本記事は、dbt Advent Calendar 2024 の 17日目の記事です。
はじめに
こんにちは、株式会社NTTデータグループ 技術革新統括本部 Apps&Data技術部の丸山です。
普段は、dbtなどを活用したデータエンジニアリング周りの支援を担当しています。
データパイプラインの開発において、開発環境や本番環境をアカウント単位やオブジェクト単位などで環境分離している方は多いのではないでしょうか。特に、開発の規模が大きくなるほど、このような適切な環境分離の重要性が増してきます。
本記事では、環境分離の必要性について述べた後、Snowflakeにおける一般的な環境分離方法や、dbt Cloudでの本番/開発環境の分離方法について解説します。
本記事の対象者
dbt Cloudを利用している方
dbtに興味をお持ちの方
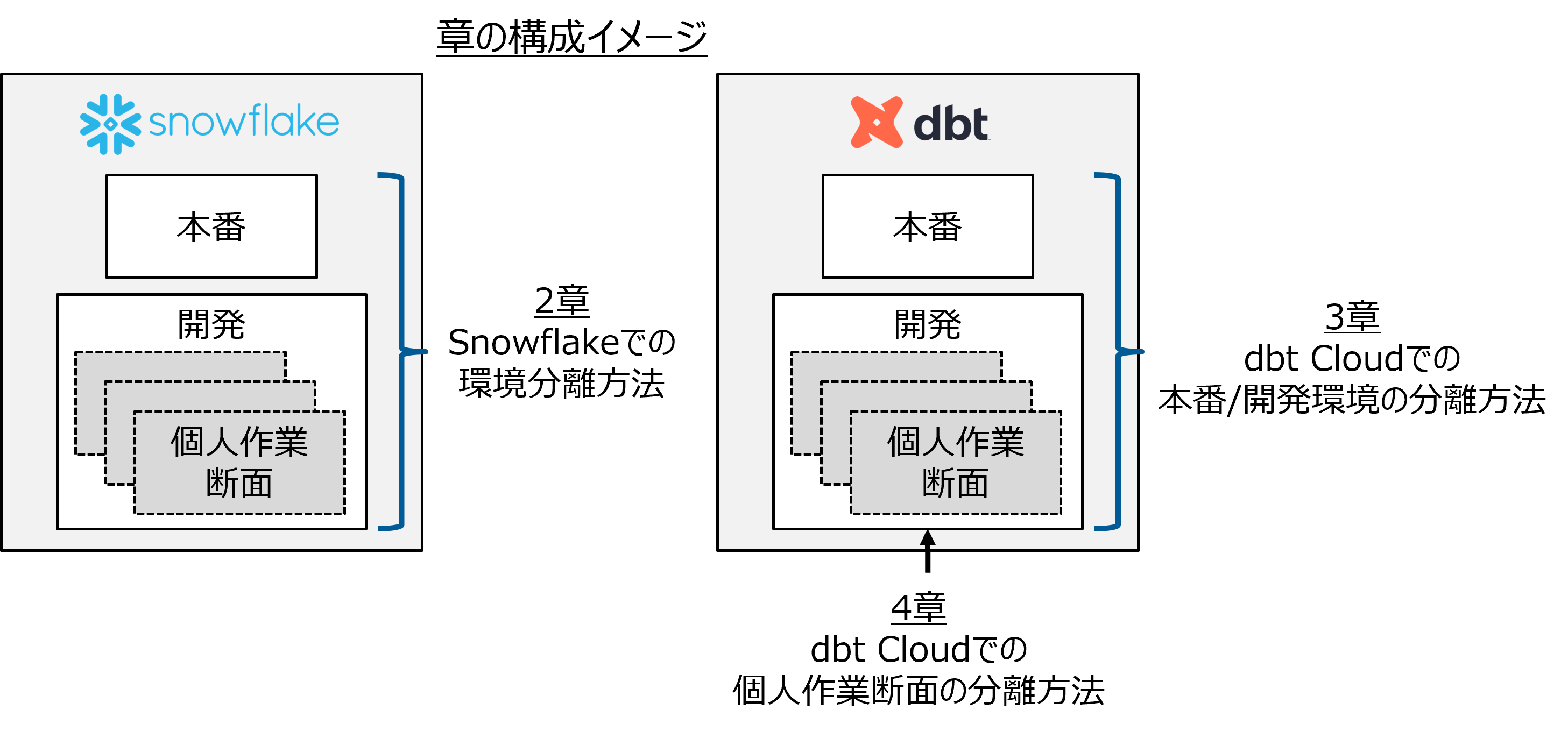
記事の構成
記事の構成は以下の通りです。
- なぜ環境分離が必要なのか?
- Snowflakeでの環境分離方法
- dbt Cloudでの本番/開発環境の分離方法
- dbt Cloudでの個人作業断面の分離方法
- 最後に
1. なぜ環境分離が必要なのか?
環境分離の必要性について、以下の3つの観点で説明します。
1-1. セキュリティリスクの低減
1-2. 設定と依存関係の管理
1-3. 開発効率の向上
1-1. セキュリティリスクの低減
企業の本番環境には、重要な顧客データや機密情報が含まれています。開発者が直接本番環境にアクセスすることで、不正アクセスや意図しない変更が行われるリスクが存在します。適切な環境分離を行うことで、開発環境と本番環境を明確に区別し、本番環境に適用されるアクセス制御を厳格に設定します。これにより、機密情報への不正アクセスを防ぎ、セキュリティリスクを軽減できます。
1-2. 設定と依存関係の管理
開発、テスト、本番環境では、それぞれ異なる設定や依存関係が必要です。一つの環境でこれらを管理することは混乱を招きやすく、設定ミスが本番サービスの停止など重大な問題につながるリスクがあります。環境ごとに異なる設定と依存関係を管理することで、メンテナンス性高く管理できます。開発環境では新しい技術やツールを試験的に導入し、本番環境では安定した設定を維持することで、安全かつ効率的な運用が可能です。
1-3. 開発効率の向上
複数の開発者が一つの環境で作業する場合、共有資源によって開発作業が競合し、作業効率が低下する可能性があります。特に大規模なチームが同時に作業を行う場合、その影響は顕著になります。したがって、個人開発の断面を適切に分離することで、開発チームは独立した環境で自由に作業を進めることができます。これにより、開発効率が向上し、作業の競合を回避することができます。
2.Snowflakeでの環境分離方法
Snowflakeでの環境分離の方法は、主に以下の3つがあげられます。開発環境での個人断面の分離方法は、いくつかパターンがありますが、ここでは代表的な分離方法を載せています。
| 節 | 本番/開発環境の分離方法 | 開発環境での個人断面の分離方法 |
|---|---|---|
| 2-1 | アカウント単位 | スキーマ単位 |
| 2-2 | データベース単位 | スキーマ単位 |
| 2-3 | スキーマ単位 | テーブル単位 |
それぞれの方法について、詳しく説明します。
2-1. アカウント単位で本番/開発環境の分離
この方法では、Snowflakeアカウントを環境ごとに分離します。例えば、開発環境と本番環境の2つを運用する場合は、それぞれ専用のアカウントを用意します。2つのアカウントを管理する必要があるため、メンテナンスコストが発生しますが、アカウント単位でのIP制限などのセキュリティ担保が可能です。したがって、本番環境はセキュアルームからのアクセスのみといった制約がある場合に、多く利用されます。また、開発環境では、以下の画像のように個人作業用のスキーマを作成することで、開発作業を分離することが可能です。

2-2. データベース単位で本番/開発環境の分離
この方法では、1つのアカウント内で環境ごとに別々のデータベースを使用します。例えば、開発環境と本番環境の2つの場合は、それぞれ専用のデータベースを用意します。特に、スキーマ横断でデータパイプラインを構築している場面において多く利用されます。また、開発環境では、以下の画像のように個人作業用のスキーマを作成することで、開発作業を分離することが可能です。

2-3. スキーマ単位で本番/開発環境の分離
この方法では、1つのデータベース内で環境ごとに異なるスキーマを使用します。例えば、開発環境と本番環境の2つの場合は、それぞれ専用のスキーマを用意します。1つスキーマ内でデータの加工処理を完結させる場面において多く利用されます。また、開発の方針によっては、開発用のスキーマが自由に払い出すことができないケースもあると思います。その場合は、以下の画像のようにテーブル名に個人作業用の識別子を付与することで、個人作業断面(テーブル)を作成することが可能です。

3. dbt Cloudでの本番/開発環境の分離方法
次に、dbt Cloudでの本番/開発環境の分離方法について紹介します。本記事では、環境変数を活用することで、2章の環境分離を容易かつメンテナンス性高く実現します。
dbt Cloudでは、公式にもある通り、コネクションと環境で様々な紐づけパターンがありますが、今回は1つのコネクションに各環境を紐づける形とします。
https://docs.getdbt.com/docs/cloud/connect-data-platform/about-connections
以下のステップで、環境分離の実現方法を説明します。
3-1. 各環境の準備
3-2. 環境変数の作成
3-3. 環境変数の適用
3-1. 各環境の準備
まず、dbt Cloudの「Deploy」の「Environments」から、必要な環境を作成します。以下の画像の例では、開発環境「DEV」、本番環境「PROD」を作成しています。

3-2. 環境変数の作成
次に「Environment variables」から各環境ごとの環境変数を設定します。(※環境変数のプレフィックスにDBT_を利用する場合)
- 2-1のアカウント単位での本番/開発環境の分離の場合
| 環境変数 | 開発環境 | 本番環境 |
|---|---|---|
| DBT_ACCOUNT | 開発アカウント名 | 本番アカウント名 |
- 2-2のデータベース単位での本番/開発環境の分離の場合
| 環境変数 | 開発環境 | 本番環境 |
|---|---|---|
| DBT_DATABASE | 開発データベース名 | 本番データベース名 |
- 2-3のスキーマ単位での本番/開発環境の分離の場合
| 環境変数 | 開発環境 | 本番環境 |
|---|---|---|
| DBT_SCHEMA | 開発スキーマ名 | 本番スキーマ名 |
以下の画像は、2-2のデータベース単位で本番/開発環境を分離する場合の設定例を示しています。「DEV」環境では「dbt_dev」データベース、「PROD」環境では「dev_prd」としています。ウェアハウスやロール、クエリタグなどのパラメータを環境で分離する場合も、環境変数として設定することが可能です。

3-3. 環境変数の適用
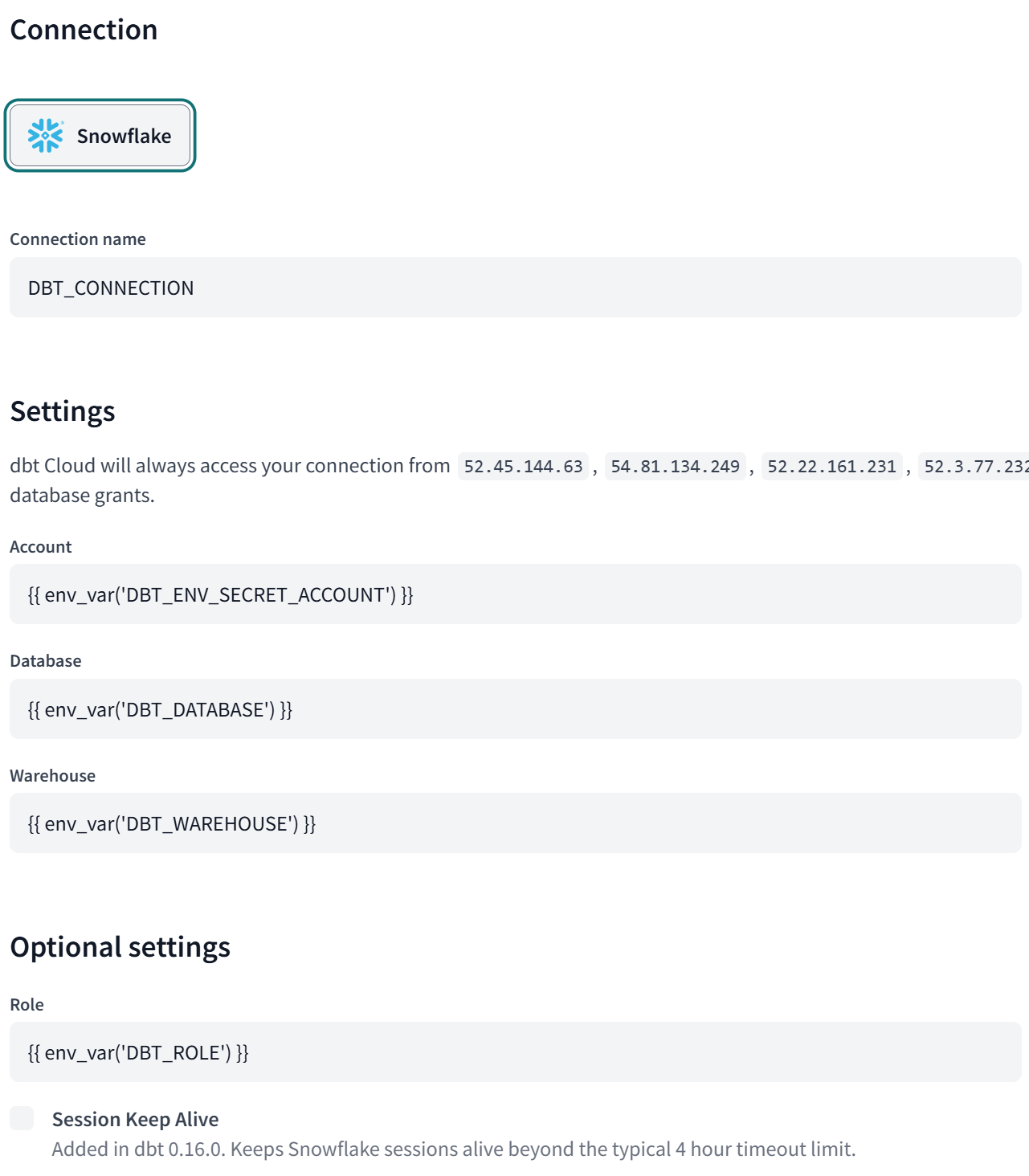
dbt Cloudの「Account Settings」にあるコネクション設定で、3-2で設定した環境変数を適用します。環境変数はenv_varで利用可能です。以下の画像の例では、「DBT_CONNECTION」というコネクションを作成し、各項目で環境変数を適用しています。
コネクション作成後、各環境のコネクション設定項目で、作成したコネクションを指定します。以下の画像の例では、各環境のコネクション設定項目にて「DBT_CONNECTION」を指定しています。
開発環境:
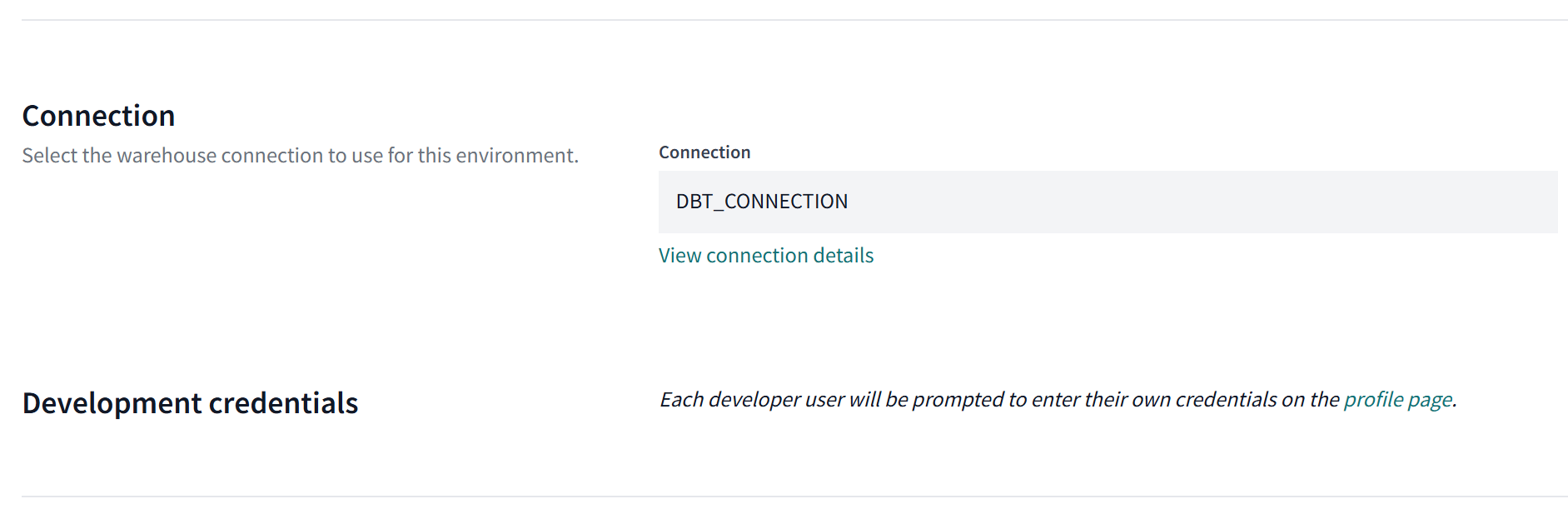
本番環境:

これで環境分離の設定は完了です。各環境でのコネクション指定後、コネクション設定画面では、以下の画像のように、1つのコネクションに対して開発環境や本番環境が紐づく形で表示されます。dbt Cloud IDEでの作業やdbt Cloudのジョブを実行する際は、設定した環境変数に基づいて実行されるようになります。

4. dbt Cloudでの個人作業断面の分離方法
続いて、開発環境内における個人作業用の断面のつくり方をご紹介します。特に、同一のデータパイプラインを複数人が同時に開発する場合、同じスキーマやテーブルで作業すると、競合が発生してしまいます。したがって、個人作業用の断面を準備することは、競合を防ぐという意味で重要になります。
今回は、以下の2つのパターンで、個人断面のつくり方をご紹介します。
4-1. スキーマ単位で個人作業断面を分離する場合
4-2. テーブル単位で個人作業断面を分離する場合
4-1. スキーマ単位で個人作業断面を分離する場合
以下の画像の例のように、開発用のデータベース内などで個人作業断面のスキーマを作成します。今回は、個人識別子をスキーマ名の接尾に付与することで、個人環境の分離を実現します。

これを実現するには、dbtが提供しているCustom schemasマクロを利用します。
4-1-1. Custom schemasマクロとは?
Custom schemasマクロとは、出力先のスキーマを変更したい場合に、dbt_project.ymlや各モデルファイルでカスタムスキーマを設定することで、任意のスキーマに出力することが可能です。この機能は、dbtのデフォルト機能として備わっています。
デフォルト設定では、カスタムスキーマを与えていない場合はターゲットスキーマ、つまり実行する環境内で設定しているスキーマとなり、カスタムスキーマを与えている場合は、ターゲットスキーマにカスタムスキーマが接尾に付与する形となります。動作イメージとしては以下の通りです。
| ターゲットスキーマ | カスタムスキーマ | 出力先のスキーマ |
|---|---|---|
| DBT_SCHEMA | なし | DBT_SCHEMA |
| DBT_SCHEMA | QIITA | DBT_SCHEMA_QIITA |
「接尾に付与されるなら、カスタムスキーマで個人識別子を設定しても良いか?」
はい、それは問題ありません。ただ、カスタムスキーマに個人識別子を直書きする方法は、デフォルトブランチへのプルリクエストやマージ時に削除を忘れるリスクがあるため、推奨されません。
代わりに、Gitのブランチ名をスキーマ名と連動させたい場合は、dbt Cloud IDEでは環境変数DBT_CLOUD_GIT_BRANCHを利用することが可能です。この環境変数をカスタムスキーマとして設定することで、ターゲットスキーマに現在のGitブランチ名が接尾に付与されたスキーマに対して出力することができます。
ブランチ名に「/」や「-」などの特殊文字が含まれている場合、実行時にエラーが発生します。
Custom schemasマクロの挙動を変更したい場合は、dbtプロジェクトのmacros配下にgenerate_schema_name.sqlというSQLファイルを作成し、公式HPに掲載されている以下のコードを貼り付けおよび修正することで、マクロの動作を変更することが可能です。
{% macro generate_schema_name(custom_schema_name, node) -%}
{%- set default_schema = target.schema -%}
{%- if custom_schema_name is none -%}
{{ default_schema }}
{%- else -%}
{{ default_schema }}_{{ custom_schema_name | trim }}
{%- endif -%}
{%- endmacro %}
4-1-2. Custom schemasマクロの変更
Custom schemasマクロに変更を加えて、スキーマ名の接尾に個人識別子を付与する処理にします。変更後のCustom schemasマクロのコードは以下の通りです。
{% macro generate_schema_name(custom_schema_name, node) -%}
{%- set unique_id = var('unique_id', '') -%} {# 個人識別子の変数 #}
{%- set default_schema = target.schema -%}
{%- if custom_schema_name is none -%} {# カスタムスキーマが与えられていない場合 #}
{%- if unique_id | trim == '' -%} {# 個人識別子が与えられていない場合 #}
{{ default_schema }}
{%- else -%} {# 個人識別子が与えられている場合 #}
{{ default_schema }}_{{ unique_id | trim }}
{%- endif -%}
{%- else -%} {# カスタムスキーマが与えられている場合 #}
{%- if unique_id | trim == '' -%} {# 個人識別が与えられていない場合 #}
{{ default_schema }}_{{ custom_schema_name | trim }}
{%- else -%} {# 個人識別子が与えられている場合 #}
{{ default_schema }}_{{ custom_schema_name | trim }}_{{ unique_id | trim }}
{%- endif -%}
{%- endif -%}
{%- endmacro %}
unique_idという個人識別子の変数を準備して、値が与えられていない場合は、空文字が代入されるようにしています。元のコードにif文を追加して、個人識別子が与えられている場合はスキーマ名に個人識別子を付与し、個人識別子が与えられていない場合はスキーマ名をそのまま出力するようにしています。
4-1-3. 実行確認
それでは、dbt Cloud IDEから挙動を確認します。まずは、通常のdbt run実行を確認します。以下の画像は、実際の実行画面です。

ターゲットスキーマはDBT_SCHEMAで設定しているため、DBT_SCHEMAにテーブルが作成されていることが分かります。
次に、個人識別子QIITAを与えてdbt runを実行してみます。以下の画像は、実際の実行画面です。
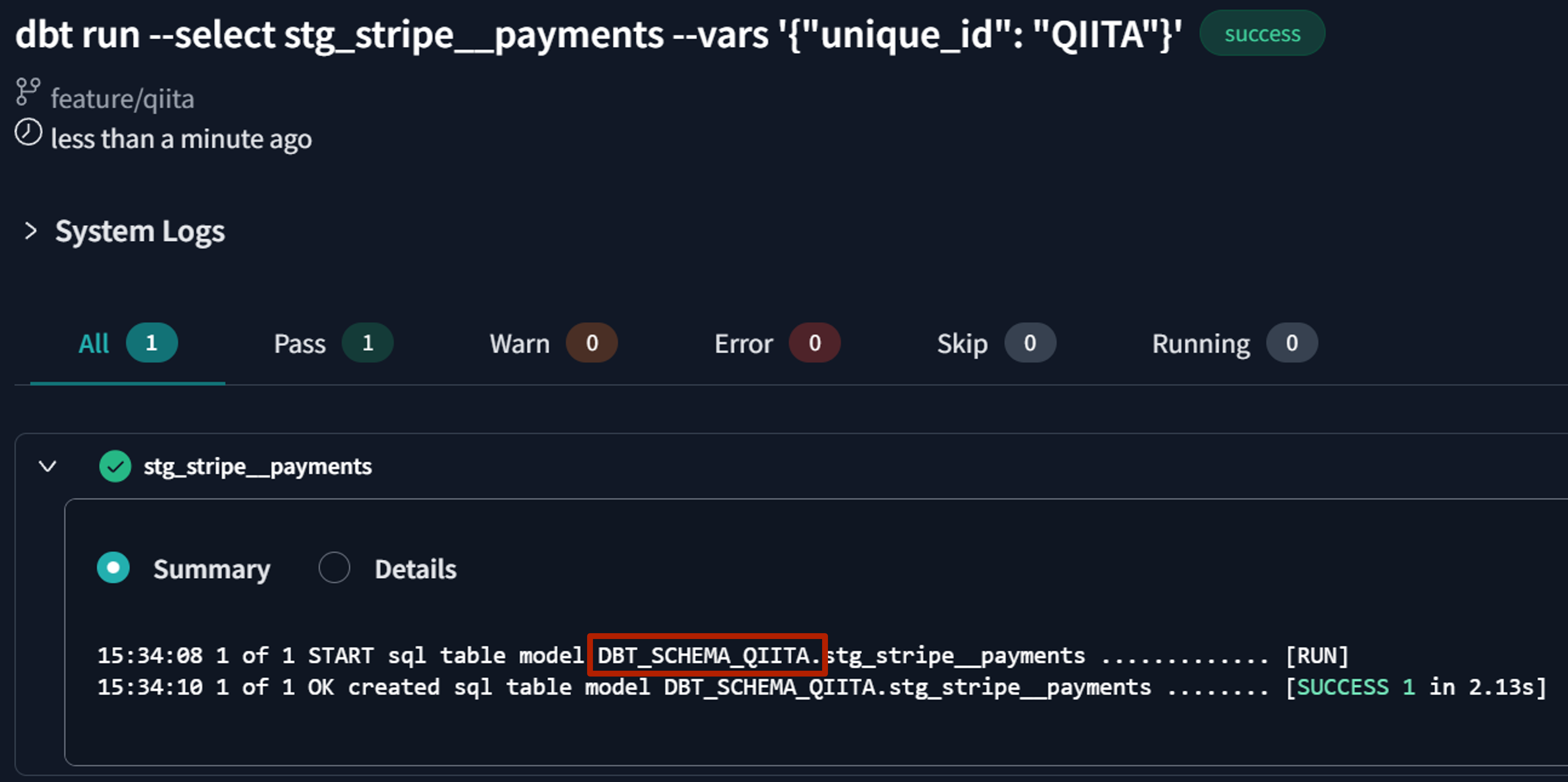
無事に、個人識別子が付与されたスキーマDBT_SCHEMA_QIITAに出力していることを確認しました。このように、スキーマ名に個人識別子を付与するようにCustom schemasマクロを変更することで、スキーマ単位での個人作業環境の分離が実現できます。
4-2. テーブル単位で個人作業断面を分離する場合
以下の画像の例のように、開発用のスキーマ内でテーブル単位の個人作業断面を作成します。今回は、開発者の個人識別子をテーブル名の接尾に付与することで、個人環境の分離を実現します。

これを実現するには、dbtが提供しているCustom aliasesマクロを利用します。
4-2-1. Custom aliasesマクロとは?
Custom aliasesマクロとは、出力するテーブル名を変更したい場合に、各モデルファイルなどでカスタムエイリアスを設定することで、任意のテーブル名で出力することが可能です。この機能は、dbtのデフォルト機能として備わっています。
デフォルト設定では、カスタムエイリアスを与えていない場合はモデル名(SQLファイル名)がテーブル名となり、カスタムエイリアスを与えている場合は、カスタムエイリアス名がそのままテーブル名となります。
| モデル名(SQLファイル名) | カスタムエイリアス | 出力テーブル名 |
|---|---|---|
| DBT_TABLE | なし | DBT_TABLE |
| DBT_TABLE | QIITA_TABLE | QIITA_TABLE |
Custom aliasesマクロの挙動を変更したい場合は、dbtプロジェクトのmacros配下にgenerate_alias_name.sqlというSQLファイルを作成し、公式HPに掲載されている以下のコードを貼り付けおよび修正することで、マクロの動作を変更することが可能です。
{% macro generate_alias_name(custom_alias_name=none, node=none) -%}
{%- if custom_alias_name -%}
{{ custom_alias_name | trim }}
{%- elif node.version -%}
{{ return(node.name ~ "_v" ~ (node.version | replace(".", "_"))) }}
{%- else -%}
{{ node.name }}
{%- endif -%}
{%- endmacro %}
4-2-2. Custom aliasesマクロの変更
Custom aliasesマクロに変更を加えて、テーブル名の接尾に個人識別子を付与する処理にします。変更後のCustom aliasesマクロのコードは以下の通りです。
{% macro generate_alias_name(custom_alias_name=none, node=none) -%}
{%- set unique_id = var('unique_id', '') -%} {# 個人識別子の変数 #}
{%- if custom_alias_name -%} {# カスタムエイリアスが与えられている場合 #}
{%- if unique_id | trim == '' -%} {# 個人識別子が与えられていない場合 #}
{{ custom_alias_name | trim }}
{%- else -%} {# 個人識別子が与えられている場合 #}
{{ custom_alias_name | trim }}_{{ unique_id | trim }}
{%- endif -%}
{%- elif node.version -%} {# モデルのバージョンがある場合 #}
{%- if unique_id | trim == '' -%} {# 個人識別子が与えられていない場合 #}
{{ return(node.name ~ "_v" ~ (node.version | replace(".", "_"))) }}
{%- else -%} {# 個人識別子が与えられている場合 #}
{{ return(node.name ~ "_v" ~ (node.version | replace(".", "_"))) }}_{{ unique_id | trim }}
{%- endif -%}
{%- else -%} {# 通常のモデルの場合 #}
{%- if unique_id | trim == '' -%} {# 個人識別子が与えられていない場合 #}
{{ node.name }}
{%- else -%} {# 個人識別子が与えられている場合 #}
{{ node.name }}_{{ unique_id | trim }}
{%- endif -%}
{%- endif -%}
{%- endmacro %}
Custom schemasマクロと同様、unique_idという個人識別子の変数を準備して、値が与えられていない場合は、空文字が代入されるようにしています。元のコードにif文を追加して、個人識別子が与えられている場合はテーブル名に個人識別子を付与し、個人識別子が与えられていない場合はテーブル名をそのまま出力するようにしています。
4-2-3. 実行確認
それでは、dbt Cloud IDEから挙動を確認します。まずは、通常のdbt run実行を確認します。以下の画像は、実際の実行画面です。

モデル名stg_stripe__paymentsがそのままテーブル名として作成されていることが分かります。
次に、コマンドから個人識別子qiitaを与えてdbt runを実行してみます。以下の画像は、実際の実行画面です。

無事に、個人識別子の付与されたテーブルstg_stripe__payments_qiitaが出力していることを確認しました。このように、テーブル名に個人識別子を付与するようにCustom aliasesマクロを変更することで、テーブル単位での個人作業環境の分離が実現できます。
5. 最後に
本記事では、環境分離の必要性からdbt Cloudでの環境分離の実現方法についてお伝えしました。
開発の規模がスケールするにしたがって、このような適切な環境分離を実現することは非常に重要になってきます。特に1章で述べたようなセキュリティリスクの低減や開発効率の向上は、開発プロセスの品質と信頼性を確保するために不可欠です。プロジェクトで求められる開発要件に対して、今回ご紹介したdbt Cloudでの環境分離の実現方法が少しでも役に立てば幸いです。
最後まで閲覧いただきありがとうございました。