はじめに
 < にゃーん 趣味でポスグレをやっている者だ
< にゃーん 趣味でポスグレをやっている者だ
みなさんこんにちは。NTTテクノクロス 原田です(いつもはnuko_yokohama名義でQiitaに書いてます。最近サボってましたが・・・)。
これはNTTテクノクロス Advent Calendar 2019の16日目の記事です。昨年に引き続き、今年もNTTテクノクロス社員としてアドベントカレンダーを書くことになりました。
私は普段はPostgreSQLに関する検証・調査や、社内でのPostgreSQL支援、OSSクラウド基盤トータルサービス、PGECons活動に関わってますが、趣味としてもPostgreSQLはちょこちょこ使っています。
今回の記事もそういうわけでPostgreSQLに関するものになります。

弊社の他のアドベントカレンダーの記事と比べると小粒で地味な感じですが、よろしくおねがいします。
サマリ
- PostgreSQLコミュニティで開発中のIncremental View Maintenace機能を使ってみた。
- マテリアライズド・ビューなんだけど元のテーブルの更新差分を自動反映するすごいやつだよ!
- 開発者/レビューアー募集中!
お題
今回は現在開発中のPostgreSQL 13で議論されている、Incremental View Maintenanceという機能について書いてみようと思います。
10月にPostgreSQL 12がリリースされたばかりですが1、開発コミュニティでは次期バージョンに向けて新機能の検討や実装が進められています。
ViewとMaterialized View
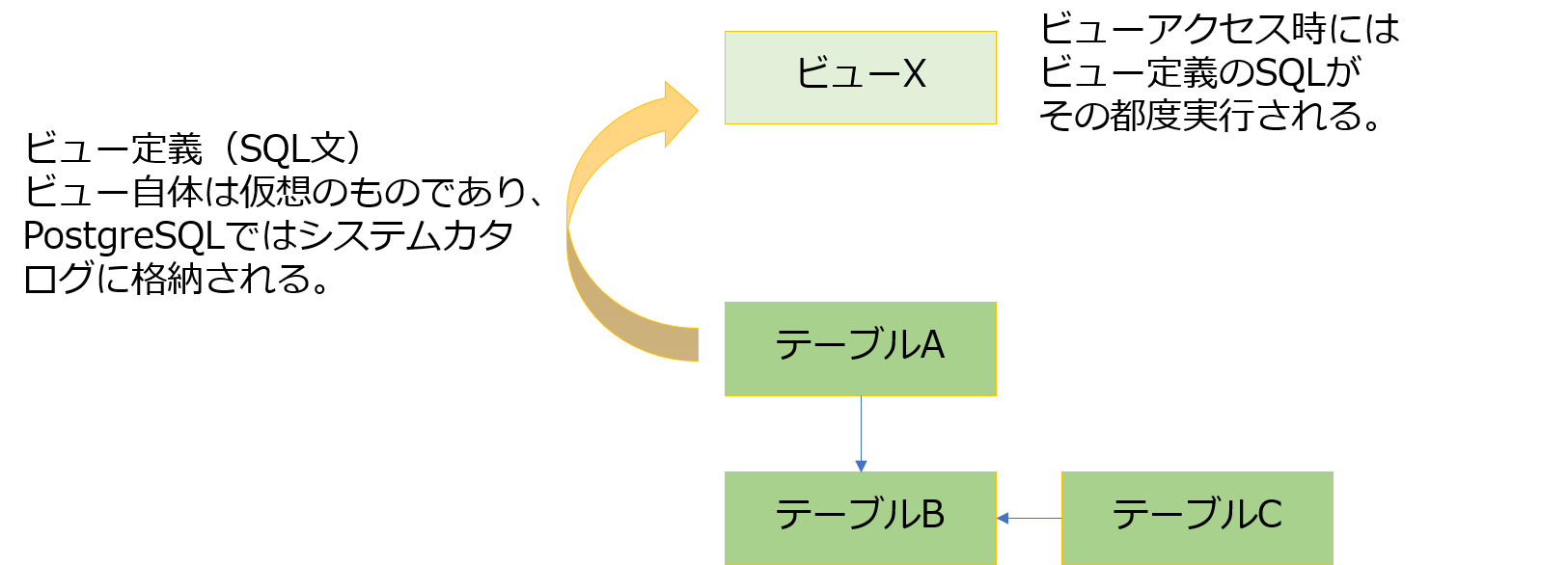
PostgreSQLに限らず、大抵のリレーショナル・データベース管理システム(RDBMS)にはビューという仕組みをサポートしています。
ビューは実体をもったものではなく、ビューを検索するときに、定義時に指定したクエリを実行するというものです。
さて、ビューとよく似たものとして、マテリアライズド・ビューという仕組みもあります。
マテリアライズド・ビューはビューと同様に定義するときにクエリを指定しますが、ビューとは異なり、クエリの実行結果を実体化(マテリアライズド)します。元のテーブルが更新された場合、マテリアライズド・ビューの内容は自動的に更新はされません。更新する場合には、リフレッシュするための別コマンドを実行する必要があります。
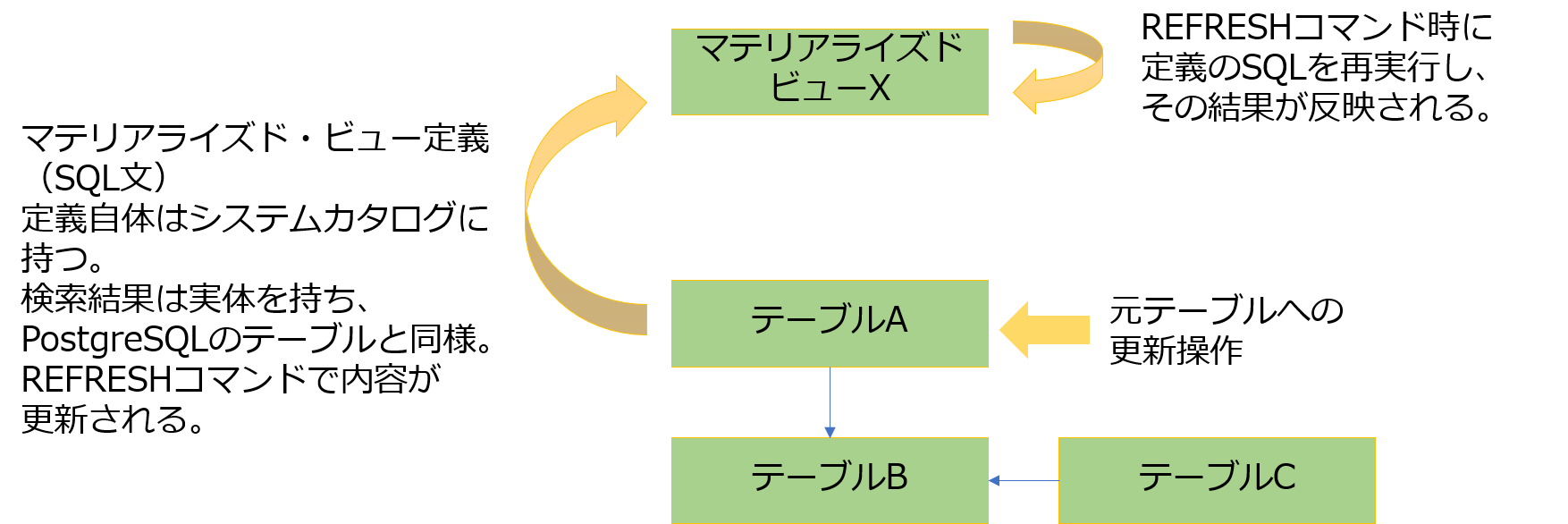
マテリアライズド・ビューは「必ずしも最新結果でなくてもいい」「毎回検索すると時間がかかるクエリの結果を保存する」といった用途で使うことができます。
これも多くのRDBMSでは利用可能です。もちろんPostgreSQLでもバージョン9.3から利用可能です。
Incremental Materialized View
ビューとマテリアライズド・ビューという2つの目的のビューがあるのをここまで簡単に説明してきました。ここからは第3のビューであるインクリメンタル・マテリアライズドの話をします。
SQLコマンドとしてはIncremental Materialized View(IMV)なんですが、仕組みの名前はIncremental View Maintenance(IVM)なので、ちょっとややこしいですね。![]()
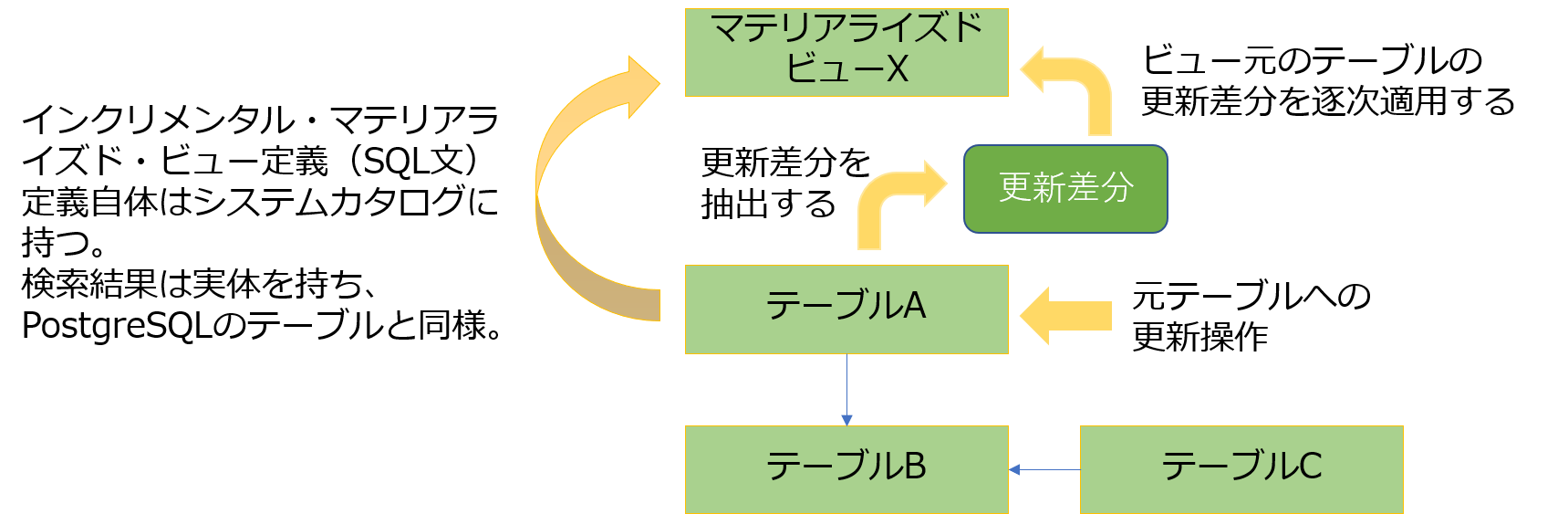
この仕組みは、すごく雑に言うと「ビューの参照元であるテーブルへの更新を逐次適用するマテリアライズド・ビュー」というものです。通常のマテリアライズド・ビューではREFRESH MATERIALIZED VIEWコマンドでビューの更新コマンドを実行しないと最新の状態に反映されませんが、インクリメンタル・マテリアライズド・ビューでは、一度ビューを定義するだけで、ビューの参照元のテーブルの更新をいい感じで自動的に反映してくれます。
仕組み
自分がざっと情報を集めた感じでは、トリガで差分をとりだし、中間テーブルや遷移テーブル等をうまく使って、反映先であるマテリアライズド・ビューに更新を反映しているようです。
Incremental View Maintenanceの詳しい仕組みに興味がある方は、自分の拙い説明より、議論をまとめているPostgreSQL Wiki - Incremental View Maintenanceや、今年のPGCONF.Asiaで、SRA OSS, Inc.の長田さんが発表した、Toward Implementing Incremental View Maintenance on PostgreSQLのスライドを見ていただけると良いかと思います。
インクリメンタル・マテリアライズド・ビューを使ってみた
こういうのは使ってみるのが理解のためには手っ取り早いです。実際にIncremental View Maintenanceの機能をソースからビルドして実際に使ってみました。
注意:以下の検証内容は現時点(2019-12-02時点)でのコミットバージョンe08f3bcdaf573b7bf9b07fe75883762780522b82のものです。今後、コマンド構文などの変更が入る可能性はあります。
ビルド
現在、IMVは SRA OSS, Inc. Japan が主に開発に携わっているようです。今回試した開発中のコードは以下のGithubリポジトリから入手しました。
https://github.com/sraoss/pgsql-ivm
ここからgit cloneするなりzipファイルをダウンロードするなりしてPostgreSQL-13devel+Incremental View Maintenance機能が入ったソースをgccを使ってビルドします。
自分の手元の環境(EC2 t.small, Amazon Linux 2, gcc (GCC) 7.3.1 20180712)で試したときには、特殊なconfigureオプションをつけずにビルドできました。
PostgreSQLのソースからのビルド方法についてはここでは割愛します。2
使用例 - シンプルなグループ化&集約演算
まず、わかりやすい例として、単一テーブルをGROUP BYして集約演算する例を使って、ビュー、マテリアライズド・ビュー、インクリメンタル・マテリアライスズド・ビューの違いを示します。
こんな感じの1000万件のレコードを持つテーブルを作成しておきます。
CREATE TABLE table_x AS
SELECT generate_series(1, 10000000) AS id,
ROUND(random()::numeric * 100, 2) AS data,
CASE (random() * 5)::integer
WHEN 4 THEN 'group-a' WHEN 3 THEN 'group-b' ELSE 'group-c' END AS part_key
;
SELECT 10000000
\d
Table "public.table_x"
Column | Type | Collation | Nullable | Default
----------+---------+-----------+----------+---------
id | integer | | |
data | numeric | | |
part_key | text | | |
TABLE table_x LIMIT 3;
id | data | part_key
----+-------+----------
1 | 70.61 | group-c
2 | 24.33 | group-c
3 | 2.79 | group-c
(3 rows)
idにはユニークな値、dataには0~100.00までのランダムな数値、part_keyには'group_a', 'gruop_b', 'group_c'のいずれかの文字列が格納されています。
このテーブルに対して、以下のようなグループ化&集約演算を行うクエリを実行します。3秒少々かかる、少し重たい処理です(3678.1ms)。
SELECT part_key, COUNT(*), MAX(data), MIN(data), SUM(data), AVG(data)
FROM table_x
GROUP BY part_key;
part_key | count | max | min | sum | avg
----------+---------+--------+------+--------------+---------------------
group-b | 2001229 | 100.00 | 0.00 | 99995643.30 | 49.9671168566915630
group-a | 2002798 | 100.00 | 0.00 | 100195357.85 | 50.0276901864291856
group-c | 5995973 | 100.00 | 0.00 | 299745927.33 | 49.9912069867559444
(3 rows)
Time: 3678.084 ms (00:03.678)
ビューの作成
さきほど挙げたGROUP化&集約演算を行うクエリを使ってビューを作成します。
まずは、普通のビュー(group_v)から。
CREATE VIEW group_v AS
SELECT part_key, COUNT(*), MAX(data), MIN(data), SUM(data), AVG(data)
FROM table_x
GROUP BY part_key;
CREATE VIEW
Time: 3.134 ms
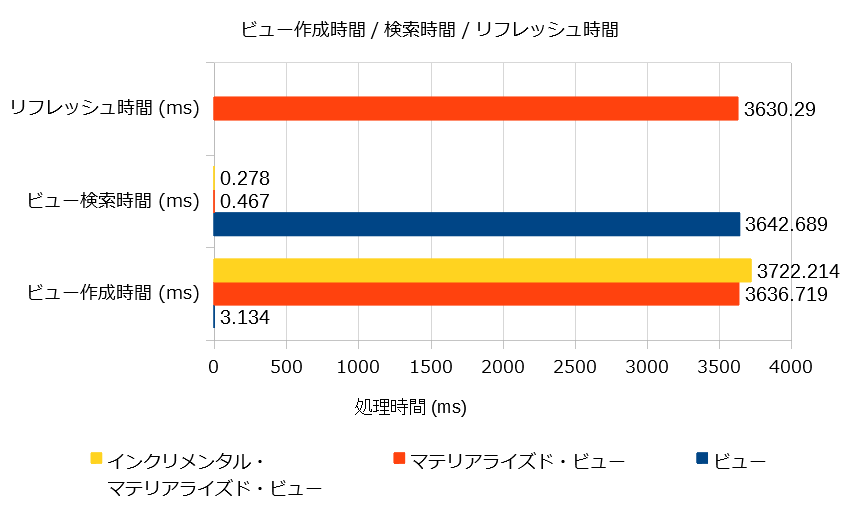
ビュー作成自体はさくっと終わります(3.1ms)。
つぎにマテリアライズド・ビュー(group_mv)。
CREATE MATERIALIZED VIEW group_mv AS
SELECT part_key, COUNT(*), MAX(data), MIN(data), SUM(data), AVG(data)
FROM table_x
GROUP BY part_key;
SELECT 3
Time: 3636.719 ms (00:03.637)
マテリアライズド・ビューの作成には、作成元となるクエリの実行時間と同じくらいの時間がかかります(3636.7ms)。
最後に、本記事の主題である、インクリメンタル・マテリアライズド・ビュー(group_imv)を作成してみます。
インクリメンタル・マテリアライズド・ビューの作成には、CREATE INCREMENTAL MATERIALIZED VIEWコマンドを使います。コマンドの形式はCREATE MATERIALIZED VIEWとほぼ同じです。3
CREATE INCREMENTAL MATERIALIZED VIEW group_imv AS
SELECT part_key, COUNT(*), MAX(data), MIN(data), SUM(data), AVG(data)
FROM table_x
GROUP BY part_key;
SELECT 3
Time: 3722.214 ms (00:03.722)
ビュー作成の時間は、マテリアライズド・ビューとほぼ同じです(3722.2ms)。まあ、これは仕方ないですね。
あと、なにげにpsqlのタブ補完機構も対応しています。これは地味に嬉しい。![]()
test=# CREATE IN
INCREMENTAL MATERIALIZED VIEW INDEX
test=# CREATE INCREMENTAL MATERIALIZED VIEW
作成したビューの確認
さて、これでビュー、マテリアライズド・ビュー、インクリメンタル・マテリアライズド・ビューの3種類のビューが作成できました。
test=# \d
List of relations
Schema | Name | Type | Owner
--------+-----------+-------------------+----------
public | group_imv | materialized view | postgres
public | group_mv | materialized view | postgres
public | group_v | view | postgres
public | table_x | table | postgres
(4 rows)
インクリメンタル・マテリアライズド・ビューもpsqlの\dメタコマンドで見るとmaterialized viewというタイプとして表示されます。
今度はマテリアライズド・ビューと、インクリメンタル・マテリアライズド・ビューの詳細を見てみましょう。
マテリアライズド・ビューの場合。
test=# \d+ group_mv
Materialized view "public.group_mv"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
----------+---------+-----------+----------+---------+----------+--------------+-------------
part_key | text | | | | extended | |
count | bigint | | | | plain | |
max | numeric | | | | main | |
min | numeric | | | | main | |
sum | numeric | | | | main | |
avg | numeric | | | | main | |
View definition:
SELECT table_x.part_key,
count(*) AS count,
max(table_x.data) AS max,
min(table_x.data) AS min,
sum(table_x.data) AS sum,
avg(table_x.data) AS avg
FROM table_x
GROUP BY table_x.part_key;
Access method: heap
最後の1行(Access method: heap)は、PostgreSQL 12から追加されたTABLE ACCESS METHODに対応する情報ですね。
そして、インクリメンタル・マテリアライズド・ビュー(group_imv)を見てみると・・・
test=# \d+ group_imv
Materialized view "public.group_imv"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
-------------------+---------+-----------+----------+---------+----------+--------------+-------------
part_key | text | | | | extended | |
count | bigint | | | | plain | |
max | numeric | | | | main | |
min | numeric | | | | main | |
sum | numeric | | | | main | |
avg | numeric | | | | main | |
__ivm_count_max__ | bigint | | | | plain | |
__ivm_count_min__ | bigint | | | | plain | |
__ivm_count_sum__ | bigint | | | | plain | |
__ivm_count_avg__ | bigint | | | | plain | |
__ivm_sum_avg__ | numeric | | | | main | |
__ivm_count__ | bigint | | | | plain | |
View definition:
SELECT table_x.part_key,
count(*) AS count,
max(table_x.data) AS max,
min(table_x.data) AS min,
sum(table_x.data) AS sum,
avg(table_x.data) AS avg
FROM table_x
GROUP BY table_x.part_key;
Access method: heap
Incremental view maintenance: yes
なにやら見慣れない列(__ivm_で始まる列)が増えています。この隠し列はCREATE INCREMENTAL MATERIALIZED VIEWコマンドの背景で自動生成されるもので更新差分を適用するための仕掛けとなります。
また、一番最後にIncremental view maintenance: yesという行が追加され、通常のマテリアライズド・ビューではなく、インクリメンタル・マテリアライズド・ビューであることがわかります。
また、この状態でトリガの状態を見てみると、table_xに対して6つのトリガが設定されていることもわかります。4
SELECT t.tgname, c.relname FROM pg_class c JOIN pg_trigger t ON (c.oid = t.tgrelid);
tgname | relname
------------------------------+---------
IVM_trigger_upd_after_17693 | table_x
IVM_trigger_del_after_17692 | table_x
IVM_trigger_ins_after_17691 | table_x
IVM_trigger_upd_before_17690 | table_x
IVM_trigger_del_before_17689 | table_x
IVM_trigger_ins_before_17688 | table_x
(6 rows)
ビューの参照
次は作成したビューを検索してみましょう。
まずはビュー(group_v)から。
SELECT * FROM group_v ORDER BY part_key;
part_key | count | max | min | sum | avg
----------+---------+--------+------+--------------+---------------------
group-a | 2002798 | 100.00 | 0.00 | 100195357.85 | 50.0276901864291856
group-b | 2001229 | 100.00 | 0.00 | 99995643.30 | 49.9671168566915630
group-c | 5995973 | 100.00 | 0.00 | 299745927.33 | 49.9912069867559444
(3 rows)
Time: 3642.689 ms (00:03.643)
ビュー定義時に指定したクエリが実行されるので時間がかかります(3642.7ms)。
次にマテリアライズド・ビュー(group_mv)。
SELECT * FROM group_mv ORDER BY part_key;
part_key | count | max | min | sum | avg
----------+---------+--------+------+--------------+---------------------
group-a | 2002798 | 100.00 | 0.00 | 100195357.85 | 50.0276901864291856
group-b | 2001229 | 100.00 | 0.00 | 99995643.30 | 49.9671168566915630
group-c | 5995973 | 100.00 | 0.00 | 299745927.33 | 49.9912069867559444
(3 rows)
Time: 0.467 ms
ビューと違って、既に検索済みの3件の結果を検索するだけなので当然のように速いです(0.47ms)。
最後にインクリメンタル・マテリアライズド・ビュー(group_imv)。
SELECT * FROM group_imv ORDER BY part_key;
part_key | count | max | min | sum | avg
----------+---------+--------+------+--------------+---------------------
group-a | 2002798 | 100.00 | 0.00 | 100195357.85 | 50.0276901864291856
group-b | 2001229 | 100.00 | 0.00 | 99995643.30 | 49.9671168566915630
group-c | 5995973 | 100.00 | 0.00 | 299745927.33 | 49.9912069867559444
(3 rows)
Time: 0.278 ms
こちらも、マテリアライズド・ビューと同じように速いです(0.28ms)。
ビュー元テーブルの更新
では、次に各ビューの元となるテーブル(table_x)を更新してみましょう。わかりやすい例として、part_keyが'group-d'という値のレコードを1件挿入してみます。
INSERT INTO table_x VALUES (10000001, ROUND(random()::numeric * 100, 2), 'gruop-d');
INSERT 0 1
Time: 4.724 m
さて、この状態で、また3つのビュー(group_v, group_mv, group_imv)を検索してみます。
まずはビュー(group_v)から。
SELECT * FROM group_v ORDER BY part_key;
part_key | count | max | min | sum | avg
----------+---------+--------+-------+--------------+---------------------
group-a | 2002798 | 100.00 | 0.00 | 100195357.85 | 50.0276901864291856
group-b | 2001229 | 100.00 | 0.00 | 99995643.30 | 49.9671168566915630
group-c | 5995973 | 100.00 | 0.00 | 299745927.33 | 49.9912069867559444
gruop-d | 1 | 76.86 | 76.86 | 76.86 | 76.8600000000000000
(4 rows)
Time: 3629.595 ms (00:03.630)
ビューの場合、元テーブル内容を再度検索するので、さきほど追加したgroup-dの行も反映されています。
でも、ビュー参照の都度、重たいSELECT文を処理するので時間はかかります(3629.6ms)。![]()
次にマテリアライズド・ビュー(group_mv)の場合。
SELECT * FROM group_mv ORDER BY part_key;
part_key | count | max | min | sum | avg
----------+---------+--------+------+--------------+---------------------
group-a | 2002798 | 100.00 | 0.00 | 100195357.85 | 50.0276901864291856
group-b | 2001229 | 100.00 | 0.00 | 99995643.30 | 49.9671168566915630
group-c | 5995973 | 100.00 | 0.00 | 299745927.33 | 49.9912069867559444
(3 rows)
Time: 0.349 ms
検索自体はすぐに終わりますが(0.3ms)、最新の情報(挿入されたgroup-dの行)が反映されていません。![]()
最新状態に反映するためには、REFRESH MATERIALIZED VIEWコマンドによるマテリアライズド・ビューのリフレッシュが必要になります。
REFRESH MATERIALIZED VIEW group_mv;
REFRESH MATERIALIZED VIEW
Time: 3630.290 ms (00:03.630)
SELECT * FROM group_mv ORDER BY part_key;
part_key | count | max | min | sum | avg
----------+---------+--------+-------+--------------+---------------------
group-a | 2002798 | 100.00 | 0.00 | 100195357.85 | 50.0276901864291856
group-b | 2001229 | 100.00 | 0.00 | 99995643.30 | 49.9671168566915630
group-c | 5995973 | 100.00 | 0.00 | 299745927.33 | 49.9912069867559444
gruop-d | 1 | 76.86 | 76.86 | 76.86 | 76.8600000000000000
(4 rows)
Time: 0.408 ms
リフレッシュすることで最新状態への反映はできますが、リフレッシュ時には重たい検索クエリが再実行されるので時間がかかります(3630.3ms)。![]()
最後に、インクリメンタル・マテリアライズド・ビュー(group_imv)を参照してみます。
SELECT * FROM group_imv ORDER BY part_key;
part_key | count | max | min | sum | avg
----------+---------+--------+-------+--------------+---------------------
group-a | 2002798 | 100.00 | 0.00 | 100195357.85 | 50.0276901864291856
group-b | 2001229 | 100.00 | 0.00 | 99995643.30 | 49.9671168566915630
group-c | 5995973 | 100.00 | 0.00 | 299745927.33 | 49.9912069867559444
gruop-d | 1 | 76.86 | 76.86 | 76.86 | 76.8600000000000000
(4 rows)
Time: 0.197 ms
きちんと、最新状態に反映されている!![]()
そして、処理時間も短い!(0.2ms) ![]()
各ビューの作成時間/検索時間/リフレッシュ時間をまとめるとこうなります。
ビューの削除
インクリメンタル・マテリアライズド・ビューの削除のためには、DROP MATERIALIZED VIEWを使います。現時点では、通常のマテリアライズド・ビューもインクリメンタル・マテリアライズド・ビューも、DROP MATERIALIZED VIEWコマンドを使って削除します。
test=# DROP MATERIALIZED VIEW group_imv ;
DROP MATERIALIZED VIEW
test=#
メリット
インクリメンタル・マテリアライズド・ビューを使った簡単な例を説明しました。
さて、インクリメンタル・マテリアライズド・ビューのメリットとは何でしょう?
雑に言うと、ビューとマテリアライズド・ビューの良いとこどり?とも言えます。
- ビューのように複雑な演算を毎回行わずに、その結果を保持してくれる。(これはマテリアライズド・ビューと同じ)
- マテリアライズド・ビューのように、別契機で
REFRESH MATERIALIZED VIEWコマンドによる更新を必要とせず、自動的に更新される。(これはビューと同じ)
ここまで書くと、なんか良いことずくめのようですが、もちろん世の中そんなには甘くありません・・・。
デメリット
仕組みを見て気づいた方も多いと思いますが、裏でトリガ機能を使って、更新差分を反映しているため、当然ながらビューの元になるテーブルへの更新処理が遅くなります!
たとえば、さっきの例で示したテーブル(table_x)に1000件データをINSERT/UPDATE/DELETEするときの、インクリメンタル・マテリアライズド・ビューの有無・設定数による処理時間を比較してみます。
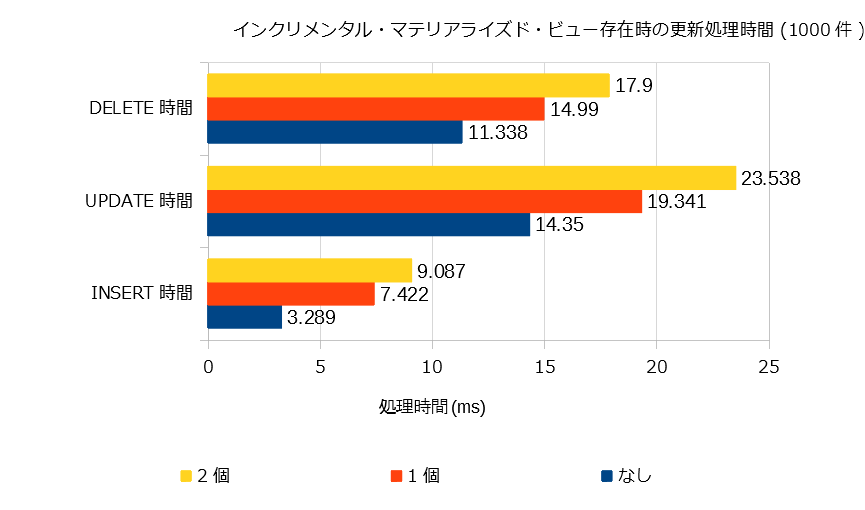
この測定結果から以下のことがわかります。
- インクリメンタル・マテリアライズド・ビューを定義すると更新性能に影響がある。
- インクリメンタル・マテリアライズド・ビューを増やすとさらに影響が大きくなる。
このように、インクリメンタル・マテリアライズド・ビューを使う場合には、更新への影響を考慮する必要があります。
例えば、非常に更新が多いテーブルをインクリメンタル・マテリアライズド・ビューの参照元として使うことは推奨できません。
また、インクリメンタル・マテリアライズド・ビューを設定するたびに、差分取り出しのためのトリガ等が生成されるため、インクリメンタル・マテリアライズド・ビューを乱用すると、「なんか更新トランザクションが妙に遅くなってる・・・![]() 」なんてこともあるかもしれません。
」なんてこともあるかもしれません。
インクリメンタル・マテリアライズド・ビューは、大量の更新が発生するテーブルを含むビューには向きません。マスタデータのような更新頻度が低い(たまに、少量の更新が発生するような)テーブルを使うビューに向いていそうです。
制約
現在、開発中のIncremental Materialized Viewを作成するときに与えるクエリには、いくつかの制約事項があります。
- 検索元にVIEW/MATERIALIZED VIEWを含むクエリは未サポート。
- 一部の集約関数(COUNT, MIN, MAX, SUM, AVG)のみサポート。
- サブクエリ/Common Table Expressionsを含むクエリは未サポート。
- HAVING句を含むクエリは未サポート。
- ORDER BY句を含むクエリは未サポート。
- ビュー元テーブルのTRUNCATEには未対応。
このあたりの制約については、Wikiページの制約事項や、Github issue、pgsql-hackersの議論が参考になると思います(もしかしたらこの記事を公開するときには、いくつか制約が解除されているかもしれません ![]() )。
)。
まとめ
ここまでの検証内容から、3種類のビューにはそれぞれ長短があることがわかります。
| ビュー方式 | 初期構築時間 | ビューに対する検索 | ビュー元に対する更新の追随 | ビュー元に対する更新時間 | クエリ制約 |
|---|---|---|---|---|---|
| ビュー | 短い | 長い | 自動的 | 影響なし | なし |
| マテリアライズド・ビュー | 長い | 短い | 手動 | 影響なし | なし |
| インクリメンタル・マテリアライズド・ビュー | 長い | 短い | 自動的 | 影響あり | 制約あり |
どれも万能というわけではなく、用途に応じて使いわけは必要です。
この機能はPostgreSQL次期バージョンに入るの?
現時点では不明です。
コミュニティで議論中/開発中のIncremental Materialized Viewですが、現状はまだ開発途中という状況で、この機能がPostgreSQLのコア機能として取り込まれるのかどうかは、正直言って不明です。というのは、コミュニティ内での議論が活発でなかったり、開発したコードがきちんとレビューされないと、PostgreSQL機能として取り込まれないからです。
現在のPostgreSQLのView/Materialized View機能に不満がある人、Oracleの同等の機能がPostgreSQLにも欲しいという人が、この機能を試したり、レビューしたり、あるいはコード作成を手伝ったりすることで、コミュニティ内での議論が活発になり、次期のPostgreSQLのコア機能として取り込まれるようになるといいなーと思っています。
自分もこの機能を試しに使い始めて、バグっぽい挙動を見つけてGithub issueを発行したり、pgsql-hackerのMLに投稿をはじめました。![]()
ちょうど今、Commitfestと呼ばれる、PostgreSQL開発イベントが始まっています。そして、Incremental Materialized View Maintenanceというページで、この機能に関する議論が行われています。
この機能に興味がある方、「私がデバッグしてやるぜ!」「コード書いてやるぜ!」という方はPostgreSQL開発者コミュニティに参加してレビューやパッチ投稿をしていただければ・・・と思います(自分のように新機能を使って不具合レポートを送るだけでも喜んでもらえます)。
おわりに
ということで、PostgreSQL 13で現在開発中の新機能について紹介してみました。
明日は、kuma-h さんの記事です。楽しみですね!
-
現在の最新バージョンは、PostgreSQL 12.1 (2019-11-14 Release)です。 ↩
-
PostgreSQL文書 第16章 ソースコードからインストール を参照してください。リンク先のバージョンはPostgreSQL 11ですが、このへんは開発中バージョンでもそれほど変わりはないはず・・・。 ↩
-
記事の執筆時点では、まだ
INCREMENTAL MATERIALIZED VIEWに関するSQLコマンドの説明ページは作成されていないので、あくまでも筆者の推測です。 ↩ -
このトリガ設定状況を見て、PostgreSQLのトリガに詳しい人はピンとくると思いますが、現時点でのIncremental View Maintenanceでは元テーブルへTRUNCATEしたときに自動的に追随はしていません。手動で
REFRESH MATERIALIZED VIEWコマンドを実行する必要があります。 ↩