はじめに
2025年7月からPythonを学習しており、アウトプットとして本記事を執筆いたします。今回はSeleniumを使用して採用情報サイトのスクレイピングを実施し、Pandasで統計量を取得、matplotlibでグラフを作成しました。手順や工夫した点をまとめています。
採用情報サイトをスクレイピング対象にした理由としては、現状転職する予定が無くても日々採用情報を確認して、需要のあるスキルは何か、現在の自分の年収はどのくらいに位置するのか、把握できたらいいなという気持ちから対象としました。
目次
1. アウトプット内容
2. 下準備
2-1. 使用環境・ライブラリ、バージョン
2-2. 環境構築
2-3. 対象サイト選定
3. スクレイピング①(採用情報の自動抽出)
3-1. 利用規約、robots.txtの確認
3-2. 対象サイトの構成確認
3-3. 自動アクセス〜情報抽出
3-4. CSVに保存
4. 統計量の取得
4-1. 採用情報全件
4-2. 都道府県ごと
5. スクレイピング②(ITスキル別の採用件数)
5-1. 対象サイトの構成確認
5-2. 自動アクセス〜情報抽出
5-3. CSVに保存、CSVから読み込み
5-4. pandas × matplotlibを用いたデータ可視化
1. アウトプット内容
今回は大きく分けて以下2つのアウトプットを実施しました。
- IT系の採用情報を自動で抽出。その情報から、全件・勤務地ごとの給料平均値や中央値、min,maxを算出。
- IT系の各スキルの採用情報件数を抽出。件数の多い順に並び替えて棒グラフで表示。
2. 下準備
2-1. 使用環境・ライブラリ、バージョン
Anacondaで仮想環境を構築し、ライブラリをインストール。その環境でJupyterLabを使って開発しています。
使用PCはMacbook Air(M1)です。
| 使用目的 | 環境・ライブラリ | バージョン |
|---|---|---|
| Python環境管理 | anaconda | conda 25.5.1 |
| コード実行用ツール | JupyterLab | 4.2.5 |
| 言語 | Python | 3.8.20 |
| ブラウザ自動化 | Selenium | 4.25.0 |
| ドライバ自動管理 | webdriver_manager | 4.0.2 |
| データ処理 | pandas | 2.0.3 |
| 時間待避 | time | 標準ライブラリ |
| データ可視化 | matplotlib | 3.7.5 |
2-2. 環境構築
anacondaでJupyterLabをLaunchし、各ライブラリをJupyterLab上でインストール(※JupterLab上でpipコマンドを使用する際、頭に" ! "をつけて実行しています)
pip install selenium==4.25
pip install webdriver_manager
pip install pandas
pip install matplotlib
from webdriver_manager.chrome import ChromeDriverManager
ChromeDriverManager().install()
2-3. 対象サイト選定
以下採用情報サイトを対象とし、この中から1つ選ぶことにしました。
- indeed
- doda
- リクルートエージェント
3.スクレイピング①(採用情報の自動抽出)
3-1.利用規約、robots.txtの確認
-
indeed
利用規約に以下の記載が合ったため、スクレイピングできないと判断。Indeed が事前に書面にて明示的に許可した場合を除き、ユーザーは、本サイトのいかなる部分についても、クローリング、スクレイピング、データマイニング、データ抽出、再現、複製、複写、販売、悪用、取引、再販を行ってはなりません。
-
doda
利用規約には特にスクレイピングについての記載は無し。robots.txtを確認すると求人検索欄のリンクはDisallowとなっていたため、スクレイピングできないと判断。
Disallow: /DodaFront/View/JobSearchList/j_ar__*/-pr__*/
Disallow: /DodaFront/View/JobSearchList.action*
Disallow: /DodaFront/View/JobSearchList/j_pr__*/-preBtn__2/
Disallow: /DodaFront/View/JobSearchList/j_oc__*/-preBtn__1/
Disallow: /DodaFront/View/JobSearchList/j_oc__*/-preBtn__2/
Disallow: /DodaFront/View/JobSearchList/j_ar__*/-preBtn__2/
Disallow: /DodaFront/View/JobSearchList/j_ar__1/*
Disallow: /DodaFront/View/JobSearchList/*/-tp__*/*
Disallow: */-ds__*/*
Disallow: */-pic__*/*
Disallow: /DodaFront/View/JobSearchList/*?*
Disallow: /DodaFront/View/JobSearchList/*/-/
- リクルートエージェント
利用規約を確認したところ、特にスクレイピングについての記載はなし。
robots.txtも求人検索欄のリンクはDisallowとなっていなかった。
→ 今回はリクルートエージェントをスクレイピング対象サイトとして実施。
3-2. 対象サイトの構成確認
GoogleChromeの検証機能を使用し、取得したい情報のタグ、class名を予め整理しています。
URL(IT系の検索ページ):https://www.r-agent.com/kensaku/syokusyu/ocpt1-09/
求人タイトル <h2 class='cpPDaA'>
企業名 <div class="kcpGrY">
年収 <div class='gruhPk'>の中の<div class="fBnySK">
勤務地 <div class='eTPXUu'>の中の<div class="fBnySK">
求人URL <a class="bWMRyK" href="">
3-3.自動アクセス〜情報抽出
# webdriverモジュールのimport:ブラウザ操作で最も使用するモジュール
# ChromeDriverの起動を管理するための Service クラスをインポート
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
# 上のセルの実行結果のパスをServiceクラスの引数に入れるイメージ(後からパスが変わった時のために、直接パスを指定せずにinstallで記載)
service = Service(ChromeDriverManager().install())
# ブラウザを自動で立ち上げる
chrome = webdriver.Chrome(service=service)
URL = 'https://www.r-agent.com/kensaku/syokusyu/ocpt1-09/'
chrome.get(URL)
デフォルトでは1ページに50件表示しています。抽出効率を上げるために、表示件数を自動で50件から100件に上げています。
# 表示件数を50から100にする
from selenium.webdriver.support.ui import Select
# 3を指定すれば100件になる
display_count = chrome.find_element(by=By.ID, value='selline')
select = Select(display_count)
select.select_by_value('3')
IT系の採用情報だけでも10万件以上存在していたため、今回は簡易的に1000件(10ページ×100件)の採用情報を取得。
サーバーへ負荷をかけないようにtime.sleep() でリクエスト間隔を空けています。
import pandas as pd
from time import sleep
# 抽出したい項目のリストを予め作成
title =[]
company_name = []
salary = []
place = []
job_url = []
# 今回は10ページのみ
page_count = 1
while page_count <= 10:
all_job_titles = chrome.find_elements(by=By.CLASS_NAME,value='cpPDaA')
for all_job_title in all_job_titles:
title.append(all_job_title.text)
all_job_companies = chrome.find_elements(by=By.CLASS_NAME,value='kcpGrY')
for all_job_company in all_job_companies:
company_name.append(all_job_company.text.replace('(企業詳細)',''))
all_job_sals = chrome.find_elements(by=By.CSS_SELECTOR,value='div.gruhPk div.fBnySK')
for all_job_sal in all_job_sals:
salary.append(all_job_sal.text.split('\n')[0])
all_job_places = chrome.find_elements(by=By.CSS_SELECTOR,value='div.eTPXUu div.fBnySK')
for all_job_place in all_job_places:
place.append(all_job_place.text)
all_job_urls = chrome.find_elements(by=By.CLASS_NAME, value='bWMRyK')
for all_job_url in all_job_urls:
job_url.append(all_job_url.get_attribute('href'))
# 次ページに進むボタンをクリック
button = chrome.find_element(by=By.CLASS_NAME,value='clbcsT')
chrome.execute_script("arguments[0].click();", button)
page_count+= 1
sleep(2)
# 取得した情報を辞書型として格納
job_info={
'タイトル':title,
'企業名':company_name,
'給料':salary,
'勤務地':place,
'URL':job_url
}
# pandasでデータフレーム化
df = pd.DataFrame(job_info)
df
chrome.quit()
ちなみに1000件だけでなく、全ページ取得したい場合は以下のコードで取得できます。
while true:
~~~省略~~~
# 「次へ」ボタンがあるかチェックしてクリック
try:
button = chrome.find_element(By.CLASS_NAME, 'clbcsT')
chrome.execute_script("arguments[0].click();", button)
time.sleep(2)
except NoSuchElementException:
print("最終ページに到達しました")
break
3-4. CSVに保存
df.to_csv('job_info.csv',index=False)
出力したCSVは以下のようになっています。(企業名は一応黒塗りさせていただいてます)

4. 統計量の取得
4-1. 採用情報全件
年収の統計量を算出したいですが、データフレームに入れた段階だと、Object型になっています。また、「〇〇万円〜〇〇万円」「〇〇万円〜」というような2通りの記載方法があり、「万円」という文字も入っていることからこの状態では統計量の計算ができないため、以下の方法で対処します。
1.「万円」「1,000 など桁数区切りの ' , '」をreplace関数で削除
2.「〇〇万円〜〇〇万円」と幅がある時は平均値を取得
def salary_to_num(s):
s = s.replace("万円", "").replace(",","")
if "~" in s:
parts = s.split("~")
start = float(parts[0])
end = float(parts[1]) if parts[1] else start # 右側が空なら下限を使う #三項演算子
return (start + end) / 2
else:
return float(s)
df['給料_list'] = df['給料'].apply(lambda s:round(salary_to_num(s)))
# 主要な統計量を取得
df['給料_list'].describe()
以下が出力結果です。1000件の求人を取得し、平均年収は804万円、最大の年収は2250万円であることがわかります。

ちなみに最大の年収の採用情報を抽出したい場合は以下のコードを使用します。
#給料が最大値の行を抽出
max_index = df_sal.idxmax()
df.loc[[max_index]]
最大の年収の採用情報はインデックス136であり、自動で指定しています。
※1500万〜3000万のため、(1500+3000)/2=2250万円が最大年収となります。

4-2. 都道府県ごと
先ほどは抽出した採用情報1000件全体の統計量でした。今回は都道府県ごとに確認してみます。
また、今回も一工夫必要となります。3.で保存したCSVを確認してみると、都道府県の欄に複数入力されていることがわかります。このまま勤務地カラムを使用して集約すると、「東京、石川、北海道」という行が出力されてしまいます。
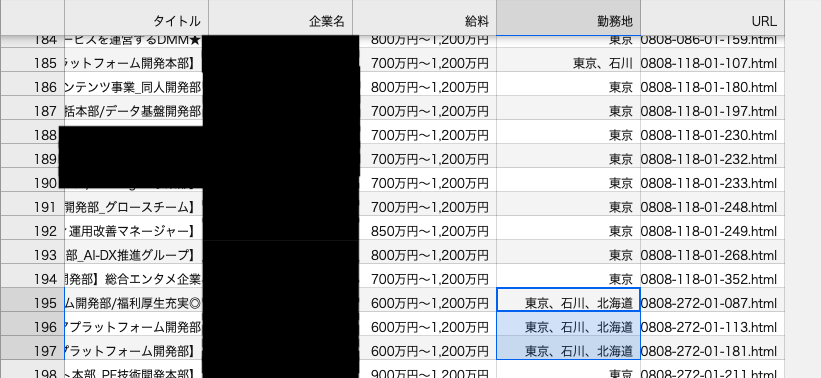
今回は勤務地が複数入力されている場合、分割して新たな行を作成するようにします。(「東京、石川、北海道」とある場合、東京の行、石川の行、北海道の行と3行に分割。)
タイトル、企業名、給料、URLは全て同じ内容が入るようにします。
#都道府県の分割
# 1. カンマで分割
df["勤務地_list"] = df["勤務地"].str.split("、")
# 2. explode で1行1勤務地に展開し、df_placeという新たなデータフレームを作成
df_place = df.explode("勤務地_list")
勤務地カラムを1行1勤務地にすることができたので、groupbyを用いて集計します。
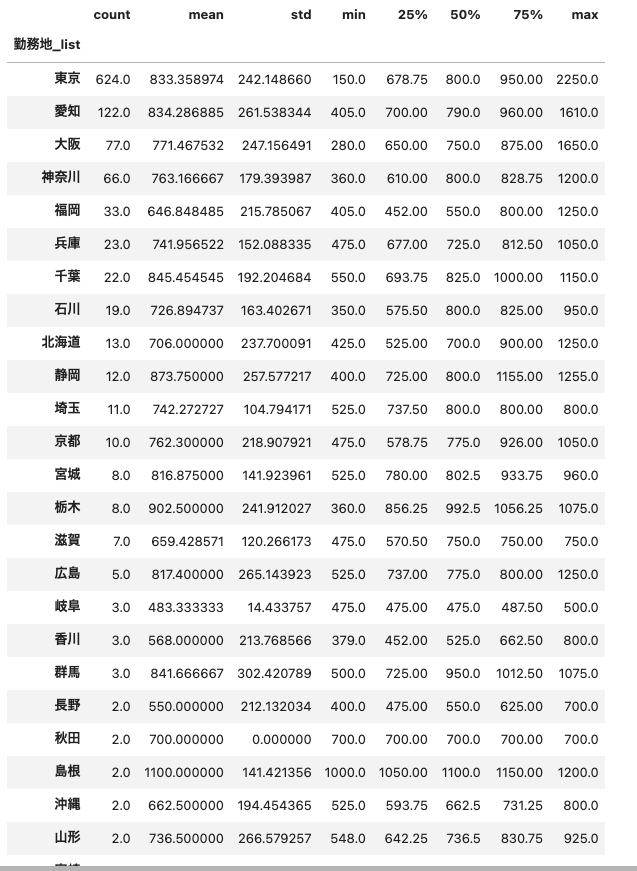
# 3. 都道府県ごとに統計量を集計
stats_by_pref = df_place.groupby("勤務地_list")["給料_list"].describe()
# 件数が多い順にソート
stats_by_pref.sort_values('count',ascending=False)
以下が出力結果です(一部省略)。東京、大阪、愛知、神奈川に求人が集中していることが分かりました。
5.スクレイピング②(ITスキル別の採用件数)
続いて、同じくリクルートエージェントを使用してITスキル別の採用件数を自動抽出していきます。
5-1. 対象サイトの構成確認
先ほどと同様、GoogleChromeの検証機能を使用し、取得したい情報のタグ、class名を予め整理しています。
url = 'https://www.r-agent.com/kensaku/skill-all/?gnav=gnavnew_kensaku_keyword'
title = class='kruepF'のtext
URL = class='jdEQv'のhref
件数 = urlの中のclass='jFTYIO'(最初の1つだけ)
5-2. 自動アクセス〜情報抽出
自動で抽出するために、一工夫が必要です。対象URLにアクセスすると以下キャプチャのように表示されます。ITスキルの情報を抽出するためには、「IT・システム開発」のバナーを選択する必要があります。

自動で選択するために以下のコードを用意します。対象クラスの要素を抽出し、「IT・システム開発」という文字列に一致したら、クリックするというコードになっています。
#IT・システム開発のタブをクリック
industries = chrome_skill.find_elements(by=By.CLASS_NAME,value='bJMUel')
target_industry = 'IT・システム開発'
for industry in industries:
if industry.text == target_industry:
industry.click()
break
ここから自動抽出していきます。IT・システム開発をみると大きく「言語・フレームワーク」「OS」「ソフトウェア」など複数に分かれています。今回は「言語・フレームワーク」のスキルのみを抽出するコードにしました。

イメージとしては「スキル名クリック→件数取得→スキル一覧ページに戻る→スキル名クリック→件数取得→・・・」という風に自動で画面遷移して件数を取得します。
skill_name = []
skill_count = []
skill_links = chrome_skill.find_elements(By.XPATH, "//div[p/text()='言語・フレームワーク']//a[@class='jdEQv']")
for skill_link in skill_links:
skill_name.append(skill_link.text)
skill_link.click()
#後で件数を数値として使用できるように,はreplace関数で削除し、int型にしておきます。
skill_count.append(int(chrome_skill.find_element(by=By.CLASS_NAME,value='jFTYIO').text.replace(",","")))
chrome_skill.back()
sleep(2)
# df_skillという辞書を作成
df_skill = ({
'スキル名':skill_name,
'件数':skill_count
})
5-3. CSVに保存、CSVから読み込み
df_skillというデータフレームを作成し、csvを作成します。
df_skill = pd.DataFrame(df_skill)
df_skill.to_csv('skill_count.csv', index=False)
せっかくなので練習も兼ねて作成したcsvから新たなデータフレームを作成してみます。
また、件数が多い順にソートして、上書きします。
import matplotlib.pyplot as plt
df_skill_csv = pd.read_csv('skill_count.csv')
# inplace=Trueとすることで、ソートした状態でdf_skill_csvを上書きします
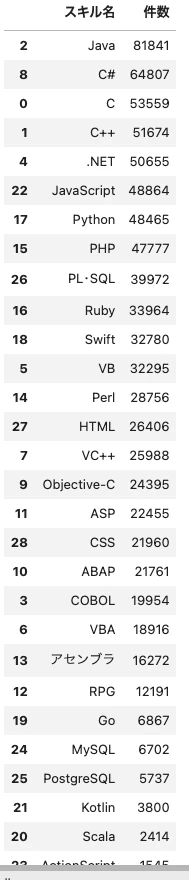
df_skill_csv.sort_values('件数',ascending=False, inplace=True)
df_skill_csv
以下出力結果です。Javaの求人めっちゃ多いですね。
5-4. pandas × matplotlibを用いたデータ可視化
最後のアウトプットです。得られたスキルごとの件数を棒グラフで表示してみます。
# フォントとグラフサイズの設定
plt.rcParams['font.family'] = 'Arial Unicode MS' #windowsの方は'MS Gothic'
# 図の大きさ
plt.rcParams["figure.figsize"] = [8, 6] # 単位はインチ
# フォントサイズ
plt.rcParams['font.size'] = 17
# 軸ラベルの大きさ
plt.rcParams['xtick.labelsize'] = 15
plt.rcParams['ytick.labelsize'] = 15
df_skill_csv.plot.bar("スキル名", legend=False)
plt.xlabel('スキル名')
plt.ylabel('件数')
plt.title('スキル別求人件数')
以下出力結果です。数字で見るより、求人件数の違いが明確に分かりますね。

まとめ
ここまでご覧いただきありがとうございました。今回はpython,pandas,seleniumを使用して採用情報の自動抽出と統計量取得を実践してみました。今回はできませんでしたが、発展的な内容として以下も面白そうです。
- スキル×勤務地のクロス集計
- 定期スクレイピング → 時系列データを蓄積 →「毎週のスキル需要推移」
- Excel / Googleスプレッドシートに自動出力
- 「地域×スキル需要」を地図上に可視化
初めてのアウトプット・Qiita記事投稿でしたがたくさん詰まり、たくさん悩んで、たくさんスッキリして、、といろんな経験ができました。今後も継続的にアウトプットしていきたいなと思います!