はじめに
にゃーん。
5月連休が終わった直後の5/8に、PostgreSQL 18 Beta1がリリースされました。
しかし、平日は仕事疲れでリリースノートの確認は進まず、2週間くらいかけてやっとリリースノートを一通り眺めたという状態・・・。
で、その中で「かけ算のスピードを改善した」という項目にふと目が止まりました。カテゴリとしては"Source Code"なので、あんまり利用者向けの改善という印象はないのだけど、かけ算という割と一般的な用語でのスピード改善なので、もしかすると利用者から見ても恩恵あったりする?ということで簡単に調べてみました。
コミットログにある改善内容
最近のPostgreSQLリリースノートは、リリースノート記載項目の末尾に、コミットログへのリンクがついている。リリースノート上の記述だけではよくわからん、という人はコミットログで補足できるということらしい。
この項目のコミットログはOptimise numeric multiplication using base-NBASE^2 arithmetic.にある。
PostgreSQLの数値データ型は大まかに3種類に分けられる。
| 種類 | データ型 |
|---|---|
| 整数データ型 | smallint, integer, bigint smallserial, serial, bigserial |
| 任意の精度を持つ数 | decimal, numeric |
| 浮動小数点データ型 | real, double precision |
コミットログの内容をざっと見した感じでは、任意の精度を持つ数(numreric)のかけ算の性能が向上したということらしい。
(で、その結果、numeric_big というリグレッションテストの実行時間が改善された、ということらしい)
実測
numeric_big.sql の実行時間の比較
雑ではあるけど、ソースコードに含まれるリグレッションテストのSQLファイルsrc/test/regress/sql/numeric_big.sqlをpsqlに食わせてそのtimeによるpsql自体の実行時間を見てみる。(3回実行、その平均値を用いる)
| バージョン | time() |
|---|---|
| PostgreSQL 17 | 0.510 |
| PostgreSQL 18 Beta1 | 0.344 |
確かにnumeric_big.sql自体の処理時間は有意に向上しているようだ。
ただ、このリグレッションテストファイルは、純粋にかけ算だけ行っているわけではない。
かけ算だけに特化したパターンで追試してみる。
numericのかけ算を大量に実行してみる
今度は自分でnumeric型の演算を大量に実行して、PostgreSQL 17/PostgreSQL 18 Beta1の処理時間を計ってみる。
とりあえずrandom()で生成した値をかけ算する、という処理を10万回繰り返すSQLで試してみる。
EXPLAIN ANALYZE
SELECT generate_series(1, 100000),
random()::numeric
*
random()::numeric
;
これは1行1回のかけ算のケースだが、同様にかけ算を2回、3回実行するSQLも作成し、それをPostgreSQL 17/PotgreSQL 18 Beta1で流してみた。
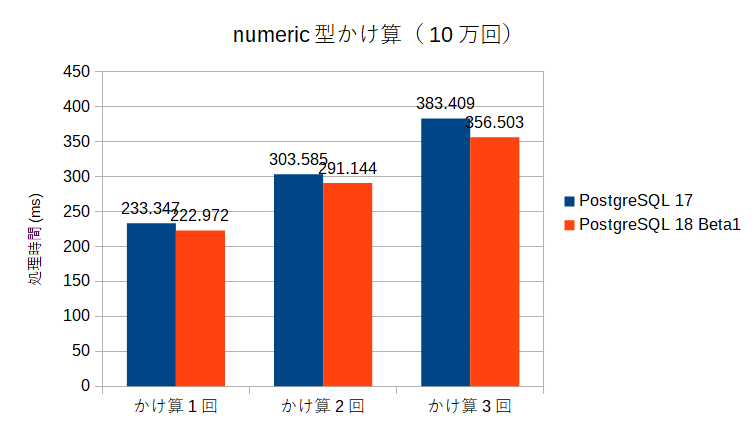
この結果を見ると、効果はあるがそこまで処理時間が改善されたようには見えない。
これには理由があって、上記のSQLの処理時間の大半はかけ算の処理ではなく、random()::numericの実行時間に費やされているためである。
このため、random()::numericの処理時間を別に測定し、その数を差し引いたもの(ほぼかけ算の時間のみになっているはず)で比較すると以下のようになる。
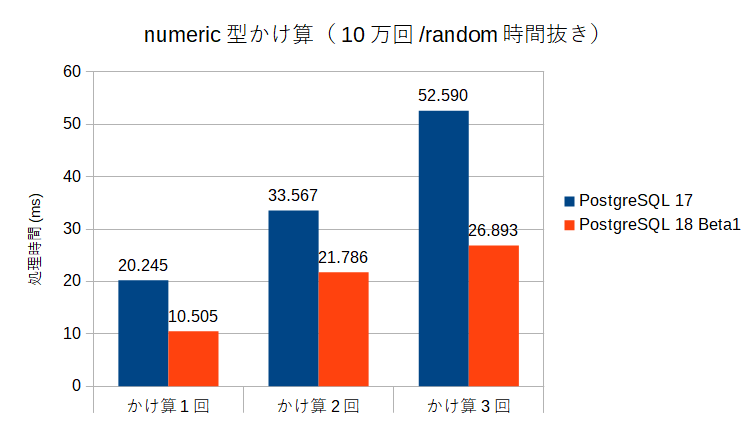
numeric型のかけ算の処理時間自体は、かなり改善されているという結果になった。
おわりに
普段、numeric型を積極的に使うことはあまりないけれど、例えばOracleからPostgreSQLへ移行する場合、Oracleのnumber型をシンプルにPostgreSQLのnumeric型にマッピングすることはありそう。
そういう案件で、数値へのかけ算を多用するケース(例えば税率の演算とか?)で、地味に性能改善が見込めそうな改善項目なのかもしれません。