はじめに
にゃーん。
最近、Twitterを見ていたらApache AGEという面白そうな拡張機能をみかけたので使ってみた。
件のツイート → https://twitter.com/DataAugmented/status/1520449666222989314
Apache AGE(incubating) is a PostgreSQL extension that provides graph database functionality.
今回は、とりあえずインストールして、簡単なグラフの生成と生成したグラフに対するOpenCypherによる単純な検索までを試してみた。
Apache AGEとは
Apache AGEはPostgreSQLの拡張機能(SQL関数)として、グラフデータベース問い合わせ言語OpenCypherのインタフェースを提供するというものらしい。
Cypherの元になった(?)Cypherという問い合わせ言語はグラフデータベースNeo4jでも使っているもので、自分も多少は使ったこともある。
現時点では(incubating)と併記されているように実用段階ではないようだが、PostgreSQL上でグラフデータベースが管理でき、かつSQLで操作できるとなれば、いろいろ楽しいことができそうなので、早速試してみることにした。
ドキュメントも一通りは揃っているようなので、簡単な操作程度であればドキュメントを見れば自分のようなグラフデータベース初心者でも、どうにかなるようだ。
https://age.apache.org/docs/master/index.html
インストールと設定
インストール資材の入手
Apache AGEは以下のサイトからソースセットを入手した。
https://www.apache.org/dyn/closer.lua/incubator/age/1.0.0/apache-age-1.0.0-incubating-src.tar.gz
現時点ではPostgreSQL 11に対応している。PostgreSQL 12, 13は今後対応するっぽい。今回は手元にあった、PostgreSQL 11.6の環境上にインストールした。
ビルド&インストール
ソースセットを展開して、展開後のディレクトリに移動し、makeを実行するのみ。
$ make USE_PGXS=1
ビルド後、make installを実行する。
これにより、PostgreSQL 11のインストール先ディレクトリ配下に、ライブラリファイル(*.so)と、CREATE EXTENSIONコマンド用のスクリプトがインストールされる。
$ ls -l lib/age.so
-rwxr-xr-x 1 ec2-user ec2-user 519792 May 3 15:20 lib/age.so
$ $ ls -l share/extension/age*
-rw-r--r-- 1 ec2-user ec2-user 77061 May 3 15:20 share/extension/age--1.0.0.sql
-rw-r--r-- 1 ec2-user ec2-user 900 May 3 15:20 share/extension/age.control
$
データベースへの登録
Apache AGEを使うためには、CREATE EXTENSIONコマンドによるデータベースへの登録を行う。
以下はsampleという名前のデータベースを作成し、そこにAGE拡張機能を登録する例である。
$ createdb sample
$ psql sample -c "CREATE EXTENSION age"
CREATE EXTENSION
$ psql sample -c "\dx"
List of installed extensions
Name | Version | Schema | Description
---------+---------+------------+------------------------------
age | 1.0.0 | ag_catalog | AGE database extension
plpgsql | 1.0 | pg_catalog | PL/pgSQL procedural language
(2 rows)
$
\dxメタコマンドで、age 1.0.0 が表示されていれば正常に登録されている。
PostgreSQLの設定
CREATE EXTENSIONによる登録が完了すると、登録先のデータベース上にag_catalogとう名前のスキーマが登録されている。
$ psql sample -c "\dn"
List of schemas
Name | Owner
------------+----------
ag_catalog | postgres
public | postgres
(2 rows)
$
AGEが提供するSQL関数もこのag_catalogスキーマ上に格納されている。
このままでも
SELECT * FROM ag_catalog.cypher( ... )
のようにスキーマ修飾をつければ利用可能だが、スキーマ修飾をつけるのが面倒なら、postgresql.confのsearch_path変数に、以下のように設定して再起動(restart)し、スキーマ修飾なしでAGEが提供する関数を使用可能にする。
search_path = ag_catalog, "$user", public
グラフの生成
AGEで格納する頂点(vertex)やエッジ(edge)を格納する領域を「グラフ」と呼ぶ。
このため最初に、「グラフ」を作成するために、AGEが提供する専用のSQL関数create_graph()を実行する。
create_graph()は1つの文字列引数をとる。この文字列引数はグラフの名前を示すもので、以降のOpenCypherのコマンドを実行する、cypher()関数には、create_graph()で指定した名前のグラフ名を渡す必要がある。
逆に言えば、1つのデータベース上には複数のグラフを配置することができるともいえる。
create_graph()の例を以下に示す。(ageデータベースには既にage拡張機能が登録ずみである)
$ psql age -c "SELECT create_graph('sample');"
NOTICE: graph "sample" has been created
create_graph
--------------
(1 row)
$
グラフの削除
作成したグラフを削除する場合には、AGEが提供する専用のSQL関数drop_graph()を実行する。
drop_graph()は2つの引数をとる。
1番目の文字列引数はグラフの名前を示すもので、削除したグラフ名を指定する。
2番目のboolean引数(cascade)は、依存するオブジェクトをcascadeして削除するかどうかのフラグになる。
drop_graph()の実行例を以下に示す。
$ psql age -c "SELECT drop_graph('sample',true);"
NOTICE: drop cascades to 2 other objects
DETAIL: drop cascades to table sample._ag_label_vertex
drop cascades to table sample._ag_label_edge
NOTICE: graph "sample" has been dropped
drop_graph
------------
(1 row)
$
なお、現状cascadeの指定は実質上true一択っぽい。
cretae_graphで生成直後のグラフを削除しようとして、2番目の引数にfalseを指定した場合、または2番目の引数を省略した場合はdropに失敗してしまうようだ。false指定時の挙動を以下に示す。
$ psql age -c "SELECT drop_graph('sample',false);"
ERROR: cannot drop schema sample because other objects depend on it
DETAIL: table sample._ag_label_vertex depends on schema sample
table sample._ag_label_edge depends on schema sample
HINT: Use DROP ... CASCADE to drop the dependent objects too.
$
グラフデータベースの構成要素
グラフを生成したら、そのグラフ内にグラフデータベースを構成するVertex(頂点・ノード)とEdge(エッジ・関連)を生成する。
グラフデータベースは基本的にはVertexと2つのVertexをつなげるEdgeから構成されている。
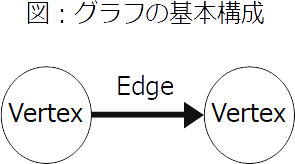
VertexやEdgeにはラベルや属性値を付与することもできる。
cypher関数
VertexやEdgeを登録する、グラフに対する検索を行う場合は、AGEが提供するSQL関数cypherを用いる。
記法に若干癖はあるが、慣れればそれほど難しくはない。
cypher関数の記述の基本構成は以下のようになる。
SELECT * FROM cypher(<graph_name>, $$
/* Cypher Query Here */
$$) AS (result agtype [,resule agtype]... );
最初の引数は、グラフの生成時に指定したグラフ名を文字列として指定する。
2番目の引数の最初に$$という見慣れない記述があるが、これは実はPostgreSQLの引用符指定。
PostgreSQLでは任意を引用符を使用することができる。
この例では$$を使っているが、これはPostgreSQLのSQL関数やPL/pgSQL関数を記述するときに使う引用符に$$を使っているから、慣例としてそれに合わせたが、実は任意の(例えば$quote$とかでも良い)文字を指定できる。
で、なぜわざわざそういう指定にするかというと、真ん中の行にある/* Cypher Query Here */のCypherクエリの中で引用符として単一引用符を使うからである。$$で引用符を指定しないと、いちいちCypherクエリ内の単一引用符をエスケープしないといけないので、面倒&可読性が落ちてしまう。
実際のCypher関数の実行例のイメージを以下に示す。
SELECT * FROM cypher('sample', $$
CREATE p = ( :Person {id: 101, name:'Alice', gender:'Fmale'} )
RETURN p
$$) as (p agtype);
Cyperによる登録・検索のサンプル
好きとか 嫌いとか 最初に言い出したのは 誰なのかしら
(「もっと!モット!ときめき」より)
ここからはサンプルを元に、Vertex、Edgeの登録、登録したあとのグラフに対する簡単な検索の例を示す。
サンプルとして、Personというラベルをもつ5つのVertexと、好き(Like)/嫌い(Dislike)の2種類のラベルによるEdgeの例をあげる。
図にするとこんな感じ。
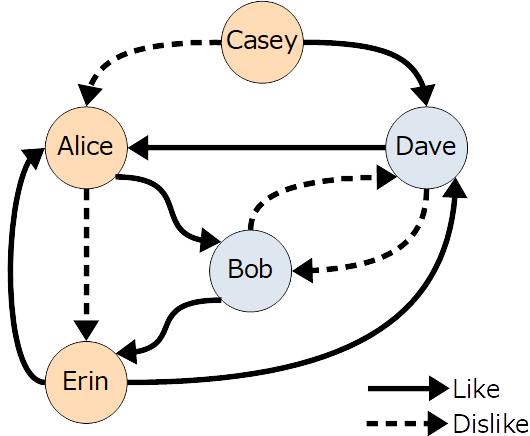
うーん、なんか愛憎乱れる状況ですねー
Vertexの登録
Vertexを登録するときには、CypherのCREATEコマンドを使う。
CREATEコマンドの基本的な形式は、
CREATE 生成したVertex = ( [:ラベル名] [ {属性名:属性値[, 属性名:属性値]... RETURN 生成したVertex
となる。で、SQL関数内で上記を記述し、cypher関数の返却値をas (変数名 型)と記述したSQLとして実行する。2段構成になっているので最初はちょい戸惑うけど、まあ、そういうものだと割り切って使うことにする。
Personラベルを持つVertexの登録例(Alice=サンの登録例)を以下に示す。
このVertexは
- ラベルはPerson
- 属性として以下の3つをもつ
- id属性。値は101
- name属性。値は'Alice'
- gender属性。値は'Female'
SELECT * FROM cypher('sample', $$
CREATE p = ( :Person {id: 101, name:'Alice', gender:'Female'} )
RETURN p
$$) as (p agtype);
p
---------------------------------------------------------------------------------------------------------------------------
[{"id": 844424930131969, "label": "Person", "properties": {"id": 101, "name": "Alice", "gender": "Fmale"}}::vertex]::path
(1 row)
上記のSELECT文を実行すると、なにかJSONっぽい値が返却される。これはpathと呼ばれるもので、生成されたVertextのメタ情報や属性値群(properties)が含まれている。
これでAlice=サンの登録ができたので、同様に他の4人も登録していく。他の4人の登録時に使ったSELECT文の例はこのページ最後の「参考情報」に記述している。
Edgeの登録
Edgeを登録する場合、一番重要なことは「Edgeの両端にはVertexが存在する」ということである。
要するに、Edgeを登録する場合にはVertexが先に存在していなくてはならない。Vertexを持たないEdgeというのは存在しない。
なので、今回の例でも先にVertexを登録し、その後に存在するVertexを選択することになる。
さっきのセクションでVertexの登録ができたので、VertextとVertexをつなぐEdgeを作成する。
Edgeの作成もVertexと同様にCREATE文を使う。Vertexと異なるのは、CREATEするときに、MATCH句を使ってEdgeの両端を指定することである。
例えば、Alice=サンからBob=サンに対して、ラベルLikeのEdgeを生成する例を以下に示す。
SELECT * FROM cypher('sample', $$
MATCH (a:Person), (b:Person)
WHERE a.name = 'Alice' AND b.name = 'Bob'
CREATE (a)-[e:Like{level: 'high'}]->(b)
RETURN e
$$) as (p agtype);
MATCH句で、ラベルPersonを2つ設定し、最初のPersonにはaという変数を、次のPersonにはbという変数を割り当てる。
そして、次のWHERE句句でaのPersonの条件として名前が'Alice'、bのPersonの条件として名前が'Bob'を設定する。
これにより、Alice=サンからBob=サンに対する関係を指定することになる。
そして、上記で特定した関係をCREATE文を使い、ラベルLike(「好き」)として生成する。
EdgeもVertexと同様に任意の属性(properties)を設定することができる。上記の例では、levelという属性に'high'という値を設定している。
(「好き」レベルが高い、という感じ)
以下、同様に図に示したLike/DislikeのラベルをもつEdgeを設定していく。
Cypherによる検索
Cypherによる検索時にも登録時と同様にcypher関数を使う。
Cypherクエリの基本は、MATCH→WHERE→RETURNとなる。
WHEREは必須ではないので、単純な検索の場合にはMATCH→RETURNのみを使う。
さて、ここで、作成したVertexとEdgeの図を再掲する。
Vertexのリスト
まず、単純にこのグラフに存在する全てのPersonのVertexを検索してみる。
SELECT * FROM cypher('sample', $$
MATCH (a:Person) RETURN a
$$ ) as ("Person" agtype);
これを実行すると、以下のような結果が返却される。
Person
--------------------------------------------------------------------------------------------------------------------
{"id": 844424930131969, "label": "Person", "properties": {"id": 101, "name": "Alice", "gender": "Female"}}::vertex
{"id": 844424930131970, "label": "Person", "properties": {"id": 102, "name": "Bob", "gender": "Male"}}::vertex
{"id": 844424930131971, "label": "Person", "properties": {"id": 103, "name": "Casey", "gender": "Female"}}::vertex
{"id": 844424930131972, "label": "Person", "properties": {"id": 104, "name": "Dave", "gender": "Male"}}::vertex
{"id": 844424930131973, "label": "Person", "properties": {"id": 105, "name": "Erin", "gender": "Female"}}::vertex
(5 rows)
特定の属性値のみの表示
これも全てのVertexを検索対象とするが、返却する情報を、nameとgenderのみに限定してみる。
SELECT * FROM cypher('sample', $$
MATCH (a:Person) RETURN a.name, a.gender
$$ ) as (name text, gender text);
RETURN句で、a全体を指定するのではなく、a.name, a.genderのように属性のリストを指定する。また、それに合わせて、cypher関数の返却型を(name text, gender text)のように変更する。
これを実行すると、以下のように名前と属性のみが結果として返却される。
name | gender
-------+--------
Alice | Female
Bob | Male
Casey | Female
Dave | Male
Erin | Female
(5 rows)
「嫌い」で繋がれたVertexの名前を表示する
最後に、ちょっとグラフデータベースっぽい検索をしてみる。
SELECT * FROM cypher('sample', $$
MATCH (a:Person)-[e:Dislike]->(b:Person) RETURN a.name, e.level, b.name
$$ ) as ("from" text, level text, "to" text);
これは、MATCHで「嫌い」(Dislike)のEdgeで繋がれたPersonのVertexを指定する、という検索である。
検索結果からPersonのVertexのnameと、Edgeに設定されたlevel属性の値を返却する。
これを実行すると以下のようになる。
from | level | to
-------+-------+-------
Alice | high | Erin
Bob | mid | Dave
Casey | high | Alice
Dave | low | Bob
(4 rows)
このセクションの最初に示した愛憎乱れる図と一致した結果になっている。
おわりに
今回は、基本中の基本ということで、インストール・基本設定・Vertex/Edgeの登録の基本、簡単な検索の例を示した。
もちろんCypherやAGEの機能はこれだけではないので、応用的な機能について、今後調査を継続してみようと思う。
おまけ
現状のAGEは、まだバギーなところもある。
今、一番困っているのは、セッションの中で最初に実行したCypherクエリが必ずERROR: unhandled cypher(cstring) function callという謎エラーになること。なお、同じクエリを再度実行すると正常に実行される。なんでやねん。
$ psql age
psql (11.6)
Type "help" for help.
age=# SELECT * FROM cypher('sample', $$
MATCH (a:Person)-[e:Dislike]->(b:Person) RETURN a.name, e.level, b.name
$$ ) as ("from" text, level text, "to" text);
ERROR: unhandled cypher(cstring) function call
DETAIL: sample
age=# SELECT * FROM cypher('sample', $$
MATCH (a:Person)-[e:Dislike]->(b:Person) RETURN a.name, e.level, b.name
$$ ) as ("from" text, level text, "to" text);
from | level | to
-------+-------+-------
Alice | high | Erin
Bob | mid | Dave
Casey | high | Alice
Dave | low | Bob
(4 rows)
参考情報
サンプルで使ったVertexとEdge登録用の全クエリ
-- create Person Vertex
SELECT * FROM cypher('sample', $$
CREATE p = ( :Person {id: 101, name:'Alice', gender:'Female'} )
RETURN p
$$) as (p agtype);
SELECT * FROM cypher('sample', $$
CREATE p = ( :Person {id: 102, name:'Bob', gender:'Male'} )
RETURN p
$$) as (p agtype);
SELECT * FROM cypher('sample', $$
CREATE p = ( :Person {id: 103, name:'Casey', gender:'Female'} )
RETURN p
$$) as (p agtype);
SELECT * FROM cypher('sample', $$
CREATE p = ( :Person {id: 104, name:'Dave', gender:'Male'} )
RETURN p
$$) as (p agtype);
SELECT * FROM cypher('sample', $$
CREATE p = ( :Person {id: 105, name:'Erin', gender:'Female'} )
RETURN p
$$) as (p agtype);
-- Create Edge
-- From Alice
SELECT * FROM cypher('sample', $$
MATCH (a:Person), (b:Person)
WHERE a.name = 'Alice' AND b.name = 'Bob'
CREATE (a)-[e:Like{level: 'high'}]->(b)
RETURN e
$$) as (p agtype);
SELECT * FROM cypher('sample', $$
MATCH (a:Person), (b:Person)
WHERE a.name = 'Alice' AND b.name = 'Erin'
CREATE (a)-[e:Dislike{level: 'high'}]->(b)
RETURN e
$$) as (p agtype);
-- From Bob
SELECT * FROM cypher('sample', $$
MATCH (a:Person), (b:Person)
WHERE a.name = 'Bob' AND b.name = 'Erin'
CREATE (a)-[e:Like{level: 'high'}]->(b)
RETURN e
$$) as (p agtype);
SELECT * FROM cypher('sample', $$
MATCH (a:Person), (b:Person)
WHERE a.name = 'Bob' AND b.name = 'Dave'
CREATE (a)-[e:Dislike{level: 'mid'}]->(b)
RETURN e
$$) as (p agtype);
-- From Casey
SELECT * FROM cypher('sample', $$
MATCH (a:Person), (b:Person)
WHERE a.name = 'Casey' AND b.name = 'Dave'
CREATE (a)-[e:Like{level: 'high'}]->(b)
RETURN e
$$) as (p agtype);
SELECT * FROM cypher('sample', $$
MATCH (a:Person), (b:Person)
WHERE a.name = 'Casey' AND b.name = 'Alice'
CREATE (a)-[e:Dislike{level: 'high'}]->(b)
RETURN e
$$) as (p agtype);
-- Dave
SELECT * FROM cypher('sample', $$
MATCH (a:Person), (b:Person)
WHERE a.name = 'Dave' AND b.name = 'Alice'
CREATE (a)-[e:Like{level: 'high'}]->(b)
RETURN e
$$) as (p agtype);
SELECT * FROM cypher('sample', $$
MATCH (a:Person), (b:Person)
WHERE a.name = 'Dave' AND b.name = 'Bob'
CREATE (a)-[e:Dislike{level: 'low'}]->(b)
RETURN e
$$) as (p agtype);
-- From Erin
SELECT * FROM cypher('sample', $$
MATCH (a:Person), (b:Person)
WHERE a.name = 'Erin' AND b.name = 'Dave'
CREATE (a)-[e:Like{level: 'mid'}]->(b)
RETURN e
$$) as (p agtype);
SELECT * FROM cypher('sample', $$
MATCH (a:Person), (b:Person)
WHERE a.name = 'Erin' AND b.name = 'Alice'
CREATE (a)-[e:Like{level: 'mid'}]->(b)
RETURN e
$$) as (p agtype);