公式ページ
公式ページによるとApache Stormは'distributed realtime computation system',分散リアルタイム計算システム。記事の執筆時点(2017年2月)でv1.0.3が最新バージョン。以下,基本的に公式ページの内容に沿って書いていく。
Rationale
MapReduceやHadoopなどの違いはリアルタイム処理が可能なこと。(以前はバッチ処理のみ)
特徴は次の通り。
- 幅広いユースケース
- スケーラブル。スケールさせるためにはマシンを増やすだけ。
- データロスがない。
- 堅牢性
- Fault-tolerant (耐障害性)
- Programming language agnostic (プログラム言語非依存)
コンセプト
- トポロジー
- ストリーム
- スパウト (spout)
- ボルト (bolt)
- ストリームグループ
- 信頼性 (Reliability)
- タスク
- ワーカー (Workers)
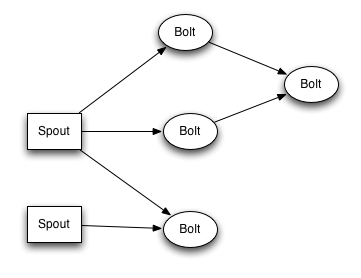
トポロジー
トポロジーはスパウトとボルトのつながりのこと。
ストリーム
Streams are defined with a schema that names the fields in the stream's tuples.
デフォルトで次の型がある。
integers, longs, shorts, bytes, strings, doubles, floats, booleans, and byte arrays.
スパウト
スパウトはトポロジーにおいてストリームの源。(Spoutは水などの噴出しのこと)
スパウトには reliable か unreliableがある. reliable spoutは処理に失敗したら再送機能がある。 whereas an unreliable spout forgets about the tuple as soon as it is emitted.
ボルト
すべての計算はボルトの中で行われる
例えば,filtering, functions, aggregations, joins, talking to databases,
複雑なトポロジーではボルトは複数段になってもかまわない。
ボルトは複数のストリームに出力してもかまわない。declareStream method を使って複数のストリームを定義することができる。
ストリームグループ
ストリームグループはストリームがタスクの間でどのように分割されるのか?を定義する)
」
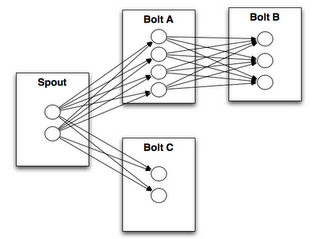
8種類のストリームグループが存在する。
- Shuffle grouping : タプルがランダムにタスクに分配される。
- Fields grouping
- Partial Key grouping
- All grouping : ストリームがすべてのタスクに複製される。注意して使うこと。
- Global grouping
- None grouping : 現時点ではShuffle groupingと同じ。
- Direct grouping
- Local or shuffle grouping
信頼性
Storm guarantees that every spout tuple will be fully processed by the topology. (すべてのスパウトはトポロジーにより完全に処理される)
Every topology has a "message timeout" associated with it. If Storm fails to detect that a spout tuple has been completed within that timeout, then it fails the tuple and replays it later.(すべてのトポロジーはタイムアウト時間がある。Stormがタイムアウトを検出すると,後に再送する)
タスク
Each spout or bolt executes as many tasks across the cluster.
ワーカー
Each worker process is a physical JVM and executes a subset of all the tasks for the topology.
API
http://<ui-host>:<ui-port>/api/v1/...
Trident
Trident is a high-level abstraction for doing realtime computing on top of Storm.
Storm のコントローラー?ラッパーみたいなもの?Javaプログラム。
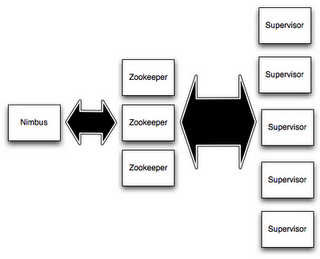
セットアップ
- Set up a Zookeeper cluster
- Install dependencies on Nimbus and worker machines
- Download and extract a Storm release to Nimbus and worker machines
- Fill in mandatory configurations into storm.yaml
- Launch daemons under supervision using "storm" script and a supervisor of your choice
ZooKeeper
StormではZooKeeperはクラスタの調整のみに使用される。メッセージ処理には利用されない。
Nimbusとworkerマシンの前提をインストール
Java7 and Python 2.6.6
(これ以外のバージョンでは動くかもしれないし,動かないかもしれない。。。)
Stormのダウンロード・解凍
ここからダウンロード
https://github.com/apache/storm/releases
storm.yamlファイルの編集
設定ファイルはconf/storm.yaml
設定項目は,
1 storm.zookeeper.servers (zookeeperサーバーのIP),storm.zookeeper.port(同じくポート番号)
storm.zookeeper.servers:
- "111.222.333.444"
- "555.666.777.888"
2 storm.local.dir (デーモンが使う場所)
storm.local.dir: "/mnt/storm"
3 nimbus.seeds : The worker nodes need to know which machines are the candidate of master in order to download topology jars and confs.
nimbus.seeds: ["111.222.333.44"]
4 supervisor.slots.ports (workerが使うポート)
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
起動
最後のステップはデーモンの起動。Stormは状態を持たないので,いつでも安全に停止できる。
デーモンの起動方法
- Nimbus : "bin/storm nimbus" under supervision on the master machine.
- Supervisor : "bin/storm supervisor" under supervision on each worker machine
- UI : "bin/storm ui" under supervision. http://{ui host}:8080.