はじめに
にゃーん。趣味でポスグレをやっている者だ。
この記事はPostgreSQL 16 全部ぬこ Advent Calendar 2022 9日目の記事です。
今回はcontribモジュールpgbuffercacheにPostgreSQL 16で入った新規関数について書いてみます。
概要
| 項目 | 内容 |
|---|---|
| タイトル | PG16:Summary function for pg_buffercache |
| Topic | Monitoring & Control |
| ステータス | commited |
| Last Modified | 2022-10-13 |
| 概要 | contrib/pg_buffercacheに サマリ情報を返却する関数 pg_buffercache_summary()が追加された |
変更内容
pg_buffercacheとは
pg_bufferchacheはPostgreSQLの共有バッファの内容をモニタリングするための拡張機能(contribモジュール)です。
この拡張機能は、PostgreSQL 8.3からサポートされている結構歴史のあるものです。
参考:PostgreSQL 14文書のpg_buffercacheのページ
現状の問題
PostgreSQL 15までは、pg_buffercharでキャッシュ全体の傾向(dirtyページがどのくらいあるか等)を取得しようとすると、
pg_buffercacheによってキャッシュページを全スキャンした結果を集約するクエリを書く必要がありました。
最近はハードウェアのスペックも上がり、共有バッファに大きなサイズを割り当てることも多いと思います。
そうした環境だと、ppg_buffercacheの結果を集約するコストはけっこう高くなります。
定期的にそうした監視を行うのであれば、その辺りのコストは下げたいもの。
pg_buffercache_summary関数
ということで、PostgreSQL 16から、pg_byffercahceの内容をサマライズした結果を出力するpg_buffercache_summary関数が追加されました。
この関数は引数なしで実行し、以下の5つ列をもつ1行のレコードを返却します。
| 列名 | 型 | 意味 |
|---|---|---|
| buffers_used | integer | 有効なrelfilenodeを持つバッファの数(ダーティと非ダーティの両方) |
| buffers_unused | integer | 無効なrelfilenodeを持つバッファの数 |
| buffers_dirty | integer | ダーティバッファの数 |
| buffers_pinned | integer | バックエンドを少なくとも1つピン留めしているバッファの数 |
| usagecount_avg | double precision | 使用済みバッファの平均使用量 |
実行結果はこんな感じになります。
=# \x
Expanded display is on.
=# SELECT * FROM pg_buffercache_summary();
-[ RECORD 1 ]--+------------------
buffers_used | 4278
buffers_unused | 12106
buffers_dirty | 2072
buffers_pinned | 0
usagecount_avg | 1.548153342683497
=#
この関数を使用しない場合には、以下のような集約クエリで同等の結果を得ることができます。
=# SELECT relfilenode <> 0 AS is_valid, isdirty, count(*) FROM
pg_buffercache GROUP BY relfilenode <> 0, isdirty;
is_valid | isdirty | count
----------+---------+-------
t | f | 2206
| | 12106
t | t | 2072
(3 rows)
=#
- 1行目と3行目を加算したものが、
buffers_used - 2行目が
buffers_unused - 3行目が
buffers_dirty
に相当してますね。
また、このクエリだとbufferd_pinnedとusagecount_avgに相当する情報は出力されません。それらを取得するためには別のクエリが必要になるようです。
検証
では、pg_bufferchacheの結果を集約したクエリと、pg_buffercache_summary()の実行時間を雑に比較してみます。
- shared_buffersを64MB, 128MB, 256MBに変更して、PostgrerSQLサーバを起動する。
- 起動直後に、pgbenchの初期化(Scalefactor=100)を実行する。
pgbench --unlogged-table -i -s 100
- pgbench実行直後に、
\timingオプションをつけてpg_buffercacheを集約したクエリと、pg_buffercache_summary()を実行し処理時間を測定する。
| shared_buffers | pg_buffercache集約 | pg_buffercache_summary |
|---|---|---|
| 64MB | 4.949 | 0.561 |
| 128MB | 8.432 | 0.691 |
| 256MB | 15.033 | 0.827 |
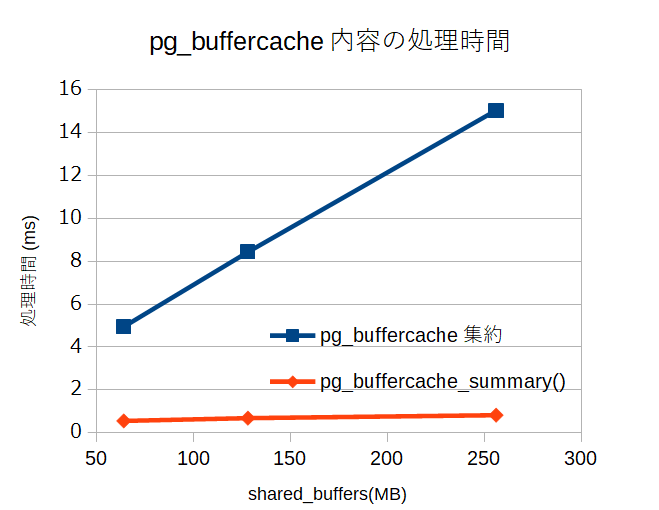
こうかはばつぐんですね。
検証した環境だと、shared_buffersにそれほど大きな値が設定できないので、集約関数を使ってもそれほど処理時間はかからないのですが、それでも、pg_buffercache_summary()を使う方が圧倒的に高速に処理できることがわかりました。
ハイスペックで数百GBのhared_buffersを設定可能な環境だと、pg_buffercache_summary()の恩恵は大きなものになりそうです。
おわりに
今回はpg_buffercache拡張機能に追加されたサマリを取得する関数について説明しました。
この関数を使ったバッファ監視の運用などを考えてみるのも面白いかもしれません。