機械学習向けコンパイラ
TensorFlow XLAやTVMをはじめとして、ユーザが作成した機械学習モデルをもとに、機械学習の演算に特化したハードウェアへ最適な実行コードを出力する「機械学習向けコンパイラ」が、少しづつ注目を集めてきています。
機械学習向けコンパイラは、機械学習特有の計算グラフレベルでの最適化、ハードウェアの特性を活かした最適化が可能になるprimitiveな演算セットレベルでの最適化という、2段階で最適化することにより、次々と登場する機械学習向けのハードに最適なバイナリを生成します。
本記事で取り上げる Glowコンパイラ は、Facebookが中心となってOSSとして開発する機械学習向けコンパイラの1つです。
それぞれのコンパイラには特性があり、厳密に最適化のレベルを区切ることはできませんが、世の中の機械学習向けコンパイラと最適化レベルは、おおよそ以下のようにまとめることができます。
| 機械学習向けコンパイラ | 機械学習特有のグラフレベルでの最適化 | primitiveな演算セットレベルでの最適化 |
|---|---|---|
| TensorFlow XLA | High Level Optimizer(HLO) | Low Level Optimizer(LLO) |
| NNVM/TVM | NNVM(Relay) | TVM |
| Glow | GraphOptimizer | IROptimizer |
本記事では、最初にGlowの内部で行っている処理の概要を説明します。
そして、Glowを実際にインストールした後、Glowを使って簡単なONNX形式のモデルを実行し、動作を確認します。
Glowがサポートするモデル形式
Glowは、本記事執筆時点で ONNX形式モデル とCaffe2形式のモデルの読み込みをサポートします。
Glowの内部構造
構成

Glowは、ONNXModelLoader と Caffe2ModelLoader を使って、ONNXやCaffe2で作成したモデルを読み込みます。ONNXModelLoader と Caffe2ModelLoader によって読み込まれたモデルは、Glow内部で利用されるモデルに変換され、モデルの実行を担う ExecutionEngine に渡されます。ExecutionEngine は、渡されたモデルを GraphOptimier や IROptimizer を使ってバックエンドに最適なコードに変換し、CPUやOpenCLなどのバックエンドで実行します。
サポートするバックエンド
Glowがサポートするバックエンドは、lib/Backends に置かれているファイルから確認することができます。
本記事執筆時点では、CPUとOpenCLの2つのバックエンドをサポートしています。
IR
Glowは、High-Level IRとLow-Level IRの2つの中間表現を持ちます。

High-Level IR
High-Level IRは、機械学習の領域に特化された演算ノードから構成される、デバイスに非依存なIR(計算グラフ)です。High-Level IRは、ConvolutionやBatchNormなどのニューラルネットワークの演算から構成されます。
High-Level IRの各データ構造の定義は、include/glow/Graph を参照することで確認できます。
例えば、計算グラフは glow::Function によって定義されます。glow::Function のメンバ変数では NodesList は、AddやConvolutionに対応するノードのリストであり、複数のノードから構成される計算グラフであることを示しています。
/// Represents the compute graph.
class Function final : public Named {
/// A list of nodes that the Function owns.
NodesList nodes_;
/// Stores a list of unique node names that were used by the module at some
/// point.
llvm::StringSet<> uniqueNodeNames_{};
/// A reference to the owner of the function.
Module *parent_;
// ...
};
Low-Level IR
Low-Level IRは、High-Level IRから線形代数演算レベルに分解された演算のリストから構成されます。Low-Level IRは、High-Level IRよりもprimitiveな演算ノードから構成されるため、デバイスに依存した最適化を行うことが可能になります。
Low-Level IRの各データ構造の定義は、include/glow/IR に置かれています。
最適化
GlowはHigh-Level IRとLow-Level IRのそれぞれについて、2段階で最適化を行うことにより、デバイスに最適な実行コードを生成します。
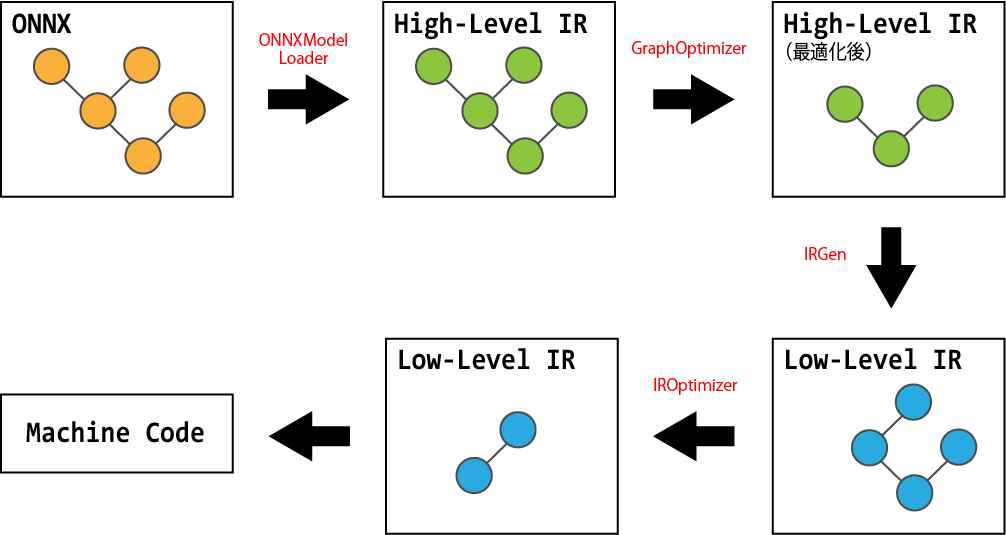
- High-Level IR Optimization(GraphOptimizer)
- Low-Level IR Optimization(IROptimizer)
Glowによって行われる最適化処理は、docs/Optimizations.md にも記述されています。
これらの最適化処理は、lib/ExecutionEngine/ExecutionEngine.cpp で定義されている glow::ExecutionEngine::compile メソッドで行われます。
void ExecutionEngine::compile(CompilationMode mode, Function *F, Context &ctx) {
// GraphOptimizer(High-Level IR Optimization)
optimizeFunction(mode, F);
ctx.allocate(M_.getPlaceholders());
// IROptimizer(Low-Level IR Optimization)
function_ = backend_->compile(F, ctx);
}
ここで backend_ は、Glowグラフを実行するバックエンドを示しているため、IROptimizer がバックエンドに依存した最適化であることが何となく想像できるかと思います。
GraphOptimizer
Glowは最初に、High-Level IRレベルでデバイスに非依存な最適化を行います。
最適化処理を担うのがGraphOptimizerで、以下に示す最適化を適用します。
- Dead Code(Node)の削除
- 共通部分式削除
- ノード融合
- 複数のMatmulノードを、1つのMatmulノードに変換
- 複数のAddノードを、1つのAddノードに変換
- 連続するConcatノードを1つのConcatノードに変換
- 推論演算の特性を活かした最適化
- BatchNormノードを、Convolutionノードに変換
- Transposeノードの定数畳み込み
- 代数的恒等式を活用した最適化
- 冗長ノードの削除
- Splatノードに対するSliceノードの削除
- 冗長なReshapeノードの削除
- 冗長なQuantization関連のノードを削除
- TransposeノードをMatmulノードへマージ
GraphOptimizerによる最適化処理の実装は、lib/Optimizer/GraphOptimizer.cpp の glow::optimize 関数から確認することができます。
void glow::optimize(Function *F, CompilationMode mode) {
while (sinkCode(F)) {
// Perform Dead Code Elimination between rounds of code sinking.
DCE(F);
}
// Optimize the pooling operation.
optimizePool(F);
// Perform Common Subexpression Elimination.
CSE(F);
// ...
}
IROptimizer
GraphOptimizerによって最適化されたHigh-Level IRから、Glowはよりprimitiveな演算のリストで表現されるLow-Level IRを生成します。
Low-Level IRの生成処理はバックエンドに依存しますが、ここではCPUをバックエンドとした場合について、Low-Level IRの生成処理を取り上げます。
CPUのLow-Level IR生成処理は、lib/Backends/CPU/CPUBackend.cpp に定義されている CPUBackend::compile の延長で呼び出される glow::generateAndOptimizeIR 関数で行われています。
std::unique_ptr<CompiledFunction>
CPUBackend::compile(Function *F, const Context &ctx) const {
// Low-Level IRの生成と最適化
auto IR = generateAndOptimizeIR(F, shouldShareBuffers());
// 最適化されたLow-Level IRからCPUのバイナリコードへコンパイル
return compileIR(std::move(IR), ctx);
}
glow::generateAndOptimizeIR 関数の中では glow::optimize 関数が呼ばれていますが、glow::optimize 関数で行っている処理そのものが、IROptimizerです。
std::unique_ptr<IRFunction>
glow::generateAndOptimizeIR(Function *F, bool shouldShareBuffers) {
auto IR = llvm::make_unique<IRFunction>(F);
IR->generateIR();
// Low-Level IRの最適化
::glow::optimize(*IR, shouldShareBuffers);
return IR;
}
IROptimizerによって行われる最適化処理は、以下の通りです。
- ピープホール最適化
- Dead Storeの削除
- メモリ最適化
- IRコードに適したテンソル表現への置き換え
- 直前の演算で使用したメモリ領域の再利用
- メモリのライフタイム短縮
- 不要なメモリ確保処理の削除
- 更新されない変数を定数化
IROptimizerによる最適化処理の詳細は、lib/Optimizer/IROptimizer.cpp の glow::optimize 関数を参照することで確認できます。
void glow::optimize(IRFunction &M, bool shouldShareBuffers) {
M.verify();
if (!optimizeIR)
return;
performPeepholeOptimizations(M);
eliminateDeadStores(M);
// Replace applicable InsertTensors and ExtractTensors with TensorViews.
optimizeInserts(M);
optimizeExtracts(M);
// ...
}
Glowを使ってみる
環境
- Ubuntu 16.04.3 LTS
Glowのインストール
Glowは、ソースコードからビルドしてインストールする必要があります。
Glowをソースコードからビルドする方法は、GlowのGitHubのトップページ に記載されているため、これに従います。
今回は、Glowをデバッグビルドしていますが、リリースビルドする場合は -DCMAKE_BUILD_TYPE=Debug を -DCMAKE_BUILD_TYPE=Release とする必要があります。
# ソースコードを取得
$ git clone git@github.com:pytorch/glow.git
# サブモジュールの更新
$ cd glow
$ git submodule update --init --recursive
# LLVMのビルド(ビルド時に生成されたバイナリはllvm_installに置かれています)
$ cd utils
$ bash build_llvm.sh
# Glowのビルド
$ cd ../..
$ mkdir build_Debug && cd build_Debug
$ cmake -G Ninja -DCMAKE_BUILD_TYPE=Debug -DCMAKE_PREFI_PATH=../glow/utils/llvm_install/ ../glow
$ ninja all
ONNX形式のモデルを作成
Glowで実行するONNX形式のモデルを作成します。
すでに多くのONNX形式のモデルが世の中に公開されていますが、Glowの内部動作を理解するためには少々複雑なモデルであるため、ここでは簡単なONNX形式のモデルを作り、作ったONNX形式のモデルをGlowで実行してみたいと思います。ONNX形式のモデルを作る方法については、ONNX形式のモデルを扱う も参照してください。
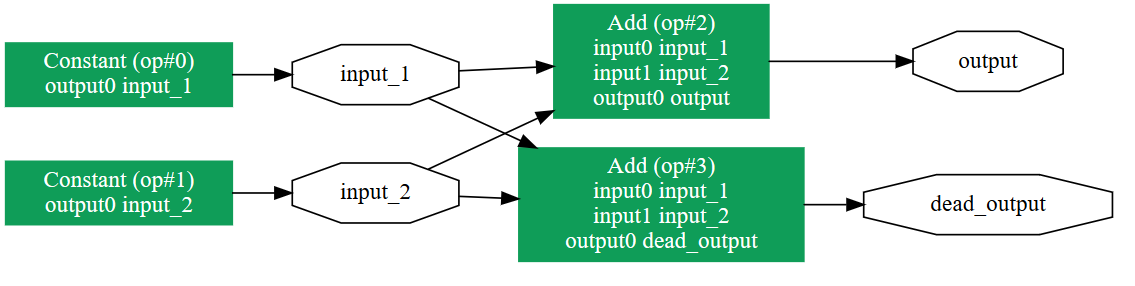
今回は、以下のように定数値同士の足し算を行って出力するだけの計算グラフを作ります。
Glowの最適化機能を確かめるため、実行されない演算を定義しています。
input_1 = [1.4, 3.7, 19.2]
input_2 = [50.3, 10.7, 9.4]
output = input_1 + input_2
dead_output = input_1 + input_2 ★実行されない演算
以下のスクリプトを実行し、ONNX形式のモデルを作ります。
import onnx
import onnx.helper as oh
from onnx import checker
out_path = "glow_test_model.onnx"
def main():
# 定数テンソル定義
const_tensors = [
oh.make_tensor(name="const_tensor_1", data_type=onnx.TensorProto.FLOAT,
dims=[3], vals=[1.4, 3.7, 19.2]),
oh.make_tensor(name="const_tensor_2", data_type=onnx.TensorProto.FLOAT,
dims=[3], vals=[50.3, 10.7, 9.4]),
]
# 出力テンソル定義
out_tensors = [
oh.make_tensor_value_info("output", elem_type=onnx.TensorProto.FLOAT, shape=[3]),
]
# ONNX形式のモデル構築
nodes = []
nodes.append(oh.make_node("Constant", inputs=[], outputs=["input_1"], value=const_tensors[0]))
nodes.append(oh.make_node("Constant", inputs=[], outputs=["input_2"], value=const_tensors[1]))
nodes.append(oh.make_node("Add", ["input_1", "input_2"], ["output"]))
nodes.append(oh.make_node("Add", ["input_1", "input_2"], ["dead_output"])) # Dead Node
graph = oh.make_graph(nodes, "Glow Test Graph", [], out_tensors)
checker.check_graph(graph)
model = oh.make_model(graph, producer_name="AtuNuka", producer_version="0.1")
checker.check_model(model)
# モデルを保存
with open(out_path, "wb") as f:
f.write(model.SerializeToString())
if __name__ == "__main__":
main()
作成した、ONNX形式のモデルを 可視化 した結果を見ると、正しくモデルを作成できているようです。
作成したONNX形式のモデルを実行することで、以下のような結果が得られることが期待値です。
[51.7, 14.4, 28.6]
ONNX形式のモデルを実行
作成したONNX形式のモデルを、Glowを使って実行します。
Glowには、ONNX形式のモデルを読み込んで実行するためのツール model-runner が用意されていますので、model-runner を使ってONNX形式のモデルを読み込んで実行したいと思います。
作成したONNX形式のモデルのパスが /onnx_model_path/glow_test_model.onnx であれば、以下のコマンドを実行することにより、作成したONNX形式のモデルを実行することができます。
なお、今回は -cpu オプションを指定し、CPUをバックエンドとして実行します。
$ build_Debug/bin/model-runner -cpu -model=/onnx_model_path/glow_test_model.onnx
実行結果
ONNXモデルを実行すると以下のような期待した出力が得られ、作成したONNX形式のモデルが正しく実行できていることを確認できました。
Model: /onnx_model_path/glow_test_model.onnx
shape: ( 3 )
max: 51.700 min: 14.400
[51.700, 14.400, 28.600, ]
最適化後のHigh-Level IR
ここで、Glowによって最適化された後の計算グラフを出力し、GraphOptimizerの効果を確かめます。
GraphOptimizerによって最適化された計算グラフは、-dumpGraph オプションをつけて実行することで確認することができます。-dumpGraph オプションをつけて出力した結果を以下に示します。
Graph structure /onnx_model_path/glow_test_model.onnx:
Add
name : output
LHS : float<3>
RHS : float<3>
users : 1
Result : float<3>
Save
name : save_output
Input : float<3>
Output : float<3>
users : 0
出力結果を見ると、Addノードが1つしか表示されていないことが確認できます。
もう1つのAddノードについては、GraphOptimizerによってDead Nodeであると判断され、削除されたものと判断できます。
また、Glowによって最適化された計算グラフは、-dumpGraphDAG オプションを利用することによって画像化することもできます。
PlaceholderやSaveといった、Glowで内部で作られるノードが追加されていますが、Dead NodeであるAddノードの1つが削除されていることを確認できます。

最適化後のLow-Level IR
-dump-ir オプションを使って、IROptimizerによって最適化された後のLow-Level IRを出力することもできます。
function /root/glow_test_model.onnx
declare {
%input_1 = WeightVar float<3> const // size: 12 // Users: @in 0
%input_2 = WeightVar float<3> const // size: 12 // Users: @in 0
%save_output = WeightVar float<3> mutable // size: 12 // Users: @out 0
; size = 36 bytes
}
code {
0 %output = elementadd @out %save_output, @in %input_1, @in %input_2
}
おわりに
機械学習向けコンパイラであるGlowの内部構造を紹介し、簡単なONNX形式のモデルを実行して、結果が期待したものになっていることを確認しました。また、Glowによって最適化されたHigh-Level IRやLow-Level IRを出力することによって、Glowが内部で行っている最適化処理の一部を確認することができました。
最適化処理のソースコードは、工夫の塊で読んでいて楽しいものですが、実際に最適化されそうなモデルを作って、期待した最適化処理が動いているのを確かめるのも面白いと感じました。
現状Glowは発展途上であることから、サポートするモデルの形式やバックエンドが少ない状況です。今後Glowの開発が進み、TensorFlow XLAやTVMのように、サポート範囲が増えていくことを期待したいと思います。