はじめに
にゃーん。趣味でポスグレをやっている者だ。
この記事はPostgreSQL 16 全部ぬこ Advent Calendar 2022 17日目の記事です。
今回はハッシュインデックス作成時の性能改善について書いてみます。
概要
| 項目 | 内容 |
|---|---|
| タイトル | Hash index build performance tweak from sorting, part II |
| Topic | Performance |
| ステータス | commited |
| Last Modified | 2022-11-24 |
| 概要 | ハッシュインデックス作成時の性能改善 |
変更内容
MLを見ると、
Adding this patch makes a CREATE INDEX about 8-9% faster, on an unlogged table.
と書いてあった。
ということで手元の環境で比較してみました。
測定方法
- 手元の環境でUNLOGGED TABLEを作成し、以下のような100万件のデータを挿入。
CREATE UNLOGGED TABLE test (id int primary key, i_data int, n_data numeric, t_data text);
INSERT INTO test VALUES
(generate_series(1, 1000000), (random() * 10000)::int, random() * 10000, generate_random_text(72));
- i_dataはinteger型、値域を0~10000の範囲にして、ある程度同じ値のハッシュが生成されるようにする、
- n_dataはnumeric型にして、ほとんど同じ値のハッシュが生成されないことを想定。
- t_dataはtextにしてランダムな72バイト文字を挿入。1
- i_data列, n_data列, t_data列を対象とするハッシュインデックスを
CREATE INDEX ... USING hashで5回作成し、その作成時間(\timingで取得)の平均を取得。
\timing
CREATE INDEX hash_ind ON test USING hash (i_data);
DROP INDEX hash_ind;
CREATE INDEX hash_ind ON test USING hash (n_data);
DROP INDEX hash_ind;
CREATE INDEX hash_ind ON test USING hash (t_data);
DROP INDEX hash_ind;
- これを、PostgreSQL 15 beta1, PostgreSQL 15.0とPostgreSQL 16で比較した。
比較結果
- えぇ・・・PostgreSQL 15 beta1よりも、PostgreSQL 15/PostgreSQL 16が有意に遅く見えるんですが・・・。
- MLだと8~9%程度の向上が見込めるって書いてあったのですが。
- どのデータ型のケースでも傾向は同じ。
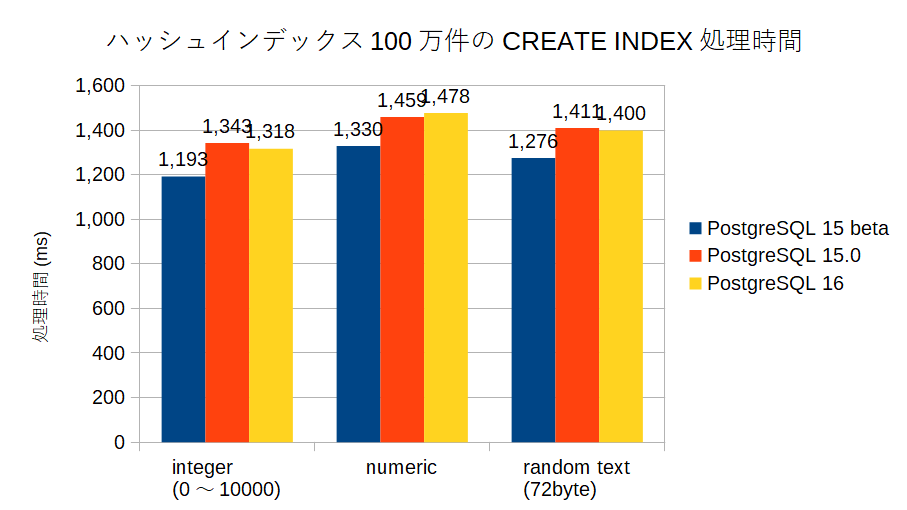
うーん、何か測定環境や、測定方式(ハッシュインデックス対象の列、CREATE INDEXのやり方)に問題があるのだろうか・・・。
それとも、開発コミュニティに報告すべきなんだろうか。
おわりに
うーん。今回の調査では、今ひとつ納得できる結果がとれませんでした。
beta版がでたあたりで測定方法の見直しも含めてリトライするか・・・にゃーん。
-
ランダムな文字列の生成は以下のpl/pgsql関数を使いました。
https://github.com/nuko-yokohama/pg_scripts/blob/master/generate_random_text.sql ↩