環境
ubuntu 18.04 LTS
hadoop-3.2.1
参考サイト
- https://qiita.com/Esfahan/items/39fd1e2f8b755eacec65
- https://qiita.com/taketarouex/items/3e3f625af82016ef1287
- https://qiita.com/ksnt/items/b204d3fa30fb3cb86a06
- https://www.ydc.co.jp/solution/standby/article/nosql_6.html
- https://ameblo.jp/g-pinchan-new/entry-11880255551.html
手順
1.Java8のインストール
HiveはJava8じゃないと動かない気がしたのでjava8にしといた。
この記事だと
OracleJDKいれてるが面倒そうだし、OpenJDKでも大丈夫でしょとおもったのでOpenJDKした。
$ sudo apt update -y
$ sudo apt upgrade -y
$ sudo apt install openjdk-8-jdk -y
$ /usr/lib/jvm/java-8-openjdk-amd64/bin/java -version
openjdk version "1.8.0_252"
OpenJDK Runtime Environment (build 1.8.0_252-8u252-b09-1~18.04-b09)
OpenJDK 64-Bit Server VM (build 25.252-b09, mixed mode)
2.必要なパッケージのインストール
sshとrsyncが必要みたいなので入れる。
$ sudo apt install ssh rsync -y
3.hadoopユーザ作成と鍵の設定などする
ユーザ作成と鍵作成
$ sudo adduser hadoop
$ su - hadoop
$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ chmod 0600 ~/.ssh/authorized_keys
接続確認
$ ssh localhost
$ exit
実際にhdoopを利用するユーザにの~/.sshに鍵をコピー
※usernameは自分の利用しているユーザ
$ sudo cp -r /home/hadoop/.ssh ~/
$ sudo chown -R username:username ~/.ssh
$ ssh hadoop@localhost
$ exit
4.hadoopインストール
ここからをダウンロード
tar zxvf /home/username/Dowoload/hadoop-3.2.1.tar.gz
mv ./hadoop-3.2.1 ./hadoop
mv ./hadoop /usr/local/
5.環境変数設定
bashrcとbash_profileとかに環境変数追加する
※自分はzsh使用しているため、zprofileに追加した
※あとでHiveも入れるので、Hiveの環境変数も入っている
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:~/.local/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$HIVE_HOME/bin
編集したファイルを読み込む
$ . ~/.zprofile
6.設定ファイルを編集
- hadoop-env.sh
$ vi $HADOOP_HOME/etc/hadoop/hadoop-env.sh
最終行に以下を挿入
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
$HADOOP_HOME/etc/hadoop/に移動し、各種設定ファイルを編集
$ cd $HADOOP_HOME/etc/hadoop/
core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/tmp/hdfs/hadoop/hadoopdata/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/tmp/hdfs/hadoop/hadoopdata/hdfs/datanode</value>
</property>
</configuration>
mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<name>mapreduce.application.classpath</name>
<value>
/usr/local/hadoop/etc/hadoop,
/usr/local/hadoop/share/hadoop/common/*,
/usr/local/hadoop/share/hadoop/common/lib/*,
/usr/local/hadoop/share/hadoop/hdfs/*,
/usr/local/hadoop/share/hadoop/hdfs/lib/*,
/usr/local/hadoop/share/hadoop/mapreduce/*,
/usr/local/hadoop/share/hadoop/mapreduce/lib/*,
/usr/local/hadoop/share/hadoop/yarn/*,
/usr/local/hadoop/share/hadoop/yarn/lib/*
</value>
</property>
</configuration>
※mapreduce.application.classpathを指定しておかないと以下のエラーがでる。正直、値自体は間違っていてる状態で動いた。何だろ。
この記事を参考にした。
エラー: メイン・クラスorg.apache.hadoop.mapreduce.v2.app.MRAppMasterが見つからなかったかロードできませんでした
yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
7.hdfs format
$ hdfs namenode -format
8.hadoop起動
拝見した記事ではだいたい分けて起動していたが、これでいいと思う
$ start_all.sh
$ jps
23297 DataNode
23057 NameNode
24003 NodeManager
23575 SecondaryNameNode
3722 war
23820 ResourceManager
3484 Jps
このプロセス郡が確認できたら起動は問題ない。
このあたりではまったのが、Datanodeが起動しない問題・・・
このブログを参考にしてみた。
自分の理解はdatenodeは常に起動のタイミングでユニークなIDを振られるので、
そのIDとディレクトリ名が一致しないと起動できない・・みたいなことだと思う。
なので以下の対処をする。
$ stop_all.sh ## hadoop止める
$ sudo rm -rf /tmp/hadoop* ## hadoop_usernameみたいなディレクトリを削除
$ sudo rm -rf /tmp/hdfs/* ## 自分が指定したhdoopのディレクトリの中身を削除
$ start_all.sh
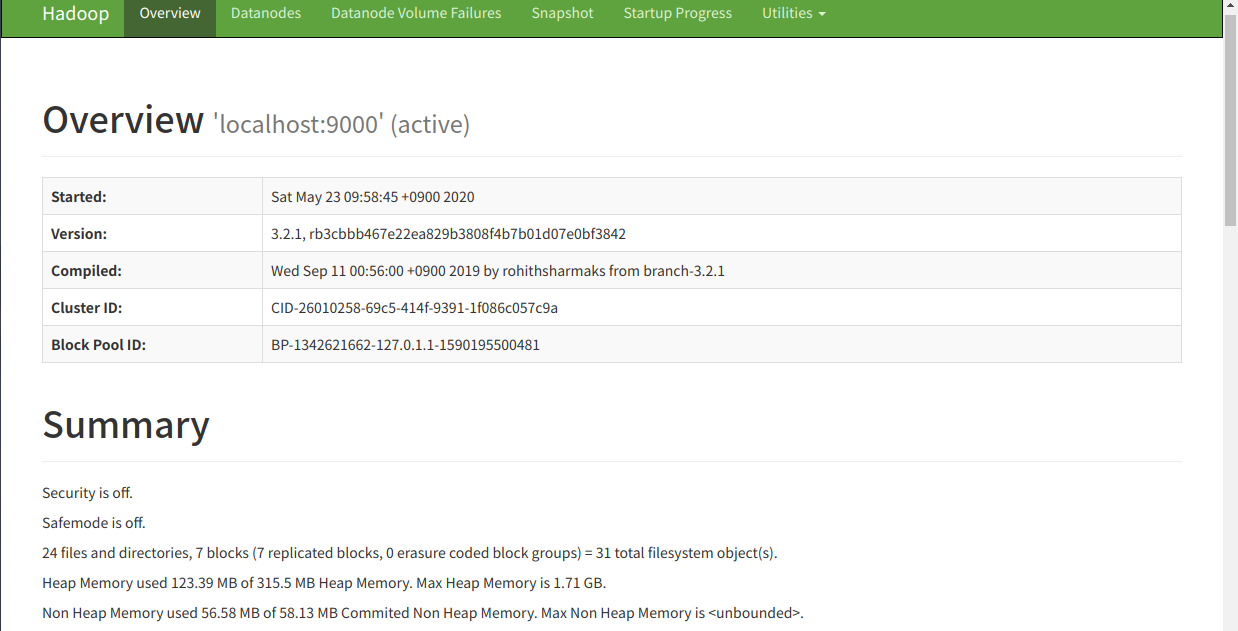
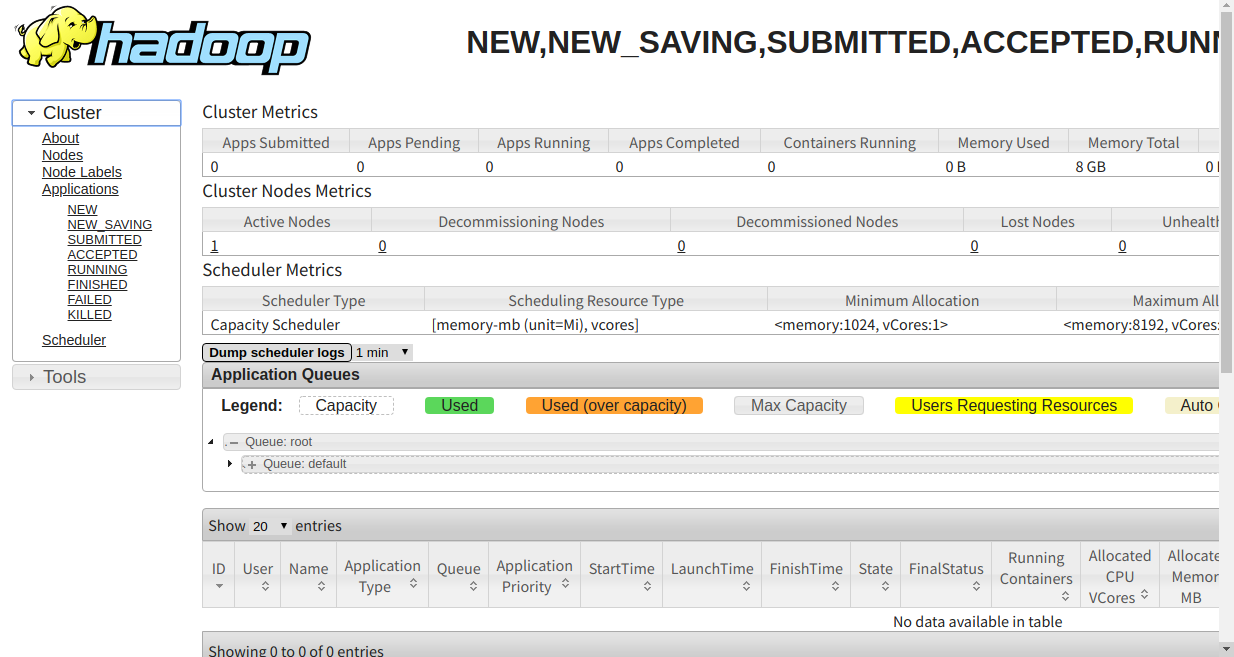
管理画面に接続してみる
実際に動かしてみるのは次回の記事で書いてみようと思う