はじめに
pg_bigmを用いて、PostgreSQL 12の改善項目を再確認してみた。
pg_bigmとは
すごくざっくり言ってしまうと、pg_bigmというのは、PostgreSQLで日本語全文検索を実現する拡張モジュールです。
PostgreSQL自体には、英文に対応した形態素全文検索機能はあります。また、英文に対応したN-Gramの全文検索機能として、pg_trgmというcontrib拡張機能はあります。
が、残念ながら日本語に対応したN-gram方式の全文検索機能はありません。pg_bigmは日本語に対応したN-gram方式の全文検索機能(全文検索インデックス)を提供するものです。
pg_bigmの(個人的に思う)一番の特徴は、これを入れるだけで、LIKE中間一致検索が爆速になる、というものです。このへんは後で実例を見たほうが早いかな。
PostgreSQL 12における改善項目
PopstgreSQL 12 beta1が5月にリリースされ、リリースノートも公開されました。
https://www.postgresql.org/docs/devel/release-12.html
そのリリースノートの中に
Reduce the WAL write overhead of GiST, GIN and SP-GiST index creation (Anastasia Lubennikova, Andrey V. Lepikhov)
という項目があります。要は全文検索インデックスなどで使われるGINインデックス生成時のWALサイズを削減する、という項目です。これについては、PostgreSQL 12 beta1がリリースされる前に、ちょっとだけ調べたのですが(PostgreSQL 12がやってくる!(3) - GINインデックスのWALサイズ削減 参照)beta1もでたことだし、身近にGINインデックスを使う例として、N-gram方式の全文検索インデックスを使うpg_bigmを使って、再確認してみることにしました。
今回の検証
- pg_bigmによってGINインデックスを作成するときのWALサイズをPostgreSQL 11とPostgreSQL 12で比較する。
- GINインデックス作成時間をPostgreSQL 11とPostgreSQL 12で比較する。
- (おまけ)pg_bigmによる全文検索処理時間を比較する。
題材
例によって(?)、青空文庫の通称「吉川三国志」のテキストを使います。
なぜ、これを選んだのかというと、単に自分が三国志が好きだから・・・というのと、ほどほどに大きいサイズのテキストデータだから。
大雑把な手順
- 青空文庫の吉川三国志テキストデータを、PostgreSQLにロードする。
- pg_bigmモジュールを組み込む。
- 一旦、PostgreSQLを停止させる。
- pg_resetwal ユーティリティを使ってWALを初期化する。
- PostgreSQLを再起動させる。このときのWALセグメントファイルの数や、LSNの位置を記録しておく。
- CREATE INDEXコマンドで、pg_bigmが提供するメソッドを用いてBi Bram(2文字に分解されたGIN転置インデックス)を作成する。そのときの時間をpsqlの \timing メタコマンドで測定しておく。
- インデックス作成後のWALセグメントファイルの数や、LSNの位置を記録しておく。
- ついでにインデックスサイズを測定しておく(バージョンによる違いはないはず)。
- この状態で、ついでに全文検索を3回実施して実行時間(EXPLAIN ANALYZEのEecution time)を測定しておく。
- 上記の手順を、PostgreSQL 11とPostgreSQL 12 beta1で実施する。
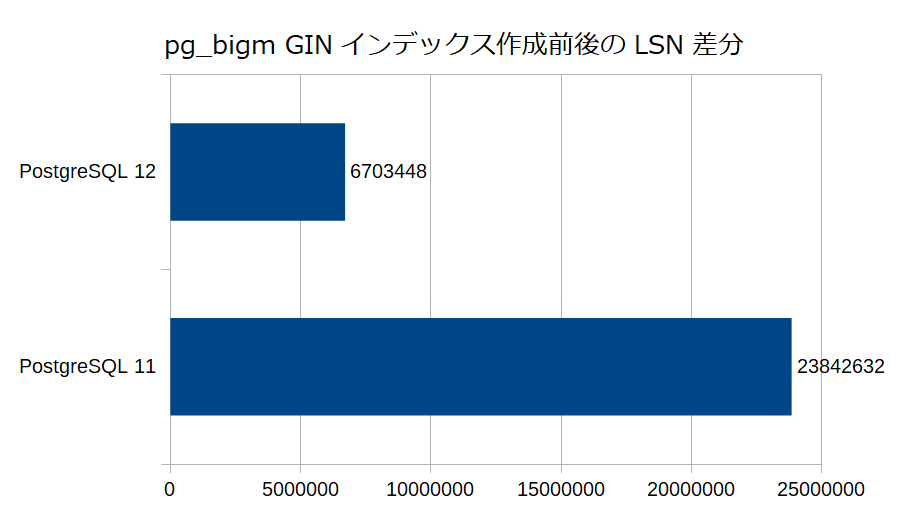
結果(インデックス作成時のWALサイズ)
結果(インデックス作成時間)
インデックスの作成時間は以下のようになる。

インデックスの作成時間には、すごく乱暴に言えば
- インデックス作成元になるテーブルのサイズ(読み込み時間)
- 作成されるインデックスのサイズ(書き込み時間)
- インデックス作成のWALサイズ(書き込み時間)
- その他(インデックス作成のためのCPU時間)
あたりが影響するんではないかと思う。ということで、インデックス作成元のテーブルのサイズ、生成されたインデックスサイズ、インデックス生成時のWALサイズを合わせてプロットしてみた。

こうやってみると、WALサイズの差の割には、生成時間への影響は思ったより小さい気もする。インデックス作成自体のCPU処理が思ったよりも重いのかな?
結果(検索時間)
生成された全文検索インデックスの内容は変わらないはずなので、検索時間もそれほど変わらないはずだが、PostgreSQL 12にはとってもゆるい感じで、以下の改善項目がリリースノートに掲載されている。
Improve search performance for multi-byte characters (Heikki Linnakangas)
これが、pg_bigmによる全文検索インデックスを使った検索にどの程度関係しているのかは(ソース等を確認していないので)不明だがpg_bigmによる検索性能に変化がないか、以下のクエリを(キャッシュに乗せた状態で)3回実行しそのExection Timeの平均をとって確認してみた。
EXPLAIN ANALYZE SELECT * FROM sangokushi WHERE data LIKE '%兀突骨%';
このクエリによって41747行の吉川三国志テキストから、13行の検索結果が得られる。
検索時間の測定結果は以下のとおり。僅かではあるがPostgreSQL 12での検索性能がよくなっている。

この結果が、上記に挙げた"Improve search performance for multi-byte characters"の賜物なのかはきちんと調べてはいないが、少なくとも、pg_bigmをPostgreSQL 12環境に適用して、大きな問題はなさそうだ。
おわりに
- pg_bigmをPostgreSQL 12に適用しても大きな問題はなさげ。
- やっぱり吉川三国志は面白いなー。