これは LAPRAS Advent Calendar 2020 の6日目の記事です。
はじめに
社内でSQLのコーディング規約について少し話題となり(その時はこの記事についての話題でした)、自分でも思うところがあるので、普段自分がデータ分析を行う上で意識していることを書いてみます。
普段自分がデータ分析を行うのは、変化するビジネス要求に応じて、ユーザー行動を探索的に調査したり、数ヶ月~1年程度の短い期間で用いるプロダクトKPIをRedashでサクッと可視化する場合がほとんどです。
そのため、このコーディングスタイルも、使い捨て〜長くて1年程度の短い寿命のコードを素早く的確に作成することを目的としたものです。
また、今回は 「SQLによる分析コード構築方法」というメタな視点でのコーディングスタイルについて書きますが、 カンマやインデントなどのいわゆる「コーディング規約」については触れません。
ちなみに自分が1人でSQLを書くときは 「予約語は小文字」 「select句のカンマは後置き」「句の先頭の予約語(select,from,where等)で改行+字下げ」 などの規約を採用しており、本記事でもそれを採用します。
データ処理における宣言型の記述と手続き的な思考
SQLは「B木のインデックスをどう操作するか」のような手続きではなく「どのようなデータがほしいか」を記述するという意味で宣言型の言語であるといわれます1。これにより、データ分析者は、データベースの処理ではなくデータそのものに集中することができます。
しかし一方で、データ処理のためのある程度複雑なクエリを書く際には、「まずはこのデータを集めて、次にこの情報を結合し、結合した属性に対してこんな集計をし、最後に移動平均を計算する」のうように、データに対する処理の流れを考えることが自然かと思います。このように、全体のデータフローを設計する際にはある種の手続き型の思考が必要になります。
このように、データベースの処理の中身よりもデータ自体に集中できる宣言型のメリットと、データに対しての手続き型の思考の反映しやすさを両立するためにはどうすればいいでしょうか?
このためには、 宣言的な記述をワークフローのように積み上げていくことで、全体のデータ処理を記述する のが良いと考えています。これは、ちょうど luigi を用いたワークフロー構築のように、宣言的に定義されたタスクと、それらの依存関係によってワークフローを記述することに似ています2。
本記事では、 積極的に with 句を用いる ことで、SQLにおけるワークフローを記述する方法を提案します。
with 句を用いたワークフロードリブンなコーディング
まずは以下のような状況を例に考えてみます。
あなたは LAPRAS SCOUT とは似て非なる、架空のスカウトサービスの運営会社にいます。
このサービスには企業ユーザー(以下「企業」)と一般ユーザー(以下「ユーザー」)がおり、企業はユーザーに対してスカウトメールを送信することができます。
あなたの会社では、企業毎に最適なサービスの利用方法を提案するため、企業をいくつかのセグメントに分類しています。最近、カスタマーサクセス担当者の感覚値では、特定のセグメントばかりがスカウトメールを大量に送っているのではないかという話になりました。今後のサービス改善の方針を決めるために調査が必要そうです。
このため、企業セグメントごとの、スカウト送信数の分布を調べることにしました。
企業セグメントごとの、スカウト送信数の分布 を抽出するにあたり、まずは、どのような処理をすればよいかワークフローを考えます。次のような木構造(一般には有向非巡回グラフ)が思い浮かぶかと思います。
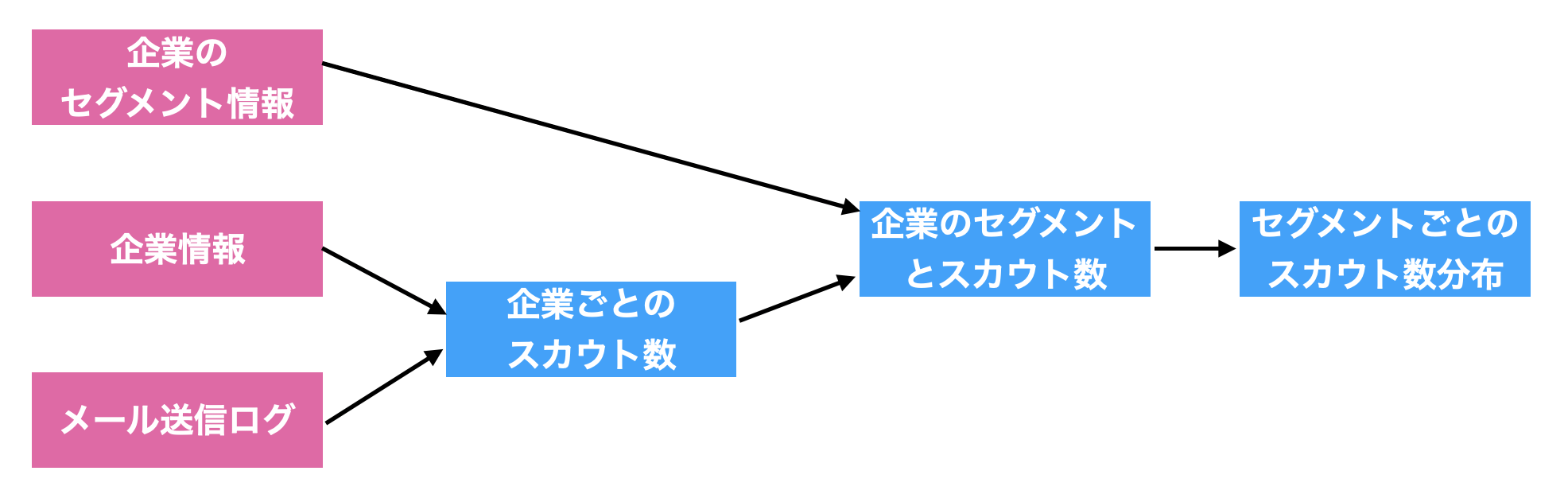
ここで、このワークフローにおける各タスク(図の四角)には、「処理の内容」ではなく「処理の結果得られるデータ」が入ることに注意してください。これにより、各タスクを宣言的に記述しつつ、それらの依存関係を定義することで全体としてのワークフローを記述する準備ができました。
それでは、このワークフローを SQL にしていきます。これには、次のように ワークフローのタスク1つ1つを with 句のサブクエリとして定義 していきます。
- どのようなタスクを定義するかを考え、わかりやすい名前を付ける(これをサブクエリの別名にする)。
- 既に定義されているタスクを from 句や join 句で用いてタスク定義を完成させる。
- 完成したタスクの結果を返すだけの select 文 (
select * fron xxx) を実行して結果を確認する。
これをワークフローの上流から下流に向かって繰り返すことで、全体のワークフローを作成します。
最終的には、次のようなクエリが出来上がります。
with first_scout as (
-- 各企業から各ユーザーへの最初のスカウトメール
select
min(id) as id,
user_id,
company_id
from
mail_log
where
mail_type = 'scout'
group by
user_id, company_id
)
, first_scout_count_for_each_company as (
-- 企業毎のスカウト送信数
select
count(*) as scout_count,
company_id
from
first_scout
group by
company_id
)
, company_with_first_scout_count_and_segment_type as (
-- 企業毎のセグメントとスカウト数
select
company.id as company_id,
ifnull(fsc.scout_count, 0) as scout_count,
cs.segment_type,
case cs.segment_type
when 1 then 'セグメント1'
when 2 then 'セグメント2'
else '未分類'
end as segment_type_str
from
company
inner join
company_segment as cs
on
cs.company_id = company.id
left outer join
first_scout_count_for_each_company as fsc
on
company.id = fsc.company_id
)
, hist as (
-- セグメントごとのスカウト数ヒストグラム
select
count(*) as company_count,
scout_count,
segment_type_str
from
company_with_first_scout_count_and_segment_type
group by
scout_count,
segment_type_str
)
select * from hist;
最終的には、select 文の本体が select * from hist だけで、大部分が with 句のクエリが出来上がります。
このようにクエリを書いていくことの利点としては、
- 処理の流れの通りに、途中結果を確認しながらクエリを書いて行くことができる。
- 処理の流れがタスク単位で明示されるので、後から見たときに全体の処理を追いやすい。
- 最後の
from histの部分を切り替えるだけで、後から途中結果を簡単に出力できる。 - 複数のタスクが1つのタスクに依存するようなワークフローを書くことができる。
などが挙げられます。
特に3つ目のメリットは大きく、後でクエリの動作を確認する際に役立ちます。
例えば、プロダクトの仕様変更をする際に、Redash にあるアドホックなKPI計測用のクエリの影響まで確認することは実質的に不可能であり、このような仕様変更がされた際には、多くの場合「データが壊れた」ことによって初めて気づく場合があります。
このとき、 最後の from hist の部分を切り替えることで、クエリの途中結果を確認することができ、容易にクエリを修正できます。
その他意識していること
ワークフロードリブンなSQLを書く上で他に気をつけていることについて触れておきます。
パフォーマンスチューニングは後回し
この方法でデータ分析用のクエリを書くにあたり、全体のワークフローの導通を確認することを最優先に考え、クエリのパフォーマンスチューニングは後回しにします。
冒頭に述べたように、このコーディングスタイルは、探索的データ分析やアドホックなKPI可視化用のクエリを想定しており、長期間頻繁に使い続けるような用途は想定していません。
このため、クエリの実行時間が10秒でも1秒でも、場合によっては10分でも実用上問題ないこともあり、それよりもクエリを書いている時間の方が貴重な場合もあります。
クエリが最終的に遅いかどうかを判断することができるのは、結果が出てからです。
最後までクエリを書いてみて、実用に耐えないほど遅い場合には、パフォーマンスチューニングをします。
一方で、クエリを書いている途中でデータフローの導通チェックをする際のレスポンスが気になる場合、適宜 limit 句を追加してデータ数を減らした上で導通チェックを行い、最後に limit 句を外します。
また、パフォーマンスチューニングを後回しにすると言っても、ワークフロー全体の設計が悪いと後で直すのが大変になるので、なるべく計算量のオーダー的には最善にできるようにワークフローを設計する時点である程度考えておくことももちろん重要です。
select 句の相関サブクエリは使う。
「〇〇ごとに最も××な△△」というクエリを書くとき、select句での相関サブクエリを使うのが一番明示的な書き方だと思うので、これは割とよく使います。
with scout as (
select
*
from
mail_log
where
mail_type = 'scout'
order by
company_id, sent_at desc -- 相関サブクエリのパフォーマンスのためにソートしておく
)
, company_with_first_scout_id as (
select
company.id,
-- 企業毎に最初に送信したスカウト
(select id from scout where company_id = company.id
order by sent_at desc limit 1) as first_scout_id
from
company
)
...
ただし、以下のことを気をつけます。
- 相関サブクエリ内では結合に必要な条件(
company_id = company.id)だけを指定する - 範囲の絞り込み(
mail_type = 'scout')は前のタスクでやっておく - 前のタスクで、結合に使う属性でソートしておく (
order by company_id, sent_at desc)。
1,2は相関サブクエリをなるべく簡潔に書くための規約です。
また、相関サブクエリは遅いという方もいらっしゃいますが、3. のソートだけしておけば、経験上このタイプの相関サブクエリが join を用いる方法と比べて著しく遅くなることはまずありません。
もしそれでも耐えられないほど遅くなってしまった場合は、後で書き換えを検討します。
どのみち、パフォーマンスチューニングは後回しです。
Redash の Query Results を使う場合は必ず明示的にインポートする
自分は普段 Redash を使ってデータ分析を行うことが多いです。
Redash では様々なデータソースからデータを取得することができますが、異なるデータソースのテーブルを結合する場合には、 Query Results データソースで別のクエリの結果を呼び出して結合します。
このとき、他のクエリを呼び出す際の query_xxx というテーブル名は何の意味も持たないため、これがクエリのあちこちにあると可読性を著しく損ねます。また、クエリ間の依存関係もわかりづらくなります。
with first_scout as (
select
min(id) as id,
user_id,
company_id
from
query_123 -- これがあちこちにあると可読性を損ねる
where
mail_type = 'scout'
group by
user_id, company_id
)
, ...
このため、 query_xxx というテーブルを呼び出す際には、必ずクエリの冒頭で明示的にタスクとして「インポート」するようにします。
-- 必要なクエリを全て明示的にインポートする
with mail_log as (select * from query_123)
, company as (select * from query_456)
, first_scout as (
select
min(id) as id,
user_id,
company_id
from
mail_log -- インポートしたクエリを使う
where
mail_type = 'scout'
group by
user_id, company_id
)
, ...
また、これによる副次的な効果として、「あとでデータソースだけを差し替える」みたいなこともやりやすくなります。
まとめ
- データ分析のためのSQLを素早く的確に作りたい。
- このとき、SQLの宣言的な記述と、データ処理全体を考える手続き的な思考を両立させたい。
- そのために、データ処理全体をワークフローと捉え、1つ1つのタスクを with句で記述する。
- これにより、全体の見通しがよくなり、後からコードを見直すのも楽になる。