はじめに
株式会社NTTデータ テクノロジーコンサルティング事業本部の@nttd-kashiwabarayです。
AWS DeepRacerをAWSマネージメントコンソールから利用できるのも残り1か月間となりました。ぜひこれまで取り組んできた方もまだやったことがない方もぜひ残り1か月楽しんでいただけたらと思っています。
現在もPractice Raceが開催されており、世界のトップレーサーたちも参戦しておりますので、ぜひチャレンジしてみてください。
なお、5月に「AWS DeepRacerで学ぶ 強化学習」という本も出版されておりますので、合わせてご覧ください。
AWS DeepRacerで学ぶ 強化学習

本ブログでは、「概要編」、「AWSマネージメントコンソール編」、「ローカルトレーニング編」として3回に渡って、AWS DeepRacerの魅力、トレーニング方法などをお伝えします。
前回の「概要編」に続いて、「AWSマネージメントコンソール編」をお伝えします。
AWSマネージメントコンソールでDeepRacerをはじめよう
AWSマネージメントコンソールを活用することで、初学者の方でもサンプルプログラムを活用しながら、5分で学習を開始することが可能です。
まずはAWSマネージメントコンソールにログインを実施して、検索窓で「DeepRacer」と入力し、「AWS DeepRacer」のリンクを押下します。
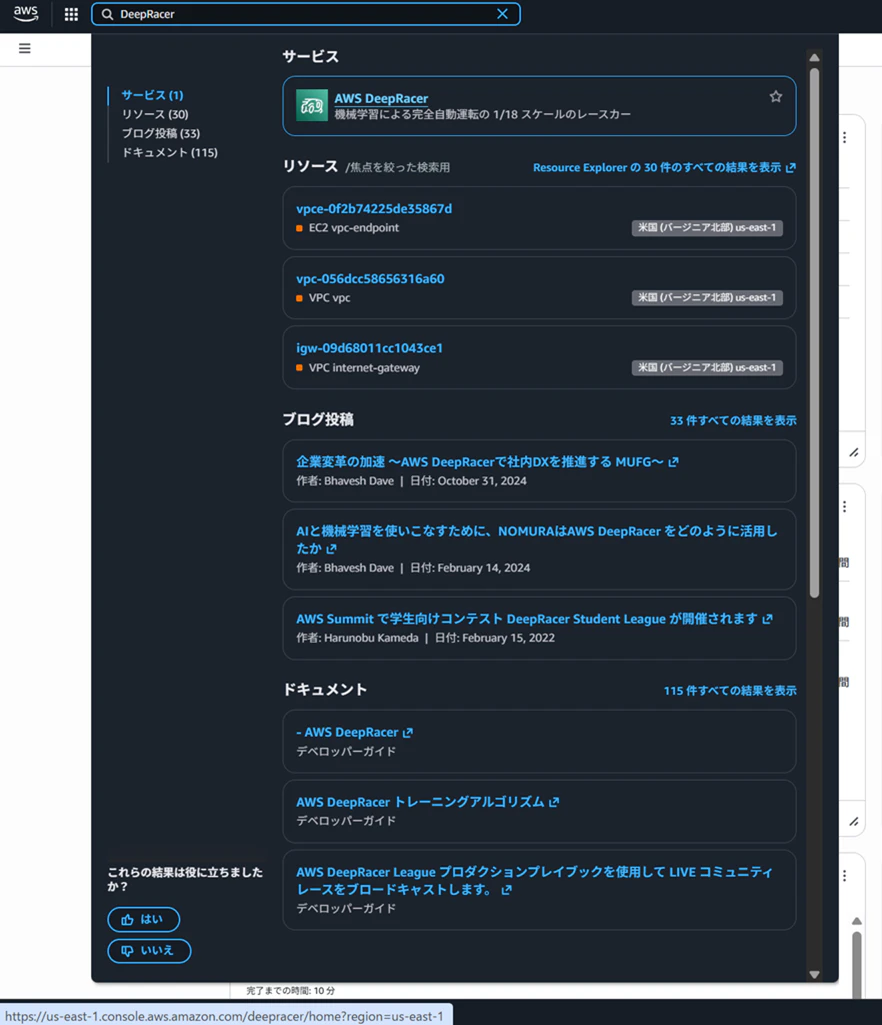
次に「Create model」ボタンを押下します。
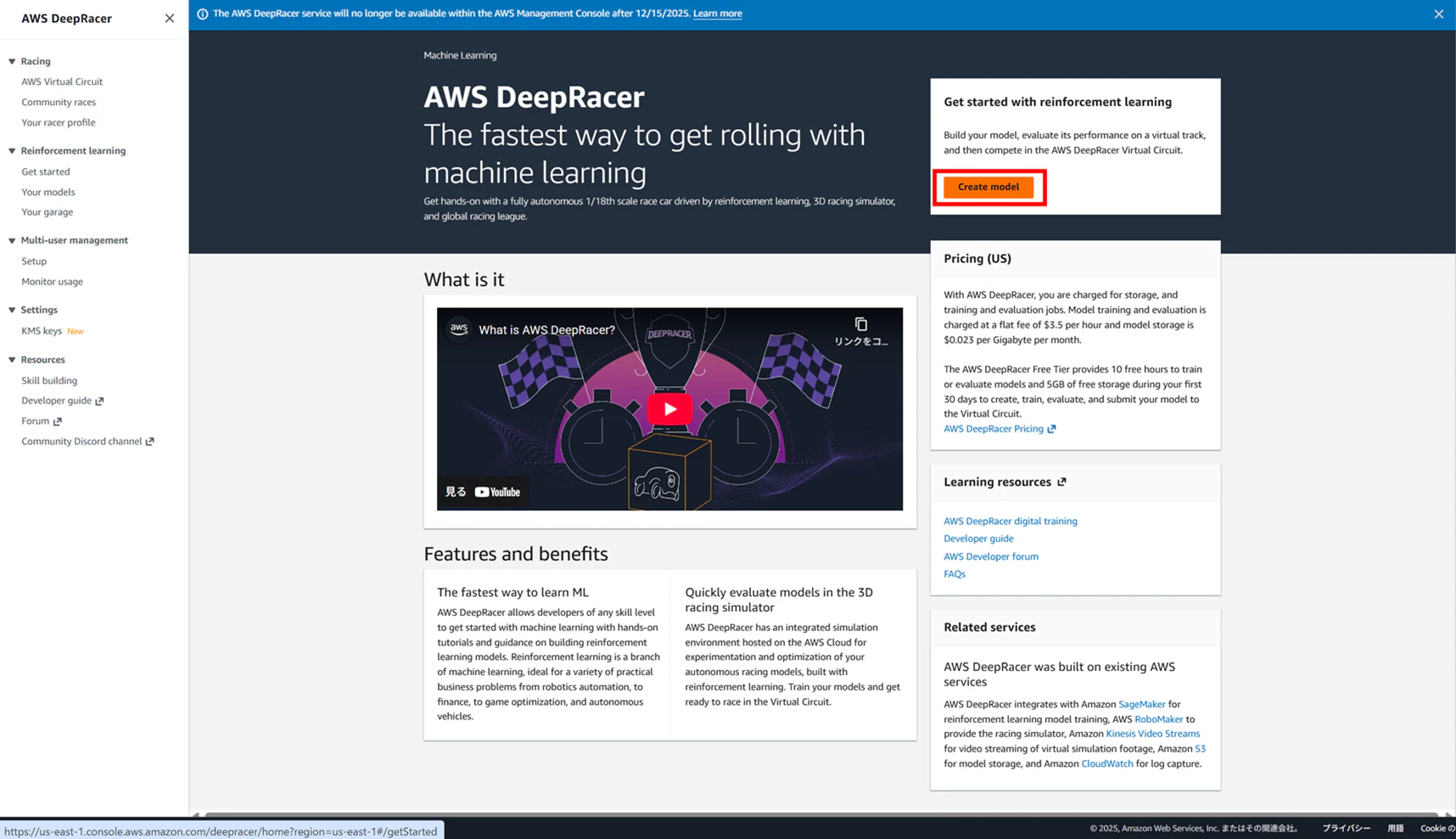
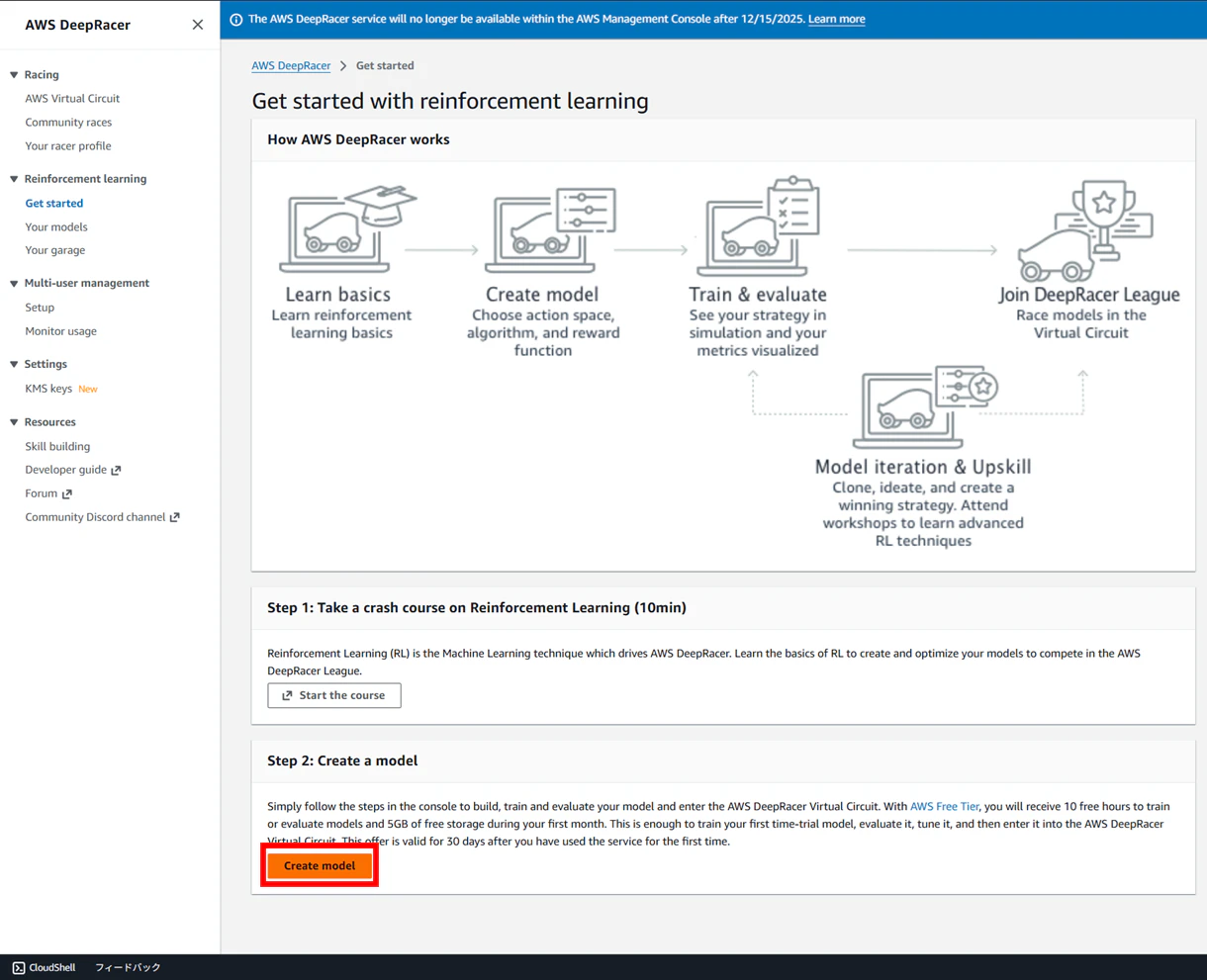
あとは画面に従って、コースやハイパーパラメータなどを選択していく形になります。この辺りの流れは次章にて説明します。
DeepRacerの学習の流れとポイント
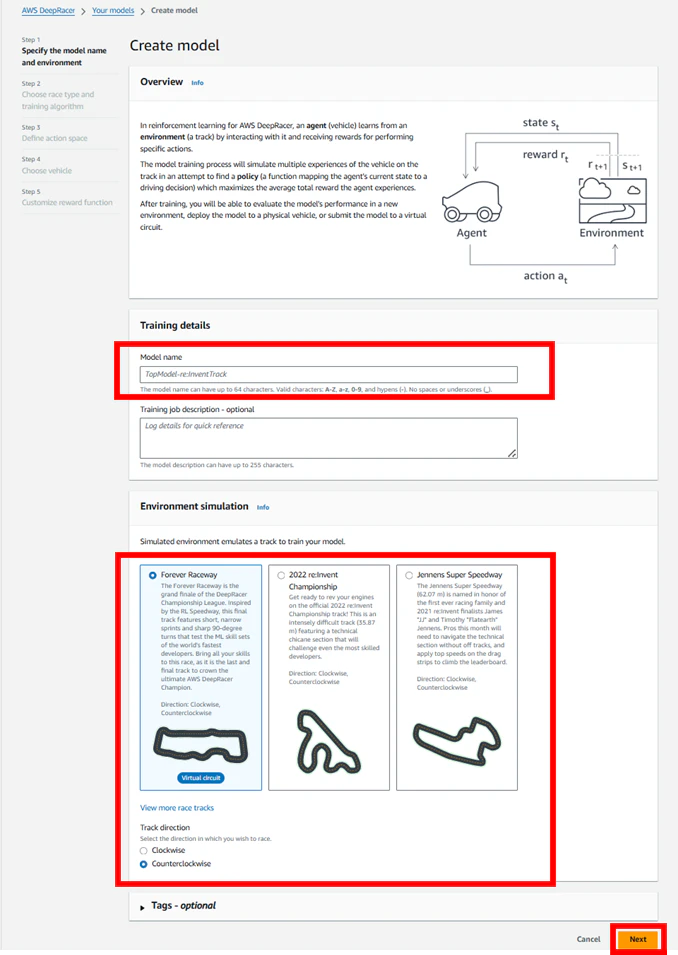
【Step1】Specify the model name and environment
最初の「Specify the model name and environment」の画面においては、モデル名の入力とコースの選択を行います。モデル名は任意でよく、コースは自身が学習したいコースを選択します。
実機のレースにおいては過学習は禁物で、汎用性を持たせる必要があるため、時計回り/反時計回りも含めて、いろいろなコースや向きで学習するのが効果的となります。
一方でバーチャルレースにおいては同じシミュレーション環境化でのレースとなるため、基本的に同じコースで学習していく形で問題ありません。
【Step2】Choose race type and training algorithm
次にレースタイプとトレーニングアルゴリズム、ハイパーパラメータを選択します。
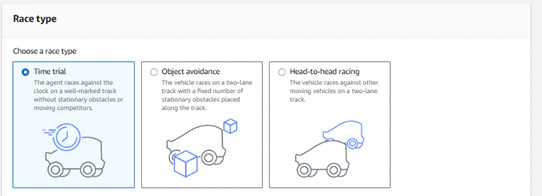
レースタイプは開催されるレースによって選択が必要ですが、通常のレースではタイムトライアルを選択します。2025年11月現在開催されているPracticeレースもタイムトライアルレースとなります。
次にトレーニングアルゴリズムを選択します。トレーニングアルゴリズムは「PPO(Proximal Policy Optimization)」と「SAC(Soft Actor-Critic)」の2つがあります。以下に簡単に特徴を説明しますが、基本的に「PPO」アルゴリズムで実施いただければと思います。
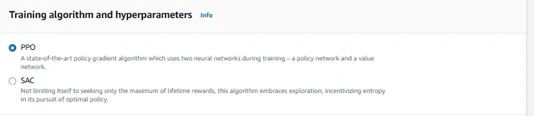
■PPO
PPOは、「オンポリシー型」の強化学習アルゴリズムで、エージェントが環境で行動し、その結果から得た報酬を基にポリシー(行動方針)を更新します。PPOは、複雑な制御タスクや自動運転のような連続的なアクションを必要とするタスクで特に効果を発揮します。
PPOは「近接ポリシー最適化」という仕組みを使って、エージェントの行動方針が一度に大きく変わらないように制御します。これにより、トレーニング中に突然エージェントが学習内容を失ったり、極端な行動を取ったりするリスクが減ります。
■SAC
SACは「オフポリシー型」の強化学習アルゴリズムで、エージェントが次の行動を選択する際に「探索(Exploration)」と「活用(Exploitation)」のバランスを考慮する特徴があります。エージェントが環境から報酬を得ながら、より良い行動方針を学習するために、柔軟で効率的な探索を行うことができます。
SACはエージェントの行動方針を最適化するだけでなく、エントロピー(ランダム性)を最大化するように設計されています。エントロピーが高いということは、エージェントがさまざまな行動を試すことを意味し、探索の幅が広がります。これにより、安定してより高い報酬が得られる可能性が増します。
次にハイパーパラメータを設定します。ハイパーパラメータとは、機械学習アルゴリズムの挙動を左右する重要な設定項目であり、モデルの性能に大きな影響を与えます。特に、DeepRacerのパフォーマンスにおいても、これらのパラメータの選定が鍵を握ります。
ただし。このハイパーパラメータが最適というものはなく、報酬関数やアクションスペースの構成、学習状況によって適切に設定する必要があります。
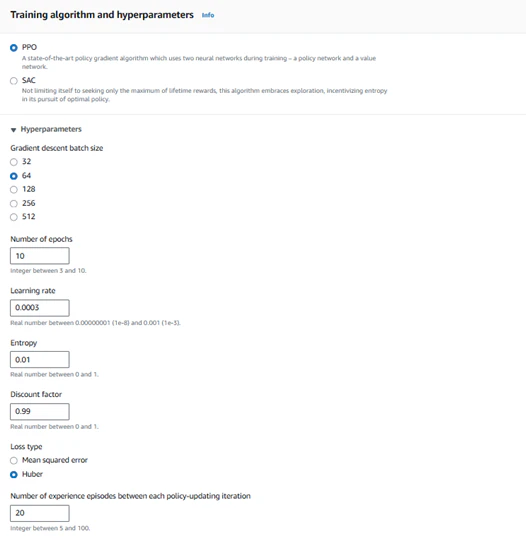
■Gradient descent batch size
Gradient descentは、学習アルゴリズムの一つであり、バッチサイズは学習フェーズにおいて、モデルのパラメータ(ここでのパラメータは、ハイパーパラメータではなくモデルの重みを指します)を更新する際に、一度にいくつの「状態」と「価値」を学習させるかを設定するものです。
バッチサイズを設定すると、経験フェーズで得られた複数のステップから、設定したバッチサイズ分のデータがランダムに抽出され、学習に使用されます。32、64、128、256、512の5つのパターンから選択可能です。
バッチサイズが大きいほど、学習は安定しやすくなりますが、その反面、学習速度が遅くなったり、トレーニングに時間がかかることがあります。
■Number of epochs
1回の学習フェーズで、パラメータの更新を何回繰り返すかを設定します。値を大きく設定すると、より安定した学習が期待されますが、その分、学習に要する時間が長くなり、速度が低下する可能性があります。
■Learning rate
学習率は、モデルの学習フェーズにおいて、パラメータの更新量を調整する重要なハイパーパラメータです。学習率が大きすぎると、更新が過剰になり「発散」と呼ばれる現象が発生し、学習が不安定になる可能性があります。逆に、学習率が小さすぎると、1回の更新による変化がわずかであるため、学習が進まず、トレーニングに非常に長い時間がかかることがあります。
■Entropy
モデルがアクションを決定する際に、どの程度のランダム性を持たせるかを設定するパラメータです。ランダム性を高く設定すると、モデルは広範囲にわたる探索が可能となり、より最適なアクションを見つけやすくなる一方で、学習に時間がかかることがあります。反対に、ランダム性を低く設定すると、学習が早期に収束する可能性が高まりますが、必ずしも最適なアクションに到達しないリスクもあります。設定可能な値は0から1までとなります。
■Discount factor
強化学習では、将来得られる報酬の総和を最大化するアクションを選択することを目的に学習を行います。その際に、どの程度先の報酬まで考慮するかを調整するパラメータが「Discount factor(割引率)」です。
例えば、Discount factorが0.9の場合、現在の報酬を割引率1として評価しますが、Nステップ先の報酬は0.9^Nの割引率で計算されます。具体的には、N=10の場合、0.9^10 ≒ 0.34となり、10ステップ先の報酬は実際の34%程度しか評価されなくなります。一方、Discount factorを0.99に設定すると、0.99^10 ≒ 0.9となり、90%の報酬が考慮されることになります。
このように、Discount factorが0.9と0.99では、後者の方が将来の報酬を重視した学習が行われることになります。ただし、Discount factorが高い場合、学習に時間がかかる可能性があるものの、より最適なモデルへ近づける可能性も高くなります。設定可能な値は0から1の値となります。
■Loss type
学習に使用する損失関数のタイプを設定できます。損失関数は、モデルの予測と実際の正解との誤差を計算するための関数であり、その選択によりモデルの収束性が異なります。
DeepRacerでは、「Huber」と「Mean squared error(MSE)」の2つの損失関数を選択できます。Huber損失関数は、発散しにくいという特性から、安定した学習が期待されます。一方、Mean squared errorは、Huberに比べて発散しやすい傾向があるものの、適切に調整すれば、より速く学習が進む可能性があります。
■Number of experience episodes between each policy-updating iteration
エージェントがポリシー(行動方針)を更新する前に、どれだけのエピソード(走行経験)を蓄積するかを決定するパラメータです。このパラメータの値によって、エージェントがポリシーを更新する頻度が変わり、学習の効率に影響を与えます。例えば10に設定すると、10回のエピソードを試行し経験を蓄積、それが学習に使用されます。
値が小さいほど、エージェントは頻繁にポリシーを更新し、より素早く新しい情報に適応する可能性があります。ただし、過度に頻繁な更新は安定性を損なうことがあり、学習が不安定になる場合があります。一方で値が大きいほどエージェントはより多くの経験を基にポリシーを更新するため、安定した学習が期待できます。しかし、更新までに時間がかかるため、学習が長時間化する可能性があります。設定可能な値は5から100までとなります。
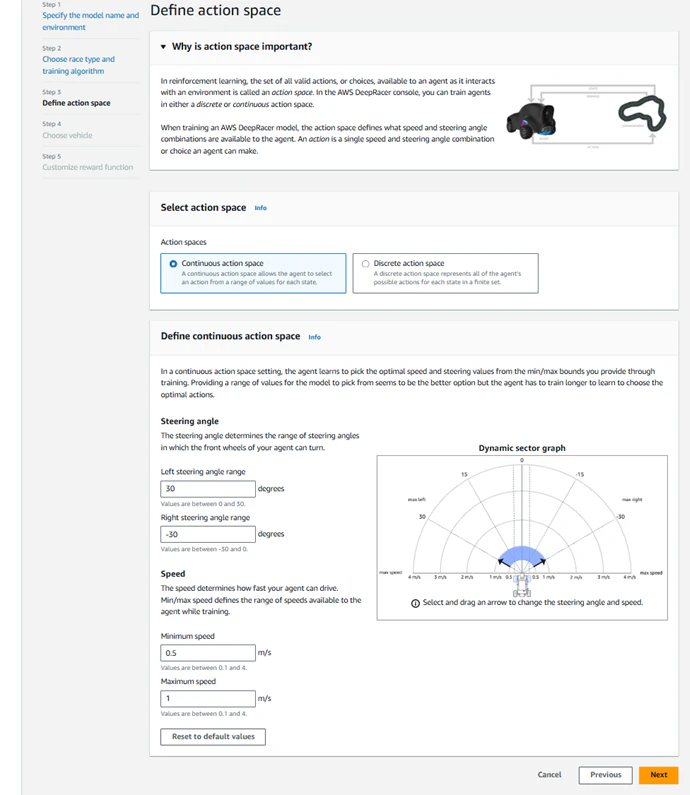
【Step3】Define action space
次にアクションスペースの設定を実施します。アクションスペースは大きく分けて「Continuous action space(連続アクションスペース)」と「Discrete action space(離散アクションスペース)」があります。
Continuous action spaceはその名の通り、アクションスペース(スピードや角度)が連続の値を取るアクションスペースとなります。
一般的にContinuous action spaceは取りうるアクション(角度、スピード)が幅広いため、Discrete action spaceに比べて収束が遅くなります。一方で最適な値を取ることができる可能性は大きくなります。Discrete action spaceは取り得るアクションが限られるため、収束は早くなります。ただし、最適なアクションスペース(スピード、ステアリング角)を設定しないと、最適な走行が出来ない可能性があります。
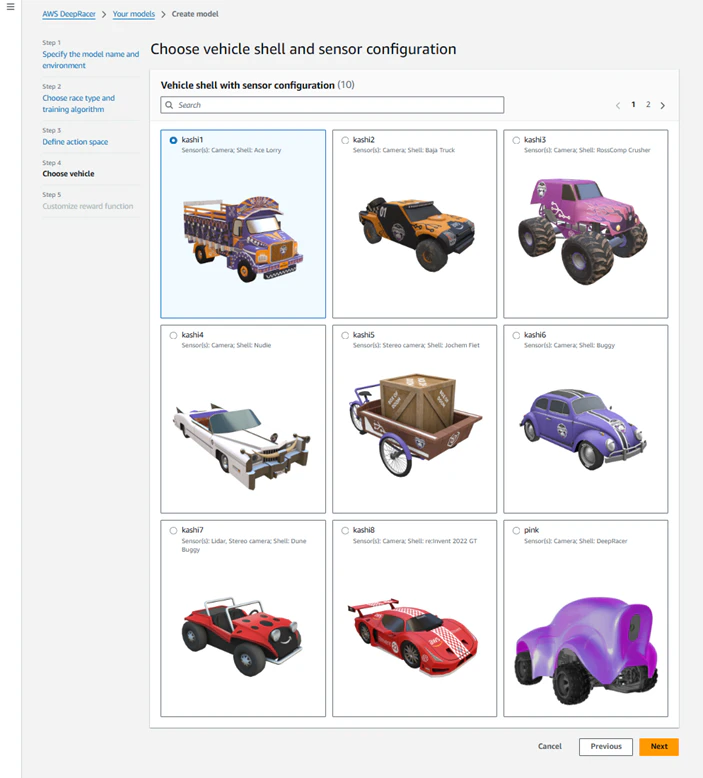
【Step4】Choose vehicle
次に車両を選択します。車両は設定によって、Camera(単眼)とStereo cameraを選択可能で、さらにLIDAR sensorをオプションとしてつけることが出来ますが、タイムトライアルレースではデフォルトのCamera(単眼)を選択すれば問題ありません。
【Step5】Customize reward function
次に報酬関数、学習時間、Virtual Circuit raceの参加有無を選択します。
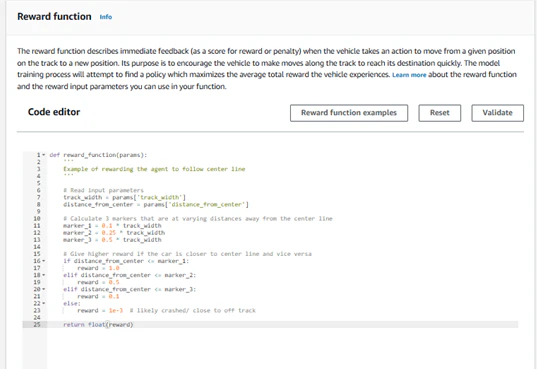
■報酬関数
入力パラメータを活用しながら報酬関数を設定します。報酬関数はいくつかサンプルが用意されているので、まずはサンプルベースで活用しながら、カスタマイズいただければと思います。サンプルの報酬関数の説明や報酬関数の部品例は書籍の中で触れておりますので、興味のある方はご覧ください。
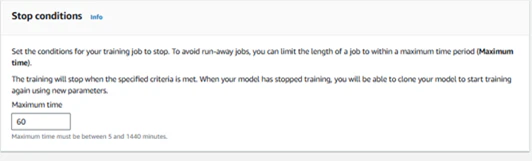
■学習時間
次に学習時間を設定します。これまで設定してきたモデルをどれくらいの時間(分)学習をさせるのかを決定します。設定可能な時間5-1440(分)となります。
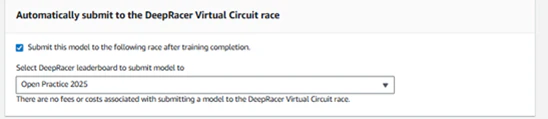
■Virtual Circuit raceの参加有無
学習後に現在開催されているレースにモデルを提出するかどうかを決定するものとなります。もし提出する場合にはチェックボックスにチェックを入れます。
以上で設定は完了で、「Create model」ボタンを押下すると学習がスタートします。ハイパーパラメータなどの説明も実施しましたが、まずはデフォルトで設定しながら学習を実施していただき、少しずつカスタマイズしていただければと思います。
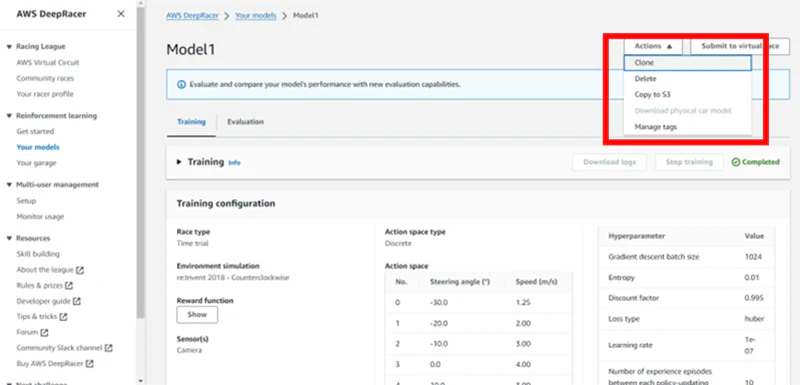
モデルの再学習(クローン)
学習したモデルを再学習(クローン)する方法も簡単に記載させていただきます。再学習の際にはトレーニングアルゴリズム、アクションスペースの種類(連続or離散)および離散アクションスペースの場合はアクションスペースの数、車両のカメラ(Camera、Stereo Camera)およびLIDAR sensorの有無は変更できないので、その点はご留意ください。もし変更したい場合は新規でモデルを構築する必要があります。
再学習させたいモデルをメニューの「Your models」から選択し、「Action」ボタンをクリックし、「Clone」リンクをクリックします。あとは通常のモデルの学習の流れと同様に設定を実施し、「Create Model」ボタンを押下すれば再学習がスタートします。
まとめ
今回のブログでは前回の「概要編」に続き、「AWSマネージメントコンソール」編をお届けしました。学習の流れやハイパーパラメータの考え方などを説明させていただきましたので、ぜひ学習の際に参考にしていただければと思います。
次のブログでは、3本立ての最後として「ローカルトレーニング編」をお届けします。興味のある方はぜひご覧いただくとともに、実際に手を動かしていただければ幸いです。
仲間募集
NTTデータ テクノロジーコンサルティング事業本部 では、以下の職種を募集しています。
1. クラウド技術を活用したデータ分析プラットフォームの開発・構築(ITアーキテクト/クラウドエンジニア)
クラウド/プラットフォーム技術の知見に基づき、DWH、BI、ETL領域におけるソリューション開発を推進します。
https://enterprise-aiiot.nttdata.com/recruitment/career_sp/cloud_engineer
2. データサイエンス領域(データサイエンティスト/データアナリスト)
データ活用/情報処理/AI/BI/統計学などの情報科学を活用し、よりデータサイエンスの観点から、データ分析プロジェクトのリーダーとしてお客様のDX/デジタルサクセスを推進します。
https://enterprise-aiiot.nttdata.com/recruitment/career_sp/datascientist
3.お客様のAI活用の成功を推進するAIサクセスマネージャー
DataRobotをはじめとしたAIソリューションやサービスを使って、
お客様のAIプロジェクトを成功させ、ビジネス価値を創出するための活動を実施し、
お客様内でのAI活用を拡大、NTTデータが提供するAIソリューションの利用継続を推進していただく人材を募集しています。
https://nttdata.jposting.net/u/job.phtml?job_code=804
4.DX/デジタルサクセスを推進するデータサイエンティスト《管理職/管理職候補》
データ分析プロジェクトのリーダとして、正確な課題の把握、適切な評価指標の設定、分析計画策定や適切な分析手法や技術の評価・選定といったデータ活用の具現化、高度化を行い分析結果の見える化・お客様の納得感醸成を行うことで、ビジネス成果・価値を出すアクションへとつなげることができるデータサイエンティスト人材を募集しています。ソリューション紹介
Trusted Data Foundationについて
~データ資産を分析活用するための環境をオールインワンで提供するソリューション~
https://enterprise-aiiot.nttdata.com/tdf/
最新のクラウド技術を採用して弊社が独自に設計したリファレンスアーキテクチャ(Datalake+DWH+AI/BI)を顧客要件に合わせてカスタマイズして提供します。
可視化、機械学習、DeepLearningなどデータ資産を分析活用するための環境がオールインワンで用意されており、これまでとは別次元の量と質のデータを用いてアジリティ高くDX推進を実現できます。
TDF-AM(Trusted Data FoundationⓇ - Analytics Managed Service)について
~データ活用基盤の段階的な拡張支援(Quick Start) と保守運用のマネジメント(Analytics Managed)をご提供することでお客様のDXを成功に導く、データ活用プラットフォームサービス~
https://enterprise-aiiot.nttdata.com/service/tdf/tdf_am
TDFⓇ-AMは、データ活用をQuickに始めることができ、データ活用の成熟度に応じて段階的に環境を拡張します。プラットフォームの保守運用はNTTデータが一括で実施し、お客様は成果創出に専念することが可能です。また、日々最新のテクノロジーをキャッチアップし、常に活用しやすい環境を提供します。なお、ご要望に応じて上流のコンサルティングフェーズからAI/BIなどのデータ活用支援に至るまで、End to Endで課題解決に向けて伴走することも可能です。
NTTデータとTableauについて
ビジュアル分析プラットフォームのTableauと2014年にパートナー契約を締結し、自社の経営ダッシュボード基盤への採用や独自のコンピテンシーセンターの設置などの取り組みを進めてきました。さらに2019年度にはSalesforceとワンストップでのサービスを提供開始するなど、積極的にビジネスを展開しています。
これまでPartner of the Year, Japanを4年連続で受賞しており、2021年にはアジア太平洋地域で最もビジネスに貢献したパートナーとして表彰されました。
また、2020年度からは、Tableauを活用したデータ活用促進のコンサルティングや導入サービスの他、AI活用やデータマネジメント整備など、お客さまの企業全体のデータ活用民主化を成功させるためのノウハウ・方法論を体系化した「デジタルサクセス」プログラムを提供開始しています。
https://enterprise-aiiot.nttdata.com/service/tableau
NTTデータとAlteryxについて
Alteryx導入の豊富な実績を持つNTTデータは、最高位にあたるAlteryx Premiumパートナーとしてお客さまをご支援します。
導入時のプロフェッショナル支援など独自メニューを整備し、特定の業種によらない多くのお客さまに、Alteryxを活用したサービスの強化・拡充を提供します。
NTTデータとDataRobotについて
NTTデータはDataRobot社と戦略的資本業務提携を行い、経験豊富なデータサイエンティストがAI・データ活用を起点にお客様のビジネスにおける価値創出をご支援します。
NTTデータとInformaticaについて
データ連携や処理方式を専門領域として10年以上取り組んできたプロ集団であるNTTデータは、データマネジメント領域でグローバルでの高い評価を得ているInformatica社とパートナーシップを結び、サービス強化を推進しています。
https://enterprise-aiiot.nttdata.com/service/informatica
NTTデータとSnowflakeについて
NTTデータではこれまでも、独自ノウハウに基づき、ビッグデータ・AIなど領域に係る市場競争力のあるさまざまなソリューションパートナーとともにエコシステムを形成し、お客さまのビジネス変革を導いてきました。
Snowflakeは、これら先端テクノロジーとのエコシステムの形成に強みがあり、NTTデータはこれらを組み合わせることでお客さまに最適なインテグレーションをご提供いたします。