAM | 32GB |
| GPU | NVIDIA GeForce RTX 3080 Ti(12GB VRAM) |
ミドルハイ程度のゲーミングPC環境です。
私はこのPCしかまともなのがないので、ローカルLLMを動かすには、「12GB VRAMでどこまでできるか」がポイントになりました。
開発の流れ
本プロジェクトの開発は、LLMプロバイダーの選定で少しだけ紆余曲折がありました。
Phase 1: OpenAI APIで基本機能を開発
最初はOpenAI API(GPT-5.1)を使って開発を進めました。
-
メリット
セットアップが簡単、JSON構造化出力が安定、応答品質が高い -
デメリット
APIコストがかかる、オフラインで動かない
エージェント同士が頻繁に会話するシステムでは、API呼び出しコストが気になります。
また、今回の用途では、@sald_raさんが主催した「ローカルAIに向き合う展示会」に出展するのも兼ねていたので、ローカルLLMを使用しました。
Phase 2: vLLM + Qwenへの挑戦と挫折
次に試したのが、vLLMサーバー上でQwen2.5-7B-Instructを動かす構成です。
しかし3080 Ti(12GB VRAM)ではスペックがギリギリでした。
- モデルロードはできるが、VRAMギリギリ
- GPTQ量子化版でも、xgrammarのguided decodingを有効にするとVRAMが不足
- 使いたいレベルの量子化が対応していない
- Unityを動かしたいので、VRAMにもっと余裕が欲しい
vLLMは高速で並列処理が可能ですが、ある程度のVRAMが必要です。24GB以上のGPU(RTX 4090、A100など)が推奨されますが、今回はあくまで展示用かつ何百体とAIを動かしたいわけではないのでオーバーエンジニアリングだと思いvLLMは却下。
Phase 3: Ollamaとgemma-3n-e4b
最終的に落ち着いたのが、Ollama + gemma-3n-e4b の構成です。
gemma-3n-e4bを選んだ理由
-
軽量で動く
12GB VRAMで余裕を持って動作(実測7-8GB程度) -
日本語が親しみやすい
自然な日本語で会話を生成してくれる -
性能が良い
軽量モデルながら、会話の文脈理解や感情表現が的確
また、上記プロバイダーを切り替え可能にしておいたことで、環境に合わせてLLMを切り替えられる柔軟な構成になりました。
推論速度に関しては、後述にもあるのですが、json形式で出力させておおよそ3~5秒程度でした。
システムアーキテクチャ
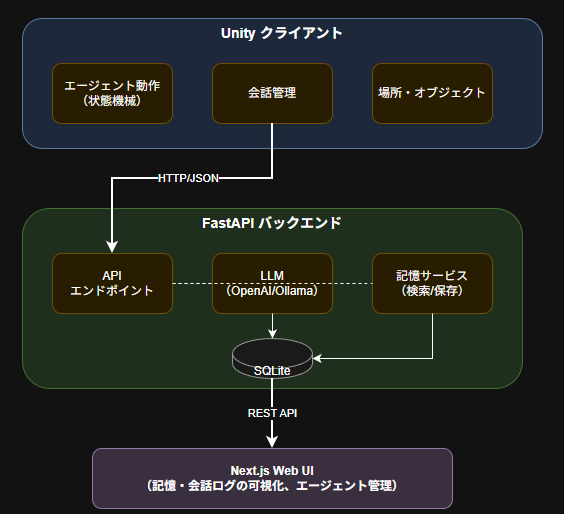
本題のアーキテクチャについてですが、上記図がわかりやすいかと思います。
Unityクライアントがエージェントの状態管理と3D空間での移動を担当し、FastAPIバックエンドが記憶システムとLLM連携を処理する、責務の分離が明確なアーキテクチャです。
アーキテクチャの設計思想
このシステムは 3層分離アーキテクチャ を採用しています。
レイヤー1: Unityクライアント(表現層)
- エージェントの3D移動・アニメーション
- 状態機械による行動制御
- 会話トリガーの判定(距離・視野角)
レイヤー2: FastAPIバックエンド(ビジネスロジック層)
- 記憶システムの管理(スコアリング・検索)
- LLMとの通信
- プロバイダー抽象化
レイヤー3: LLM(推論層)
- OpenAI API / Ollama / vLLM
- 環境変数で切り替え可能
なぜこの設計にしたのか
- 関心の分離: Unity側はグラフィックスに集中、記憶処理はバックエンドで
- スケーラビリティ: 将来的に複数Unityクライアントから同一バックエンドへの接続も可能
- デバッグ性: FastAPIのログで記憶検索の挙動を確認しやすい
- LLM切り替え: 本番はOpenAI、開発はローカルLLMなど柔軟に対応
当初は「Unity単体でLLM呼び出し」も検討しましたが、
記憶システムのロジックが複雑になることと、
Pythonエコシステム(LangChain、FastAPI等)の恩恵を受けられないため却下しました。
Unity側の主な使用技術
- 通信: UniTask + UnityWebRequest(FastAPIへの非同期リクエスト)
- VRM: UniVRM 1.0(キャラクターの表示・操作)
- JSON: Newtonsoft.Json(LLMレスポンスのパース)
- Pathfinding: NavMesh(PoIへの移動制御)
上記にある通り、モデルはVRMモデルを使用しUniVRMでUnity上に取り込んでいます。
また、AIキャラクターの移動に関しては、NavMeshを使用することで自動で経路計算をしてくれるので、行くべき座標を指定するだけで自ずと移動してくれます。
エージェントの行動と会話
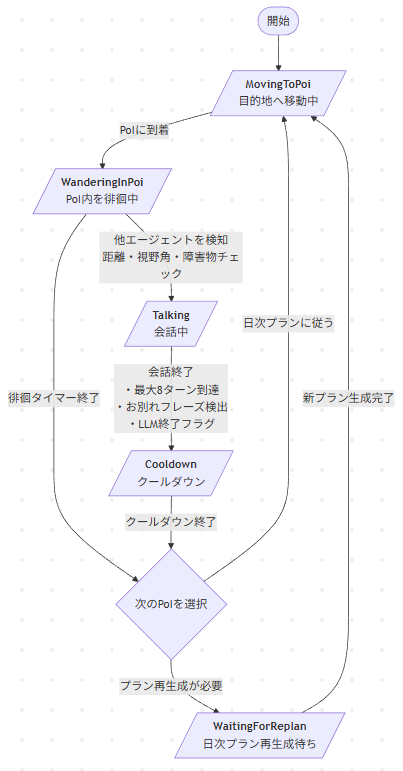
エージェントのフローチャートはこの画像の通りです。
状態機械
エージェントは5つの状態を持って動作します。
- MovingToPoi: 目的地(PoI)へ移動中
- WanderingInPoi: PoI内を徘徊中
- Talking: 会話中
- Cooldown: 会話後のクールダウン
- WaitingForReplan: 日次プラン再生成待ち
PoI(Point of Interest)は「レストラン」「公園」などの場所を表し、エージェントは日次プランに従って移動します。
会話のトリガーと終了
会話は「距離」「視野角」「障害物の有無」をチェックして開始されます。
終了条件は3つのOR条件で判定
- 最大8ターンに到達
- お別れフレーズを検出(「またね」「じゃあね」など)
- LLMが終了フラグを返す
LLMが終了フラグを返し忘れた場合でも、会話が暴走しない設計になっています。
会話の構造
{
"agent_id": "Aoi",
"target_id": "Hikari",
"session_id": "abc123",
"location_name": "中央カフェ",
"history": [
"Hikari: 今日は天気がいいね",
"Aoi: うん、散歩日和だね"
],
"time_of_day": 14.5
}
LLMの応答はJSON Schemaで構造化
{
"dialogue": "そうだね、散歩したくなるよね",
"emotion": "happy",
"is_conversation_end": false
}
記憶アーキテクチャ
Generative Agents論文の記憶システムを参考に実装しました。これがこのプロジェクトのコア部分です。
今回は開発速度を考慮して簡易的にキーワードマッチを採用しましたが、語彙のゆらぎに対応するためベクトル検索もありかと思います。
記憶の種類
| タイプ | 説明 | 例 |
|---|---|---|
observation |
具体的な出来事 | 「カフェでHikariと会話した」 |
reflection |
会話からの振り返り | 「Hikariとの会話は楽しかった」 |
plan |
日次の行動計画 | 「午前中は図書館で勉強する」 |
記憶検索のスコアリング
記憶の検索では、3つの指標を重み付けして最終スコアを算出します。
$$score = \alpha \cdot recency + \beta \cdot importance + \gamma \cdot relevance$$
Recency(新近性)
def compute_recency_score(timestamp, now):
minutes = (now - timestamp).total_seconds() / 60
return 0.99 ** minutes # 1分ごとに1%減衰
古い記憶ほどスコアが低くなり、新しい記憶が優先されます。
Importance(重要度)
LLMが生成時に付与した1-10のスコアを正規化。会話終了時に「この会話の重要度を1-10で評価してください」とプロンプトしています。
Relevance(関連性)
現在のコンテキストとの関連度。本実装ではシンプルなキーワードオーバーラップを使用していますが、本格的な実装は埋め込みベクトルのコサイン類似度を使うべきです。
Reflection(振り返り)の生成
会話終了時、会話内容から振り返りを生成して保存します。
会話ログ → LLM → 1段落の要約 + 重要度(1-10)
これが次回以降の会話でコンテキストとして参照されます。
Generative Agents論文では観察の蓄積から複数の高レベル洞察を生成しますが、本実装は会話単位での単純な要約生成に簡略化しています。
実装のポイント
JSON Schemaによる構造化出力
LLMの応答を安定させるため、JSON Schemaを指定して構造化出力を強制しています。
CHAT_RESPONSE_SCHEMA = {
"type": "object",
"properties": {
"dialogue": {"type": "string"},
"emotion": {"type": "string"},
"is_conversation_end": {"type": "boolean"},
},
"required": ["dialogue", "emotion", "is_conversation_end"],
}
OpenAIのresponse_formatやOllamaのformatオプションでこのスキーマを適用し、パース失敗を防いでいます。
LLMプロバイダーの抽象化
環境変数LLM_PROVIDERで切り替え可能な設計にしました。
# OpenAI API
LLM_PROVIDER=openai
OPENAI_API_KEY=sk-xxx
# Ollama(12GB VRAM環境向け)
LLM_PROVIDER=ollama
OLLAMA_MODEL=hf.co/unsloth/gemma-3n-E4B-it-GGUF:Q4_K_M
プロバイダーごとにクラスを分け、共通インターフェースで呼び出せるようにしています。
まとめ
得られた知見
1. LLMプロバイダー選定:環境に合わせた柔軟性が重要
| プロバイダー | メリット | デメリット | 向いている用途 |
|---|---|---|---|
| OpenAI API | セットアップ簡単、品質安定 | コスト、オフライン不可 | プロトタイプ、本番 |
| vLLM | 高速、guided decoding対応 | VRAM要求高(24GB+推奨) | ハイスペック環境 |
| Ollama | 軽量、セットアップ簡単 | 速度はvLLMに劣る | ミドルスペック環境 |
プロバイダーを抽象化しておくことで、環境や用途に応じて切り替えられます。最初から複数対応を想定した設計が有効でした。
2. 記憶スコアリング:シンプルな重み付けで十分機能する
$$score = \alpha \cdot recency + \beta \cdot importance + \gamma \cdot relevance$$
- 複雑なアルゴリズムより、チューニングしやすいシンプルな式が実用的
- Recencyの指数減衰(
0.99 ** minutes)は直感的で調整しやすい - Relevanceは埋め込みベクトルが理想だが、キーワードマッチでも動作する
3. JSON Schemaによる構造化出力は必須
LLMの応答を安定させるために構造化出力は必須でした。
- 問題: 自由形式だとパース失敗、フィールド欠落が頻発
- 解決: JSON Schemaで型と必須フィールドを強制
- 効果: パースエラーがほぼゼロに
4. 会話終了条件:複数条件のOR設計で暴走を防止
LLMだけに終了判断を任せると、会話が終わらないケースがあります。
| 終了条件 | 役割 |
|---|---|
| 最大ターン数(8ターン) | 絶対的な上限 |
| お別れフレーズ検出 | 自然な終了をキャッチ |
| LLM終了フラグ | LLMの意図を反映 |
LLMの出力に依存しすぎないフェイルセーフ設計が重要です。
5. 3層アーキテクチャの利点
Unity・Backend・WebUIを分離したことで得られた恩恵:
- 独立したテスト: BackendだけでLLM応答を検証できる
- デバッグ容易: WebUIで記憶状態をリアルタイム確認
- 技術選定の自由: 各層で最適な技術を選択可能
6. 12GB VRAMでのローカルLLM運用
RTX 3080 Ti(12GB)での実測値:
| 構成 | VRAM使用量 | 結果 |
|---|---|---|
| vLLM + Qwen 7B GPTQ | 11-12GB | ギリギリ、Unity併用困難 |
| Ollama + gemma-3n-e4b | 7-8GB | 余裕あり、Unity併用可能 |
VRAMは「動く」だけでなく「余裕を持って動く」が重要。他アプリとの併用を考慮すべきです。
今後の拡張可能性
- 感情システム: 感情状態を追跡し、会話トーンに反映
- 埋め込み検索: Relevance計算をベクトル類似度に置き換え
- スケールアウト: より多くのエージェントの同時シミュレーション
質問やフィードバックがあれば、記事のコメント欄でお知らせください。