開発環境
"react": "^18.2.0",
"typescript": "^4.9.5",
問題の形式
ChatGPTを使用して以下の文言を各毎回投げるとします。
問題自体を自動生成してくれるのでテンプレートだと楽ですね。
以下のコードの基本的な処理から応用的な処理の問題を4個出して欲しい、
言語 javascript typescript
問題として使用したいメソッド 「」
こちらから使用するメソッドを指定するからこれで問題出してほしい、特にヒントはいらない、問題だけ4個出して欲しい。
オブジェクトと配列に関してはサンプル程度のを問題と一緒に用意して欲しい。
詰まるか答え合わせが必要になった時はまた送信するからレビューして。
問題の出題は以下と同様の形式でお願いしたいな。
// 問題1: 汎用的な配列を逆順にする関数
// サンプル配列:
const sampleArray1 = [1, 2, 3, 4, 5];
// 関数を書いてください。
// 問題2: 二つの配列からオブジェクトを生成する関数
// サンプル配列:
const keys = ["a", "b", "c"];
const values = [1, 2, 3];
// 関数を書いてください。
今回実行してみたコード一覧。
上記テンプレートで、今回はtypescriptのジェネリクス型を指定してみました。
網羅的な出題だったため、こんな感じで使えるんだとは参考になるかなと思います。
ここでマイルール。
毎回ただconsole.logだとTSの勉強にならんなぁと考えたので、
関数化までしっかり書いてから実行したいと思います。
そもそもジェネリクスってなんの役割が??
ちょっと端から端まで読んでみると割と長い... サンプルなんかを用いてと考えましたが割と長くなりそうなので...
結論から言うと「型と安全性とコードの共通化」が可能であると言うことでいいみたい。
色々な型で同じコードを使うと、コードを型の安全性が犠牲になる。
逆に、型の安全性を重視しようとしすぎると、同じような内容のコードを何個も用意しなくてはならず、共通化ができなくなる。
こう言う問題を解決したのが、ジェネリクス型なんですって。
ちなみにプライベートでも薬局なんかでよく聞くワードなんですけど、調べてみたら
ジェネリック=「汎用」、「後発品」 と言う意味らしいです。
意外と中途半端な理解の横文字なんですけど、こう意味がわかるとまた理解度が変わるんじゃないだろうかって言うのが僕の最近の意見です。
ジェネリック医薬品の方はおそらく「後発品」に該当する意味合い。
今回のTS ジェネリクスは「汎用」の意味合いでいいんじゃないかな。
anyとジェネリクスって何が違うんだよって言う話
確かに上記した説明みたらまぁ汎用性ね〜OK〜となりそうなものなんですけれど....
そんなにわざわざ汎用性求めるならそこの特定の関数だけanyで書いちゃえばいいじゃん....とも思ってました。
まずハマったこと(TSXファイル使ってる方向けの内容です)
実は以前もジェネリクスについて学習してみようと思ったことはあったのですが、、下記の状態で完全にハマってしまい学習やめてしまってました。 意外と知らない方が多かったのでここで書いてみますね。。
今回掲載しているサンプルコードはあくまでも実行処理だけなので、React環境のApp.tsx内に記述。
ここ最近はReact環境で配列処理なんかも学習してます。(単純にReact以外でTS使用する環境構築わからないからこれもやってないだけなんですけどね)
ジェネリクスの書き方としてまず
<T,>(arr: T[]):
これがあるのですが、TSXでは正規表現の問題があるらしくてカンマが必須のようです。
関数だけをutilisに分けて、.tsが拡張子のファイルの場合にはこちらのカンマが不要。
,が抜けている状態でtsx内に書いた場合はなぜか解消できない構文エラーなんかに、悩まされます。入力の補完機能は効かないし、コード生成も使えない....(以前はここで解消できずに辞めてしまいました。) ちなみにChatGPTにコード丸投げしても解決しなかったので、どうにかしてほしいな〜って感じですね。
それでは例題をもとに自分がこの中でつまづいたポイントと一言感想書きました。
問題①
問題1: 汎用的な配列を逆順にする関数
// サンプル配列:
const sampleArray1: number[] = [1, 2, 3, 4, 5];
const sampleArray2: string[] = ["a", "b", "c", "d", "e"];
const sortInversion = <T,>(arr: T[]): T[] => {
return arr.reverse();
};
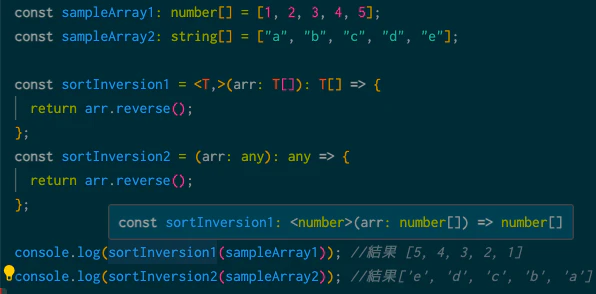
console.log(sortInversion(sampleArray1)); //結果 [5, 4, 3, 2, 1]
console.log(sortInversion(sampleArray2)); //結果['e', 'd', 'c', 'b', 'a']
今回は、配列の処理を汎用的に実施したいと言うことでサンプル配列をnumber型と文字列型として2パターン用意しました。
このジェネリクスを使用することで、汎用性が高い関数を生成できます。むむむ。
reverse()メソッドでは配列の中身のindexを逆転させた配列を表示。
reverseメソッドは、スプレッド構文でコピーしたりして使うのが吉のようなので改めて学習しよう(元の配列の値を書き換えてしまうため)
ちなみにジェネリクス使わないとどう書くのかって話。
(ジェネリクス知る前の僕はこう書いてました....)
でも逆になんですけど、ジェネリクスもしまだ難しいなぁとか書けないなぁって言う理解度の場合でも、開発の現場では逃げ切れます。(もちろん適切に使えるところは使った方がいいですがこういう考えも時には大事かなって言うのが僕の意見です)
// 例えばstringもnumberも使いたい場合(若干長いし見づらい)
const sortInversion = (arr: number[] | string[]):number[] | string[] => {
// なんでも受け入れる、なんだかんだ大好きany君(毎回これで逃げてたら一生TS使いこなせる気がしない)
const sortInversion = (arr:any):any => {
//またはそもそも関数を分けてしまう。とかですかねぇ....
最近こういう場面が増えてきて、現場のルールはあっても「正解はない」と思い知らされてます。こう言う知見はつけていきたいですね。
でもやっぱりこう記事書いてて理解が深まってくるにつれて、疑問も付き纏ってきたので解決したいと思います。
anyを使うのと、ジェネリクス使うのって何が違うの?って言う話。
いや、そうなんですよ。両者の使い分けって何?と。
直感的に理解していることといえば、「any警察」なんて言われるレベルのアンチanyの方がいるんですね。多用したらレビューでバンバン指摘されたかたがいました。。笑 とりあえずanyは嫌われます。
とりあえず比較してみました。
any の特徴
①TSでの型チェック機能が無効になる。 間違った型のデータを関数に渡しても、コンパイル時にエラーが起こらない。
→静的型付けであるTSにおけるメリットが潰れてしまう。 実行時に予期せぬエラーが起こる可能性が高くなる(関数実行のボタンクリックした時など)
②関数がどのような型のデータを受け入れるか不明確になることで、可読性が低下する。
問題①をany型としてみて、実行文をconsole.log()で出力してるところのマウスを当ててみます。
確かに型推論見ても結果がわからないですね。複雑な関数の場合にanyを多用されてしまうと、読む側は嫌な気分になりそうです。
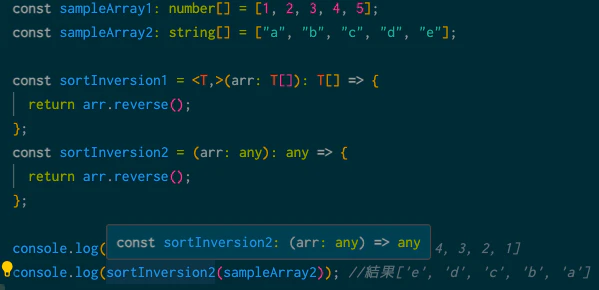
③暗黙的にあらゆる型に変換されるため、意図しない挙動を引き起こす可能性がある。
結論: anyはなるべく極力避けるべし!!
じゃあジェネリクスのメリットは??
①基本的に上記のanyと真逆の「親切さ」を持ってると思えばいいんじゃないかと。
型の安全性は保持される、再利用性高まる、可読性向上。
(arr: number[]) => number[] と表示されるのは、TypeScriptの型推論が働いて、sampleArray1 が number[] 型であることを認識し、それに応じて関数の型パラメータ T を number と推論しているからです。
補足的な説明が長くなったため問題開始。
問題②
問題2:二つの配列からオブジェクトを生成する関数
// サンプル配列:
const keyArray = ["a", "b", "c"];
const valueArray = [1, 2, 3];
const generateObject = <T,>(
keys: string[],
values: T[]
): { [key: string]: T } => {
if (keys.length === values.length) {
const obj: { [key: string]: T } = {};
for (let i = 0; i < keys.length; i++) {
obj[keys[i]] = values[i];
}
return obj;
} else {
throw new Error("key: valueの配列数は同等でなくてはならない。");
}
};
console.log(generateObject(keyArray, valueArray)); //結果{a: 1, b: 2, c: 3}
デフォルトが空になっているオブジェクトですが、for文使って
obj[keys[i]] = values[i];
この記述をするとオブジェクトの中身が追加されるんですね...(知らなかった)
配列に追加の場合は.append使いますが、、オブジェクトに追加ってあんまりやってこなかったので....
基本から見直しが必要と思う時って、やっぱりこういうときだよね....
throw〜〜に関しては、例外処理を含んで後日別記事に書きたいと考えてます。(最近やっと理解しましたため)
問題③
問題3:汎用的な配列のフィルタリング関数
// サンプル配列:
const numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10];
const filteringArray = <T,>(
targetArray: T[],
predicate: (value: T) => boolean // 引数として条件式を記入可能に
): T[] => {
return targetArray.filter(predicate);
};
// 偶数だけを取り出すフィルター関数とした
console.log(filteringArray(numbers, (item) => item % 2 === 0)); // 結果: [2, 4, 6, 8, 10]
引数として、filter関数の条件式を渡しています。
問題④ 特定の型の要素を持つ配列に対する操作関数
問題4: 特定の型の要素を持つ配列に対する操作関数
type BASIC_TYPE =
| "boolean"
| "number"
| "string"
| "void"
| "undefined"
| "null"
| "object"
| "symbol"
| "bigint";
// サンプル配列:
const mixedArray = [1, "a", 2, "b", 3, "c"];
// 数値のみを抽出する関数を書いてください。
const extractNumbers = <T,>(array: T[], targetType: BASIC_TYPE): T[] => {
const v = array.filter((item) => typeof item === targetType);
return v;
};
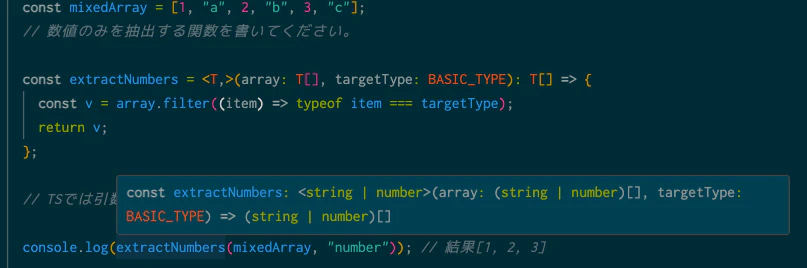
console.log(extractNumbers(mixedArray, "number")); // 結果[1, 2, 3]
今回の配列には、stringとnumberが入ってますね。
くどいようですが、第一引数のarray: T[]に対してstringとnumberの配列が使用されてるため、
ジェネリクスの判定として、型推論ではこのように表示がされます。
確かに使いこなせると相当便利そうな気がする。応用的に使えるようにするためにまず浅いところから手を伸ばしてみたいと思います。
感想
「人に教えるつもりでインプットは行え!!」という教えを基に書きました。
引き続き書くぞおおおおお