はじめに
最近、コードの構造を扱うツールとして ast-grep と ts-morph を知りました。
これらを使って「API のバリデーションを可視化するツール」を作ってみたので、
設計・実装の前後半に記事を分けて、その過程をまとめていきます。
上記のツールを組み合わせることで「構文」と「意味」の両方を扱える点が面白く、
以下のような実務の課題解決にも応用できそうだと感じました。
- ドキュメントで管理しようとすると、更新・管理コストが高く、実態と乖離しやすい
- Swagger だけでは、実際のバリデーションロジックが仕様として表現されない
- コードを正とするだけでは実装の中に埋もれてしまい、可読性が低い
こうした課題に対しては、
「コードを正として、ドキュメントを自動生成する」アプローチが有効だと考えています。
そこで今回は、Express で実装された API コードからバリデーション情報を抽出し、
非エンジニアでも読みやすい形に整理・整形するツールを作成してみました。
作成にあたり、以下を目標として設定しました。
- バリデーション条件を解析して、エンドポイント単位で整理する
- 非エンジニアでも理解できる形に変換し、HTML ドキュメントとして出力する
本記事では、こうした課題をどのように分解し、ast-grep と ts-morph を組み合わせることで解決を目指したのか、
そして、それらを踏まえたツール設計について解説していきます。
実際のコードを交えた実装の考え方やツールの評価については、次回記事で取り上げる予定のため、ここでは触れません。
1. 作成するツールの概要
「バリデーション可視化ツール」のプロトタイプを作成します。
概要
TypeScript で実装された API コードを入力として、各エンドポイントごとのバリデーション情報を抽出し、
人間が読みやすい形式に整形した HTML ドキュメントとして出力します。
- 入力:TypeScript で実装された API コード(Express)
- 出力:バリデーション情報をまとめた HTML ドキュメント
目標
このツールでは、主に以下の点を実現することを目標とします。
- エンドポイント単位でバリデーションを一覧化できる
- 各フィールドの 必須/任意 が一目で分かる
- バリデーションの内容を自然な日本語で表現する
- 非エンジニアでも理解できる形で情報を整理する
具体的には、例えばこのようなコードがあった場合、
body("title").notEmpty().isLength({ min: 1, max: 200 })
以下のように変換されるイメージです。
title:必須、1文字以上200文字以内
このように、実装として書かれているバリデーションロジックを「仕様としてそのまま利用できる形」に変換することを目指します。
出力イメージ
実際には、以下のような形式で HTML として出力されます。
まずは全体のイメージです。
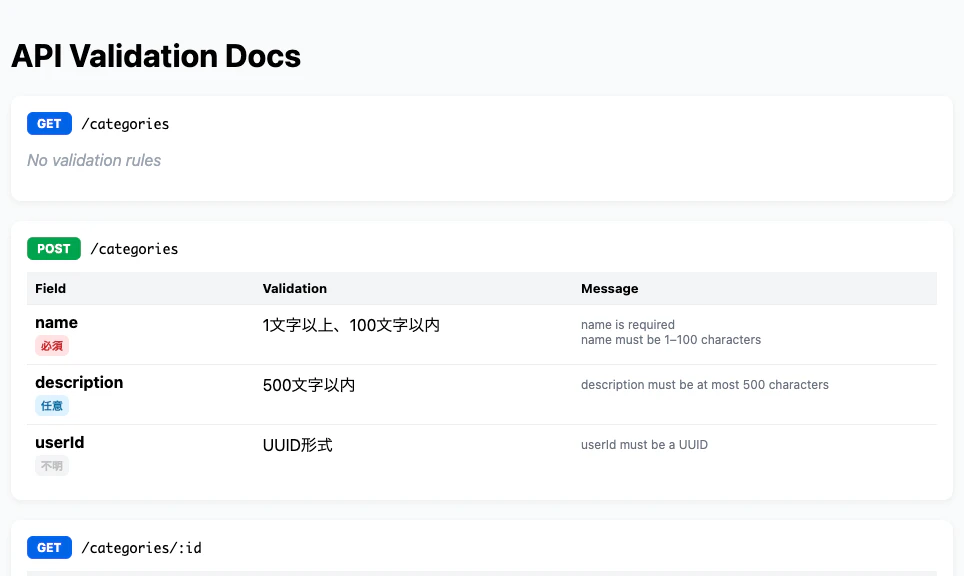
次に、個別のエンドポイントの詳細イメージです。
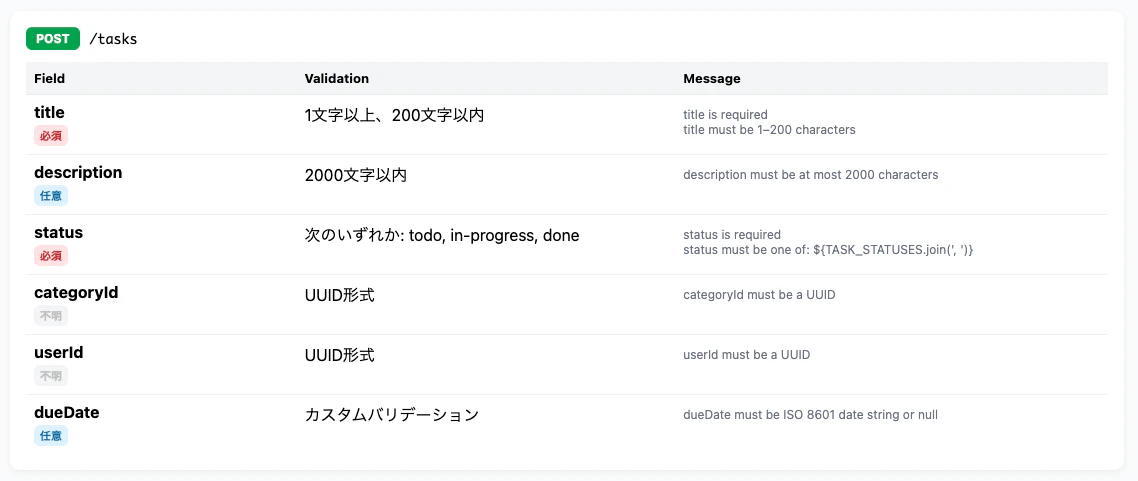
フィールド名、必須/任意、バリデーション内容が一覧で確認でき、
エンドポイントごとの仕様を一目で把握できるようになっています。
本記事で扱う範囲
今回はプロトタイプとしての実装を目的としているため、すべてのケースに対応できているわけではありません。
特に以下のような点については、完全には扱えていない部分があります。
-
custom()を用いた任意のバリデーション - テンプレートリテラルを含むメッセージの解決
- 関数の引数によって変化する意味の解釈(例:フィールドの 必須/任意 判定)
2. 題材となるアプリケーション
検証用として、シンプルな TODO アプリの API を用意しました。
実務でもよく見られる構成を前提としているため、
単純なサンプルコードではなく、現実的なコードベースに近い形で検証しています。
一般的なレイヤード構成を意識しており、
ルーティング・バリデーション・ビジネスロジックがそれぞれ分離されています。
大まかなディレクトリ構成は以下の通りです。
src/
├── controllers/
├── routes/
├── middlewares/
├── validators/
├── repositories/
├── usecases/
├── types/
└── utils/
今回のツールでは、特に以下のレイヤを対象にしてバリデーション情報を抽出します。
- routes(エンドポイントの定義)
- validators(バリデーションの定義)
- middlewares(バリデーションの適用)
controllers, usecases, repositories については、今回の処理には直接関係しないため詳細には触れませんが、
実際のアプリケーションに近い構成を前提とすることで、より実用的なケースでの検証を意識しています。
3. 実務的なコードからバリデーションを抽出するためのポイント
ここまでで、「どのようなコードを対象にするか」は整理できました。
では、実際にそのコードからバリデーションを抽出する際には、どのようにコードを読み解く必要があるのでしょうか。
シンプルなサンプルコードであれば、バリデーションはその場に直接書かれているため、
文字列として抽出するだけでもある程度は扱えます。
しかし実務のコードは、可読性や再利用性を考慮して、
- 処理の関数化
- ファイルの分割
- 条件分岐
- 定数化
といった構造が取り入れられます。
その結果、バリデーションの定義はコード全体に分散し、単純な方法では追いきれなくなります。
以下では、題材とするアプリケーションの実装内容をもとに、
バリデーション抽出時に押さえておくべきポイントを整理していきます。
3-1. ルーティングの構造
例えば、ルーティングは以下のように定義されています。
taskRouter.post('/', createTaskBody, ...)
一見するとシンプルですが、この時点では createTaskBody の中身は分かりません。
「どのようなバリデーションが行われているか」については、このコードだけでは判断できない構造です。
つまり、ルーティング定義は「バリデーションの参照元」であって、実体そのものではありません。
このようなケースでは、
- ルーティングからバリデーション定義を特定する
- 参照関係を辿って実体に到達する
という処理が必要になります。
本ツールでは、ast-grepでルーティングの構造を抽出し、
引数として渡されているバリデータ関数を特定することで、解析の起点を決定しています。
3-2. ファイルをまたぐ定義
上記の続きとなりますが、 createTaskBody は別ファイルから import されています。
import { createTaskBody } from '../validators/task.validator.js'
バリデーションの実体は別の場所にあり、単一ファイルの解析では完結しません。
このようなケースでは、単にコードを読み取るだけではなく、
- import 文を解析して依存関係を特定する
- ファイルパスを解決して対象ファイルに到達する
- その中から対象の定義を取得する
といった処理が必要となります。
本ツールでは、ast-grepで取得した情報をもとにimport元を特定し、
ts-morphで対象ファイルを読み込むことで、定義元まで辿れるようにしています。
3-3. メソッドチェーンによる定義
バリデーションは、次のようなメソッドチェーンで表現されています。
body("title").trim().notEmpty().isLength(...)
このようなコードは単なる文字列ではなく、「呼び出しの連なり」として構造を持っています。
そのため、
-
notEmpty()が必須を意味する -
isLength()が文字数制限を意味する
といった「意味」は、呼び出し順を含めて解釈する必要があります。
単純なパターンマッチではこれらの関係を正しく扱えないため、
AST(構文木)としてメソッドチェーンを分解し、呼び出しの列として扱うアプローチが必要になります。
本ツールでは、メソッドチェーンを走査して
「どのメソッドがどの順で呼ばれているか」を配列として抽出し、
その情報をもとにルールへ変換しています。
3-4. 条件分岐による変化
ここで重要なのが、バリデーションの内容は条件によって変化することがある、ということです。
const chain = required
? body("title").trim().notEmpty().withMessage("title is required")
: body("title").optional().trim();
このようなケースでは、単に構文を取得するだけでは不十分で、
条件式の評価結果に応じて「どのチェーンが適用されるのか」を解釈する必要があります。
解析対象は単なる「コードそのもの」ではなく、「特定の条件下で実際に評価されるコード」になります。
そのため、条件式を考慮して「どの分岐が実際に適用されるか」を判断しながら解析する必要があります。
本ツールでは、関数の引数として渡された値をもとに分岐を評価し、
「どの分岐を採用するか」を決定したうえで再帰的に解析しています。
3-5. 関数による抽象化
バリデーションは関数として定義されているケースもあります。
titleField(true)
この場合、呼び出し元と関数定義を結びつけることで初めて、
どのようなバリデーションが適用されているか、が分かります。
このようなケースでは、関数呼び出しを起点にして定義元の関数を辿って中身を展開する必要があり、
「その場のコード」だけではなく、呼び出し関係を跨いで解析する仕組みが求められます。
本ツールでは、関数の引数とパラメータを紐づけたうえで、
戻り値の式を再帰的に解析することで対応しています。
3-6. 定数による値の分離
バリデーションの条件は、コード内に直接書かれているとは限りません。
たとえば、以下のようなコードであれば、定数の定義元を辿る必要があります。
const TASK_STATUSES = ['todo', 'in-progress', 'done'] as const;
body('status').isIn(TASK_STATUSES);
このように、バリデーションの条件そのものもコード上に分散するため、
単純な構文解析だけでは「どの値が許可されているのか」を正しく把握することができません。
「値そのもの」ではなく、「参照」を扱っているため、参照先を解決して、実際の値に展開する必要があります。
本ツールでは、型情報をもとにリテラル値を取得することで
配列の中身まで解決できるようにしています。
3-7. 任意関数(custom)の存在
さらに、任意のロジックを実装できる custom() のようなケースもあります。
.custom((value) => {
if (value === null || value === undefined) return true;
if (typeof value !== "string") return false;
const t = Date.parse(value);
return !Number.isNaN(t);
})
このような部分は実行時のロジックに依存するため、静的解析だけでは完全に理解することができません。
このように、実務のコードからバリデーションを抽出するためには、
- 参照関係を辿る(import・関数)
- 構造として分解する(メソッドチェーン)
- 条件や値を解釈する(条件分岐・定数)
といった複数の観点を組み合わせて扱う必要があります。
これは単純なテキスト処理ではなく、コードの構造と意味の両方を扱う「静的解析」の問題です。
次章では、これらの課題を踏まえて、
実際にどのようなパイプラインとして処理を設計したのかを見ていきます。
4. ツール設計(パイプライン)
前章で確認した通り、実務ベースのコードからバリデーションを抽出するためには、複数の処理を組み合わせて扱う必要があります。
これらをひとつの処理としてまとめてしまうと、実装が複雑になり、全体の見通しも悪くなってしまいます。
そのため、本ツールでは処理を一段階で解決しようとするのではなく、
責務ごとに分割したパイプラインとして設計しています。
4-1. 全体像
ツール全体の処理は、大きく4つのステップに分かれます。
- ast-grepでバリデーション構造を抽出
- ts-morphで意味解釈(関数・型・定数の解決)
- 中間表現(IR: Intermediate Representation)として構造化
- HTMLへ変換して出力
このように段階的に分解することで、
- 構文の抽出
- 意味の解釈
- データの整理
- 表現への変換
という異なる関心ごとを分離しています。
また、この設計では単に処理を分割するだけでなく、
入力、解析、出力を疎結合にすることも意識しています。
特に重要なのが、途中に「中間表現(IR)」を挟んでいる点です。
このIRは単なる中間データではなく、
解析結果を一度「確定したデータ」として切り離すための境界、として機能します。
ts-morph による解析の段階では、
- どの関数を辿るか
- どの分岐を採用するか
- どの値を解釈するか
といった「解釈の途中状態」が含まれています。
これをそのまま出力処理に渡してしまうと、
表示ロジック側が解析の詳細に依存してしまい、責務が混ざってしまいます。
そのため、一度 IR として
- エンドポイント
- フィールド
- バリデーションルール
といった「確定した情報」に変換し、解析と表現の責務を分離しています。
4-2. 各ステップの役割
① 構文の抽出(ast-grep)
まずは ast-grep を用いて、対象となるコードを抽出します。
ここでは、body("...") や param("...") といったバリデーション定義の構造を持つコードを検出し、解析対象となる箇所を絞り込みます。
このステップでは「どこを解析するか」を決めることに集中します。
② 意味の解釈(ts-morph)
次に ts-morph を用いて、抽出したコードの意味を解釈します。
具体的には、以下のような処理を行います。
- import を辿って定義元を解決する
- 関数呼び出しを展開し、実際の処理内容を取得する
- 定数や型情報から値を取得する
このステップによって、単なる構文情報から「実際のバリデーション内容」を復元していきます。
③ IR への変換
解釈した情報を、「IR」として構造化します。
例えば、以下のような情報を持つデータとして整理します。
{
"method": "POST",
"path": "/tasks",
"validators": [
{
"field": "title",
"rules": [
{ "type": "required", "message": "title is required" },
{
"type": "length",
"min": 1,
"max": 200,
"message": "title must be 1–200 characters"
}
]
}
]
}
このステップのポイントは、単なる整形ではなく
「解析結果を共通フォーマットに正規化し、後続処理から切り離す」ことにあります。
IR を境界として挟むことで、
- 解析ロジックの役割は「コードをどう解釈するか」
- 出力処理の役割は「データをどう見せるか」
というように、それぞれの責務を明確に分離することができます。
また、このように一度 IR に変換することで、
出力先や入力となるコードの構造や解析手法が変わった場合でも、
同じフォーマットに落とし込める限り、後続の処理を変更せずに再利用することができます。
④ 出力(HTML生成)
最後に、IR をもとに HTML を生成します。
ここでは、非エンジニアでも理解しやすいように
- 必須/任意の明示
- 自然な日本語でのルール表現
- エンドポイント単位での整理
といった点を意識して整形を行います。
このステップは、あくまでも「表現」に責務を限定しており、バリデーションの解釈ロジックには依存しません。
おわりに
本記事では、API のバリデーションを可視化するツールを題材に、
実務的なコードをどのように読み解き、整理していくかを見てきました。
バリデーションは一見シンプルですが、実際にはコード全体に分散しているため、
構造と意味の両方を意識して扱う必要があり、思っていたよりも扱いが難しい領域だと感じました。
今回は整理した内容をもとに、設計までを取り上げましたが、
次回は実際のコードを交えつつ、どのように実装していったのかを紹介していく予定です。
以上です。最後まで閲覧いただきありがとうございます。