はじめに
にゃーん。
今年は改元という国内イベントを挟んで10連休!な人もいるかと思います。
自分も10連休なんですが、諸事情により海外へキラキラ旅行とか行けないです。かなしみ。1
まあ、せっかくの休みなので、普段、仕事ではなかなかできないPostgreSQLまわりの調べ物や実験をしてみるのも良いかなと。
今回のお題はPostgreSQL 9.5から導入されたBRINを久々に見てみます。
BRINとは
PostgreSQLはB-Treeインデックスだけでなく、様々な用途向けのインデックスを提供しています(PostgreSQL文書のインデックスの種類参照)。
BRIN(Block Range INdex)はそうしたインデックス種別の一つで、テーブルの連続的な物理ブロックの範囲に格納された値についての要約を格納します。こうした格納形態のため、どんなケースでも有効というわけではなく、論理的な値の並びが物理的なブロックの並びと一致しているときに効果を発揮します。例えば、ログを蓄積するときのタイムスタンプなどは、典型的なBRINの適用パターンになります。
BRINはB-Treeと比較すると非常にインデックスサイズが小さいことが特徴です(後の検証結果でも取り上げます)。インデックスサイズが小さいということは、インデックスへの作成や更新の時間も小さくすることが期待できます。
検索時には、小さいサイズのインデックスをスキャンして、要約(例えば最大値/最小値)をもとに条件値がどのブロックに存在するかを判断します。そして、そのブロックに含まれるタプルをまず返却します。次の段階で、実際に与えられた条件に合致するか再評価します。
これをRecheckと呼びます。BRINを使った検索では、このRecheckの処理時間がけっこう大きな比率を占めることがあります。
BRINの詳細はPostgreSQL文書のBRINインデックスの章を読んでください。
今回の検証
今回は、挿入した順にタイムスタンプが単調増加するようなテーブルのタイムスタンプ列に対して通常のB-TreeインデックスとBRINを適用した場合の、
- インデックス作成時間
- インデックス更新時間
- インデックスを使った範囲検索
を比較してみようと思います。
検証環境
ハードウェア/OS
- 今回の検証環境にはAWS EC2の
t2.medium(CPU 2つ、メモリ4GB)を使用しています。 - OSはAmazon Linux 2を使っています。
- ディスクには
gp2(32GB、汎用SSD、IOPS 100)を使用。
PostgreSQL
- 検証に使用するPostgreSQLのバージョンは初版の事情により10.7にしています。
- 特に特殊なconfigureオプションは付与せずソースからビルドした版を使っています。
- データベースクラスタとWALのディスクは分けていません。
- PostgrSQLのパラメータは以下を除きデフォルトのままにしています。
- shared_buffers = 400MB # 実メモリの約10%
- max_parallel_workers_per_gather = 0 # あえてパラレルスキャンを無効にする
検証用テーブル
以下のような検証用テーブルtestを定義します。
CREATE TABLE public.test (
id INTEGER,
create_ts TIMESTAMP WITHOUT TIME ZONE,
data INTEGER,
filler CHARACTER(84)
)
- レコード自体の長さは100文字。
- id列にはあえてprimary key制約をつけないでおきます。
- 今回の検証ではFILLFACTORは100にしておきます。
挿入データ
検証用テーブルtestに、以下のようなINSERT文を使って、1000万件のデータを挿入します。
INSERT INTO test VALUES (
generate_series(1, 10000000), -- id
'2019-04-27 12:00:00'::timestamp + (generate_series(1,10000000) * interval '1 second'), -- create_ts
(random() * 100)::integer, -- data
repeat(' ', 84) -- filler
)
2つ目の列create_tsには、2019-04-27 12:00:00から1秒ずつ加算したタイムスタンプが1000万件挿入されます。この列の最大値は、2019-08-21 05:46:40となります。
1000万秒なんて、わりとあっさり過ぎちゃうものですね。
このINSERT文を実行すると、こんな感じのデータが格納されます。
id | create_ts | data | filler
----------+---------------------+------+--------------------------------------------------------------------------------------
1 | 2019-04-27 12:00:01 | 99 |
2 | 2019-04-27 12:00:02 | 9 |
3 | 2019-04-27 12:00:03 | 78 |
(中略)
9999998 | 2019-08-21 05:46:38 | 36 |
9999999 | 2019-08-21 05:46:39 | 38 |
10000000 | 2019-08-21 05:46:40 | 95 |
(10000000 rows)
なお、このテーブルの大きさは約1.4GBです。
testdb=# SELECT pg_relation_size('test');
pg_relation_size
------------------
1412415488
(1 row)
この状態で、testテーブルの各列のcorrelation(物理的な行の並び順と論理的な列の値の並び順に関する統計的相関。1または-1だと並びが完全に一致している。絶対値として0に近いと物理的な並びと論理的な並びの関係は弱くなる)を確認します。
testdb=# SELECT tablename, attname, correlation FROM pg_stats WHERE tablename = 'test';
tablename | attname | correlation
-----------+-----------+-------------
test | filler | 1
test | id | 1
test | create_ts | 1
test | data | 0.0139445
(4 rows)
create_tsは並びの相関が強く(1)、ランダムに値を設定したdata列は相関が弱い(0に近い)になっていることが確認できます。
今回は格納する件数を1000万件にしましたが、時間とディスク容量に余裕があれば、もっと多くの件数を格納するように、generate_series()の第2引数を大きくするといいんじゃないかと思います。2
インデックスの生成
1000万件のデータが格納されたこのテーブルのcreate_ts列に対して、インデックスを設定します。
B-Treeインデックスの場合には、以下のようにコマンドを実行します。3
CREATE INDEX ts_btree ON test USING btree (create_ts)
BRINの場合には、USING BRINに変更します。
CREATE INDEX ts_brin ON test USING BRIN (create_ts)
それぞれのインデックス生成時間とインデックス作成時間は以下のようになりました。
| インデックス種別 | 作成時間(ms) | インデックスサイズ(byte) |
|---|---|---|
| B-Tree | 9051.213 | 224,641,024 |
| BRIN | 1749.538 | 57,344 |
BRINの場合、作成時間もかなり短くなります。そしてこの検証モデルの場合、BRINのサイズはB-Treインデックスのなんと約4000分の1になります。
インデックスの更新
今度はデータが空の状態で、B-Treeインデックス/BRINを設定し、その状態で1000万件のデータを挿入したとき(「挿入データ」の節を参照)の時間を見てみます。比較用にインデックスを設定しない状態での挿入時間も示します。

インデックスなしのほうが、微妙にBRINよりも遅くなってますが(笑)、これは誤差の範疇でしょう。インデックスなしとBRINがある状態での挿入時間には、ほとんど差はありません。
対して、B-Treeインデックスが付与された状態での挿入時間には有意な差が見られます。
インデックス検索時間
さて、データ挿入に関してはBRINの優位性があるのは見えましたが、ではデータ検索についてはどうなのか。
今回は範囲検索のSELECT文をEXPLAIN ANALYZEで実行し、Execution timeと、Scan時のactual timeを比較してみます。
SQLはこんな感じのものです。
EXPLAIN ANALYZE SELECT COUNT(*) FROM test WHERE create_ts <= '2019-04-28'
cretae_tsに対して範囲検索を行いますが、以下のように範囲を変更して、それぞれの処理時間を見てみます。
| 指定日時 | ヒット件数 | 選択度 | 備考 |
|---|---|---|---|
| 2019-04-27 12:00:00 | 0 | 0% | 最小値は2019-04-27 12:00:01なので0件になる。 |
| 2019-04-27 12:30:00 | 1800 | 0.02% | |
| 2019-04-27 13:00:00 | 3600 | 0.04% | |
| 2019-04-27 15:00:00 | 10800 | 0.11% | |
| 2019-04-27 18:00:00 | 21600 | 0.22% | |
| 2019-04-27 21:00:00 | 32400 | 0.32% | |
| 2019-04-28 | 43200 | 0.43% | |
| 2019-04-30 | 216000 | 2.16% | さよなら平成。 |
| 2019-05-06 | 734400 | 7.34% | ああ・・・GWが終わる・・・。 |
| 2019-05-15 | 1512000 | 15.12% | |
| 2019-05-31 | 2894400 | 28.94% | |
| 2019-06-15 | 4190400 | 41.90% | |
| 2019-06-30 | 5486400 | 54.86% | |
| 2019-07-31 | 8164800 | 81.64% | B-Treeインデックスは使われなくなる。 |
| 2019-08-31 | 10000000 | 100% | 全県ヒットする。BRINも使われなくなる。 |
Execution time
選択度に対するExecution timeの結果を以下に示す。
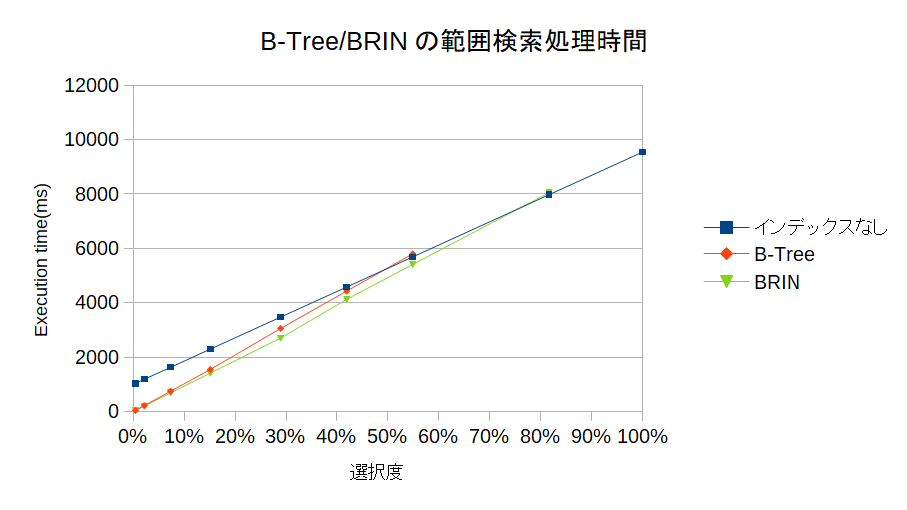
すごく大雑把に言えば、選択度が小さいうちは、当然ながらインデックスがないときよりもB-treeインデックス/BRINがあるほうが処理時間は小さい。
スキャン処理時間
Executoin timeだとCOUNT(*)処理も含まれてしまうので、スキャン処理そのものの時間を見たほうが比較はしやすそうだ。
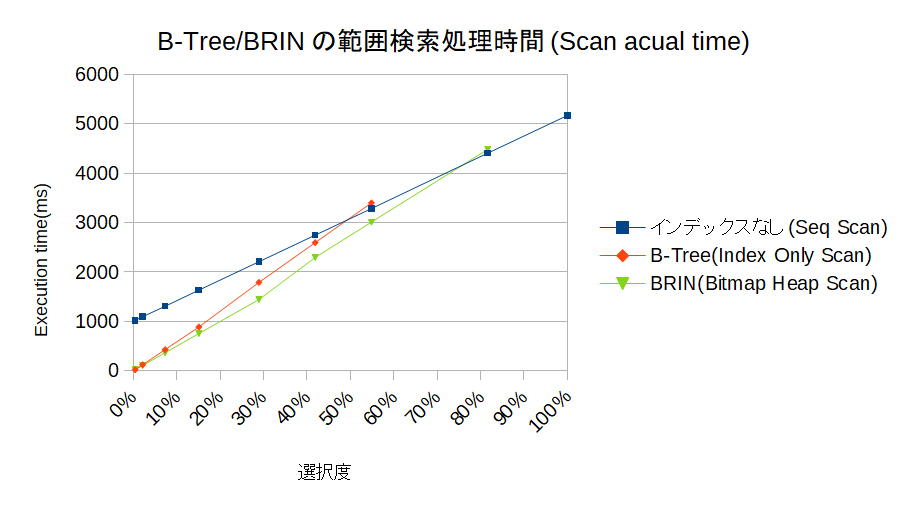
絶対値は違うけど、傾向はほぼ同じ。
そもそもなんで、インデックスなしのときに選択度の違いによって、Seq Scanの処理時間がここまで異なるのか。そもそもインデックスなしなら、選択度がどうあれリードするテーブルのブロック数は同じはず・・・。
と思っていたのだけど、どうやら、(少なくとも)この検証環境においては、データをタプル化する処理+タプル化したデータを評価する処理が、かなり重いようなのだ。
選択度の極めて小さい区間(0%~0.5%)に着目すると、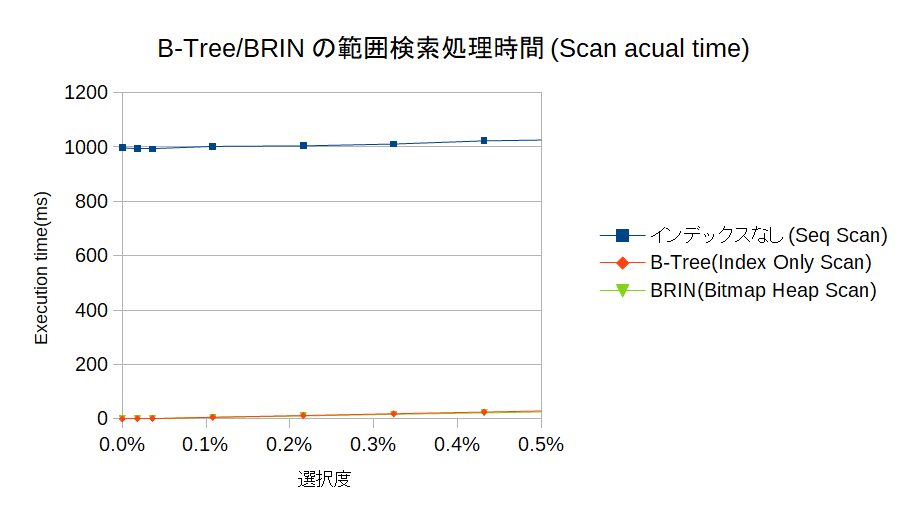
のような結果になる。Seq Scan処理そのものはだいたい1秒くらい。
推測
このテーブルのサイズは約1.4GB。shared_buffersには乗り切らないサイズではあるが、OSのメモリ(約4GB)よりは小さいので、OSキャッシュに乗った状態でスキャンされているのかもしれない。なので、Seq Scanであってもスキャンの時間は1秒程度で済むのだろう。それよりも、データをタプル化する処理+タプル化したデータを評価する処理が支配項になっていると推測される。
B-TreeインデックスとBRINのスキャン処理時間比較
で、肝心のB-TreeインデックスとBRINとの処理時間の比較結果を見るために、さきほどのグラフからB-TreeインデックスとBRINのみを拡大して表示してみる。
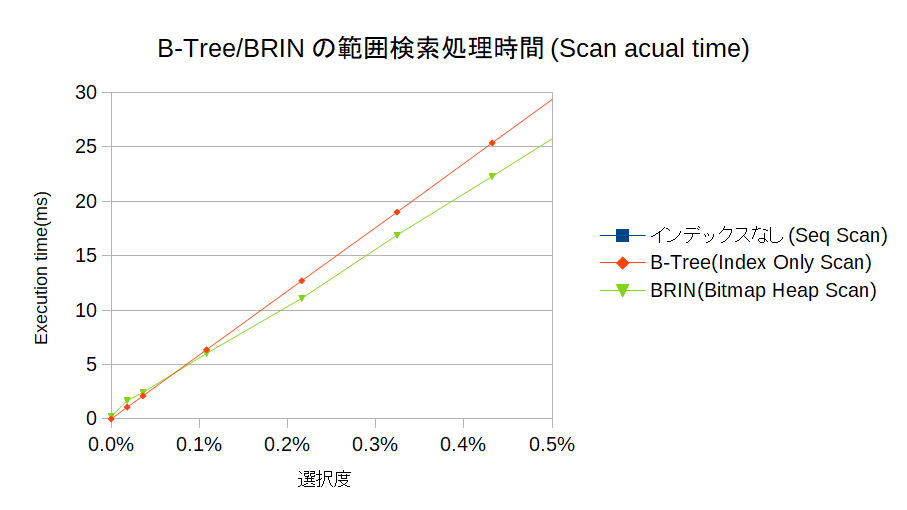
これでも少し見づらいけど、選択度が0.1%までは、B-Treeインデックスが処理時間が小さく、それを超えるとBRINが有利になってくる。
本当に1件しかヒットさせたくないような条件(あるいは、MIN/MAXを求める)なら、B-Treeインデックスが適しているが、連続した範囲検索をするなら(それほど広い範囲でなくても)BRINのほうが適しているという結果となった。
ただ、BRINの効果を体感的に得るのであれば、この程度のテーブルサイズでは小さすぎるかも。数十GB以上のテーブルにならないと、範囲検索の性能向上のメリットは小さそうだ。
まとめ
- 物理的な並びと論理的な並びが完全に一致するようなケースでBRINを使うと、以下のような効果がある。
- インデックス作成時間の短縮
- インデックスサイズの大幅な削減
- インデックスが設定された状態でのデータ挿入時間がインデックスなしと大差なくなる。
- ある程度の件数を取得する範囲検索であれば、B-Treeインデックスよりも処理時間が短縮できる。
- テーブルのサイズとしては、数GBレベルではあまりメリットは感じられないかも。
- (本題とは関係ないけど)ヒット件数が多くなる条件の場合のタプル生成と評価の処理は意外と重い(環境によるのかもしれないが・・・)
おわりに
今回は、特にBRINのチューニングやBRIN固有のメンテナンスについては説明しませんでした。次回はそのへんの話をしたいと思います。
おそらく、この記事が平成最後のQiita記事になると思います。
令和でまた会いましょう!