はじめに
データベースも知らないよちよち歩きでBigQueryに触り始めたので、今後やりたいことの備忘録がてらTipsを共有していきます。
SQL自体も勉強しながらやりくりしていますので有識者様のマサカリを歓迎します。
やりたいこと
下図のように日付とセンサ値、その他情報が入ったテーブルがあるとします。
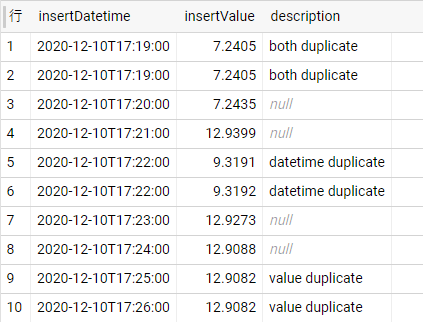
使用しているIoTセンサがチープなもので、同じ時刻で異なる情報が送られてくる仕様を想像してください。
今後の集計作業に邪魔になるため、日付の重複を検知してその行を削除するような前処理の実装を考えます。
※ 行1, 2と行5, 6がそれぞれ今回の重複判定対象となります。
重複判定処理
単純な列指定
SELECT DISTINCT insertDatetime
FROM `project.dataset.table`
ORDER BY insertDatetime;
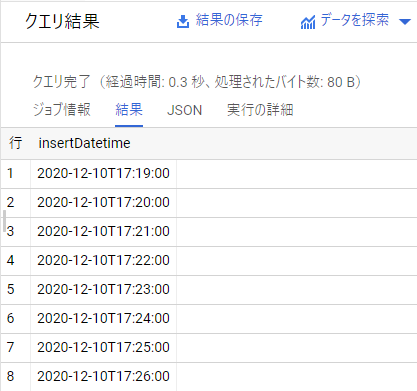
まずは一番単純な DISTINCT column_name です。
重複判定に用いるカラム名を指定すれば日付の重複は確かに消えていますが、他に参照したいセンサ値たちが取れていません。
取得したい列全てを指定
SELECT DISTINCT *
FROM `project.dataset.table`
ORDER BY insertDatetime;
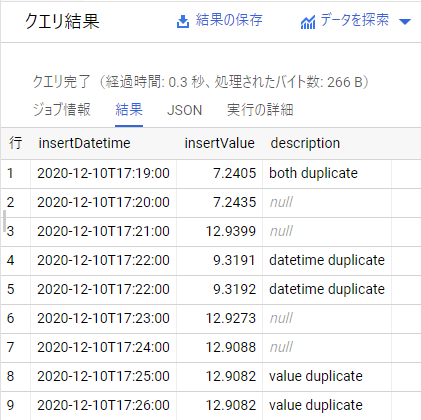
取得したいのは全てのカラムなので、今度はDISTICT *を指定します。
挙動としてはDISTINCTの対象が全てのカラムになるため、全てのカラムが同じ値である行1が消えました。
惜しいですが、行4も消えてほしいためまだ満足できません。
行番号を用いて参照
WITH indexing AS (SELECT *, ROW_NUMBER() OVER(ORDER BY insertDatetime) AS refId FROM `project.dataset.table`)
SELECT * EXCEPT(refId) FROM indexing
WHERE refId in (SELECT max(refId) FROM indexing GROUP BY insertDatetime)
ORDER BY insertDatetime;
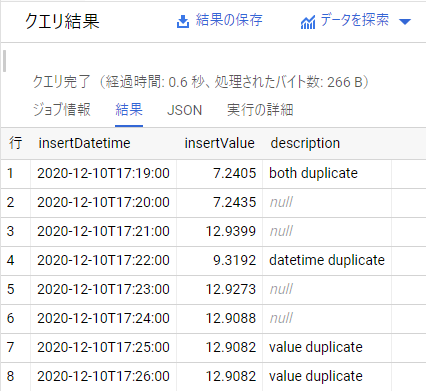
手間が一気に増えましたが、やったことは「行番号を用いて重複していない行のみを抽出する」というものです。
WITH indexing AS (SELECT *, ROW_NUMBER() OVER(ORDER BY insertDatetime) AS refId FROM `project.dataset.table`)
refIdという行番号を示す列を新たに作成します。
WITHを用いて元のデータと行番号列を一時保存しておきます。
(WITHでできるものは何なのでしょうか…… 共通テーブル?一時テーブル?ビュー?)
SELECT * EXCEPT(refId) FROM indexing
WHERE refId in (SELECT max(refId) FROM indexing GROUP BY insertDatetime)
ORDER BY insertDatetime;
重複対象となるinsertDatetimeをGROUP BYで指定し、該当する最大行 (=最新値) をサブクエリで取得します。
古い方を残したい場合はMIN(refId)で良いですね。
あとはサブクエリで抽出した行をWITHで保存した結果からSELECT WHEREで指定すれば、日付が重複する行を除去した全列データが取得できます (refIdは処理用に設けただけなのでEXCEPTで除いています) 。
クエリ結果を見ても、行1と行4が消えて欲しい形で参照できていることが分かります。
終わりに
MySQLの場合はDISTINCT ON(column)で本記事と同じことができるとかなんとか。
リファレンスを読みましたがこれに該当する操作はBigQueryには無さそうだったので情報共有を兼ねて本記事を書きました。
私と同じような初学者の助けになれば幸いです。
もう少しスマートに書けるなら教えてくれると嬉しいです。