はじめに
はじめまして。 NTTデータ ソリューション事業本部 デジタルサクセスソリューション事業部 の nttd-nagano です。
Informatica(インフォマティカ) のクラウドデータマネージメントプラットフォームとして、「Intelligent Data Management Cloud」(※1。以下IDMCと記載)というものがあります。
今回は、そのIDMCのデータ統合サービス「Cloud Data Integration」(※2。以下CDIと記載)の機能「プッシュダウン最適化」機能(Pushdown Optimization)にて、 Amazon Redshift にELT(※4)してみた ので、ご報告します。
※1. Intelligent Data Management Cloud
略称はIDMC。旧称はIICS。クラウドデータマネジメントプラットフォーム。以下IDMCと記載。※2. Cloud Data Integration
略称はCDI。データ統合サービス。ETL処理(※3)やELT処理(※4)を担う。以下CDIと記載。※3. ETL処理
データベースなどに蓄積されたデータから必要なものを抽出(Extract)し、目的に応じて変換(Transform)し、データを必要とするシステムに格納(Load)すること。※4. ELT処理
ETL処理(※3)と対比して使われることが多い言葉。データ統合処理の順序を従来型のE→T→Lの順ではなく、E→L→Tの順でおこなう。近年ではDBMSの性能が爆発的に向上したことから、その性能を有効活用するために使われる手法。
データ統合処理は、データの変換を伴うことが多いですが、 この 「プッシュダウン最適化」機能では、ELT処理によりDBMSの処理能力を最大限に活用し、高いパフォーマンスを実現します。
具体的には、 データ変換処理を各DBMS固有の命令を含む最適なSQLクエリに変換して、DBMS側で実行します。
今回は、 Amazon Redshift を対象に、この「プッシュダウン最適化」機能の使い方をご紹介します。
S3バケットを作って入力側となるファイルを格納する
CDIは様々なシチュエーションでデータ統合処理をRedshiftにプッシュダウンすることができますが、今回、Redshiftにロードするデータは、S3にCSVファイルとして格納しておくことにしました。
まず、AWSマネジメントコンソールの「S3」にて、S3バケットを作りました。
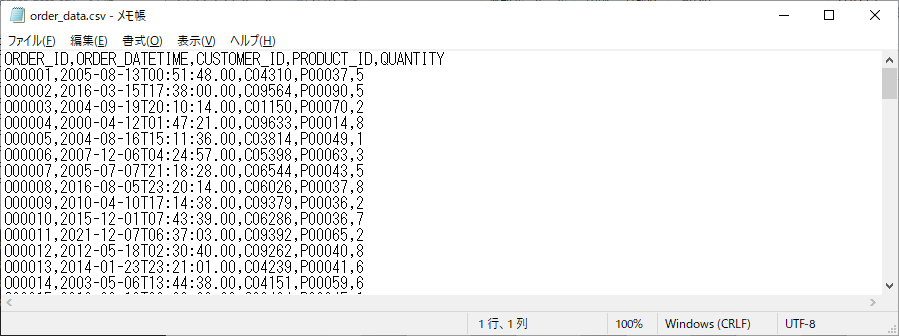
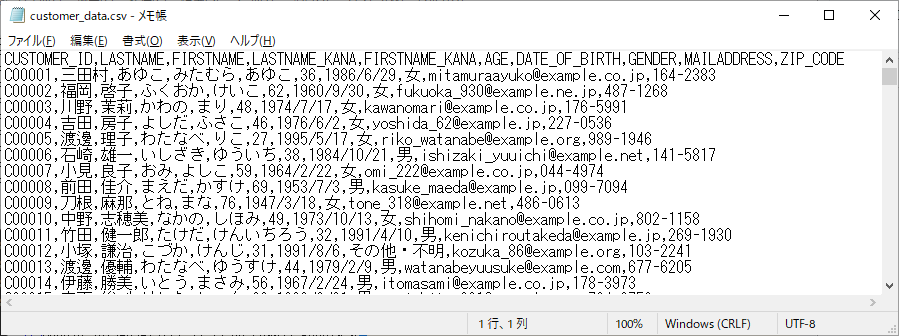
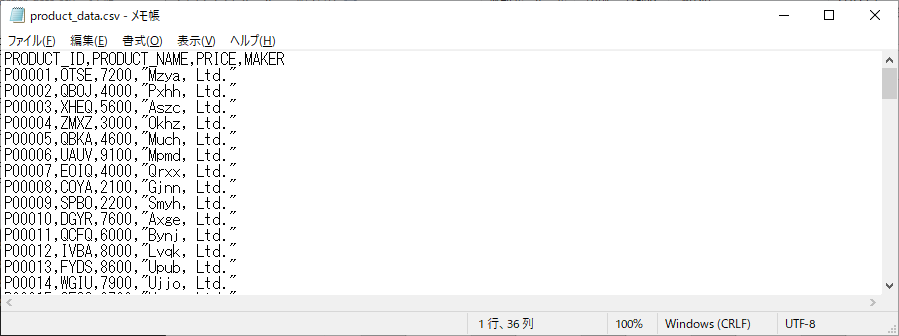
次に、入力ファイルとして、次のような3種類のダミーデータを用意し、格納しました。
- order_data.csv (注文情報)
- customer_data.csv (顧客マスタ)
- product_data.csv (商品マスタ)
Redshiftに出力側となるテーブルを作る
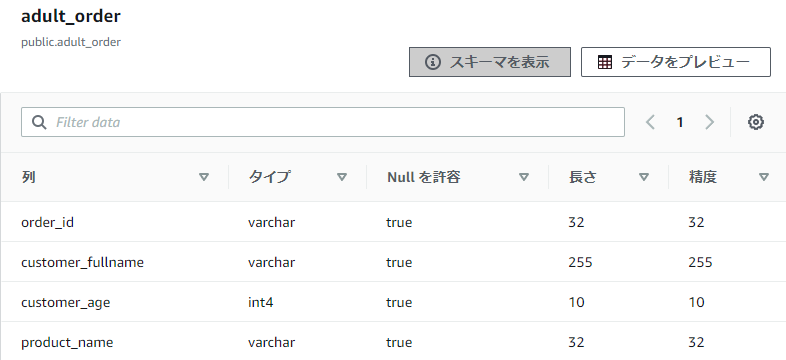
今回、Redshift側にロードする際には、前述の入力を変換しながら結合していくこととします。(詳細は後述)
AWSマネジメントコンソールの「Redshift」の「クエリエディタ」にて、次のようなテーブルを作りました。
Redshift用のIAMロールを作る
Redshiftに変換処理をさせるということは、RedshiftがS3バケット内のファイルを読むことになります。
AWSマネジメントコンソールの「IAM」にて、IAMロールを作成し、対象S3バケットに対して適切な権限を持つポリシーを割り当てます。
今回は簡単のために、 AmazonS3FullAccess ポリシーを割り当てたIAMロールを作りました。
RedshiftにIAMロールを関連付ける
作ったIAMロールをRedshiftに関連付けます。
- AWSマネジメントコンソールの「Redshift」にて、クラスターのプロパティを開きます。
- 「関連付けられたIAMロール」の部分で、「IAMロールの管理」をクリックし、「IAMロールを関連付ける」をクリックします。
- 先ほど作成したIAMロールを選択し、「IAMロールを関連付ける」をクリックします。
上記のようにあらかじめ作成しておいたIAMロールを関連付けるか、あるいは、「IAMロールの管理」をクリックした後、「IAMロールを作成」をクリックすれば、この場で特定のS3バケットに対する権限を持つIAMロールを作成することもできます。
IDMCにログインし、アドオンコネクタとしてS3とRedshiftを有効にする
CDIでは接続先のリソース毎に、「コネクタ」を使用します。標準のコネクタのほかに、 様々なアドオンコネクタがあります。
CDIの30日間の無料体験 を使用している場合などは、アドオンコネクタを使えるようにする作業が必要です。下記の操作を実施してください。すでに使えるようになっている場合はこの作業は不要です。
- IDMCにログインする。
- アプリケーションピッカー(マイサービス)で「管理者」をクリックする。
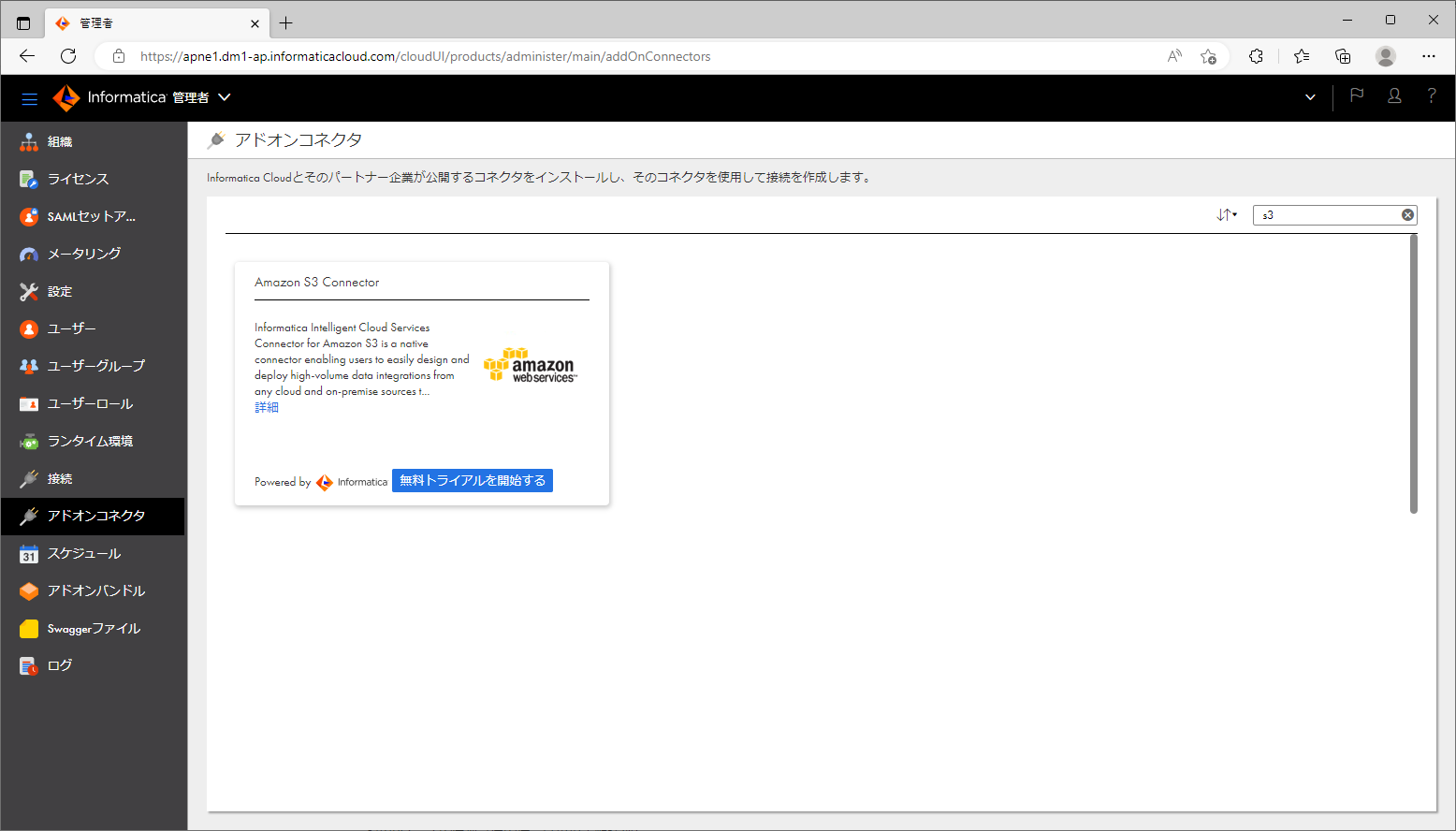
- 左ペインで「アドオンコネクタ」をクリックする。
- 右上の検索欄に「s3」と入力する。
- 「Amazon S3 Connector」の「無料トライアルを開始する」ボタンをクリックする。
- ダイアログで「OK」ボタンをクリックする。
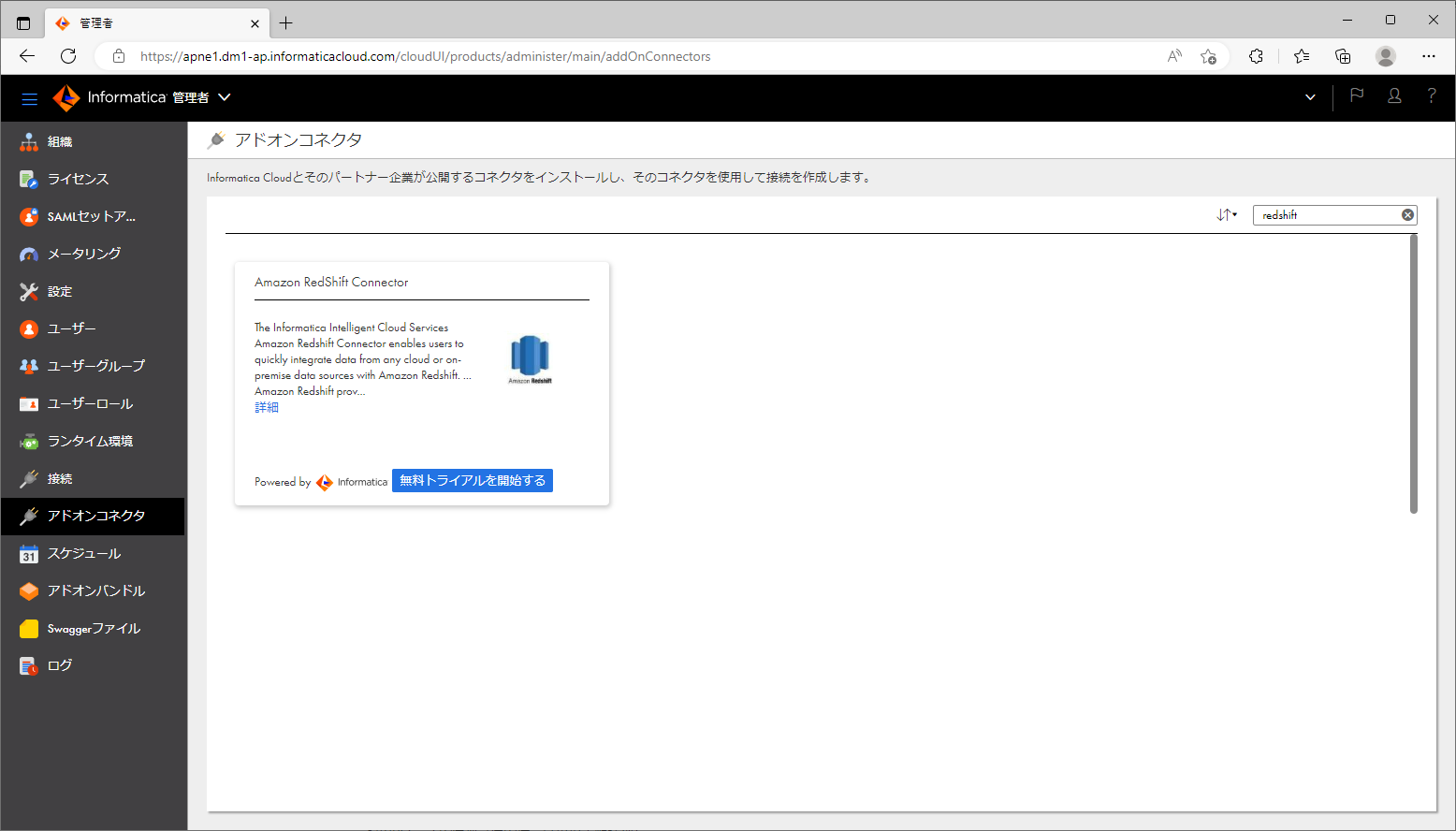
- 右上の検索欄に「redshift」と入力する。
- 「Amazon Redshift Connector」の「無料トライアルを開始する」ボタンをクリックする。
- ダイアログで「OK」ボタンをクリックする。
接続オブジェクトを作る
CDIでは接続先の設定を「接続」(あるいは「接続オブジェクト」)という定義体で管理しています。
今回はS3とRedshiftの接続オブジェクトを作ります。
- 左ペインで「接続」をクリックする。
- 「新しい接続」ボタンをクリックする。
-
S3用の接続オブジェクト を作るために、下記のように入力する。(下記は一例です。S3バケットの設定に合わせます)
設定項目 設定値 接続名 【任意(以降では「conn_amazons3」と記載)】 説明 タイプ Amazon S3 v2 ランタイム環境 【自分のランタイム環境(Secure Agentをインストールしたマシン)】 Access Key Secret Key IAM Role ARN External Id Use EC2 Role to Assume Role Folder Path 【先ほど作成したS3バケット名】 Master Symmetric Key Customer Master Key ID S3 Account Type Amazon S3 Storage Region Name 【S3バケットが存在するリージョン名】 Federated SSO IdP NONE Other Authentication Type NONE S3 VPC Endpoint Type NONE STS VPC Endpoint Type NONE KMS VPC Endpoint Type NONE - 「保存」ボタンをクリックする。
- 「テスト接続」ボタンをクリックする。
- 「この接続のテストに成功しました。」と表示されることを確認する。
- 「新しい接続」ボタンをクリックする。
-
Redshift用の接続オブジェクト を作るために、下記のように入力する。(下記は一例です。Redshiftクラスターの設定に合わせます)
設定項目 設定値 接続名 【任意(以降では「conn_amazonredshift」と記載)】 説明 タイプ Amazon Redshift v2 ランタイム環境 【自分のランタイム環境(Secure Agentをインストールしたマシン)】 Authentication Type Default Username 【ユーザー名】 Password 【パスワード】 Use EC2 Role to Assume Role S3 Access Key ID S3 Secret Access Key S3 IAM Role ARN External Id Master Symmetric Key JDBC URL 【RedshiftのJDBC URL(マネジメントコンソールの「Redshift」にてコピーする)】 Cluster Region 【Redshiftクラスターが存在するリージョン】 Customer Master Key ID - 「保存」ボタンをクリックする。
- 「テスト接続」ボタンをクリックする。
- 「この接続のテストに成功しました。」と表示されることを確認する。
マッピングを作る
CDIでは、データ統合処理を「マッピング」という定義体で管理しています。
まず、空のマッピングを作ります。
- アプリケーションピッカー(マイサービス)で「データ統合」をクリックする。
- 左ペインにて「新規」をクリックする。
- ダイアログで、「マッピング」>「マッピング」をクリックする。
- 「作成」ボタンをクリックする。
さて、マッピングでのデータ統合処理の内容ですが、今回は、「S3バケット内の複数のCSVファイルのデータを抽出し、一部を変換して、結合し、さらに変換した後に、Redshiftのテーブルにロードする」というものにしてみます。
詳細は割愛しますが、おおむね次のような手順で作成しました。
データ変換はあくまで一例なので、その内容よりも、プッシュダウン先であるターゲットオブジェクトの設定に注目していただければと思います。
- ソースオブジェクト が3個になるように配置する。
- 各ソースオブジェクトを選択し、「ソース」パートに以下のように設定する。
設定項目 設定値 接続 【先ほど作成したS3用接続オブジェクト】 ソースタイプ 単一オブジェクト オブジェクト 【各CSVファイル】 形式 Flat - フィルタトランスフォーメーション を配置し、customerと接続する。18歳以上を通過させるように設定する。
- ジョイナトランスフォーメーション を配置し、orderとcustomerを接続する。
- ジョイナトランスフォーメーション を配置し、前項のジョイナトランスフォーメーションとproductを接続する。
- 式トランスフォーメーション を配置し、前項のジョイナトランスフォーメーションを接続する。
- 式トランスフォーメーションにて、「LASTNAME」と「FIRSTNAME」を 文字列結合 するように設定する。
-
ターゲットオブジェクト を選択し、「ターゲット」パートに以下のように設定する。
設定項目 設定値 接続 【先ほど作成したRedshift用接続オブジェクト】 ターゲットの種類 単一オブジェクト オブジェクト 【先ほど作成したテーブル】 操作 Insert S3 Bucket Name 【S3バケット名】 Enable Compression 【デフォルト値のまま】 Staging Directory Location Batch Size 【デフォルト値のまま】 Max Errors Per Batch Upload Insert 【デフォルト値のまま】 Truncate Target Table Before Data Upload 【デフォルト値のまま】 Require Null Value For Char And Varchar WaitTime In Seconds For S3 File Consistency 【デフォルト値のまま】 Copy Options AWS_IAM_ROLE=【先ほど作成したIAMロールのARN(マネジメントコンソールの「IAM」にてコピーする)】 Temporary Credential Duration 【デフォルト値のまま】 S3 Server Side Encryption S3 Client Side Encryption Analyze Target Table Vacuum Target Table 【デフォルト値のまま】 Prefix To Retain For Staging Files On S3 Success File Directory Error File Directory Treat Source Rows As INSERT Override Target Query Transfer Manager Thread Pool Size 【デフォルト値のまま】 Minimum Upload Part Size Schema Name Target Table Name Preserve record order on write Number of files per batch 【デフォルト値のまま】 Recovery Schema Name Pre-SQL Post-Sql 拒否された行の転送 - ターゲットオブジェクトに前述の式トランスフォーメーションを接続する。
- ターゲットオブジェクトの「フィールドマッピング」パートにて、受信フィールドとターゲットフィールドをマッピングする。
上記のように作っていくと、下記のスクリーンショットのようなマッピングになります。
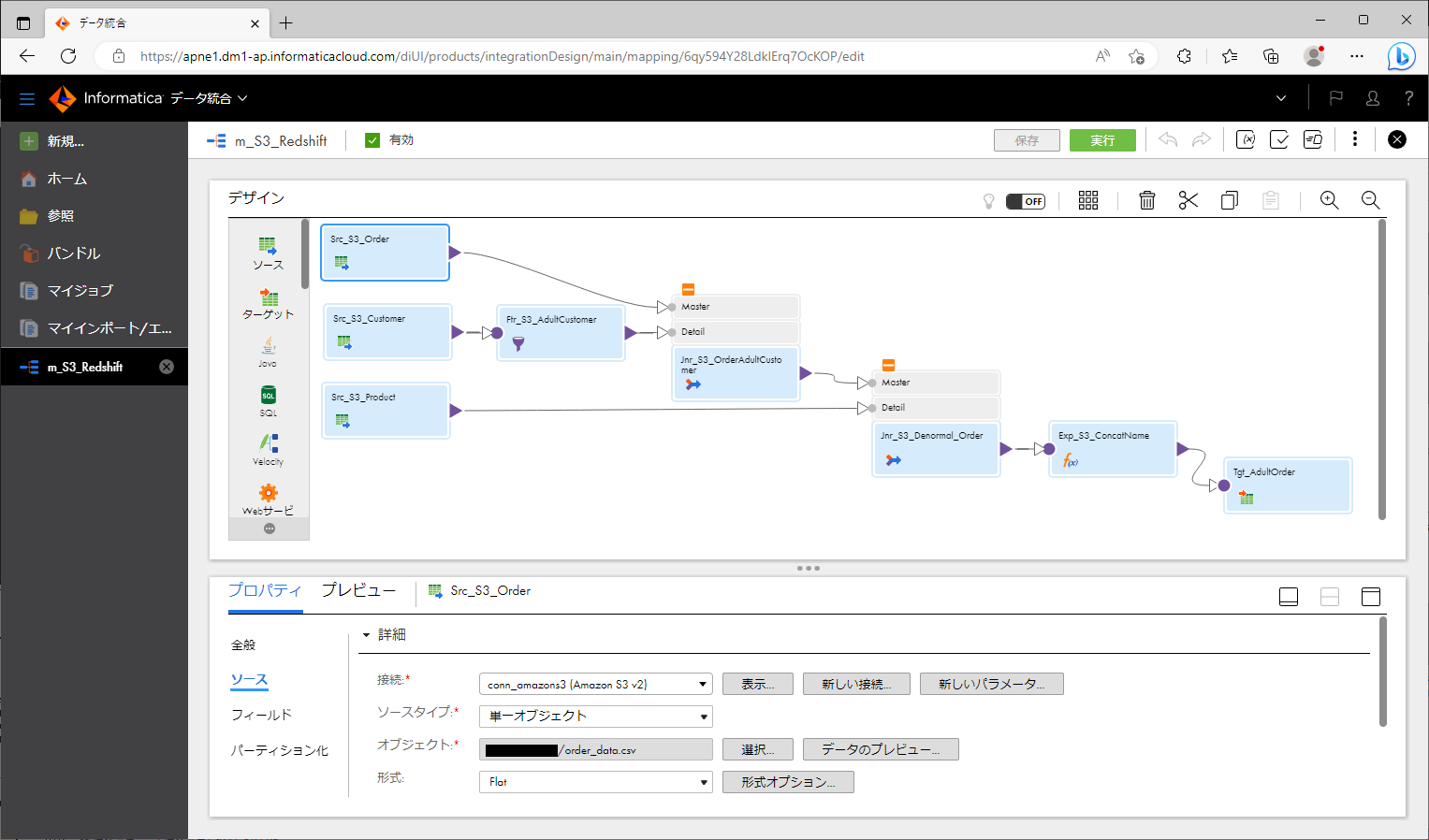
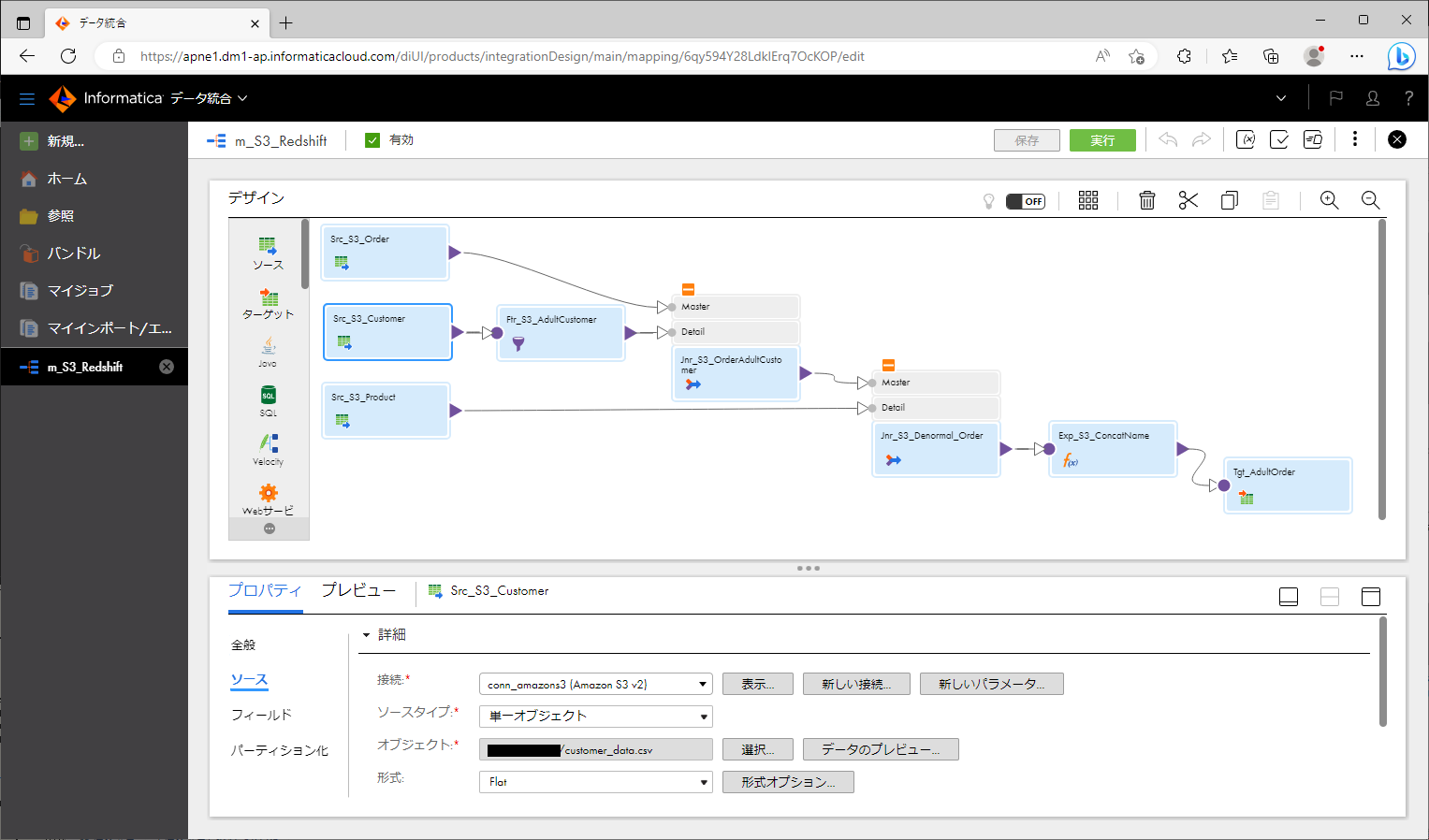
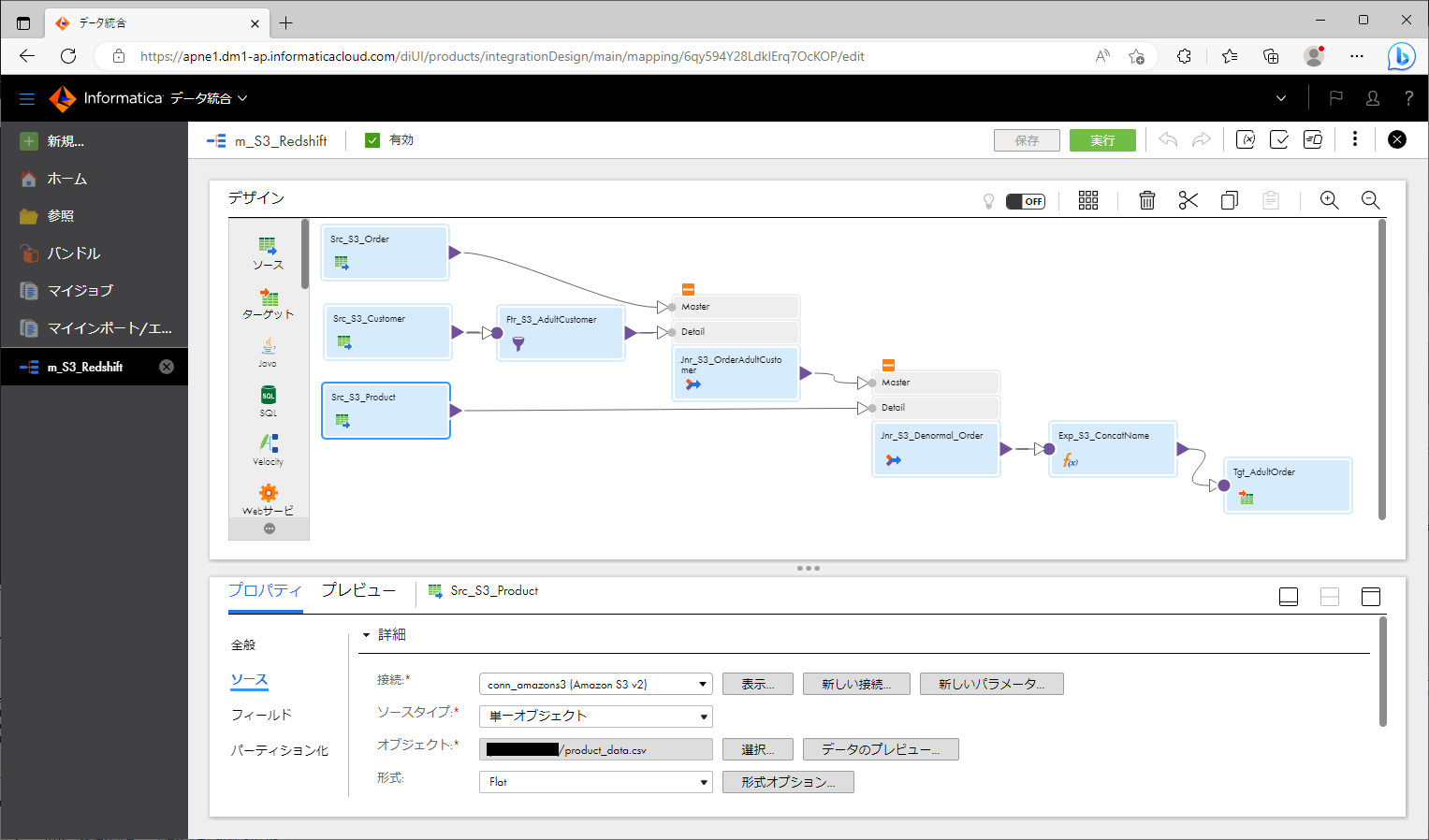
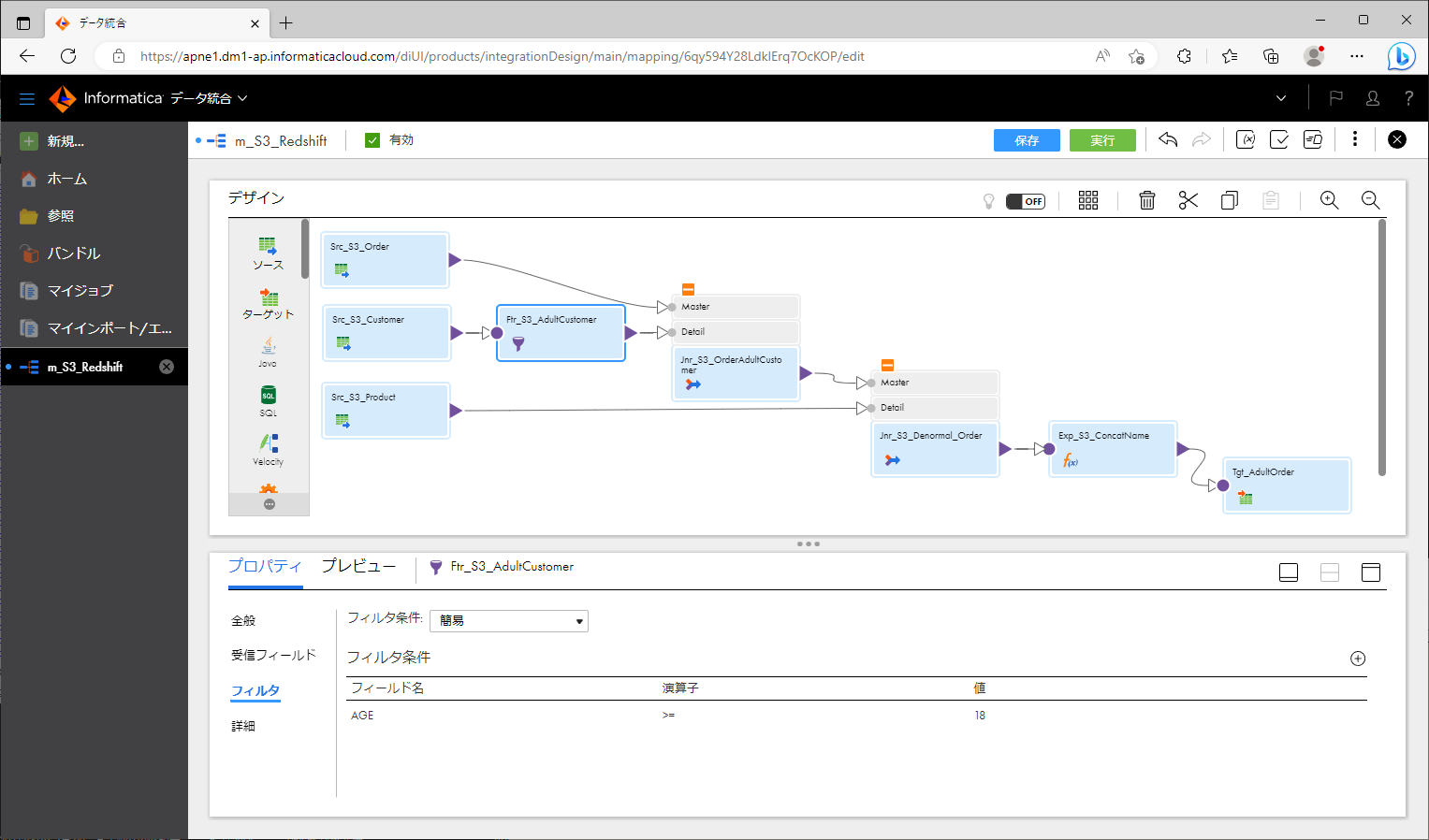
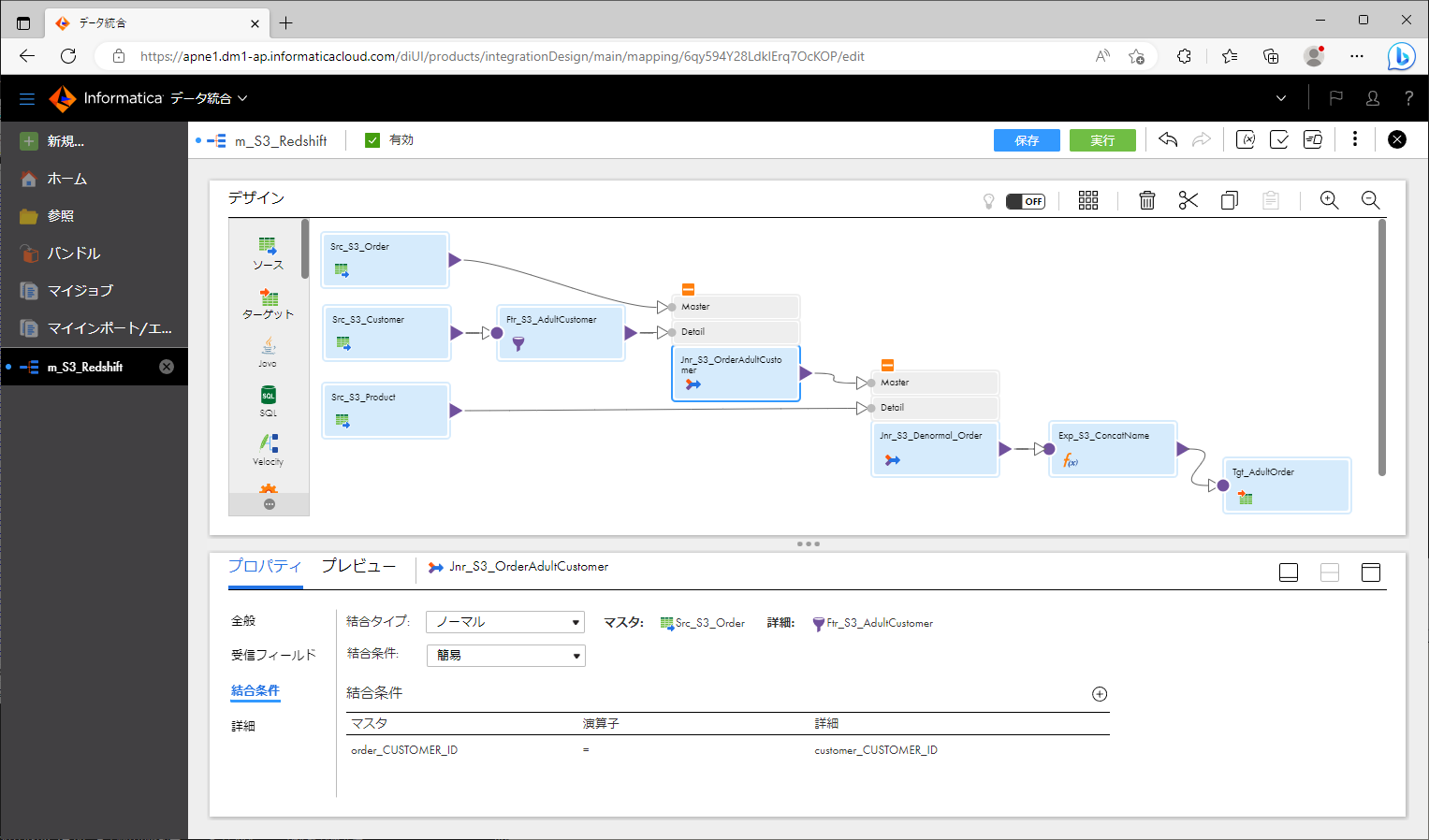
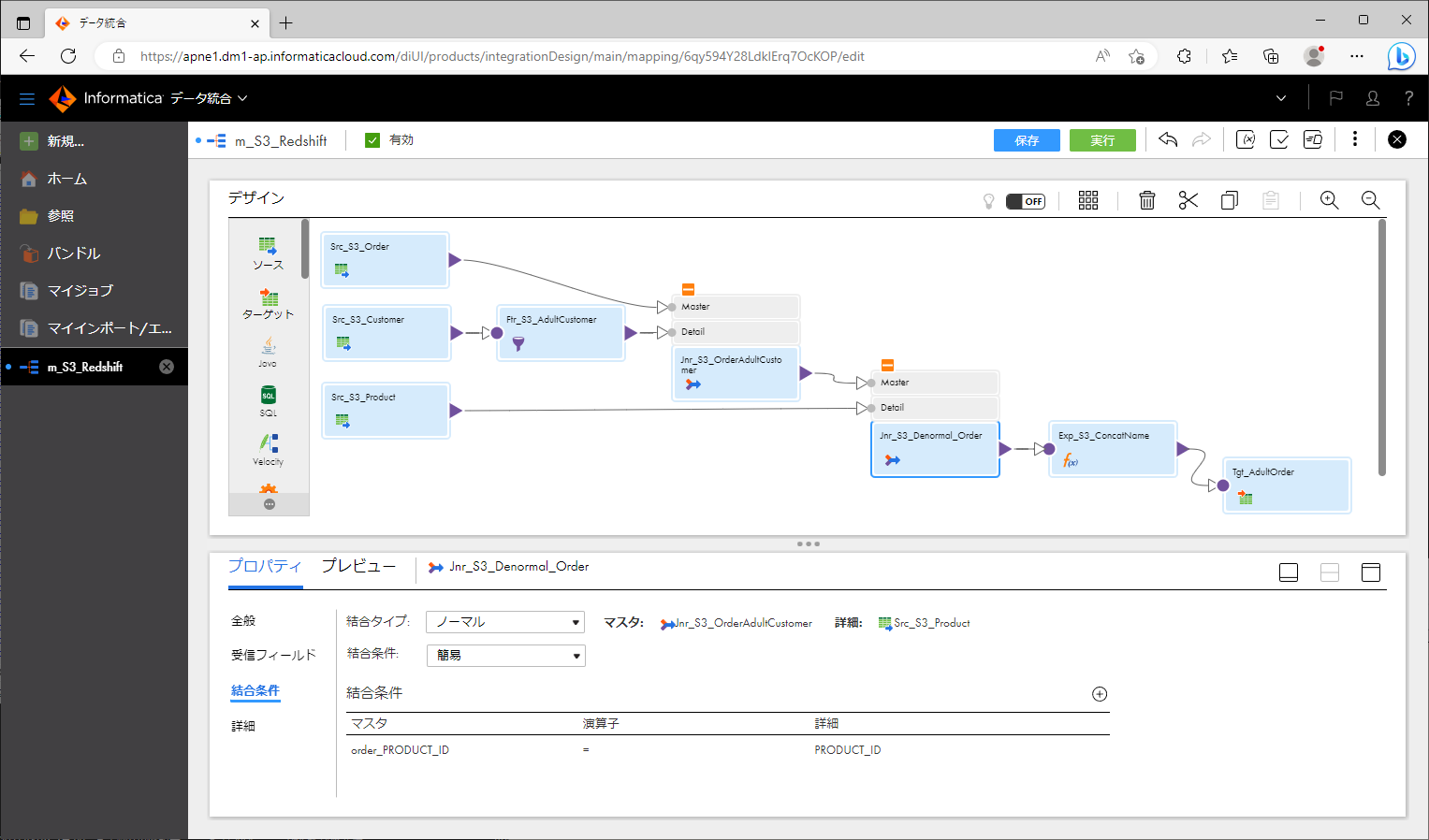
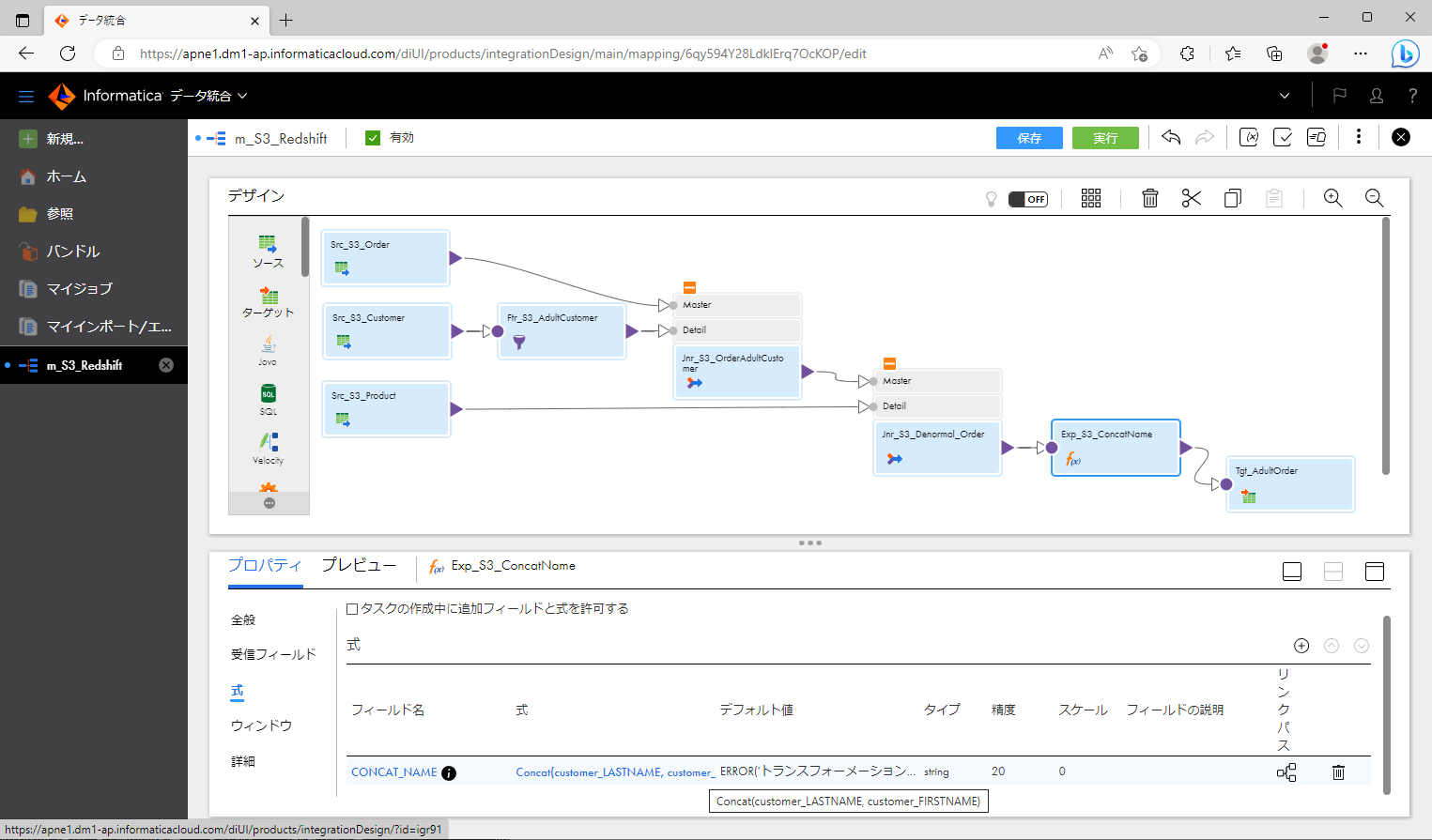
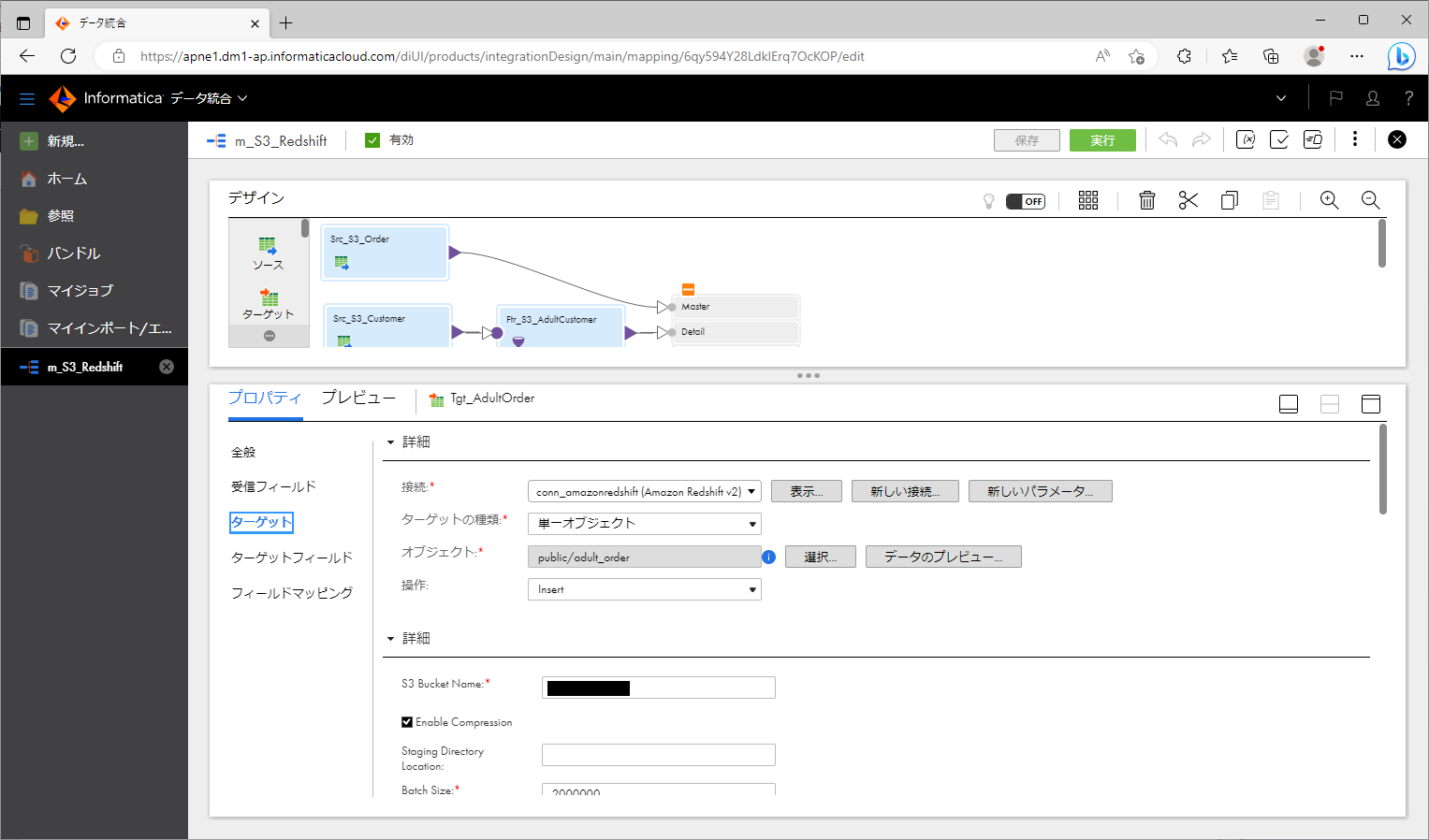
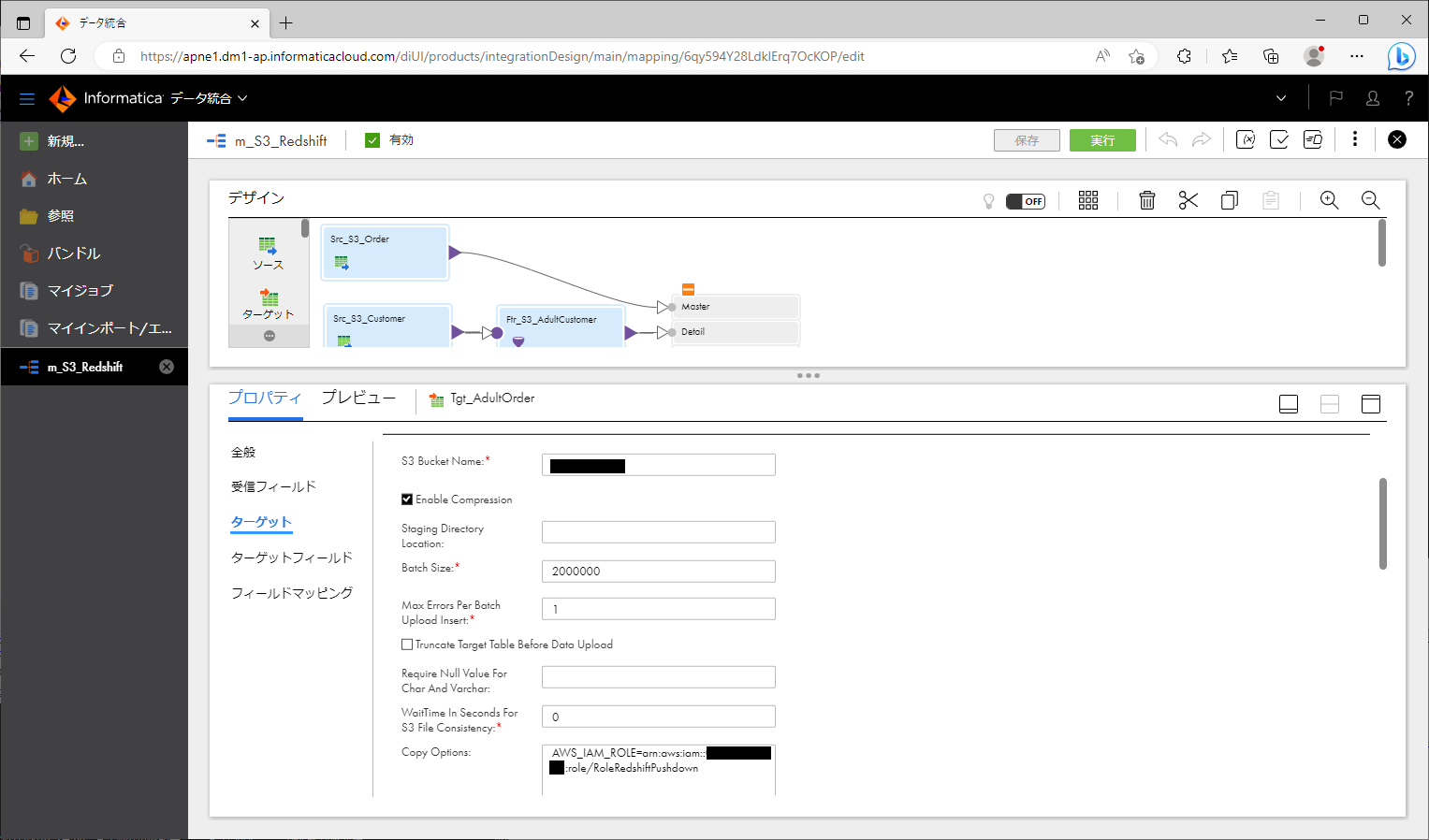
プッシュダウン最適化結果をプレビューする
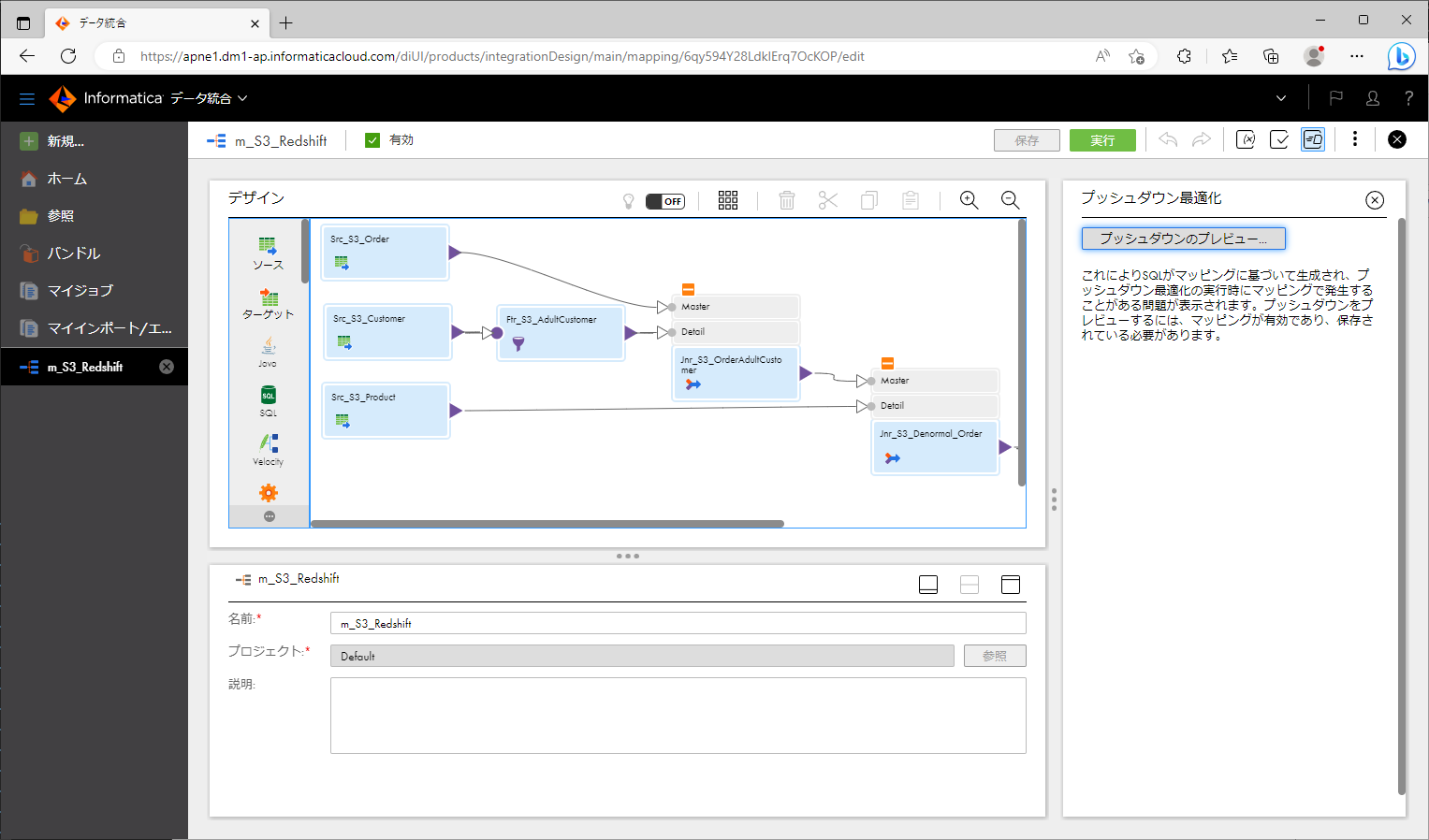
プッシュダウン最適化機能によってマッピングがどのようにSQLクエリに変換されるかをプレビューしてみましょう。
次のように操作します。
- 画面右上の「プッシュダウン最適化」アイコンをクリックする。
- 「プッシュダウンのプレビュー」ボタンをクリックする。
- 「次へ」ボタンをクリックする。
- 「プッシュダウンプレビュー」ボタンをクリックする。
- 生成されたSQLクエリが表示されている箇所の右上の「⇔」アイコンをクリックする。
- プレビューを見終わったら、「閉じる」ボタンをクリックする。
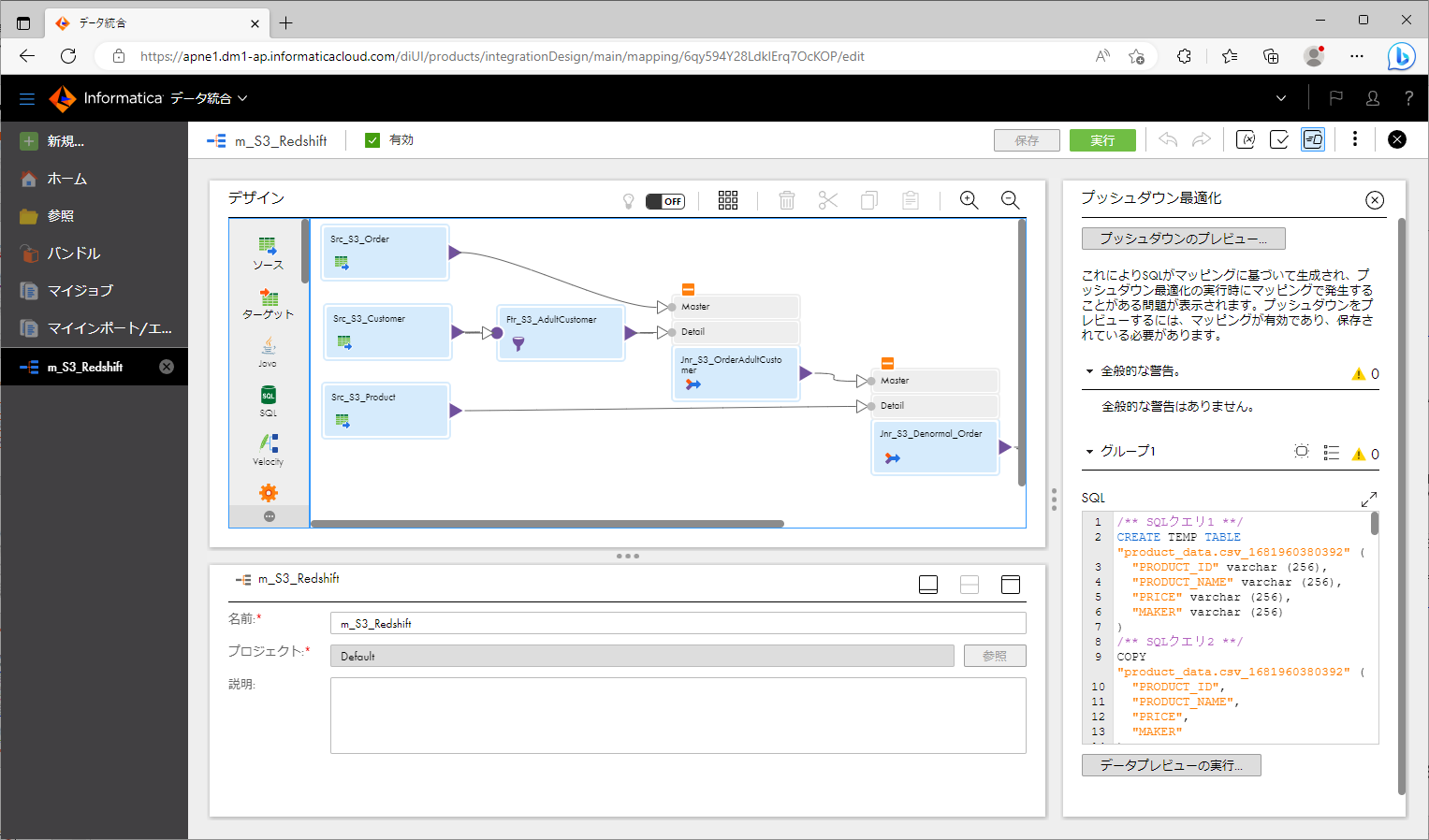
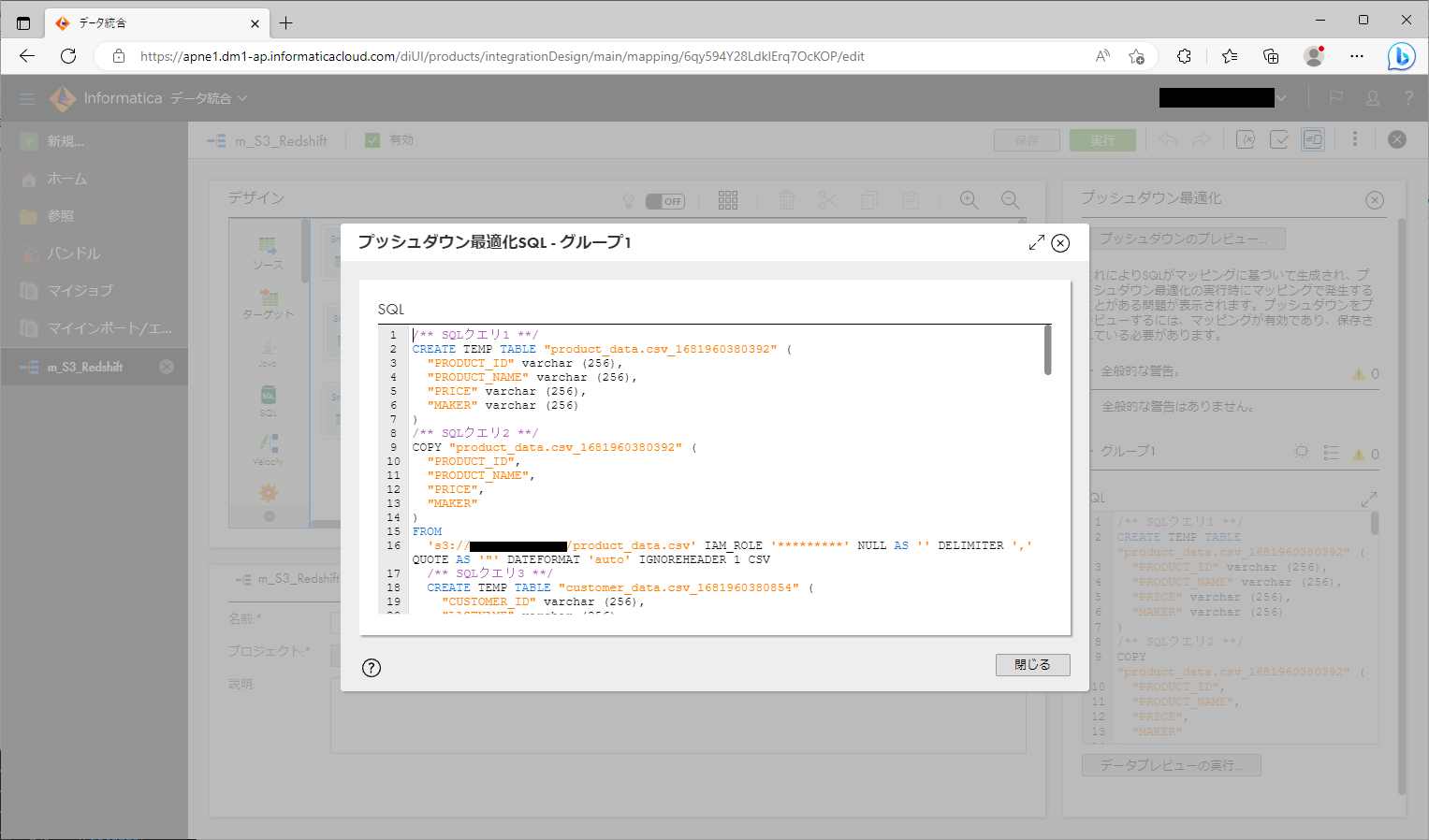
下記が生成されたSQLクエリです。長いのでクエリ毎に折りたたんでいます。
生成されたSQLクエリ1
/** SQLクエリ1 **/
CREATE TEMP TABLE "product_data.csv_1681960380392" (
"PRODUCT_ID" varchar (256),
"PRODUCT_NAME" varchar (256),
"PRICE" varchar (256),
"MAKER" varchar (256)
)
生成されたSQLクエリ2
/** SQLクエリ2 **/
COPY "product_data.csv_1681960380392" (
"PRODUCT_ID",
"PRODUCT_NAME",
"PRICE",
"MAKER"
)
FROM
's3://--------/product_data.csv' IAM_ROLE '*********' NULL AS '' DELIMITER ',' QUOTE AS '"' DATEFORMAT 'auto' IGNOREHEADER 1 CSV
生成されたSQLクエリ3
/** SQLクエリ3 **/
CREATE TEMP TABLE "customer_data.csv_1681960380854" (
"CUSTOMER_ID" varchar (256),
"LASTNAME" varchar (256),
"FIRSTNAME" varchar (256),
"LASTNAME_KANA" varchar (256),
"FIRSTNAME_KANA" varchar (256),
"AGE" varchar (256),
"DATE_OF_BIRTH" varchar (256),
"GENDER" varchar (256),
"MAILADDRESS" varchar (256),
"ZIP_CODE" varchar (256)
)
生成されたSQLクエリ4
/** SQLクエリ4 **/
COPY "customer_data.csv_1681960380854" (
"CUSTOMER_ID",
"LASTNAME",
"FIRSTNAME",
"LASTNAME_KANA",
"FIRSTNAME_KANA",
"AGE",
"DATE_OF_BIRTH",
"GENDER",
"MAILADDRESS",
"ZIP_CODE"
)
FROM
's3://--------/customer_data.csv' IAM_ROLE '*********' NULL AS '' DELIMITER ',' QUOTE AS '"' DATEFORMAT 'auto' IGNOREHEADER 1 CSV
生成されたSQLクエリ5
/** SQLクエリ5 **/
CREATE TEMP TABLE "order_data.csv_1681960380493" (
"ORDER_ID" varchar (256),
"ORDER_DATETIME" varchar (256),
"CUSTOMER_ID" varchar (256),
"PRODUCT_ID" varchar (256),
"QUANTITY" varchar (256)
)
生成されたSQLクエリ6
/** SQLクエリ6 **/
COPY "order_data.csv_1681960380493" (
"ORDER_ID",
"ORDER_DATETIME",
"CUSTOMER_ID",
"PRODUCT_ID",
"QUANTITY"
)
FROM
's3://--------/order_data.csv' IAM_ROLE '*********' NULL AS '' DELIMITER ',' QUOTE AS '"' DATEFORMAT 'auto' IGNOREHEADER 1 CSV
生成されたSQLクエリ7
/** SQLクエリ7 **/
INSERT INTO
"public"."adult_order" (
"order_id",
"customer_fullname",
"customer_age",
"product_name"
)
SELECT
"t80".c3 :: VARCHAR(32),
((CONCAT("t80".c0, "t80".c1)) :: VARCHAR(20)) :: VARCHAR(255),
"t80".c2 :: INT4,
"pro1"."PRODUCT_NAME" :: VARCHAR(32)
FROM
(
SELECT
"pro0"."PRODUCT_ID" :: VARCHAR(256),
"pro0"."PRODUCT_NAME" :: VARCHAR(256)
FROM
"product_data.csv_1681960380392" AS "pro0"
) AS "pro1" ("PRODUCT_ID", "PRODUCT_NAME")
INNER JOIN (
SELECT
"t40"."LASTNAME",
"t40"."FIRSTNAME",
"t40"."AGE",
"ord1"."ORDER_ID",
"ord1"."PRODUCT_ID"
FROM
(
SELECT
"cus1"."CUSTOMER_ID",
"cus1"."LASTNAME",
"cus1"."FIRSTNAME",
"cus1"."AGE"
FROM
(
SELECT
"cus0"."CUSTOMER_ID" :: VARCHAR(256),
"cus0"."LASTNAME" :: VARCHAR(256),
"cus0"."FIRSTNAME" :: VARCHAR(256),
"cus0"."AGE" :: VARCHAR(256)
FROM
"customer_data.csv_1681960380854" AS "cus0"
) AS "cus1" ("CUSTOMER_ID", "LASTNAME", "FIRSTNAME", "AGE")
WHERE
'18' <= "cus1"."AGE"
) AS "t40" ("CUSTOMER_ID", "LASTNAME", "FIRSTNAME", "AGE")
INNER JOIN (
SELECT
"ord0"."ORDER_ID" :: VARCHAR(256),
"ord0"."CUSTOMER_ID" :: VARCHAR(256),
"ord0"."PRODUCT_ID" :: VARCHAR(256)
FROM
"order_data.csv_1681960380493" AS "ord0"
) AS "ord1" ("ORDER_ID", "CUSTOMER_ID", "PRODUCT_ID") ON "ord1"."CUSTOMER_ID" = "t40"."CUSTOMER_ID"
) AS "t80" (c0, c1, c2, c3, c4) ON "t80".c4 = "pro1"."PRODUCT_ID"
マッピングタスクを作って実行する
さてこれで、どんなSQLクエリが生成されるかは分かったので、実際に実行してみます。
実行するには、まず、「マッピングタスク」という定義体を作成し、その後、そのマッピングタスクを実行します。
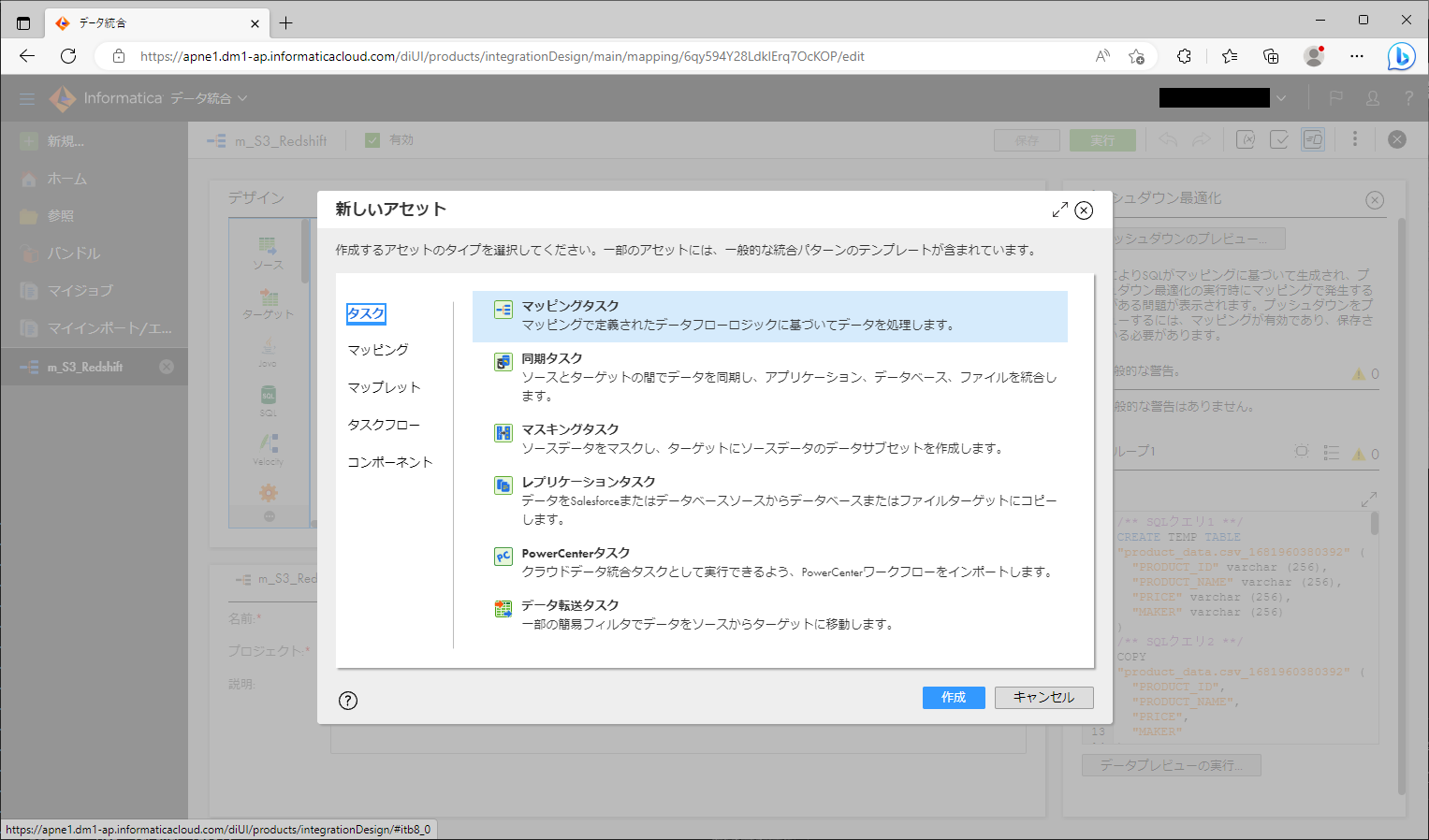
- 左ペインにて「新規」をクリックする。
- ダイアログで、「タスク」>「マッピングタスク」をクリックする。
- 「作成」ボタンをクリックする。
- 次のように設定する。
設定項目 設定値 タスク名 【任意】 プロジェクト 【デフォルト値のまま】 説明 ランタイム環境 【自分のランタイム環境(Secure Agentをインストールしたマシン)】 マッピング 【先ほど作成したマッピング】 - 「次へ」ボタンをクリックする。
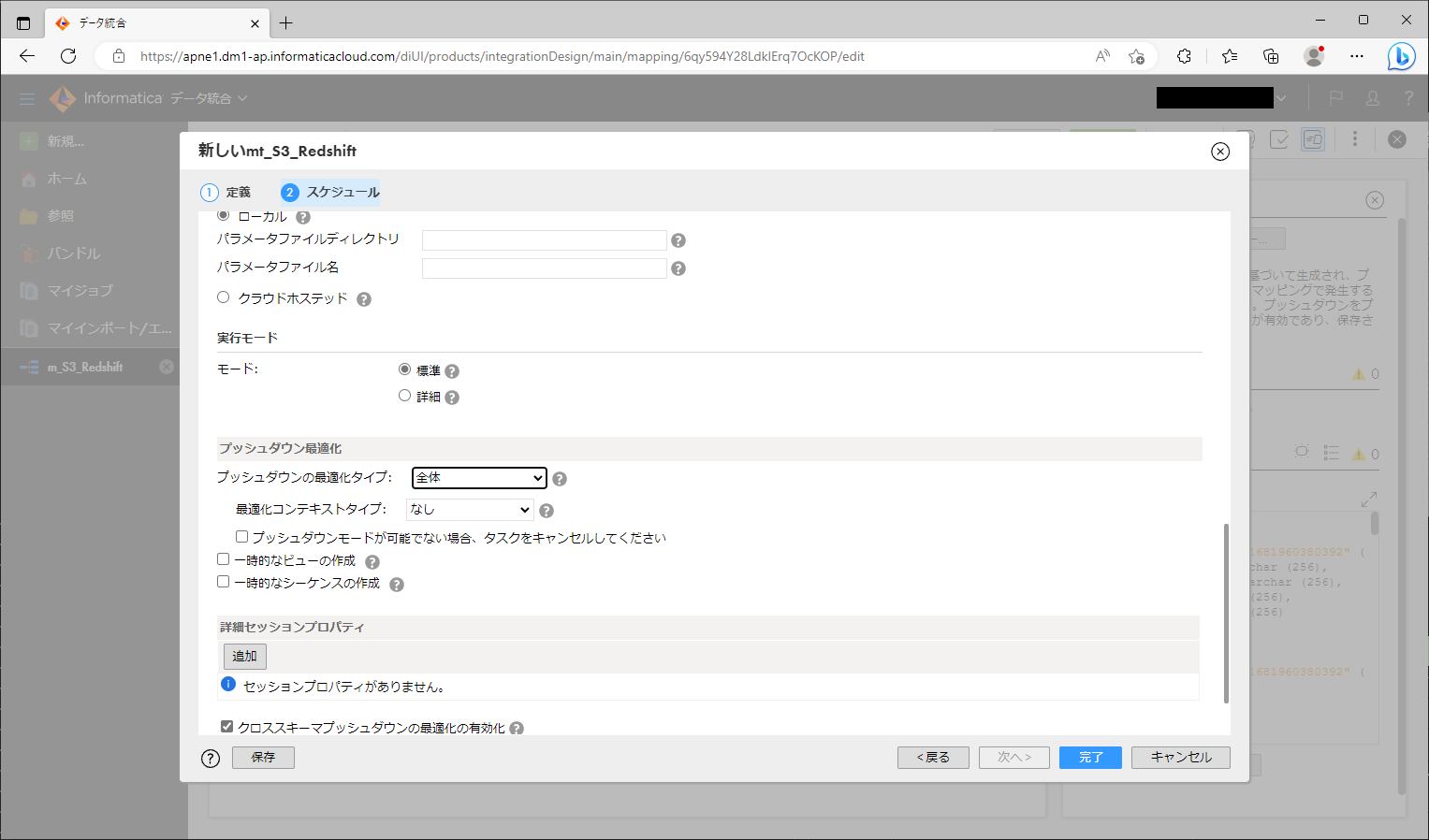
- 「スケジュールと詳細設定」の 「プッシュダウン最適化」パート にて、次のように設定する。
設定項目 設定値 プッシュダウンの最適化タイプ 【任意。「全体」など。プッシュダウン先を片寄せしたい場合は他の値を選ぶ。】 最適化コンテキストタイプ 【デフォルト値のまま】 プッシュダウンモードが可能でない場合、タスクをキャンセルしてください 【デフォルト値のまま】 一時的なビューの作成 【デフォルト値のまま】 一時的なシーケンスの作成 【デフォルト値のまま】 - 「完了」ボタンをクリックする。
- 「実行」ボタンをクリックする。
マッピングタスクの実行結果を見る
マッピングタスクを実行できたので、結果を見てみましょう。
次のように操作します。
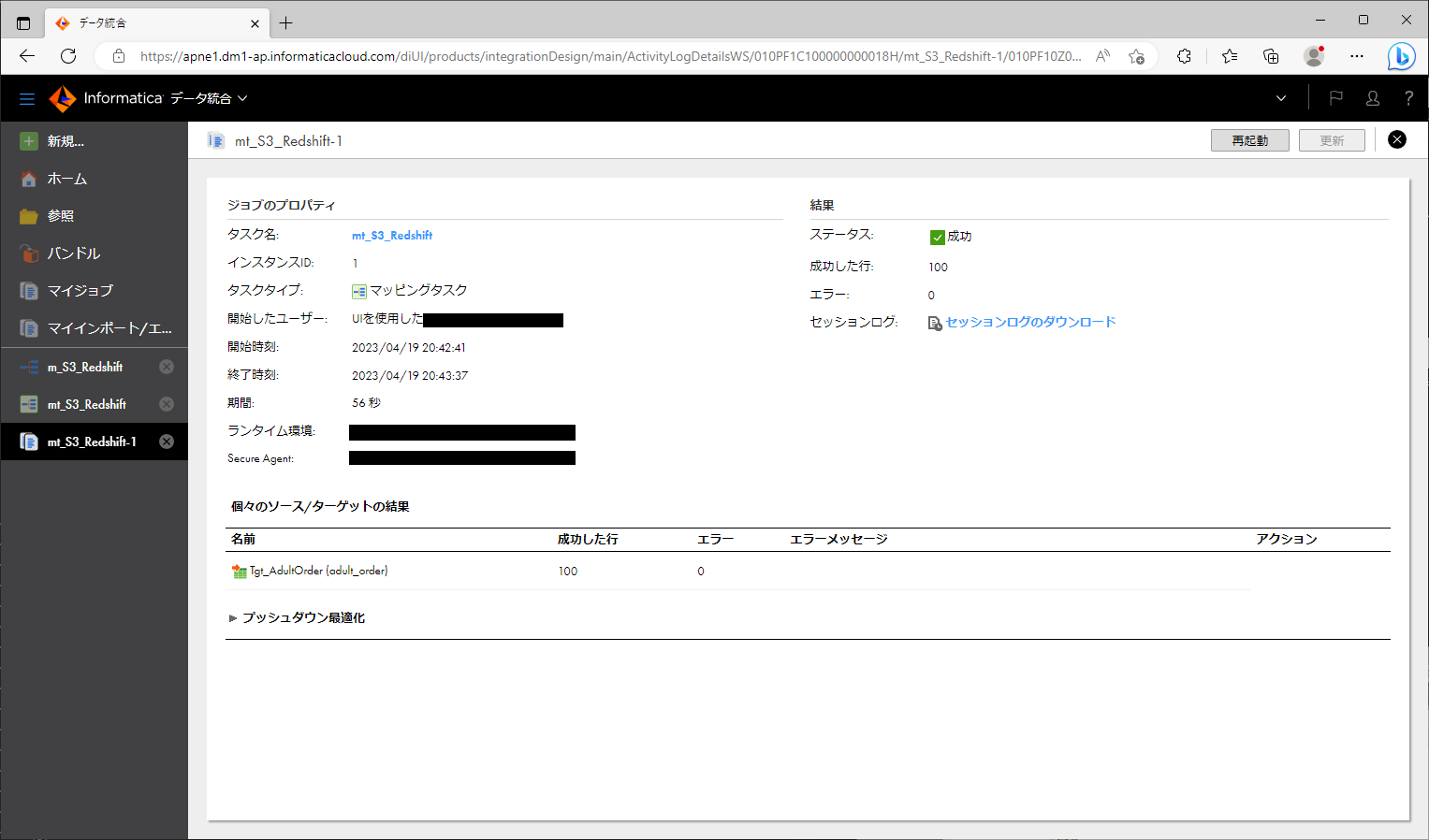
- 左ペインにて「マイジョブ」をクリックする。
- 最上部(最新)のジョブインスタンスをクリックする。
- 「ステータス」に「成功」と表示されていることを確認する。
- 下部の「プッシュダウン最適化」パートにて、プッシュダウンされたSQLクエリを確認する。
ここで、本当にプッシュダウンされているか、この画面からセッションログをダウンロードして見てみます。
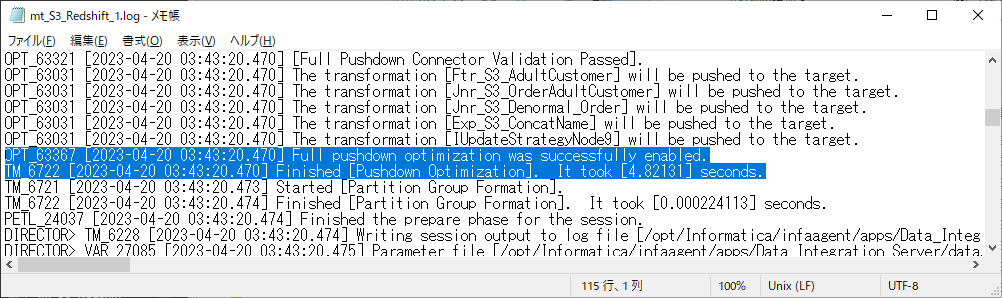
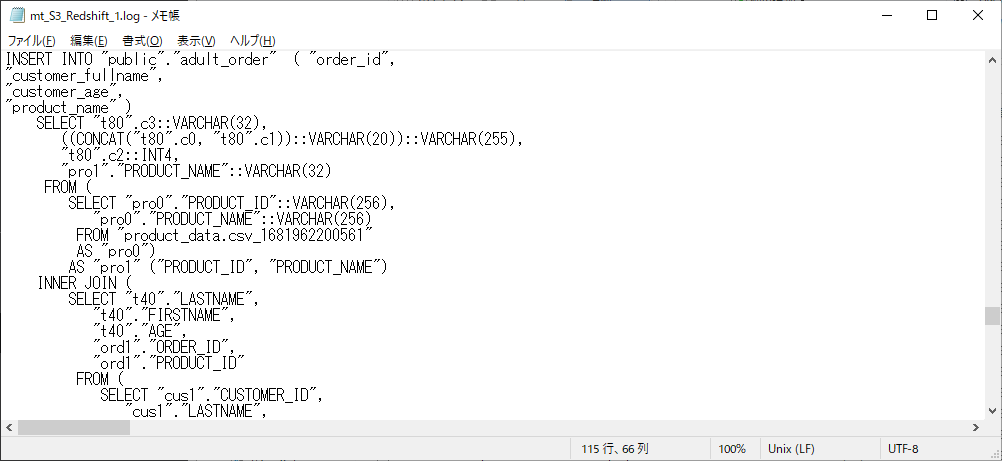
実際にプッシュダウンされており、先ほどプレビューで見たSQLクエリが、Redshiftに発行されていることを確認できました。
結局、プッシュダウンでパフォーマンスは上がったの?
さて、ここまで読んできた皆さんが気になるのは、「結局、プッシュダウンの有無によって、データ統合処理のパフォーマンスは向上したの?」という点かと思いますが、それは、次に挙げるような様々な条件によって変わるため、ここで提示するのは控えます。
- プッシュダウンなしのデータ統合処理(ETL処理)で使用するEC2インスタンスのインスタンスタイプ
- プッシュダウンありのデータ統合処理(ELT処理)で使用するRedshiftクラスターのノードの種類
- 入出力するデータ量 etc...
大量のデータを処理する場合であったり、プッシュダウン先のパワーに期待できる場合は、プッシュダウン最適化機能の有効化を選択肢に入れるのも良いでしょう。(プッシュダウンできない種類の変換処理もあります)
おわりに
以上、「Informaticaのデータ統合サービスCloud Data IntegrationでRedshiftにELTしてみた」でした。
CDIは30日間の無料体験ができる ので、この機会に試してみてはいかがでしょうか。
仲間募集
NTTデータ ソリューション事業本部 では、以下の職種を募集しています。
1. クラウド技術を活用したデータ分析プラットフォームの開発・構築(ITアーキテクト/クラウドエンジニア)
クラウド/プラットフォーム技術の知見に基づき、DWH、BI、ETL領域におけるソリューション開発を推進します。
https://enterprise-aiiot.nttdata.com/recruitment/career_sp/cloud_engineer
2. データサイエンス領域(データサイエンティスト/データアナリスト)
データ活用/情報処理/AI/BI/統計学などの情報科学を活用し、よりデータサイエンスの観点から、データ分析プロジェクトのリーダーとしてお客様のDX/デジタルサクセスを推進します。
https://enterprise-aiiot.nttdata.com/recruitment/career_sp/datascientist
3.お客様のAI活用の成功を推進するAIサクセスマネージャー
DataRobotをはじめとしたAIソリューションやサービスを使って、
お客様のAIプロジェクトを成功させ、ビジネス価値を創出するための活動を実施し、
お客様内でのAI活用を拡大、NTTデータが提供するAIソリューションの利用継続を推進していただく人材を募集しています。
https://nttdata-career.jposting.net/u/job.phtml?job_code=804
4.DX/デジタルサクセスを推進するデータサイエンティスト《管理職/管理職候補》
データ分析プロジェクトのリーダとして、正確な課題の把握、適切な評価指標の設定、分析計画策定や適切な分析手法や技術の評価・選定といったデータ活用の具現化、高度化を行い分析結果の見える化・お客様の納得感醸成を行うことで、ビジネス成果・価値を出すアクションへとつなげることができるデータサイエンティスト人材を募集しています。https://nttdata-career.jposting.net/u/job.phtml?job_code=898
ソリューション紹介
Trusted Data Foundationについて
~データ資産を分析活用するための環境をオールインワンで提供するソリューション~
https://www.nttdata.com/jp/ja/lineup/tdf/
最新のクラウド技術を採用して弊社が独自に設計したリファレンスアーキテクチャ(Datalake+DWH+AI/BI)を顧客要件に合わせてカスタマイズして提供します。
可視化、機械学習、DeepLearningなどデータ資産を分析活用するための環境がオールインワンで用意されており、これまでとは別次元の量と質のデータを用いてアジリティ高くDX推進を実現できます。
TDFⓇ-AM(Trusted Data Foundation - Analytics Managed Service)について
~データ活用基盤の段階的な拡張支援(Quick Start) と保守運用のマネジメント(Analytics Managed)をご提供することでお客様のDXを成功に導く、データ活用プラットフォームサービス~
https://www.nttdata.com/jp/ja/lineup/tdf_am/
TDFⓇ-AMは、データ活用をQuickに始めることができ、データ活用の成熟度に応じて段階的に環境を拡張します。プラットフォームの保守運用はNTTデータが一括で実施し、お客様は成果創出に専念することが可能です。また、日々最新のテクノロジーをキャッチアップし、常に活用しやすい環境を提供します。なお、ご要望に応じて上流のコンサルティングフェーズからAI/BIなどのデータ活用支援に至るまで、End to Endで課題解決に向けて伴走することも可能です。
NTTデータとInformaticaについて
データ連携や処理方式を専門領域として10年以上取り組んできたプロ集団であるNTTデータは、データマネジメント領域でグローバルでの高い評価を得ているInformatica社とパートナーシップを結び、サービス強化を推進しています。
https://www.nttdata.com/jp/ja/lineup/informatica/
NTTデータとTableauについて
ビジュアル分析プラットフォームのTableauと2014年にパートナー契約を締結し、自社の経営ダッシュボード基盤への採用や独自のコンピテンシーセンターの設置などの取り組みを進めてきました。さらに2019年度にはSalesforceとワンストップでのサービスを提供開始するなど、積極的にビジネスを展開しています。
これまでPartner of the Year, Japanを4年連続で受賞しており、2021年にはアジア太平洋地域で最もビジネスに貢献したパートナーとして表彰されました。
また、2020年度からは、Tableauを活用したデータ活用促進のコンサルティングや導入サービスの他、AI活用やデータマネジメント整備など、お客さまの企業全体のデータ活用民主化を成功させるためのノウハウ・方法論を体系化した「デジタルサクセス」プログラムを提供開始しています。
https://www.nttdata.com/jp/ja/lineup/tableau/
NTTデータとAlteryxについて
Alteryx導入の豊富な実績を持つNTTデータは、最高位にあたるAlteryx Premiumパートナーとしてお客さまをご支援します。
導入時のプロフェッショナル支援など独自メニューを整備し、特定の業種によらない多くのお客さまに、Alteryxを活用したサービスの強化・拡充を提供します。
NTTデータとDataRobotについて
NTTデータはDataRobot社と戦略的資本業務提携を行い、経験豊富なデータサイエンティストがAI・データ活用を起点にお客様のビジネスにおける価値創出をご支援します。
NTTデータとDatabricksについて
NTTデータではこれまでも、独自ノウハウに基づき、ビッグデータ・AIなど領域に係る市場競争力のあるさまざまなソリューションパートナーとともにエコシステムを形成し、お客さまのビジネス変革を導いてきました。
Databricksは、これら先端テクノロジーとのエコシステムの形成に強みがあり、NTTデータはこれらを組み合わせることでお客さまに最適なインテグレーションをご提供いたします。