先日,言語処理100本ノック2020が公開されました.私自身,自然言語処理を初めてから1年しか経っておらず,細かいことはよくわかっていませんが,技術力向上のために全ての問題を解いて公開していこうと思います.
すべてjupyter notebook上で実行するものとし,問題文の制約は都合よく破っていいものとします.
ソースコードはgithubにもあります.あります.
3章はこちら.
環境はPython3.8.2とUbuntu18.04です.
第4章: 形態素解析
夏目漱石の小説『吾輩は猫である』の文章(neko.txt)をMeCabを使って形態素解析し,その結果をneko.txt.mecabというファイルに保存せよ.このファイルを用いて,以下の問に対応するプログラムを実装せよ.
必要なデータセットはここからダウンロードしてください.
ダウンロードしたファイルはdata以下に置くものとします.
MeCabを使った形態素解析
mecab < data/neko.txt > data/neko.txt.mecab
こんな感じの中身のファイルが得られます
一 名詞,数,*,*,*,*,一,イチ,イチ
EOS
EOS
記号,空白,*,*,*,*, , ,
吾輩 名詞,代名詞,一般,*,*,*,吾輩,ワガハイ,ワガハイ
は 助詞,係助詞,*,*,*,*,は,ハ,ワ
猫 名詞,一般,*,*,*,*,猫,ネコ,ネコ
で 助動詞,*,*,*,特殊・ダ,連用形,だ,デ,デ
ある 助動詞,*,*,*,五段・ラ行アル,基本形,ある,アル,アル
。 記号,句点,*,*,*,*,。,。,。
30. 形態素解析結果の読み込み
形態素解析結果(neko.txt.mecab)を読み込むプログラムを実装せよ.ただし,各形態素は表層形(surface),基本形(base),品詞(pos),品詞細分類1(pos1)をキーとするマッピング型に格納し,1文を形態素(マッピング型)のリストとして表現せよ.第4章の残りの問題では,ここで作ったプログラムを活用せよ.
MeCabの出力の各行から,表層形,基本形,品詞,品詞細分類1を取り出す関数を用意します.
文末に当たった時にNoneを返します.
def line_to_dict(line):
line = line.rstrip()
if line == 'EOS':
return None
lst = line.split('\t')
pos = lst[1].split(',')
dct = {
'surface' : lst[0],
'pos' : pos[0],
'pos1' : pos[1],
'base' : pos[6],
}
return dct
MeCabの出力を上記関数の出力のリストに変換していきます.
def mecab_to_list(text):
lst = []
tmp = []
for line in text.splitlines():
dct = line_to_dict(line)
if dct is not None:
tmp.append(dct)
elif tmp:
lst.append(tmp)
tmp = []
return lst
with open('data/neko.txt.mecab') as f:
neko = mecab_to_list(f.read())
[[{'surface': '一', 'pos': '名詞', 'pos1': '数', 'base': '一'}],
[{'surface': '\u3000', 'pos': '記号', 'pos1': '空白', 'base': '\u3000'},
{'surface': '吾輩', 'pos': '名詞', 'pos1': '代名詞', 'base': '吾輩'},
{'surface': 'は', 'pos': '助詞', 'pos1': '係助詞', 'base': 'は'},
{'surface': '猫', 'pos': '名詞', 'pos1': '一般', 'base': '猫'},
{'surface': 'で', 'pos': '助動詞', 'pos1': '*', 'base': 'だ'},
{'surface': 'ある', 'pos': '助動詞', 'pos1': '*', 'base': 'ある'},
{'surface': '。', 'pos': '記号', 'pos1': '句点', 'base': '。'}],
[{'surface': '名前', 'pos': '名詞', 'pos1': '一般', 'base': '名前'},
{'surface': 'は', 'pos': '助詞', 'pos1': '係助詞', 'base': 'は'},
{'surface': 'まだ', 'pos': '副詞', 'pos1': '助詞類接続', 'base': 'まだ'},
{'surface': '無い', 'pos': '形容詞', 'pos1': '自立', 'base': '無い'},
{'surface': '。', 'pos': '記号', 'pos1': '句点', 'base': '。'}]]
31. 動詞
動詞の表層形をすべて抽出せよ.
surfaces_of_verb = {
dct['surface']
for sent in neko
for dct in sent
if dct['pos'] == '動詞'
}
for _, verb in zip(range(10), surfaces_of_verb):
print(verb)
print('合計:', len(surfaces_of_verb))
自惚れ
湧き出
膨れ
放さ
遊ぶ
至ら
持ち切っ
よごれ
あたる
働い
合計: 3893
32. 動詞の原形
動詞の原形をすべて抽出せよ.
bases_of_verb = {
dct['base']
for sent in neko
for dct in sent
if dct['pos'] == '動詞'
}
for _, verb in zip(range(10), bases_of_verb):
print(verb)
print('合計:', len(bases_of_verb))
すく
消え去る
遊ぶ
明ける
引き立つ
あたる
あらわれる
あせる
填める
振れる
合計: 2300
33. 「AのB」
2つの名詞が「の」で連結されている名詞句を抽出せよ.
def tri_grams(sent):
return zip(sent, sent[1:], sent[2:])
def is_A_no_B(x, y, z):
return x['pos'] == z['pos'] == '名詞' and y['base'] == 'の'
A_no_Bs = {
''.join([x['surface'] for x in tri_gram])
for sent in neko
for tri_gram in tri_grams(sent)
if is_A_no_B(*tri_gram)
}
for _, phrase in zip(range(10), A_no_Bs):
print(phrase)
print('合計:', len(A_no_Bs))
tri-gramを取って,「名詞 + の + 名詞」となるものだけを抜き出します.リスト内包記法で2重ループを回しています.
僕の所
鮪の切身
家の芽生
代目の王様
牛込の山伏
左の問答
猫の足
人の来客
個の老人
以外のもの
合計: 4924
34. 名詞の連接
名詞の連接(連続して出現する名詞)を最長一致で抽出せよ.
def longest_nouns(sent):
lst = []
tmp = []
for dct in sent:
if dct['pos'] == '名詞':
tmp.append(dct['surface'])
else:
if len(tmp) > 1:
lst.append(tmp)
tmp = []
return lst
noun_chunks = [
''.join(nouns)
for sent in neko
for nouns in longest_nouns(sent)
]
for _, chunk in zip(range(10), noun_chunks):
print(chunk)
print('合計:', len(noun_chunks))
文ごとにループを回して,名詞が連続する部分を抜き出していきます.名詞1つだけの出現は連接とみなしませんでした.
人間中
一番獰悪
時妙
一毛
その後猫
一度
ぷうぷうと煙
邸内
三毛
書生以外
合計: 7335
35. 単語の出現頻度
文章中に出現する単語とその出現頻度を求め,出現頻度の高い順に並べよ.
from collections import Counter
surfaces = [
dct['surface']
for sent in neko
for dct in sent
]
cnt = Counter(surfaces).most_common()
for _, (word, freq) in zip(range(10), cnt):
print(word, freq)
Counterで数を数えただけですね.
の 9194
。 7486
て 6868
、 6772
は 6420
に 6243
を 6071
と 5508
が 5337
た 3988
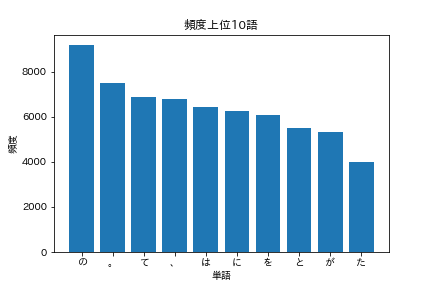
36. 頻度上位10語
出現頻度が高い10語とその出現頻度をグラフ(例えば棒グラフなど)で表示せよ.
import matplotlib.pyplot as plt
import japanize_matplotlib
matplotlibを使っていきたいですが,これだけだと日本語がうまく表示されません.japanize_matplotlibをインポートするとなんかうまくいきます.
words = [word for word, _ in cnt[:10]]
freqs = [freq for _, freq in cnt[:10]]
plt.bar(words, freqs)
plt.title('頻度上位10語')
plt.xlabel('単語')
plt.ylabel('頻度')
plt.show()
下のようなグラフが表示されるはずです.
37. 「猫」と共起頻度の高い上位10語
「猫」とよく共起する(共起頻度が高い)10語とその出現頻度をグラフ(例えば棒グラフなど)で表示せよ.
"共起"する単語は同じ文に現れる単語としてみます.
co_occured = []
for sent in neko:
if any(dct['base'] == '猫' for dct in sent):
words = [dct['base'] for dct in sent if dct['base'] != '猫']
co_occured.extend(words)
cnt = Counter(co_occured).most_common()
for _, (word, freq) in zip(range(10), cnt):
print(word, freq)
の 391
は 272
、 252
に 250
を 232
だ 231
て 229
。 209
と 202
が 180
正直助詞ばかりでつまらないので,品詞を制限してみます.
co_occured = []
for sent in neko:
if any(dct['base'] == '猫' for dct in sent):
words = [
dct['base']
for dct in sent
if dct['base'] != '猫'
and dct['pos'] in {'名詞', '動詞', '形容詞', '副詞'}
]
co_occured.extend(words)
cnt = Counter(co_occured).most_common()
for _, (word, freq) in zip(range(10), cnt):
print(word, freq)
する 144
* 63
事 59
吾輩 58
いる 58
ある 55
の 55
人間 40
ない 39
云う 38
せっかくなので,猫と人間が共起する文をいくつか見てみます.
for sent in neko[:1000]:
if any(dct['base'] == '猫' for dct in sent) and any(dct['base'] == '人間' for dct in sent):
lst = [dct['surface'] for dct in sent]
print(''.join(lst))
白君は涙を流してその一部始終を話した上、どうしても我等猫族が親子の愛を完くして美しい家族的生活をするには人間と戦ってこれを剿滅せねばならぬといわれた。
しかし人間というものは到底吾輩猫属の言語を解し得るくらいに天の恵に浴しておらん動物であるから、残念ながらそのままにしておいた。
ちょっと読者に断っておきたいが、元来人間が何ぞというと猫々と、事もなげに軽侮の口調をもって吾輩を評価する癖があるははなはだよくない。
人間の糟から牛と馬が出来て、牛と馬の糞から猫が製造されたごとく考えるのは、自分の無智に心付かんで高慢な顔をする教師などにはありがちの事でもあろうが、はたから見てあまり見っともいい者じゃない。
よそ目には一列一体、平等無差別、どの猫も自家固有の特色などはないようであるが、猫の社会に這入って見るとなかなか複雑なもので十人十色という人間界の語はそのままここにも応用が出来るのである。
こんなところを見ると、人間は利己主義から割り出した公平という念は猫より優っているかも知れぬが、智慧はかえって猫より劣っているようだ。
主人のように裏表のある人間は日記でも書いて世間に出されない自己の面目を暗室内に発揮する必要があるかも知れないが、我等猫属に至ると行住坐臥、行屎送尿ことごとく真正の日記であるから、別段そんな面倒な手数をして、己れの真面目を保存するには及ばぬと思う。
38. ヒストグラム
単語の出現頻度のヒストグラム(横軸に出現頻度,縦軸に出現頻度をとる単語の種類数を棒グラフで表したもの)を描け.
words = [
dct['base']
for sent in neko
for dct in sent
]
cnt = Counter(words).most_common()
freqs = [freq for _, freq in cnt]
plt.title('ヒストグラム')
plt.xlabel('単語')
plt.ylabel('頻度')
plt.hist(freqs, bins=100, range=(1,100))
plt.show()

39. Zipfの法則
単語の出現頻度順位を横軸,その出現頻度を縦軸として,両対数グラフをプロットせよ.
plt.title('Zipfの法則')
plt.xlabel('単語')
plt.ylabel('頻度')
plt.xscale('log')
plt.yscale('log')
plt.plot(range(len(freqs)), freqs)
plt.show()
それっぽい図になっていますね.
