
システムの可用性を高めるためにクラスタリング技術はよく使われます。
そのクラスタリングの推奨ノード数が3つ以上のソフトウェアは非常に多いのですが、その理由まではあまり詳しく書かれていません。
今回は、クラスタメンバー同士がお互いの状態を確認しながらクラスタを構成する The Raft consensus Algorithm のようなアルゴリズムを想定して、なぜ「3」なのか?また、クラスタを構築するときに気を付けるべきポイントをまとめてみたいと思います。
書いた切っ掛けは、Google Cloud Platform 東京リージョンが最初から3つのゾーンでリリースしたのを見たことでした。「クラスタ構成を考慮して最初から 3 つ用意したのかな ![]() 」と勝手な推測しています。
」と勝手な推測しています。 ![]()
例えば 3 を要求するもの
3ノード以上を推奨するソフトウェアなどをリストしてみます。
※ 直訳は参考程度に読んで下さい ![]()
Redis
Note that the minimal cluster that works as expected requires to contain at least three master nodes. For your first tests it is strongly suggested to start a six nodes cluster with three masters and three slaves.
(直訳)
期待した通りに動作する最小なクラスタには少なくとも3つのマスターノードが必要になることに気をつけてください。最初のテストには、3つのマスターノードと3つのスレーブを含めて合計6ノードで始めることを強く推奨します。
MariaDB Galera Cluster
Minimal cluster size
In order to avoid a split-brain condition, the minimum recommended number of nodes in a cluster is 3. Blocking state transfer is yet another reason to require a minimum of 3 nodes in order to enjoy service availability in case one of the members fails and needs to be restarted. While two of the members will be engaged in state transfer, the remaining member(s) will be able to keep on serving client requests.
(直訳)
最小クラスタサイズ
スプリットブレインの状態を回避するために、推奨される最小クラスタノード数は 3 です。ブロッキングステート転送は、メンバーの1つがダウンしたり再起動が必要な状況においてサービス継続ができるために最低3ノードを必要とするもうひとつの理由です。2つのメンバーがステート転送をしている間も残りのメンバーはクライアントからのリクエストを処理しつづけます。
etcd
Optimal Cluster Size
The recommended etcd cluster size is 3, 5 or 7, which is decided by the fault tolerance requirement. A 7-member cluster can provide enough fault tolerance in most cases. While larger cluster provides better fault tolerance the write performance reduces since data needs to be replicated to more machines.
(直訳)
最適なクラスタサイズ
推奨される etcd のクラスタサイズはフォルトトレランスの観点からみて、3 か 5、もしくは 7 になります。7メンバークラスタは殆どの場合に十分なフォルトトレランスを実現できます。より大きいクラスタサイズはフォルトトレランスに優れていますが、沢山のマシーンにデータを複製する必要があるので書き込み性能が落ちてしまいます。
Consul
We recommend 3 or 5 total servers per datacenter. A single server deployment is highly discouraged as data loss is inevitable in a failure scenario.
(直訳)
データセンター毎に 3 台もしくは 5 台のサーバーを推奨しています。単一構成では障害時のデータ損失を避けれないのでやめるべきです。
Influxdb
InfluxDB cluster model
InfluxDB supports arbitrarily sized clusters and any replication factor from 1 to the number of nodes in the cluster.
There are three types of nodes in an InfluxDB cluster: consensus nodes, data nodes, and hybrid nodes. A cluster must have an odd number of nodes running the consensus service to form a Raft consensus group and remain in a healthy state.
(直訳)
InfluxDB クラスタモデル
InfluxDBは任意のサイズのクラスタとリプリケーションファクタをサポートします。(中略・・)Raftコンセンサスを形成して健全な状態を維持するためには、そのコンセンサスサービスのメンバーは奇数でなければなりません。
などなど。
3 を推奨ノード数とする記述がやはりありますね。フォルトトレランス とか スプリッドブレイン とかの単語も出てきています。また、InfluxDBでは 3 を明言せずに奇数を必須としていますね。
クラスタとしては何を考慮するのか

分散システムにおいて CAP 定理というものがあり、以下の3つの頭文字を取ったものになっています。
- Consistency (一貫性)
- Availability (可用性)
- Partition Tolerance (分割耐性)
「Consistency (一貫性)」は、データの「正」をどれにするかを決めるものです(後述します)。
「Availability(可能性)」については、サービスを止めないで継続することです。先ほど出てきた フォルトトレランス は可用性を提供するうえで、どのノード数までダウンを許容する・考慮するかを定義するものになります。
最後に、「Partition Tolerance (分割耐性)」は、ある複数ノードで構成されるクラスタがネットワークなどで分断されてしまった場合の耐性に関するものです。スプリッドブレイン はこの分断が発生した状態を言います(頭脳が2つ以上に分かれてしまった状態と理解すると良いと思います)。ここで大切なのは分断されてしまったときでもサービスを継続したいので、分断されたものの中からどれを生かすかを判断をしなければなりません。判断する場合には多数決(マジョリティ)を使うことが多く、そのためには 3 ノード以上居ないと成り立たないことなります。これが 3 つ必要な大きな理由となります。
次は、クラスタが分断されたときにどんな動きをするのか図を交えて説明したいと思います。
分断の図解
3ノードクラスタの場合
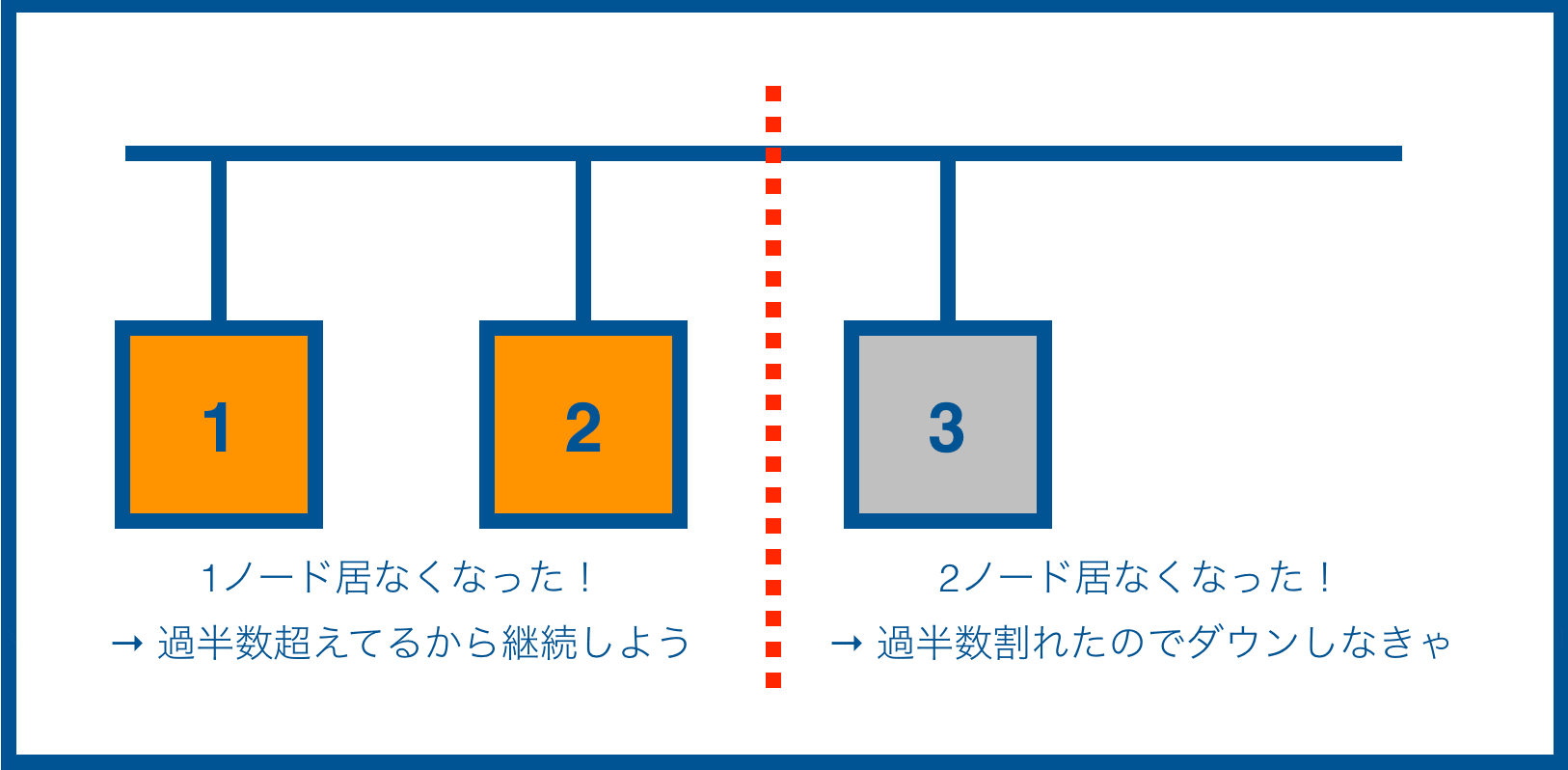
※ 赤点線 = 分断された箇所
ノード1、2側からするとノード3が居なくなりましたが、過半数を維持しているので稼働を継続します。一方でノード3側は、過半数を割れたので自分自身で稼働を停止させることになります。停止しなければならない理由は後述します。
4ノードクラスタの場合
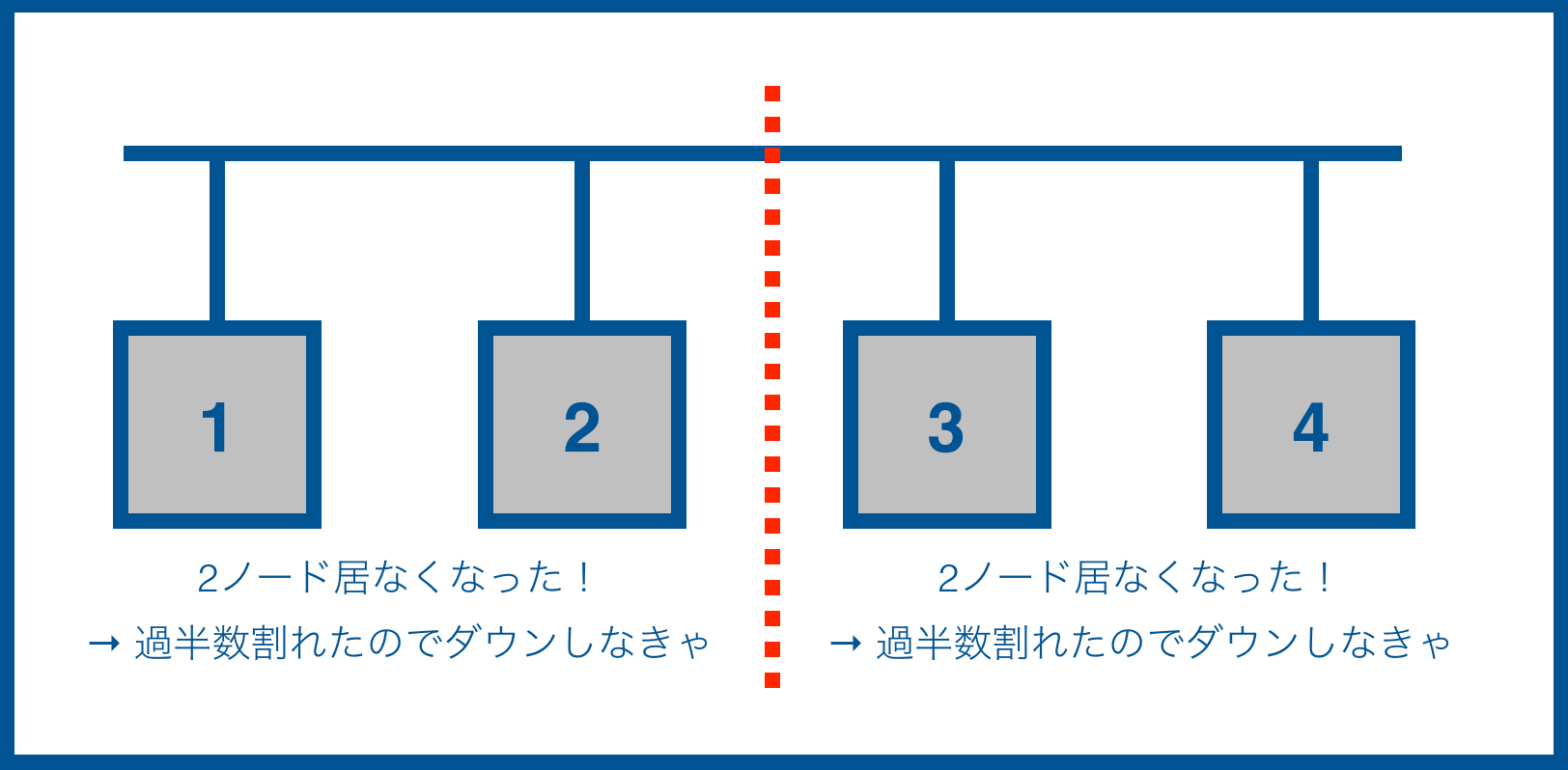
※ 赤点線 = 分断された箇所
この場合、全断になってしまいます。 ![]()
4ノードクラスタの場合は、過半数は3なのでそれを維持したほうが稼働を継続します。上図の場合、どちらも過半数が割れてしまい全てのノードが稼働を停止せざる得なくなります。
この状態が発生する可能性があれば、この4ノード構成は(障害時にも処理を継続したいはずなので)設計ミスであるということになります。処理性能に問題がなければ3ノードクラスタに、処理性能が足りなければ5ノードに変更することを考えなければなりません(ただし、ノード数を増やすとデータ複製などのオーバーヘッドが大きくなり必ずしも性能が増えないので注意が必要です)。
ノード数とマジョリティ、フォルトトレランスの相関
クラスタノード数を考える時、以下の表に沿って考えると良いです。色々なところで使われている表です。
| ノード数 | マジョリティ | フォルトトレランス数 |
|---|---|---|
| 1 | 1 | 0 |
| 2 | 2 | 0 |
| 3 | 2 | 1 |
| 4 | 3 | 1 |
| 5 | 3 | 2 |
| 6 | 4 | 2 |
以下で表すことができますね。
フォルトトレランス数 = ノード数 - マジョリティ
前にも説明しましたが、マジョリティは過半数のことで、フォルトトレランスは障害を許容できるノード数です。
単純にノード数を増やしても耐障害性(フォルトトレランス数)は上がりません。例えば、4ノードクラスタの図で示した分断が発生すると、逆に3ノードクラスタよりも耐障害性が弱くなる場合があるので注意しなければなりません。
奇数にしておくことがお薦めです。 ![]()
なぜ過半数割れをすると停止するのか
「Consistency (一貫性)」を維持するためになります。
クラスタが分断されたときに、分断された両方のノードへクライアントからの書き込みリクエストが到達してしまう可能性があります。そのまま処理を継続してしまうと書き込まれたデータのどちらが正しいかを判断する事が難しくなります。そのため少ないノード数の方をダウンさせることでデータの一貫性(Consistency)を保つために停止することにしています。可用性よりデータの方が大切ですからね。
ロケーションも意識する
クラスタを扱うOSSなどのノード配置を設計する場合には、ロケーションも意識しなければなりません。
例えば、3ノードクラスタをクラウド(IaaS)上の2つのゾーンに配置すると、1ゾーンに2ノード存在することになります。運悪く、2ノードが配置されたゾーン全体がダウンすると、そのクラスタは機能できなくなります。配置するインフラで発生しうる障害を想定して、もっとも安全な配置(設計)を考える必要があります。
冒頭で記載した Google Cloud Platform 東京リージョンが最初から3ゾーンで提供開始したのは、この設計を厳密に実現させるための仕様と勝手に理解しています。 ![]()
余談
過半数を考慮しないクラスタも世の中に存在します。
例えば、KVS として Apache Cassandra や Basho Riak 、AeroSpike があります。これらは Amazon が 2007 年に発表した Dynamo をベースに開発されており、 Vector Clock や Consistent Hashing などの技術でデータ一貫性や耐障害性の高いクラスタリングを実現しています。
Riak で実際にネットワーク分断させた状態でデータを書き込みをしたことがありますが、分断中もそのまま処理を継続できていました。また、分断が回復した後でも自動でデータの再配置と修復を行い、何事も無かったように正常な状態に戻るのをみたとき感動しました。 ![]()
まとめ
- クラスタを考えるときは奇数ノード(3以上)を意識
- 単純に+1して偶数にしないこと
- 過半数割れが発生する時を考える
- ロケーションも意識することでより強固に
全てのクラスタリグ技術に当てはまらないのでご注意ください。
それでは良いクラスタライフを ![]()