はじめに
株式会社NTTデータ デジタルサクセスソリューション事業部 で AWS や Databricks を推進している nttd-saitouyun です。
MLflow LLM Evaluate で モデルサービングされた LLM を評価する記事を書きました。
今回は同じシナリオで、LLM-as-a-Judge による評価をしてみます。
マニュアルには OpenAI の GPT を使った評価が多いのですが、今回は、AWS で Databricks を使っている方に役立つように モデルサービングエンドポイントで接続している Amazon Bedrock / Claude 3.5 Sonnet を使って評価を行います。
MLflow LLM Evaluate
LLM の評価は正解を定義することが難しいなど従来と違った難しさがありますが、MLflow LLM Evaluate は、LLM の評価を効率的に行うフレームワークです。
マニュアルの説明は以下のとおりです。
LLMのパフォーマンスの評価は、比較する単一のグラウンドトゥルースが存在しないことが多いため、従来の機械学習モデルとは少し異なります。 MLflow には、LLM の評価に役立つ API mlflow.evaluate() が用意されています。
事前準備
事前準備はこちらの記事に記載した内容と全く同じです。リンク先の記事をご覧ください。
あえて解説するのであれば、LLM-as-a-Judge にモデルサービングされたモデルを利用する場合は以下の記載が必要となります。
from mlflow.deployments import set_deployments_target
set_deployments_target("databricks")
今回は評価対象のモデルもモデルサービングされたものであるため、すでに事前準備に含まれています。
LLM-as-a-Judge を使った MLflow LLM Evaluate の実行
以前作成したrun_evaluation関数を少し変更するだけで LLM-as-a-Judge による評価ができます。
from mlflow.metrics.genai import (
answer_correctness,
answer_relevance,
answer_similarity
)
def run_evaluation(endpoint, judge_model_endpoint):
with mlflow.start_run(run_name = endpoint) as run:
# LLM(サービングエンドポイント)の情報を記録
mlflow.log_param("endpoint", endpoint)
mlflow.log_param("endpoint details", get_serving_endpoint_info(endpoint))
# LLMの評価を実行
results = mlflow.evaluate(
model = f"endpoints:/{endpoint}",
data = eval_data,
inference_params = {"max_tokens": 128, "temperature": 0.0},
targets = "ground_truth",
model_type = "question-answering",
extra_metrics = [
answer_correctness(model = f"endpoints:/{judge_model_endpoint}"),
answer_relevance(model = f"endpoints:/{judge_model_endpoint}"),
answer_similarity(model = f"endpoints:/{judge_model_endpoint}"),
],
)
上記のように評価用の関数を定義し、以下のように呼び出します。
run_evaluation("azure-openai-gpt-4o", "aws-oregon-claude-3-5-sonnet")
run_evaluation("aws-oregon-claude-3-5-sonnet", "aws-oregon-claude-3-5-sonnet")
run_evaluation("google-oregon-gemini-1-5-pro", "aws-oregon-claude-3-5-sonnet")
run_evaluation("databricks-meta-llama-3-1-405b-instruct", "aws-oregon-claude-3-5-sonnet")
run_evaluation("databricks-dbrx-instruct", "aws-oregon-claude-3-5-sonnet")
それでは変更点を解説していきます。
評価メトリクスのモジュールのインポート
from mlflow.metrics.genai import (
answer_correctness,
answer_relevance,
answer_similarity
)
MLflowは、LLM-as-a-Judge として使用できる事前定義されたメトリクスを提供しています。
| メトリクス | 説明 | 高スコアの意味 | 低スコアの意味 |
|---|---|---|---|
answer_similarity() |
モデル出力とground_truthの類似性を評価 | 出力がground_truthと類似の情報を含む | 出力がground_truthと一致しない可能性 |
answer_correctness() |
モデル出力の事実的正確さを評価 | 出力がground_truthと類似かつ正確な情報を含む | 出力がground_truthと不一致または不正確 |
answer_relevance() |
モデル出力の入力に対する関連性を評価(コンテキスト無視) | 出力が入力と同じ主題について | 出力が話題と無関係の可能性 |
relevance() |
モデル出力の入力とコンテキストに対する関連性を評価 | モデルがコンテキストを理解し、関連情報を抽出 | 出力が質問とコンテキストを無視し、幻覚の可能性 |
faithfulness() |
モデル出力のコンテキストに対する忠実さを評価(入力無視) | 出力がコンテキストと一致する情報を含む | 出力がコンテキストと矛盾する可能性 |
-
LLM-as-a-Judge で利用できるメトリクスの詳細は以下のページをご覧ください。
→ Metrics with LLM as the Judge -
以下のモジュールを使えば、プロンプトを与えて評価することもできるようです。
→ mlflow.metrics.genai.make_genai_metric_from_prompt -
さらに、カスタムメトリクスの作成もできるようです。
→Creating Custom LLM-evaluation Metrics
評価用の LLM とメトリクスの指定
def run_evaluation(endpoint, judge_model_endpoint):
with mlflow.start_run(run_name = endpoint) as run:
・・・
# LLMの評価を実行
results = mlflow.evaluate(
・・・・
・・・・
extra_metrics = [
answer_correctness(model = f"endpoints:/{judge_model_endpoint}"),
answer_relevance(model = f"endpoints:/{judge_model_endpoint}"),
answer_similarity(model = f"endpoints:/{judge_model_endpoint}"),
],
)
extra_metricsとして先ほどインポートしたモジュールを指定します。そして、各モジュールのmodel引数に評価用の LLM のエンドポイントを指定します。
MLflow LLM Evaluate の実行
定義した評価関数を引数を変えて実行します。
run_evaluation("azure-openai-gpt-4o", "aws-oregon-claude-3-5-sonnet")
run_evaluation("aws-oregon-claude-3-5-sonnet", "aws-oregon-claude-3-5-sonnet")
run_evaluation("google-oregon-gemini-1-5-pro", "aws-oregon-claude-3-5-sonnet")
run_evaluation("databricks-meta-llama-3-1-405b-instruct", "aws-oregon-claude-3-5-sonnet")
run_evaluation("databricks-dbrx-instruct", "aws-oregon-claude-3-5-sonnet")
以下のコードは モデルサービングエンドポイントazure-openai-gpt-4o のQAの結果をモデルサービングエンドポイント aws-oregon-claude-3-5-sonnet が評価します。
run_evaluation("azure-openai-gpt-4o", "aws-oregon-claude-3-5-sonnet")
以上です。簡単な修正で済みました。
MLflow LLM Evaluate の評価結果の確認
Databricks のエクスペリメント(実験管理) に質問と回答、実験条件、回答の評価指標値が記録されています。
※図の凡例は以下の通りです。

answer_correctness
以下のような結果になりました。ほぼ同列です。
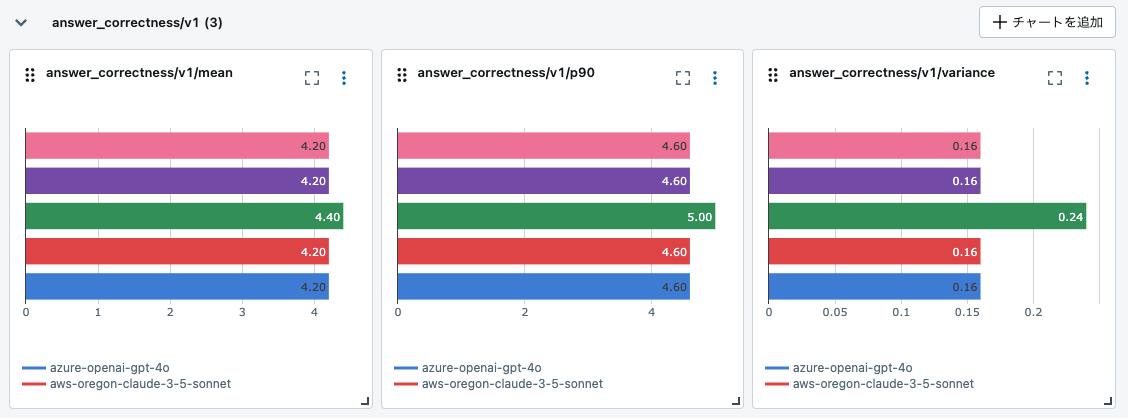
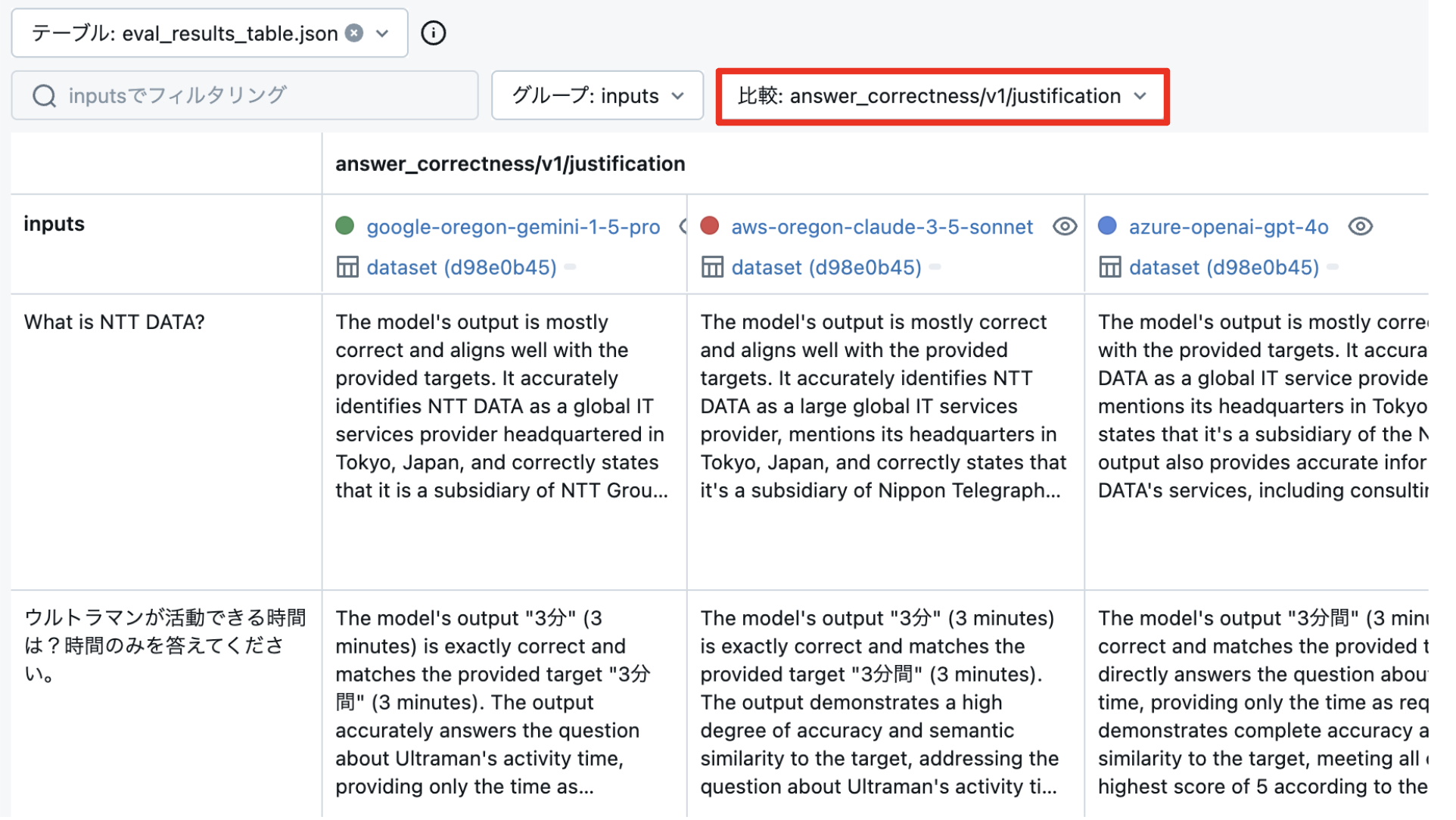
評価タブから回答やスコア以外に 「justification」という評価の理由を確認することができます。
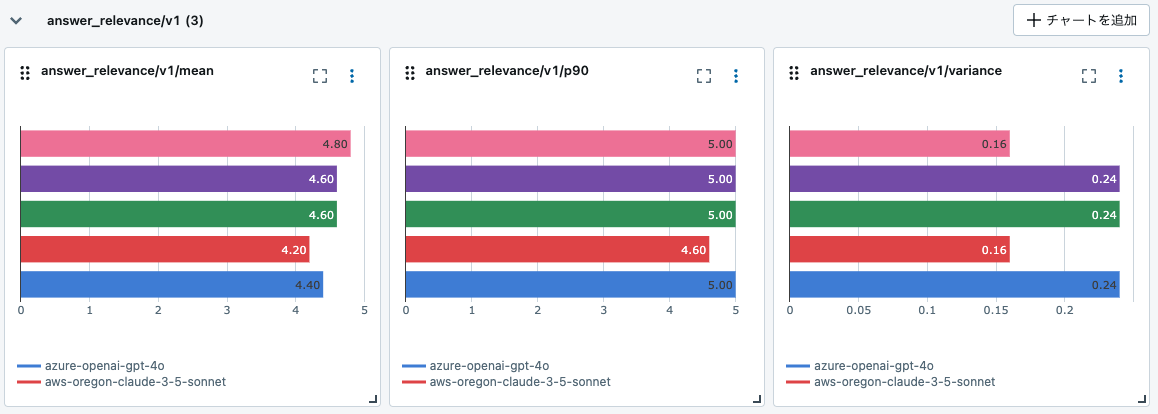
answer_relevance
以下のような結果になりました。DBRX が Claude 3.5 Sonnet より高い評価になっていました! Databricksに関する質問が多いからか・・・?と思いながら原因を突き止めてみます。
「justification」を見てみると、Claude 3.5 Sonnet が 4/5点しか取れていない理由は、いずれも回答が途中で切れているのが理由でした。
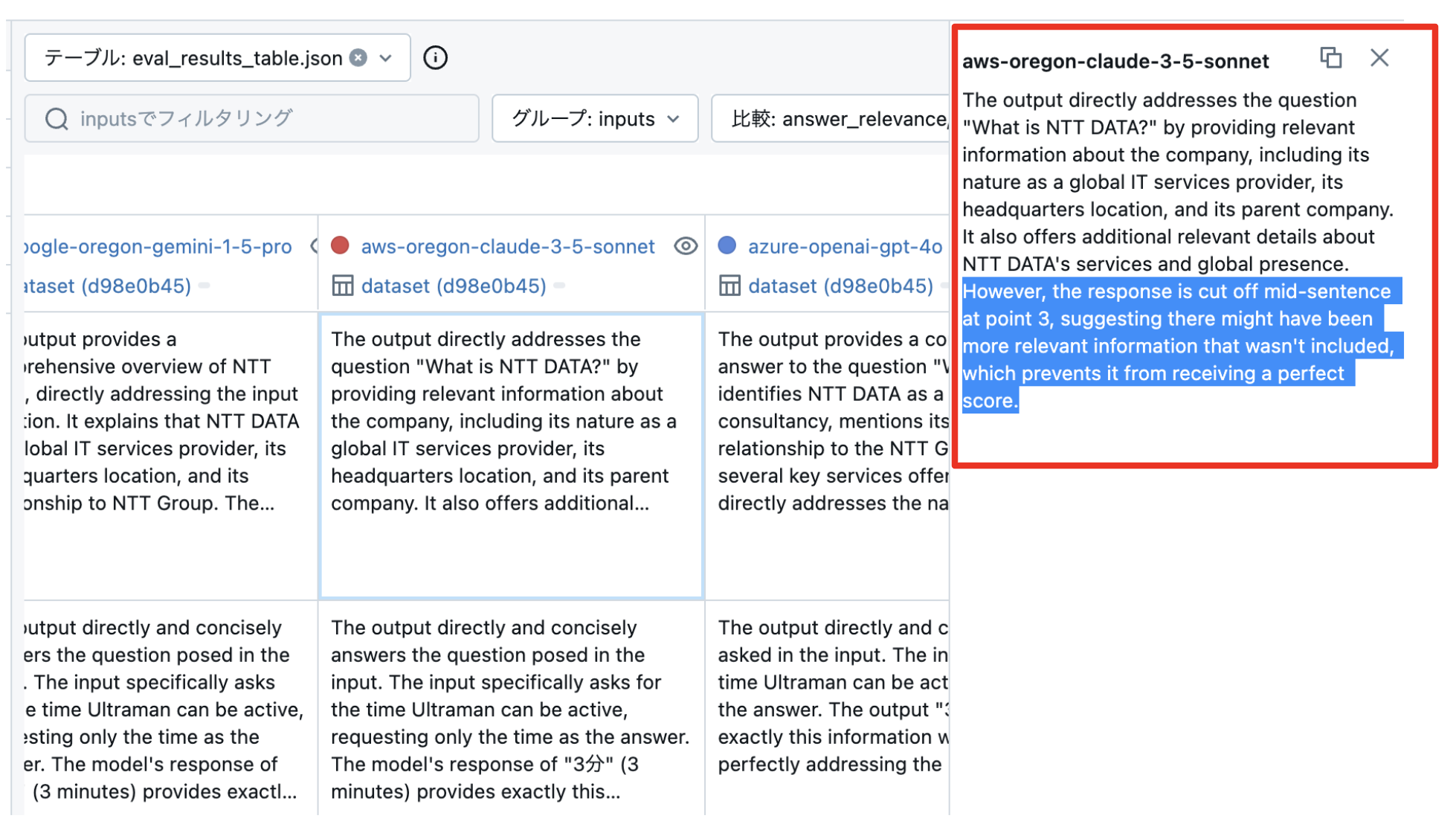
Outputs(回答)をみると、確かに回答は3.の書き途中で途切れてました。
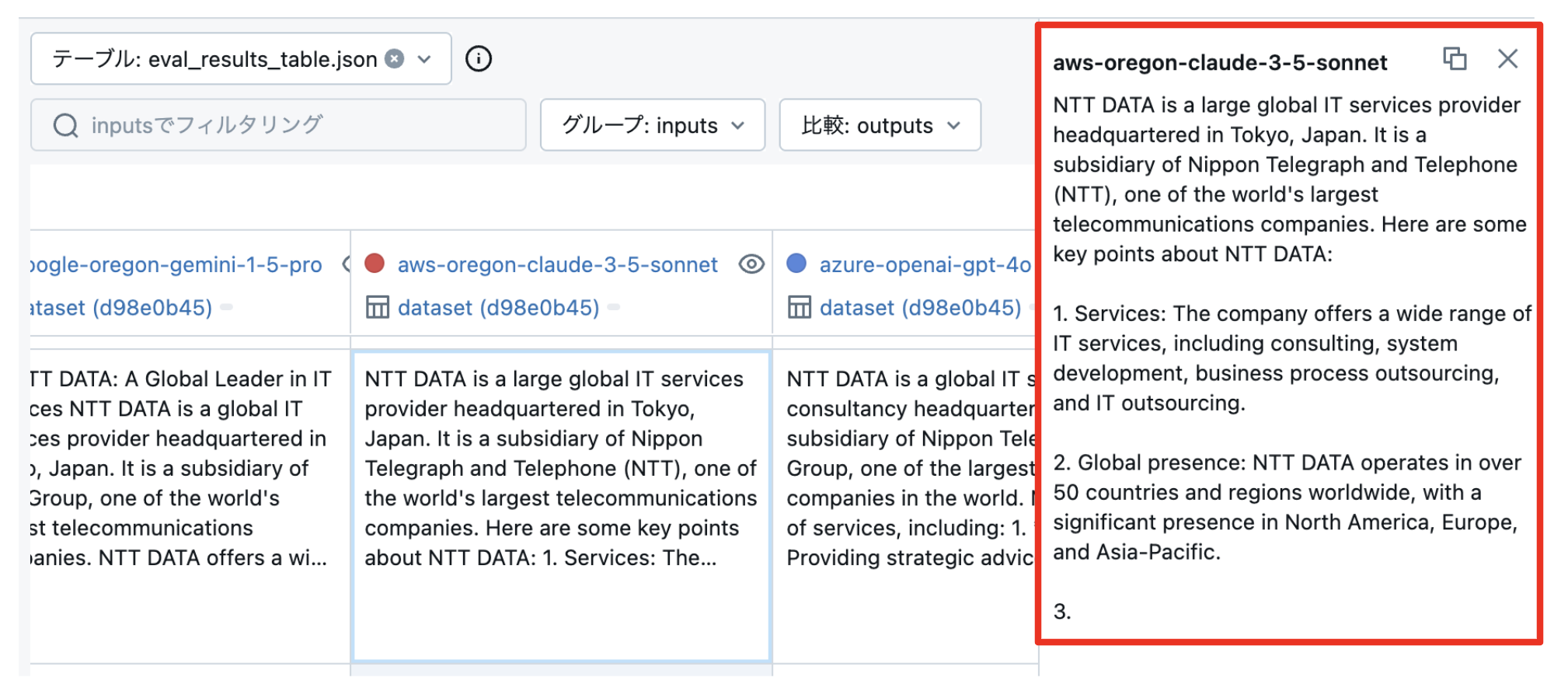
max_tokens = 128 は、Claude 3.5 Sonnet には少なすぎるよようです。または、「何文字以内でまとめて回答して」などとプロンプトで工夫が必要であることがわかります。
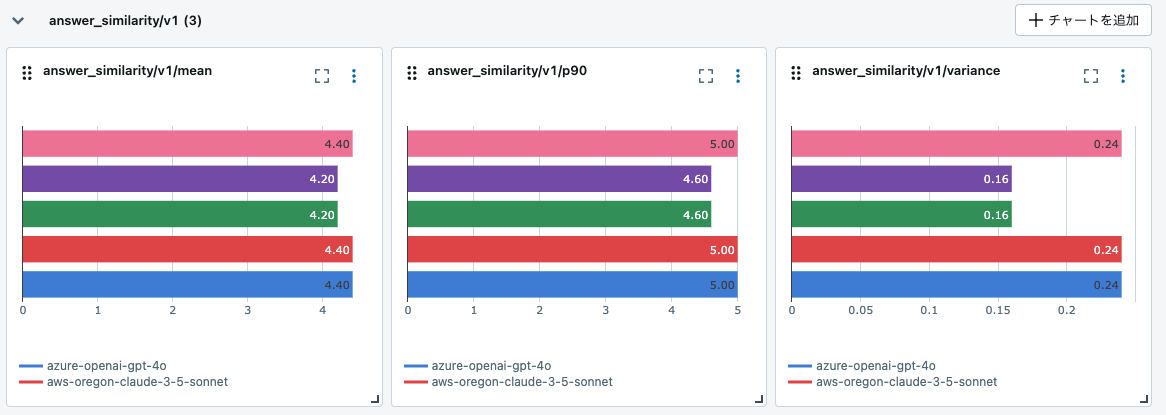
answer_similarity
こちらの回答も記載しておきます。ほぼ同等です。
モデルの選択
今回の試行ではモデルの回答の品質レベルは、やや Gemini が高いものの、ほぼ同じであることがわかりました。(Claude や GPT はプロンプトやトークン数の制限のため真価を発揮できていないだけですが)
回答の品質レベルが十分なのであれば、それ以外の指標、例えば回答速度やコストを考慮すると DBRX が適しているといった結論もあり得そうです。
※レイテンシーのメトリクスを追加して図にしてみました。軽量である分、DBRXがダントツで回答が早いです。
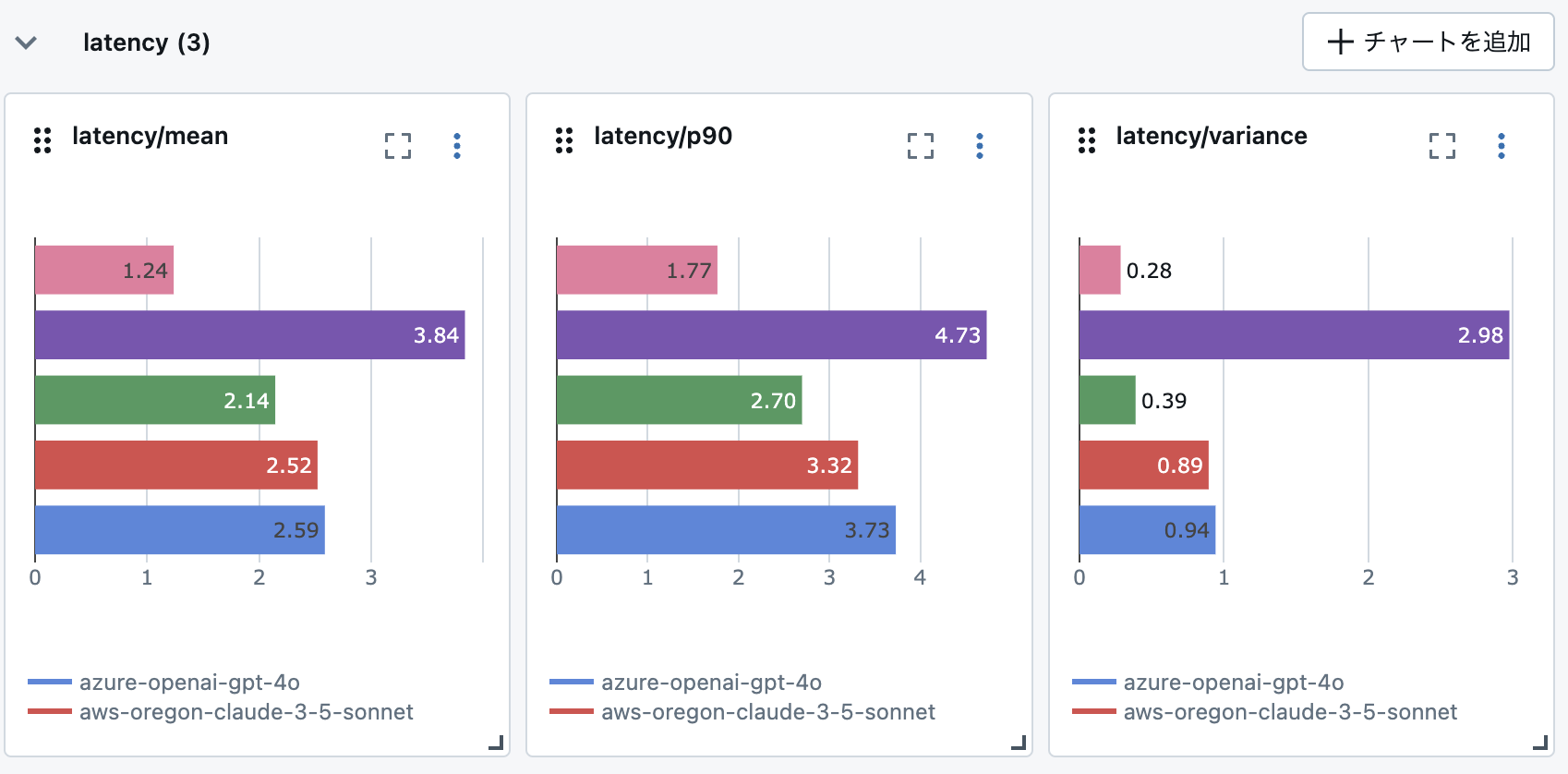
このように MLflow LLM Evaluate を使って LLM を評価を定量化し、さまざまな角度(メトリクス)から比較することで、パラメータ数の大きい LLM 一辺倒ではなく、やりたいことに適した LLM を合理的に選択できるのではないでしょうか!
おわりに
MLflow LLM Evaluate で LLM-as-a-Judge が簡単かつ分かりやすく実現でき、LLM の評価を効率的にできることがお分かりいただけましたでしょうか。
また、モデルサービングエンドポイントを活用することで LLM がどこにあるのかを気にせず(マルチクラウドでも)、QAや評価に利用できます。
引き続き、Databrikcs や 生成AIに関する情報発信していきたいと思います!
仲間募集
NTTデータ デザイン&テクノロジーコンサルティング事業本部 では、以下の職種を募集しています。
1. クラウド技術を活用したデータ分析プラットフォームの開発・構築(ITアーキテクト/クラウドエンジニア)
クラウド/プラットフォーム技術の知見に基づき、DWH、BI、ETL領域におけるソリューション開発を推進します。https://enterprise-aiiot.nttdata.com/recruitment/career_sp/cloud_engineer
2. データサイエンス領域(データサイエンティスト/データアナリスト)
データ活用/情報処理/AI/BI/統計学などの情報科学を活用し、よりデータサイエンスの観点から、データ分析プロジェクトのリーダーとしてお客様のDX/デジタルサクセスを推進します。https://enterprise-aiiot.nttdata.com/recruitment/career_sp/datascientist
3.お客様のAI活用の成功を推進するAIサクセスマネージャー
DataRobotをはじめとしたAIソリューションやサービスを使って、 お客様のAIプロジェクトを成功させ、ビジネス価値を創出するための活動を実施し、 お客様内でのAI活用を拡大、NTTデータが提供するAIソリューションの利用継続を推進していただく人材を募集しています。4.DX/デジタルサクセスを推進するデータサイエンティスト《管理職/管理職候補》
データ分析プロジェクトのリーダとして、正確な課題の把握、適切な評価指標の設定、分析計画策定や適切な分析手法や技術の評価・選定といったデータ活用の具現化、高度化を行い分析結果の見える化・お客様の納得感醸成を行うことで、ビジネス成果・価値を出すアクションへとつなげることができるデータサイエンティスト人材を募集しています。ソリューション紹介
Trusted Data Foundationについて
~データ資産を分析活用するための環境をオールインワンで提供するソリューション~https://enterprise-aiiot.nttdata.com/tdf/
最新のクラウド技術を採用して弊社が独自に設計したリファレンスアーキテクチャ(Datalake+DWH+AI/BI)を顧客要件に合わせてカスタマイズして提供します。
可視化、機械学習、DeepLearningなどデータ資産を分析活用するための環境がオールインワンで用意されており、これまでとは別次元の量と質のデータを用いてアジリティ高くDX推進を実現できます。
NTTデータとDatabricksについて
NTTデータは、お客様企業のデジタル変革・DXの成功に向けて、「databricks」のソリューションの提供に加え、情報活用戦略の立案から、AI技術の活用も含めたアナリティクス、分析基盤構築・運用、分析業務のアウトソースまで、ワンストップの支援を提供いたします。TDF-AM(Trusted Data Foundation - Analytics Managed Service)について
~データ活用基盤の段階的な拡張支援(Quick Start) と保守運用のマネジメント(Analytics Managed)をご提供することでお客様のDXを成功に導く、データ活用プラットフォームサービス~https://enterprise-aiiot.nttdata.com/service/tdf/tdf_am
TDF-AMは、データ活用をQuickに始めることができ、データ活用の成熟度に応じて段階的に環境を拡張します。プラットフォームの保守運用はNTTデータが一括で実施し、お客様は成果創出に専念することが可能です。また、日々最新のテクノロジーをキャッチアップし、常に活用しやすい環境を提供します。なお、ご要望に応じて上流のコンサルティングフェーズからAI/BIなどのデータ活用支援に至るまで、End to Endで課題解決に向けて伴走することも可能です。
NTTデータとSnowflakeについて
NTTデータでは、Snowflake Inc.とソリューションパートナー契約を締結し、クラウド・データプラットフォーム「Snowflake」の導入・構築、および活用支援を開始しています。 NTTデータではこれまでも、独自ノウハウに基づき、ビッグデータ・AIなど領域に係る市場競争力のあるさまざまなソリューションパートナーとともにエコシステムを形成し、お客さまのビジネス変革を導いてきました。 Snowflakeは、これら先端テクノロジーとのエコシステムの形成に強みがあり、NTTデータはこれらを組み合わせることでお客さまに最適なインテグレーションをご提供いたします。NTTデータとInformaticaについて
データ連携や処理方式を専門領域として10年以上取り組んできたプロ集団であるNTTデータは、データマネジメント領域でグローバルでの高い評価を得ているInformatica社とパートナーシップを結び、サービス強化を推進しています。NTTデータとTableauについて
ビジュアル分析プラットフォームのTableauと2014年にパートナー契約を締結し、自社の経営ダッシュボード基盤への採用や独自のコンピテンシーセンターの設置などの取り組みを進めてきました。さらに2019年度にはSalesforceとワンストップでのサービスを提供開始するなど、積極的にビジネスを展開しています。これまでPartner of the Year, Japanを4年連続で受賞しており、2021年にはアジア太平洋地域で最もビジネスに貢献したパートナーとして表彰されました。
また、2020年度からは、Tableauを活用したデータ活用促進のコンサルティングや導入サービスの他、AI活用やデータマネジメント整備など、お客さまの企業全体のデータ活用民主化を成功させるためのノウハウ・方法論を体系化した「デジタルサクセス」プログラムを提供開始しています。
NTTデータとAlteryxについて
Alteryxは、業務ユーザーからIT部門まで誰でも使えるセルフサービス分析プラットフォームです。 Alteryx導入の豊富な実績を持つNTTデータは、最高位にあたるAlteryx Premiumパートナーとしてお客さまをご支援します。導入時のプロフェッショナル支援など独自メニューを整備し、特定の業種によらない多くのお客さまに、Alteryxを活用したサービスの強化・拡充を提供します。