はじめに
AWSのLambdaはサーバーレスでコードを実行できる仕組みです。Lambdaはとても小規模なコードならばブラウザでコーディングが完結する手軽さがあります。ですが、実際にLambdaで実行した処理はそこそこ重たい処理のケースが多いです。特に、信号処理のように特定のライブラリに依存するような処理は、ブラウザだけで完結させることが難しく、Lambdaレイヤーや、コンテナを使用した方法を採用しなければなりません。
Lambdaレイヤーや、コンテナを使用したLambdaは開発するのがちょっと大変です。インターネットで情報を探すと、誰かが完成させたものはたくさんあるのですが、完成させる過程に関する資料が少ないのが気になりました。
そこで、今回は私が開発者ならばどういうアプローチをするか、を記事にしようと思います。
※ここで作成したLambdaより大規模になるならば、大人しくSAMなどの利用をした方が良いかもしれません。
作成するLambda
今回作成するLambdaは次の通りの仕様とします。
- S3バケットへのファイルの設置をトリガーとする
-- ファイルはmp3の音声ファイルとする - トリガーと同じS3バケットに、mp3のビットレートを変換したファイルを設置する
- mp3のビットレート変換にはffmpegを用いる
ここで、2行目に危険な内容が書かれていることに気付いた方はLambdaに慣れています。LambdaのトリガーとするS3バケットに対して、ファイルを送り返してしまってはいけないのです。LambdaからS3にファイルを設置したことによってトリガーが発火するので、Lambdaが毎回2回以上実行されてしまいます。実装でミスをすると無限ループになってしまうこともあります。
ですが、今回はあえて非推奨のパターンで実装します。理由としては、もともとサーバで動いていた処理の互換が求められることがあるからです。
- サーバで嵩張る処理をLambdaに逃がしてほしい
- 既存のソースには手を付けたくない
というケースが珍しくないためです。入出力でバケットを分けるコストと、Lambdaが毎回2回起動してしまうコストを比べてみて、入出力を分けることができるのであれば、そのように実装すべきです。
ffmpegの実行に関しては、今回はffmpegが実行可能なコンテナを用意することで解決したいと思います。
ブラウザで処理の骨格を作る(開発前準備)
コンテナを利用したLambdaはデプロイに手数がかかります。今回、コンテナに頼る部分はffmepgの実行だけです。なので、S3からファイルを受け取り、S3にファイルを返す、という部分はコンテナなしで作れるはずです。
(1)S3をin, outで2つのバケットを用意する
最終的な目標は入出力に同じS3バケットを使うことですが、うっかり無限ループを作ってしまうと面倒なので、一旦入出力を分けて作ります。ffmpeg-srcとffmpeg-dstというバケット名にしました。
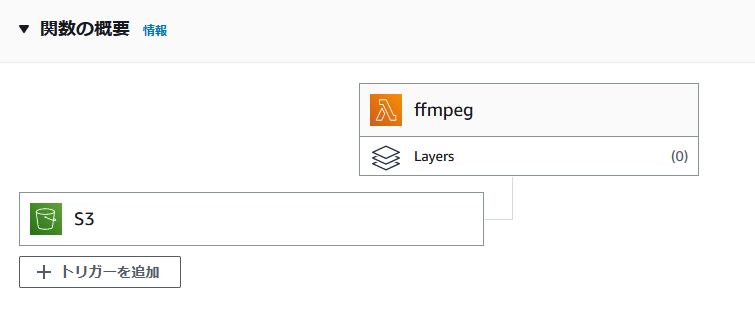
(2)Lambda関数を新規作成して、ffmpeg-srcをトリガーに設定する
Lambda関数を新規作成して、ffmpeg-srcをトリガーに設定します。言語は何となくPythonにしました。S3のトリガーでプレフィックスやサフィックスのオプションがありますが、今回は使いません。
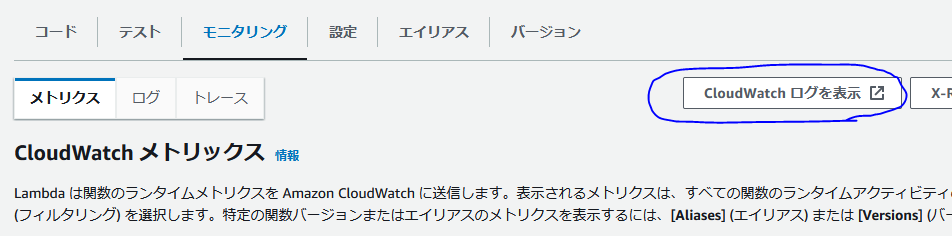
(3)CloudWatchでLambdaのログを閲覧できるようにする
CloudWatchのロググループを作成し、Lambdaのログを閲覧できるように設定します。Lambda関数を新規作成しただけの状態だとログを見ることができません。この状態で開発を行おうとするとデバッグがノーヒントになってしまいとても大変です。
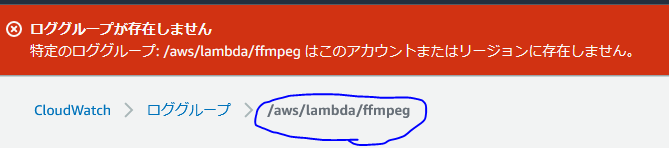
次の画像のCloudWatchログを表示、を押下すると、何もしていない状態だと、ロググループに該当するものが無い旨が表示されます。
ここに出ているロググループ名を新規作成すればOKです。
ここで、適当なファイルをS3に設置するとCloudWatchにLambdaが実行されたログが出てきます。ログの反映には少し時間がかかります。
これで、Lambdaを開発する準備が最低限整いました。
ブラウザで処理の骨格を作る
(1)S3と疎通する
S3へのファイル設置をトリガーとして、設置されたファイルをダウンロード、そしてファイルのコピーをoutput_bucketにアップロードするコードを書いてみます。
注意としては、Lambdaは一時領域として、/tmpに書き込むことができますが、ディレクトリを掘ることができないので、/tmp直下に保存するように書きます。これを忘れてしまうと、何故かファイルが消えるという現象に悩まされることになります。
import json
import subprocess
import boto3
import os
import urllib.parse
s3 = boto3.resource('s3')
output_bucket = "ffmpeg-dst"
def lambda_handler(event, context):
if 'Records' in event.keys():
input_bucket = event['Records'][0]['s3']['bucket']['name']
input_key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8')
in_bucket = s3.Bucket(input_bucket)
else :
print("ファイルが来ていればここは動かないはず")
return ""
print(input_key)
# get S3 Object
file_path = '/tmp/downloaded'
in_bucket.download_file(input_key, file_path)
# ダウンロードしたファイルをS3にアップロード
if os.path.exists(file_path):
print('Size: {}'.format(os.path.getsize(file_path)))
data = open(file_path, 'rb')
out_bucket = s3.Bucket(output_bucket)
out_bucket.put_object(Key=input_key,Body=data)
data.close()
else :
print("ダウンロードしたファイルがない")
return ''
このコードをデプロイして、S3にファイルを置いてみます。すると、コケます。CloudWatchでログを確認すると、LambdaがS3を参照する権限を持ってないことがわかります。
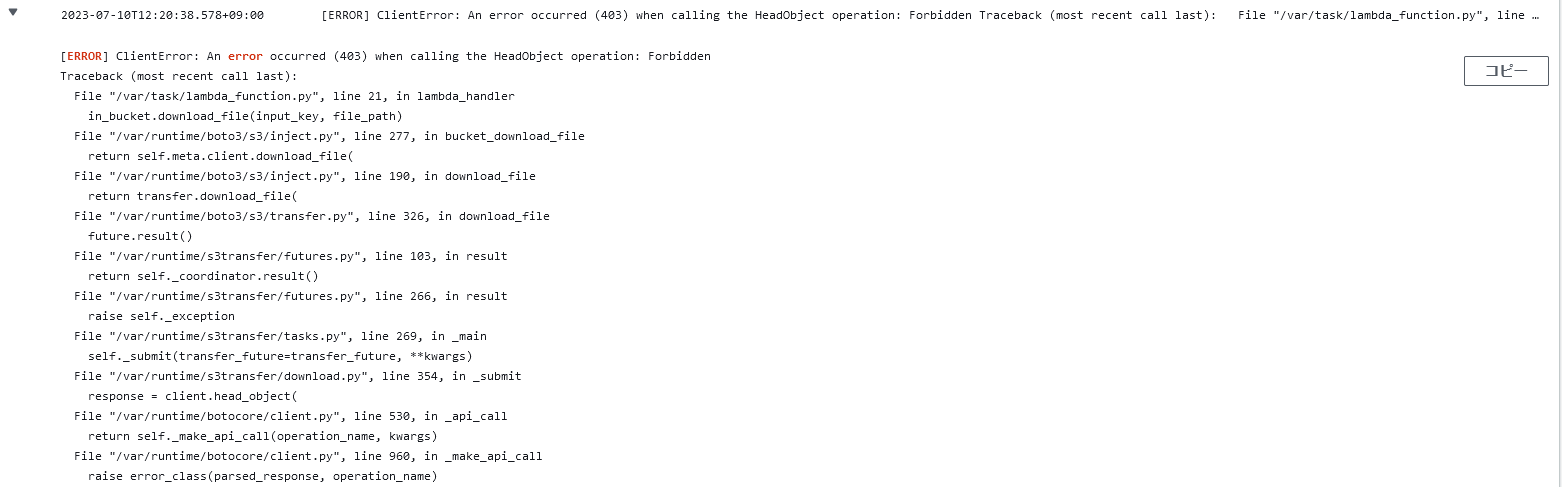
Lambdaに適切なロールをアタッチすれば動くようになります。このあたりはインターネットに資料がたくさんあるので、ここでは割愛します。
(2)無限ループを止める仕組みを作る
S3の入出力バケットを分けている方はここを読む必要はありません。今回は入出力を同じバケットにするために、少し仕様を追加します。
- 入力ファイル名は「*_orig.mp3」の場合に処理をする、それ以外の場合は停止する
- 出力ファイルは「*_128kbps.mp3」とする
とします。こうすることで、出力したファイルにより処理がループしてしまうことを回避しようと思います。
import json
import subprocess
import boto3
import os
import urllib.parse
import shutil
s3 = boto3.resource('s3')
output_bucket = "ffmpeg-dst"
def lambda_handler(event, context):
if 'Records' in event.keys():
input_bucket = event['Records'][0]['s3']['bucket']['name']
input_key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8')
in_bucket = s3.Bucket(input_bucket)
else :
print("ファイルが来ていればここは動かないはず")
return ""
if not input_key.endswith("_orig.mp3"):
print("処理対象外")
return ""
print(input_key)
# get S3 Object
file_path = '/tmp/downloaded'
in_bucket.download_file(input_key, file_path)
# 処理したことにして、同じファイルをローカルの処理後ファイル名で設置する。
result_local_path = '/tmp/result'
shutil.copy(file_path, result_local_path)
# S3にアップロードするKey
result_s3_path = input_key.replace("_orig.mp3", "_128kbps.mp3")
# S3にアップロード
if os.path.exists(result_local_path):
print('Size: {}'.format(os.path.getsize(result_local_path)))
data = open(result_local_path, 'rb')
out_bucket = s3.Bucket(output_bucket)
out_bucket.put_object(Key=result_s3_path,Body=data)
data.close()
else :
print("ダウンロードしたファイルがない")
return ''
これで、出力先バケットにコピーされたファイルは、ファイル名がLambdaの処理条件に引っかからないようになったので、出力先のバケットを入力バケットに変えます。
import json
import subprocess
import boto3
import os
import urllib.parse
import shutil
s3 = boto3.resource('s3')
def lambda_handler(event, context):
if 'Records' in event.keys():
input_bucket = event['Records'][0]['s3']['bucket']['name']
input_key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8')
in_bucket = s3.Bucket(input_bucket)
else :
print("ファイルが来ていればここは動かないはず")
return ""
if not input_key.endswith("_orig.mp3"):
print("処理対象外")
return ""
print(input_key)
# get S3 Object
file_path = '/tmp/downloaded'
in_bucket.download_file(input_key, file_path)
# 処理したことにして、同じファイルをローカルの処理後ファイル名で設置する。
result_local_path = '/tmp/result'
shutil.copy(file_path, result_local_path)
# S3にアップロードするKey
result_s3_path = input_key.replace("_orig.mp3", "_128kbps.mp3")
# S3にアップロード
if os.path.exists(result_local_path):
print('Size: {}'.format(os.path.getsize(result_local_path)))
data = open(result_local_path, 'rb')
in_bucket.put_object(Key=result_s3_path,Body=data)
data.close()
else :
print("ダウンロードしたファイルがない")
return ''
これで骨格の作成が完了しました。
あとは、
shutil.copy(file_path, result_local_path)
ここをffmpegのコマンド実行に差し替えたコードを、ffmpegの実行環境を整備したコンテナに差し込んでデプロイすれば、希望通りの動作になるはずです。
(3)コンテナを用意して動作を確認する
Dockerfileはこちらを参考にしました。
FROM public.ecr.aws/lambda/python:3.10
ENV SNDFILE_VERSION=1.0.28
WORKDIR "${LAMBDA_TASK_ROOT}"
RUN yum -y install curl tar gzip zlib xz xz-utils
RUN curl -L -o "libsndfile-${SNDFILE_VERSION}.tar.gz" "http://www.mega-nerd.com/libsndfile/files/libsndfile-${SNDFILE_VERSION}.tar.gz"
RUN tar xf "libsndfile-${SNDFILE_VERSION}.tar.gz"
WORKDIR "${LAMBDA_TASK_ROOT}/libsndfile-${SNDFILE_VERSION}"
RUN yum install -y gcc make
RUN ./configure --prefix=/opt/
RUN make
RUN make install
WORKDIR "${LAMBDA_TASK_ROOT}"
RUN curl https://johnvansickle.com/ffmpeg/releases/ffmpeg-release-amd64-static.tar.xz -o ffmpeg.tar.xz -s
RUN tar -xf ffmpeg.tar.xz
RUN mv ffmpeg-*-amd64-static/ffmpeg /usr/bin
# Create function directory
RUN mkdir -p ${LAMBDA_TASK_ROOT}
COPY app.py ${LAMBDA_TASK_ROOT}
CMD [ "app.handler" ]
Dockerfileと同じディレクトリに、app.pyを設置してビルドします。
ブラウザではlambda_handlerでしたが、CMD [ "app.handler" ]に合わせて関数名の辻褄がずれないように注意しましょう。
import json
import subprocess
import boto3
import os
import urllib.parse
import shutil
s3 = boto3.resource('s3')
def handler(event, context):
if 'Records' in event.keys():
input_bucket = event['Records'][0]['s3']['bucket']['name']
input_key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8')
in_bucket = s3.Bucket(input_bucket)
else :
print("ファイルが来ていればここは動かないはず")
return ""
if not input_key.endswith("_orig.mp3"):
print("処理対象外")
return ""
print(input_key)
# get S3 Object
file_path = '/tmp/downloaded.mp3'
in_bucket.download_file(input_key, file_path)
result_local_path = '/tmp/result.mp3'
#ffmpegでビットレートを変換
proc = subprocess.run("ffmpeg -i /tmp/downloaded.mp3 -b:a 128k /tmp/result.mp3", shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
print('STDOUT: {}'.format(proc.stdout))
print('STDERR: {}'.format(proc.stderr))
# S3にアップロードするKey
result_s3_path = input_key.replace("_orig.mp3", "_128kbps.mp3")
# S3にアップロード
if os.path.exists(result_local_path):
print('Size: {}'.format(os.path.getsize(result_local_path)))
data = open(result_local_path, 'rb')
in_bucket.put_object(Key=result_s3_path,Body=data)
data.close()
else :
print("ダウンロードしたファイルがない")
return ''
(4)動作確認とパラメータ設定
Lambdaは初期状態では3秒でタイムアウトになります。大抵はここが足りなくなるので、適宜決めましょう。他のパラメータはよしなに。