GxPのやすば(@nyasba)です。
本記事はグロースエクスパートナーズアドベントカレンダー 8日目の記事です。
はじめに
近年、AIによるコード生成を前提とした開発スタイルに切り替わってきました。社内でもAIエージェントを活用して、生産性を高めていこうという取り組みを積極的に行っています。
そうした中で、従来のアプリケーションアーキテクチャの意図を想定せずにそのままAIエージェントによる実装を当てはめようとして、うまくいかないケースを見かけることもあります。そこで、AIエージェントを効果的に活用するためにはどのような考え方が必要なのか、一度整理しておこうと思いこの記事を書きました。
実装経験の少ないエンジニアの方や、今までアプリケーションアーキテクチャを意識したことない方には特に読んでいただきたいです。
今までの開発で重視してきたこと
📝 1. 業務ドメインに沿ったコードを書く
- 業務用語に沿った変数名を使う
- 実際の業務で使われている言葉をそのまま変数名・関数名に採用する
- 業務の考え方そのままでロジックを書く
- 業務フローの順序や判断基準を、そのままコードに落とし込む
例: 「1週間以下」と「8日未満」は、結果は同じでも意味が違う - “コード用の抽象化”より“業務の実態”を優先
- 業務フローの順序や判断基準を、そのままコードに落とし込む
🏗️ 2. 決められたアプリケーションアーキテクチャに従う
- Domain層は業務ロジックの中心
- 業務ロジックは Domain に集約する
- Domain は他層(DB、API、UI)に依存しない
- Infrastructure層(backend)は外部I/O専用
- DBアクセス、外部API呼び出しなど
→ Domain と物理世界をつなぐ場所
- DBアクセス、外部API呼び出しなど
- Frontend は Container Component / Presentational Component に分離
- Container Component: データ取得・状態管理・アプリケーションロジック
- Presentational Component: UI描画、ビジュアル、ユーザー操作イベント
→ UIとロジックの境界が明確でAI生成も安定
🧪 3. 決められたテスト戦略に沿ってテストを書く
- 各レイヤーの特性に合ったテストを設計
- Domain → ピュアロジックなので Unit Test が書きやすい
- Infrastructure → 外部依存があるので Integration Test
- Serviceロジック → Infrastructure層依存はMockにした Test
- API → Contract Test や E2E Test
--
これらを徹底することで、チームの中で何をどこに実装されているかの共通認識が持て、保守性も高くなります。コードが構造化されて作られているため、タスクを分割して並行で開発することもできるようになります。
Springバックエンドサーバのアプリケーションアーキテクチャについて以前書いた記事も参考に紹介しておきます。
Spring+DDDでのアプリケーションアーキテクチャとテスト戦略
AIに実装させるために
ここから本題です。
AIに実装させる際の課題、その対策について紹介します。
🧩 事前にレイヤー間の境界を明確に定義する
極端な例ですが、以下のようなアーキテクチャを採用している場合に、「API作って」という雑な依頼をしても、あまり効果的な結果は得られません。もちろん、コンテキストを正しく与えることでうまくいくケースもあるとは思います。
オレンジの枠の全てを丸ごとAIに依頼すると、守らなければいけないアプリケーションアーキテクチャをAI任せにしてしまうことになります。

API全体を実装するためには、下図の青い枠の単位でAIに取り組ませたほうが、こちらの意図に近いものになりやすいです。
Repository のインターフェース、ドメインモデルの構造などを、あらかじめ青い枠の単位で IN/OUT をある程度決めてから、AIエージェントに指示を出すイメージです。
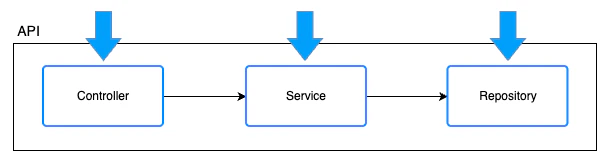
従来の開発スタイルでも、タスクを分割してチームで分担して進めるときには、このような考え方で進めていたと思います。自分で実装をしない場合であっても、こういったアプリケーションアーキテクチャの境界を設計し、その単位で指示を出す力がより重要になってきている、という点です。
この境界を明確にする作業を Planモード(まずは設計や計画だけをAIにさせるモード) として実行しても良いと思います。事前に全体構造の実装計画をPlanモードで計画して、それに応じて青い枠の単位で開発するのであれば精度が高まります。
⚙️ AI実装時に適したアーキテクチャに見直す
ただ、AI実装したときに常にこれらの考え方が最適とは限りません。
Repository を正しく再利用するのであればこの構造は適しているかもしれませんが、作りたいものごとに Repository を追加していくようなスタイルであれば、あまり既存のやり方にこだわらず、見直していくべきです。
例えば、CQRS でのクエリのように「データを取得するだけ」の構成の場合、AIへの指示はこのくらいです。
「INPUTをもとにこのSQLを実行してデータを取得してほしい」
その場合は、例えば Controller 層の中でデータ取得を行い、ドメインクラスを用いずにレスポンスを返却するような構成にしておくことで、AI実装の精度が高くなります。

結果として、AIとは関係なく CQRS の説明そのままになってしまいましたが、ここで言いたいのは、 「作りたいものをシンプルに言語化した内容」 がそのまま対応したコードに落とし込めるようにしておく ことが重要、という点です。
間に境界が多すぎると、
- ここ用のDTOを定義して…
- このUseCase用にインターフェースを切って…
- そのためのRepositoryメソッド名を…
と、AIに説明しないといけないことがどんどん増えていきます。
「境界をキレイに引くこと」が目的化していないか、一度立ち止まって、AI実装に適したアプリケーションアーキテクチャを見直していきましょう。
🧑💼 業務的な概念は人が指示・判断する
最後に業務面についてです。
基本的に、AIはコンテキストで渡した情報の中から正しそうな回答を返しているだけですので、 業務的な概念は自動的には反映されません。
- ファイル名・クラス名・関数名の命名規則
- 「この業務ではこの言葉はこう使う」といった前提
- 「この条件は絶対に外してはいけない」ような暗黙知
といったものは、プロンプトで指示された内容をベースに作られます。
業務的なことをすべてコンテキストで渡すことも難しいですし、「業務的にここはちゃんと考慮してね」とふわっとした指示をしても思い通りにはなりません。
結局は以下のような具体的な 手段 を指示する形になっていきます。
- このロジックはこことは違うから個別に分けておいて
- このドメインにメソッド切って持たせて
- Repositoryのメソッド名はこういう名前にして
私の場合、これらはいずれも機能的な部分が一通りできてから、リファクタリングとして修正することが多いです。リモートエージェントに実装させている場合は、この部分で結構やり取りが発生するので、理想との差が大きいと感じたときは、自分の手でまとめて修正してしまうこともあります。
やはり、2025年末時点では、業務的な概念に合わせて保守性高くコードを保つ「最後の砦」は人だと思っています。
AIが業務の「文脈」まで自然に理解してくれる世界は、まだもう少し先で、少なくとも今は 「業務を知っている人が、AIを使ってコードを書く」 構図のほうが現実的です。
まとめ
記事を書きながら徐々に気付いてきましたが、「AI実装時にこそ特別に重要」な話というより、もともと普通に重要だった話でもあります。ただ、AI活用の方法を模索するときこそ、こうした基本を理解し、意識的に実行していくことが大事だと思います。
システムを長く保守していく場合は、VibeCoding のようなブラックボックスなアプローチではなく、型を明確にしてそれに沿って作るのが現実的なアプローチです。
そして、AI実装で効果を上げるために、 「何をINPUTにどんな指示を出すか、その結果どんなOUTPUTを期待するか」 の設計をしましょう。指示しないことは、基本的には考慮されません。
ただ、経験の浅いエンジニアにとっては、以前は言語化されておらず理解しづらかった概念が、AIへ指示するために言語化されることで、理解を深めるチャンスになるかもしれません。
業務面のバックグラウンドを活かして、AIよりも高い価値を出していきましょう💪