ガウス過程と機械学習
書籍「ガウス過程と機械学習」(持橋大地/大羽成征・著)の各章の公式などをまとめます。
途中式はかなり省略しているため、詳細は書籍を参照してください。
1章 線形回帰モデル
単回帰
N個の観測値のペア $Data={(x_1, y_1), .. , (x_N, y_N)}$ に対して、
$\hat{y}=a+bx$ によって観測モデルを考えることを単回帰という。
$E=\sum_{n=1}^N{(y_n - \hat{y}_n)^2}$ を最小にする $a, b$ は、
\begin{pmatrix}
N & \sum_n{x_n} \\
\sum_n{x_n} & \sum_n{x_n^2}
\end{pmatrix}
\begin{pmatrix}
a \\
b
\end{pmatrix}
=
\begin{pmatrix}
\sum_n{y_n} \\
\sum_n{x_n y_n}
\end{pmatrix}
を満たす。
重回帰
N個の観測値のペア $Data={(\boldsymbol{x_1}, y_1), .. , (\boldsymbol{x_N}, y_N)}$ ($\boldsymbol{x_k} = (1, x_{k1}, ..., x_{kD})^T$ )に対して、
$\hat{y}=w_0 + w_1x_1 + ... +w_Dx_D = \boldsymbol{x} \cdot \boldsymbol{w}$ によって観測モデルを考えることを重回帰という。
\boldsymbol{\hat{y}} = \begin{pmatrix}\boldsymbol{x_1} \cdot \boldsymbol{w} \\\vdots \\\boldsymbol{x_N} \cdot \boldsymbol{w}\end{pmatrix} \\X = \begin{pmatrix}\boldsymbol{x_1}^T \\\vdots \\\boldsymbol{x_N}^T \\\end{pmatrix}
とすると
\boldsymbol{\hat{y}} = X \boldsymbol{w}
と書ける。
$E = ||\boldsymbol{y} - \boldsymbol{\hat{y}}||^2$ ($\boldsymbol{y} = (y_{1}, ..., y_{D})^T$ )を最小にする $\boldsymbol{w}$ は、次のようになる。
\boldsymbol{w} = (X^T X)^{-1} X^T\boldsymbol{y}
線形回帰
N個の観測値のペア $Data={(\boldsymbol{x_1}, y_1), .. , (\boldsymbol{x_N}, y_N)}$ に対して、
$\hat{y}=w_0 + w_1 \phi_1(\boldsymbol{x}) + ... +w_D \phi_D(\boldsymbol{x}) = \boldsymbol{\phi}(\boldsymbol{x}) \cdot \boldsymbol{w}$ によって観測モデルを考えることを線形回帰という。
\boldsymbol{\hat{y}} = \begin{pmatrix}\boldsymbol{\phi}(\boldsymbol{x_1}) \cdot \boldsymbol{w} \\\vdots \\\boldsymbol{\phi}(\boldsymbol{x_N}) \cdot \boldsymbol{w}\end{pmatrix} \\\Phi = \begin{pmatrix}\boldsymbol{\phi}(\boldsymbol{x_1})^T \\\vdots \\\boldsymbol{\phi}(\boldsymbol{x_N})^T \\\end{pmatrix}
とすると
\boldsymbol{\hat{y}} = \Phi \boldsymbol{w}
と書ける。
$E = ||\boldsymbol{y} - \boldsymbol{\hat{y}}||^2$ ($\boldsymbol{y} = (y_{1}, ..., y_{D})^T$ )を最小にする $\boldsymbol{w}$ は、次のようになる。
\boldsymbol{w} = (\Phi^T \Phi)^{-1} \Phi^T\boldsymbol{y} \cdots (*1.1)
リッジ回帰
線形回帰の(*1.1)は $\Phi^T \Phi$ が逆行列を持つときにしか適用できない。
また、 $\Phi^T \Phi$ の行列式が 0 に近いとき、$\boldsymbol{w}$ のノルムが大きくなる($\boldsymbol{x}$ の値に敏感になる)。
これらを回避するために正則化をする。
すなわち、$E = ||\boldsymbol{y} - \boldsymbol{\hat{y}}||^2 + \alpha ||\boldsymbol{w}||^2$ を最小にする $\boldsymbol{w}$ を求める。このとき $\boldsymbol{w}$ は次のようになる。
\boldsymbol{w} = (\Phi^T \Phi + \alpha I)^{-1} \Phi^T\boldsymbol{y}
2章 ガウス分布
ガウス分布
$$
N(x|\mu, \sigma^2) = \frac{1}{\sqrt{2\pi}\sigma}exp(-\frac{(x - \mu)^2}{2\sigma^2})
$$
ガウス分布と線形回帰
線形回帰にノイズが乗ったモデル
$$
y = \boldsymbol{w} \cdot \boldsymbol{x} + \epsilon \
p(\epsilon) = N(0, \sigma^2)
$$
を考える。二式を合わせると
$$
p(y) = N(\boldsymbol{w} \cdot \boldsymbol{x}, \sigma^2)
$$
と書ける。
つまり、$y$ の確率密度関数は、
$$
p(y|\boldsymbol{x}) = \frac{1}{\sqrt{2\pi}\sigma}exp(-\frac{(y - \boldsymbol{w} \cdot \boldsymbol{x})^2}{2\sigma^2})
$$
となる。
$Data = {(X, \boldsymbol{y})}$ に対して、$p(\boldsymbol{y}| X) = \prod_{n}{p(y_n| \boldsymbol{x}_n)}$ より、
「$p(\boldsymbol{y}| X)$ を最大化する」 ⇔ 「$||\boldsymbol{y} - X \boldsymbol{w}||^2$ を最小化する」 (途中式略)
となるため、
「ガウス分布を誤差に含めた確率モデル」=「2乗誤差による線形回帰」
ということがわかる。
ガウス分布とリッジ回帰
線形回帰にノイズが乗り、かつ重みの事前分布をガウス分布としたモデル
$$
y = \boldsymbol{w} \cdot \boldsymbol{x} + \epsilon \
p(\epsilon) = N(0, \sigma^2) \
p(\boldsymbol{w}) = \prod_{i}{N(w_i|0, \lambda^2)}
$$
を考える。
$Data = {(X, \boldsymbol{y})}$ に対して、$p(\boldsymbol{y}, \boldsymbol{w}| X) = p(\boldsymbol{y}| \boldsymbol{w}, X)p(\boldsymbol{w})$より、
「$p(\boldsymbol{y}, \boldsymbol{w}| X)$ を最大化する」 ⇔ 「$||\boldsymbol{y} - X \boldsymbol{w}||^2 + \alpha||\boldsymbol{w}||^2$ を最小化する」 (途中式略)
となるため、
「重みの事前分布を加味したガウス分布誤差の確率モデル」=「2乗誤差によるリッジ回帰」
ということがわかる。
多変量ガウス分布
$$
N(\boldsymbol{x}|\boldsymbol{\mu}, \Sigma) = \frac{1}{\sqrt{2\pi}^D \sqrt{|\Sigma|}}exp(-\frac{1}{2}(\boldsymbol{x} - \boldsymbol{\mu})^T \Sigma^{-1} (\boldsymbol{x} - \boldsymbol{\mu}))
$$
$D$ は $\boldsymbol{x}$ の次元。
多変量ガウス分布の特徴
期待値と共分散行列
$$
\boldsymbol{\mu} = \mathbb{E}[\boldsymbol{x}] \
\Sigma = \mathbb{E}[\boldsymbol{x}\boldsymbol{x}^T] - \mathbb{E}[\boldsymbol{x}]\mathbb{E}[\boldsymbol{x}^T]
$$
ガウス分布の線形変換
$$
\boldsymbol{x} ~ N(\boldsymbol{0}, \Sigma) \
\boldsymbol{y} = A \boldsymbol{x}
$$
のとき、$\boldsymbol{y}$ はガウス分布に従う。(精度行列$^*$は、$(A^{-1})^T \Sigma^{-1} A^{-1}$)
* 共分散行列の逆行列
ガウス分布の周辺化
D次元ベクトル $\boldsymbol{x}$ を分割して
\boldsymbol{x} =
\begin{pmatrix}
\boldsymbol{x}_1 \\
\boldsymbol{x}_2
\end{pmatrix}
とする。
\begin{pmatrix}
\boldsymbol{x}_1 \\
\boldsymbol{x}_2
\end{pmatrix}
~
N(\begin{pmatrix}
\boldsymbol{x}_1 \\
\boldsymbol{x}_2
\end{pmatrix},
\begin{pmatrix}
\Sigma_{11} \Sigma_{12} \\
\Sigma_{21} \Sigma_{22}
\end{pmatrix})
とすると、
p(\boldsymbol{x}) = \int p(\boldsymbol{x}_1, \boldsymbol{x}_2) d\boldsymbol{x}_2 = N(\boldsymbol{\mu}, \Sigma_{11})
ガウス分布の条件付き分布
記号、条件は「ガウス分布の周辺化」と同じとすると、
p(\boldsymbol{x}_2| \boldsymbol{x}_1) = N(\boldsymbol{\mu_2} + \Sigma_{21}\Sigma_{11}^{-1}(\boldsymbol{x}_1 - \boldsymbol{\mu}_1), \Sigma_{22} - \Sigma_{21} \Sigma_{11}^{-1} \Sigma_{12})
3章 ガウス過程
線形回帰モデルの重みがガウス分布に従う場合
N個の観測値のペア $Data={(\boldsymbol{x_1}, y_1), .. , (\boldsymbol{x_N}, y_N)}$ に対して、
$$
\boldsymbol{y} = \Phi \boldsymbol{w}
$$
とする。ただし、
\Phi = \begin{pmatrix}
\boldsymbol{\phi}(\boldsymbol{x_1})^T \\
\vdots \\
\boldsymbol{\phi}(\boldsymbol{x_N})^T \\
\end{pmatrix}
=
\begin{pmatrix}
\phi_0(\boldsymbol{x_1}) & \cdots & \phi_H(\boldsymbol{x_1}) \\
\vdots & & \vdots \\
\phi_0(\boldsymbol{x_N}) & \cdots & \phi_H(\boldsymbol{x_N})\\
\end{pmatrix}
である。このとき、次が成り立つ。
$$
\boldsymbol{w} \sim N(0, \lambda^2I) \hspace{10pt} \Rightarrow \hspace{10pt} \boldsymbol{y} \sim N(0, \lambda^2 \Phi \Phi^T) \hspace{10pt} \cdots (*3.1)
$$
この式から、線形回帰モデルにあった重み $\boldsymbol{w}$ が高次元であった場合でも(無限次元でも)、重み $\boldsymbol{w}$ を求める必要がなく、$\boldsymbol{y}$ の分布は $\lambda^2 \Phi \Phi^T$ で決まることがわかる。
ガウス過程の定義(簡易版)
任意のN個の入力 $\boldsymbol{x_1}, ..., \boldsymbol{x_N}$ に対して、対応する出力 $\boldsymbol{y} = (y_1, ..., y_N)$ が多変量ガウス分布に従うとき、$\boldsymbol{x}$ と $y$ はガウス過程に従うという。
カーネルトリック
(*3.1) の共分散行列を $K = \lambda^2 \Phi \Phi^T$ とかく。$K$ の成分は $K_{mn} = \lambda^2 \boldsymbol{\phi}(\boldsymbol{x_m})^T \boldsymbol{\phi}(\boldsymbol{x_n})$ とかける。
ここで、$k(\boldsymbol{x_m}, \boldsymbol{x_n}) = \boldsymbol{\phi}(\boldsymbol{x_m})^T \boldsymbol{\phi}(\boldsymbol{x_n})$ をカーネル関数、$K$ を**カーネル行列(またはグラム行列)**と呼ぶ。
特徴ベクトル $\boldsymbol{\phi}(\boldsymbol{x})$ を直接表現せずに、カーネル関数によってカーネル行列を計算することをカーネルトリックという。
ガウス過程の定義
任意のN個の入力 $\boldsymbol{x_1}, ..., \boldsymbol{x_N}$ に対応する出力 $\boldsymbol{f} = (f(\boldsymbol{x_1}), ..., f(\boldsymbol{x_N}))$ が、平均 $\boldsymbol{\mu} = (\mu(\boldsymbol{x_1}), ..., \mu(\boldsymbol{x_N}))$ , 共分散行列 $K = (k(\boldsymbol{x_m}, \boldsymbol{x_n}))$ のガウス分布 $N(\boldsymbol{\mu}, K)$ に従うとき、$f$ はガウス過程に従うといい、
$$
f \sim GP(\mu(\boldsymbol{x}), k(\boldsymbol{x_m}, \boldsymbol{x_n}))
$$
とかく。これを、次のように略記することもある。
$$
f \sim N(\boldsymbol{\mu}, K)
$$
観測ノイズ
出力に観測ノイズが乗る場合、すなわち $\boldsymbol{f} = (f(\boldsymbol{x_1}) + \epsilon_1, ..., f(\boldsymbol{x_N}) + \epsilon_N), \hspace{3.0pt} \epsilon_n \sim N(0, \sigma^2)$ のとき、
$$
f \sim N(\boldsymbol{\mu}, K + \sigma^2 I)
$$
となり、カーネル関数は $k(\boldsymbol{x_m}, \boldsymbol{x_n}) + \sigma^2 \delta(m, n)$ となる。
カーネル関数の例
・ガウスカーネル(動径基底関数RBF)
$$
k(\boldsymbol{x_m}, \boldsymbol{x_n}) = \theta_1 exp(- \frac{|\boldsymbol{x_m} - \boldsymbol{x_n}|^2}{\theta_2})
$$
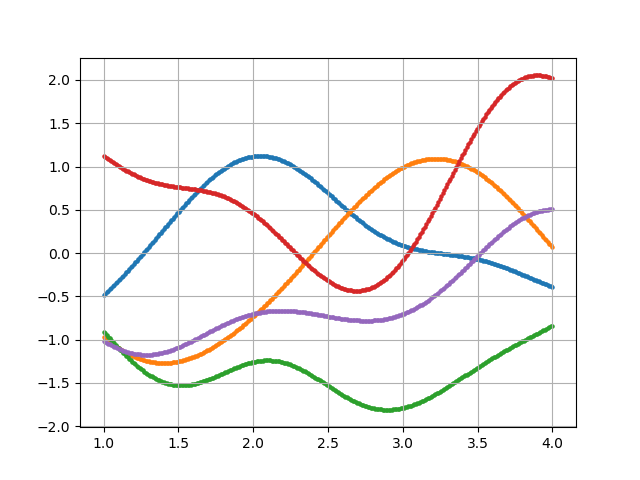
・線形カーネル
$$
k(\boldsymbol{x_m}, \boldsymbol{x_n}) = \boldsymbol{x_m} \cdot \boldsymbol{x_n}
$$
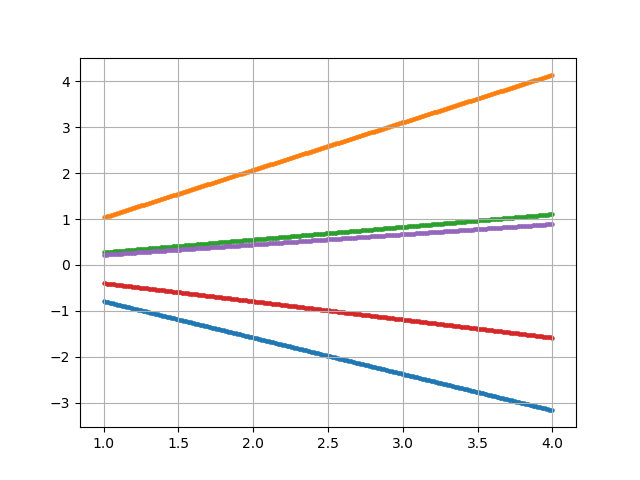
・指数カーネル
$$
k(\boldsymbol{x_m}, \boldsymbol{x_n}) = exp(- \frac{|\boldsymbol{x_m} - \boldsymbol{x_n}|}{\theta})
$$
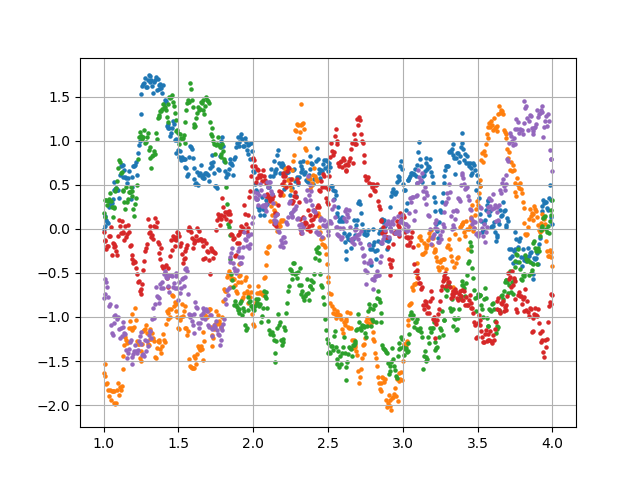
・周期カーネル
$$
k(\boldsymbol{x_m}, \boldsymbol{x_n}) = exp(\theta_1 cos( \frac{|\boldsymbol{x_m} - \boldsymbol{x_n}|}{\theta_2}))
$$
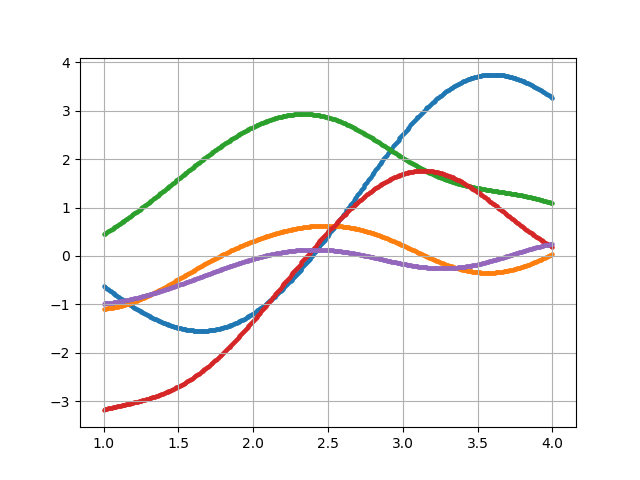
・Matérnカーネル
$$
k_{\nu}(\boldsymbol{x_m}, \boldsymbol{x_n}) = \frac{2^{1-\nu}}{\Gamma(\nu)}(\frac{\sqrt{2\nu}r}{\theta})^{\nu}K_{\nu}(\frac{\sqrt{2\nu}r}{\theta}) \hspace{15pt} (r = |\boldsymbol{x_m} - \boldsymbol{x_n}|)
$$
$K_\nu$ は第2種変形ベッセル関数。
-
$\nu = \frac{1}{2}$ のとき、$k_{1/2}(\boldsymbol{x_m}, \boldsymbol{x_n}) = exp(- \frac{r}{\theta})$ ・・・指数カーネル
-
$\nu = \frac{3}{2}$ のとき、$k_{3/2}(\boldsymbol{x_m}, \boldsymbol{x_n}) = (1 + \frac{\sqrt{3}r}{\theta})exp(- \frac{\sqrt{3}r}{\theta})$
- $\nu = \frac{5}{2}$ のとき、$k_{5/2}(\boldsymbol{x_m}, \boldsymbol{x_n}) = (1 + \frac{\sqrt{5}r }+ \frac{5r^2}{3\theta^2}{\theta}) exp(- \frac{\sqrt{5}r}{\theta})$
- $\nu = \infty$ のとき、$k_{\infty}(\boldsymbol{x_m}, \boldsymbol{x_n}) = exp(- \frac{r^2}{2\theta^2})$ ・・・ガウスカーネル
Matérnカーネルは、ガウスカーネルと指数カーネルを $\nu $ によって連続的につなぐ。
ガウス過程回帰モデル
N個の入出力のペア $Data={(\boldsymbol{x_1}, y_1), .. , (\boldsymbol{x_N}, y_N)}$ が与えられているとする。
$y$ は正規化して平均が $0$ であるとする。
$y = f(\boldsymbol{x})$ 、$f \sim GP(\boldsymbol{0}, k(\boldsymbol{x}, \boldsymbol{x'}))$ とする。
このとき、$\boldsymbol{y} = (y_1, ..., y_N)^T$ とすると、$\boldsymbol{y} \sim N(\boldsymbol{0}, K)$ となる。
ここで、データには含まれていない入出力のペア $(\boldsymbol{x}^*, y^*)$ が与えられたとき、
\begin{pmatrix}
\boldsymbol{y} \\
y^*
\end{pmatrix}
\sim
N(\boldsymbol{0},
\begin{pmatrix}
K && \boldsymbol{k}_* \\
\boldsymbol{k}_*^T && k_{**}
\end{pmatrix})
となる。ただし、
\boldsymbol{k}_{*} = (k(\boldsymbol{x}^{*}, \boldsymbol{x}_1), ..., k(\boldsymbol{x}^{*}, \boldsymbol{x}_N))^T, \hspace{5pt} k_{**} = k(\boldsymbol{x}^{*}, \boldsymbol{x}^{*})
である。
したがって、2章のガウス分布の周辺化より、予測分布は次のようになる。
p(y^*| \boldsymbol{x}^*, D) = N(\boldsymbol{k}_*^T K^{-1} \boldsymbol{y}, k_{**} - \boldsymbol{k}_*^T K^{-1} \boldsymbol{k}_*)
同様に、データには含まれていない複数の入出力のペア $((\boldsymbol{x}_1^*, y_1^*), ...,(\boldsymbol{x}_M^*, y_M^*))$ が与えられたとき、
$\boldsymbol{y}^* = (y_1^*, ..., y_N^*)^T$ とすると、
\begin{pmatrix}
\boldsymbol{y} \\
\boldsymbol{y}^*
\end{pmatrix}
\sim
N(\boldsymbol{0},
\begin{pmatrix}
K && \boldsymbol{k}_* \\
\boldsymbol{k}_*^T && \boldsymbol{k}_{**}
\end{pmatrix})
となる。ただし、$\boldsymbol{k}_*(n, m) = k(\boldsymbol{x}_n, \boldsymbol{x}m^*), \hspace{5pt} \boldsymbol{k}{**}(n, m) = k(\boldsymbol{x}_n^*, \boldsymbol{x}_m^*)$ である。
したがって、予測分布は次のようになる。
p(\boldsymbol{y}^*| X^*, D) = N(\boldsymbol{k}_*^T K^{-1} \boldsymbol{y}, \boldsymbol{k}_{**} - \boldsymbol{k}_*^T K^{-1} \boldsymbol{k}_*)
ガウス過程のハイパーパラメータの最適化
$\boldsymbol{\theta}$ をパラメータにもつカーネル $k_{\boldsymbol{\theta}}(\boldsymbol{x}, \boldsymbol{x}')$ によるカーネル行列 $K_{\boldsymbol{\theta}}$ について、観測データ $\boldsymbol{y}$ の確率の対数、すなわち $\boldsymbol{\theta}$ の対数尤度は
L = \log p(\boldsymbol{y}| X, \boldsymbol{\theta}) \propto -\log |K_{\boldsymbol{\theta}}| - \boldsymbol{y}^T K_{\boldsymbol{\theta}}^{-1} \boldsymbol{y}
となる。データセットに最適なガウス過程モデルを作成するためには、$L$ を最大にする $\boldsymbol{\theta}$ を求めれば良い。
$L$ を最大にする $\boldsymbol{\theta}$ を求めるためには、MCMC、勾配法(SCG法やL-BFGS法)を用いると良い。
様々な観測モデル
ガウス過程による関数値 $f$ から観測値 $y$ が生成される観測モデルは、条件付き確率 $p(y|f)$ によって表される。
これまでは、 $p(\boldsymbol{y}| \boldsymbol{f}) = N(\boldsymbol{f}, \sigma^2I)$ といったガウス分布を想定してきたが、観測モデルは他にも様々なものが考えられる。
外れ値に対してロバスト(頑健)→コーシー分布
2値の識別→ロジスティック関数
観測値が非負整数のみ→ポアソン分布
4章 確率的生成モデルとガウス過程
用語の定義
-
確率変数
その値が試行ごとに確率的に決まる変数。
-
確率分布
確率変数(離散値)がとり得る値に対して確率を定める関数。
-
確率密度関数
確率変数(連続値値)がとり得る値に対して確率を定める関数。
-
同時分布
確率変数 $X, Y$ に対して、その組み合わせ $(X, Y)$ の確率分布 or 確率密度関数。
-
確率過程
任意の $N$ 個の入力値 $\boldsymbol{x}_1, ..., \boldsymbol{x}_N$ に対して、出力値 $\boldsymbol{f}_N = (f(\boldsymbol{x}_1), ..., f(\boldsymbol{x}_N)$ の同時確率 $p(\boldsymbol{f}_N)$ を与えることができるとき、 $f$ を確率過程と呼ぶ。
※ ガウス過程は、 $p(\boldsymbol{f}_N)$ を $N$ 次元のガウス分布とする。
-
周辺化と周辺分布
確率変数 $X, Y$ に対して、
p(X) = \int p(X, Y) dYによって $X$ の確率密度関数を得る操作を周辺化と呼び、得た確率分布 $p(X)$ を周辺分布と呼ぶ。
-
条件付き分布
$X$ の値が既知 or 所与としたときの $Y$ の確率分布を条件付き分布と呼び、 $p(Y|X)$ とかく。条件 $X$ は確率密度関数である必要はない。
-
ベイズの定理
p(Y|X)p(X) = p(X, Y) = p(X|Y)p(Y)より、次が成り立つ。
p(Y|X) = \frac{p(X|Y)p(Y)}{p(X)}これをベイズの定理と呼ぶ。
-
確率的生成モデリング
次のように、観測される値の生成過程を確率分布で表現する作業を確率的生成モデリングと呼ぶ。
- 未知の値を確率変数で表す。
- 個々の値が生成される確率的な過程をそれぞれ確率分布で表す。
- 全ての確率変数の同時分布を表す。
- 必要な周辺分布を求める。
例えば、
-
確率変数 $X, Y$ に対して、
-
それぞれの確率分布を $p(X), p(Y|X)$ と仮定する。
確率分布 $p(Y)$ を得たい場合、
-
同時変数 $p(X, Y) = p(Y|X)p(X)$ を求め、
-
周辺化 $p(Y) = \int p(X, Y) dX$ を行う。
-
確率変数の独立性
確率分布 $X, Y$ が次を満たすとき、$X$ と $Y$ は独立であるという。
p(X, Y) = p(X)p(Y) -
確率変数の条件付き独立性
確率分布 $X, Y$ が次を満たすとき、$X$ と $Y$ は条件 $Z$ のもとで条件付き独立であるという。
p(X, Y) = p(X|Z)p(Y|Z) -
確率的生成モデル(または確率モデル)
- 「観測値 $Y$ は、何らかの確率分布 $p(Y)$ からのサンプリング $Y \sim p(Y)$ によって得られたものだ」とする仮説を確率的生成モデル(または確率モデル)という。
-
確率モデルの仮説間の違いを $\theta$ で表して、確率モデルを条件付き確率 $p(Y|\theta)$ で表したものをパラメトリックモデルという。
- 観測 $Y$ に基づいてパラメータ $\theta$ を決定することをパラメータの推定という。
-
観測データの尤度関数 $L(\theta) = p(Y|\theta)$ が最大になるように、パラメータ $\theta$ を定める方法を最尤推定という。
-
ベイズ推定
ベイズ推定とは、次のように、観測値を得ることによって確率変数 $\theta$ の分布を更新することである。
-
尤度関数をモデリングする。
未知変数 $\theta$ のもとで観測 $Y$ が確率的に生成される過程を、条件付き確率 $p(Y|\theta)$ で書き下し、これを未知変数 $\theta$ の関数 $L(\theta) = p(Y|\theta)$ とみなす。
-
事前確率をモデリングする。
未知変数 $\theta$ のとり得る値の範囲と、その主観的な可能性の度合いを、確率分布 $p(\theta)$ の形で表す。
-
ベイズの定理を適用して未知変数 $\theta$ の事後確率 $p(\theta|Y)$ を求める。
p(\theta|Y) = \frac{p(Y|\theta)p(\theta)}{p(Y)}
ベイズ推定は、最尤推定と異なり、未知のパラメータや予測分布が確率分布の形で得られる。
-
-
カーネル密度推定
サンプルを用いた確率分布推定の方法。
サンプル $x_1, ..., x_N \sim p(x)$ に対して、確率分布 $p(x)$ を次のように推定できる。
\tilde{p}(x) = \frac{1}{K} \sum_{k=1}^{K}{h_k(x)}ここで、$h_k(x) \geq 0, k=1, ..., K$ を基底関数と呼び、$\int{h_k(x)}dx = 1$ を満たすものとする。
カーネル密度推定は、サンプルに対応する基底関数を以下のように定義した場合をいう。
h_n(x) = h(\frac{x_n - x}{\sigma})ここで、$h(x)$ は正値をとる任意の関数であり、カーネル関数と呼び、$\sigma$ をバンド幅と呼ぶ。
カーネル関数の例
-
ガウス分布カーネル(なめらかで見栄えの良い確率密度関数が得られる)
h(x) = N(x| 0, I) -
エパネクニコフカーネル(精度の良い確率密度関数が得られる)
h(x) = \frac{3}{4}(1 - ||x||^2)I(||x|| < 1)ただし、$I(\cdot)$ は $()$ の中が成り立てば 1、そうでなければ 0 をとる関数。
-
5章 ガウス過程の計算法
(随時更新予定)