はじめに
GMOコネクトの永田です。
AWS上でWebサービスを開発したいんだけどどんな構成が良い?と聞かれることがそれなりにあり、毎回同じようなことを話していましたので、まとめてみます。
前提: Public公開するWebサービス。データはRDSへ格納する。
まとめ
- (1) 海外アクセスの考慮
- (2) 大規模障害(Region障害)の考慮
- (3) AZ障害の考慮
- (4) 計画停止の有無
各考慮事項の詳細
1. 海外アクセスの考慮
海外アクセスの有無や、アクセスに対する要求によって、構成がだいぶ変わります。
| 海外アクセス有無 | 海外レスポンス時間の最適化 | 構成(案) | コスト |
|---|---|---|---|
| 海外アクセス有り | 静的コンテンツ+動的コンテンツともあり。動的コンテンツは全Regionで一意。 | Aurora Global Database + MultiRegion 参考: https://aws.amazon.com/jp/blogs/database/use-amazon-aurora-global-database-to-build-resilient-multi-region-applications/ |
SingleRegionのコスト x Region数 |
| 海外アクセス有り | 静的コンテンツ+動的コンテンツともあり。動的コンテンツは各Regionで別 | SingleRegion構成を各Regionに別々に構築(ドメインも別) | SingleRegionのコスト x Region数 |
| 海外アクセス有り | 静的コンテンツのみ最適化 | Single Region構成を1Regionに構築。静的コンテンツはCloudFrontで各RegionのEdgeでキャッシュ | SingleRegionのコスト |
| 海外アクセスなし(考慮不要) | 考慮不要 | Single Region構成を1Regionに構築。静的コンテンツはCloudFrontでも良い。 | SingleRegionのコスト |
過去の事例だと「海外アクセスなし(考慮不要)」のパターンが多かったです。まずはスモールに始めるという考え方です。
2. 大規模障害(Region障害)の考慮
次に、大規模障害(Region障害、TokyoならTokyo Regionの3AZが全滅)が発生したときの考え方になります。
DR(Disaster Recovery)戦略とか、BCP(Business Continuity Plan)対策とも呼ばれます。
DR戦略の考え方はAWS Blogで解説があるとおり4種類あり、それにより障害発生時の目標復旧時間(Recovery Time Objective、)・目標復旧時点(Recovery Point Objective、障害時にどこまでデータが巻き戻るか)と、コストへのトレードオフとなります。

| DR戦略 | RTO(目標復旧時間) | RPO(目標復旧時点) | インフラコスト(直感) | 構成(案) |
|---|---|---|---|---|
| Backup & Restore | 数時間〜数日 | 1日前(日次Backupの場合) | SingleRegionコスト | TokyoでSingleRegion構成+OsakaへリモートBackup |
| Pilot Light | 1時間〜数時間 | 数秒 | SignleRegionコストx1.3倍ぐらい | TokyoでSingleRegion構成+OsakaのDBへリアルタイムレプリケーション |
| Warm standby | 数十分〜1時間 | 数秒 | SignleRegionコストx1.5倍ぐらい | Tokyo/OsakaのMultiRegion構成。Osakaは縮退構成 |
| Multi-site active/active | 数分 | 数秒 | SignleRegionコストx2倍ぐらい | Tokyo/OsakaのMultiRegion構成。Osakaもフル構成 |
過去の事例だと「Backup & Restore」のパターンが多かったです。
まずはスモールに始めるというのもありますし、本当の大規模障害でTokyoRegion(AZ3すべて)が壊滅するパターンだと、クラウドの対応だけではなくて運用も考慮が必要(Tokyo拠点だけではなくOsaka拠点とか遠隔地でも運用保守部隊を維持とか)で、そこまではtoo muchという案件が多かったです。
3. AZ障害の考慮
次にAZ障害(Availability Zone、概ねデータセンター)の考慮をします。
AZ障害ですが、数年に1回ぐらいAZレベルの大規模障害は発生しており、考慮は必要になります。
2025年のAZ障害
2021年のAZ障害
2019年のAZ障害
MultiAZなWebサービスの構成案
ここでは、Webサービスの一般的な構成として、ロードバランサー(ALB) + Web/APIサーバー(ECS on Fargate)+ データベース(Aurora)を前提に考えてみます。
といっても、ECSのインスタンスがステートレスになっている前提であれば、検討の対象はデータベースのAuroraのみとなります。
そこでMultiAZなAuroraの構成を検討するのですが、一つ上のMultiRegionの考慮で検討したRTO(目標復旧時間) RPO(目標復旧時点)とインフラコストとのトレードオフと、同じような検討となります。
| MultiAZ方針 | RTO(目標復旧時間) | RPO(目標復旧時点) | インフラコスト(直感) |
|---|---|---|---|
| Writerのみ(SingleInstance) | 10分未満 AZ障害は手動復旧が必要なので復旧までの時間はかなり伸びる (※2) |
0秒(※1) | SingleInstanceコスト |
| Writer+ReadReplica | 30秒〜60秒(※3) | 0秒(※1) | SingleInstanceコストx2倍 |
| Writer+ReadReplica +RDSProxy | 3秒(※4) | 0秒(※1) | SingleInstanceコストx2.5倍ぐらい |
(※1)Auroraの耐障害性
具体的な値は公開されていないものの、以下の「Amazon Aurora アーキテクチャ概要」に記載されている通り、1インスタンス構成であってもデータ自体は3AZの6ノードに記録されます。そのため非常に高い耐障害性を備えています。
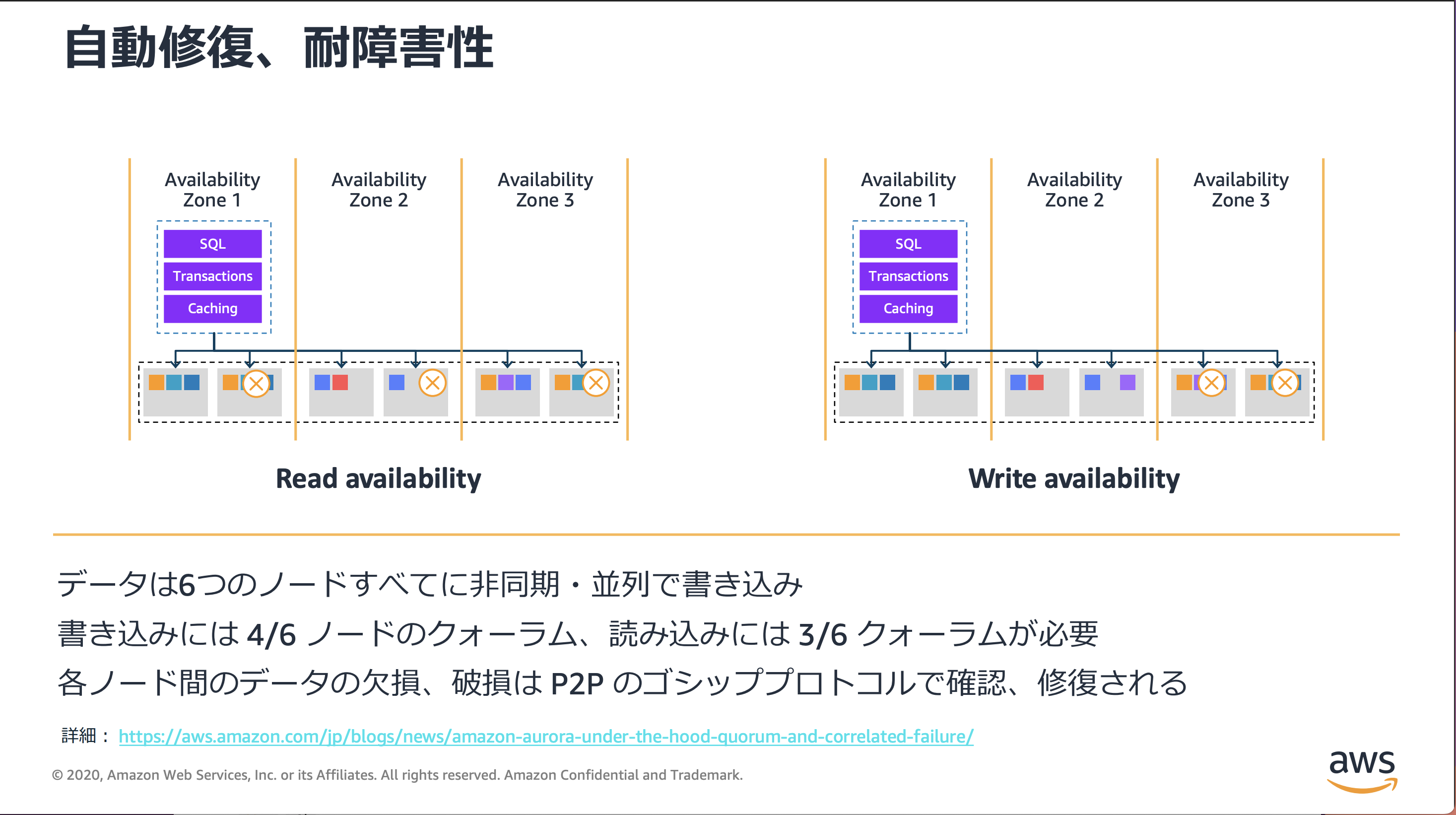
(※2)Aurora Writerのみ(SingleInstance)の障害時復旧時間
DB クラスターに Aurora レプリカが含まれていない場合、障害イベントの発生時にプライマリインスタンスが同じ AZ に再作成されます。障害イベントによって中断が発生し、その間例外によって読み取りと書き込みオペレーションが失敗します。新しいプライマリインスタンスが再作成されると、サービスが回復します。これは、通常は 10 分未満で行われます。
プロビジョン済みまたは Aurora Serverless v2 クラスターに 1 つの DB インスタンスしか含まれていない場合、またはプライマリインスタンスとすべてのリーダーインスタンスが同じ AZ にある場合は、別の AZ に 1 つまたは複数の新しい DB インスタンスを手動で作成する必要があります。
- DBインスタンス障害時は、10分未満で自動復旧
- writerのみでAZ障害時は、手動でDBインスタンスを作成する必要あり
(※3) Aurora Writer+ReadReplica構成の障害時復旧時間
DB クラスターに 1 つ以上の Aurora レプリカがある場合は、障害発生中に 1 つの Aurora レプリカがプライマリインスタンスに昇格されます。障害イベントによって短い中断が発生し、その間例外によって読み取りと書き込みオペレーションが失敗します。ただし、サービスの一般的な復元時間は 60 秒未満であり、多くの場合 30 秒未満です。
- Writer+ReadReplicaで別AZにインスタンス構築時、30秒〜60秒ほどで自動復旧
- インスタンス障害、AZ障害とも自動復旧可能
(※4) RDSProxy導入時の障害時復旧時間
MariaDB ドライバーを使用してデータベースに直接接続する場合は 24 秒がかかりますが、RDS Proxy での平均フェイルオーバー時間は 3.1 秒でした。87% 改善された結果です。
- RDSProxyがある場合、3秒程度でfailoverが完了する
MultiAZ以上の構成とする場合、コストも2倍以上となる(ランニングコストの大部分がDBのことが多い)ため、MultiAZとするかは悩むところですが、AZ障害発生頻度と発生時の復旧手順や時間とのトレードオフとなりそうですね。
4. 計画停止の有無
多くのシステムが「計画停止あり」と、事前に計画していればサービス停止を許容することが多いかと思いますが、念の為この要件は最初に確認しておきたいです。
ただごく稀に計画停止が原則なしで無停止(ダウンタイムなし)で運用したいと無茶をいう案件もあったりします。
といってもRDB(Aurora)を採用している限りダウンタイムが発生するイベントはあるので、顧客をがんばって説得するか、いっそのことRDBをあきらめてDynamoDBとかにする、などとなります。
以下Blogに、AuroraでMultiAZ構成にしていてもダウンタイムが発生するパターンがまとめられています。
(再掲)まとめ
- (1) 海外アクセスの考慮
- (2) 大規模障害(Region障害)の考慮
- (3) AZ障害の考慮
- (4) 計画停止の有無
ここまでで、アーキテクチャ上に大きく影響する非機能要件が整理されました。これでアーキテクチャ面では大きな手戻りが少なくなるかもしれないですね!
弊社では、AWSを使ったサービスの開発や技術支援をはじめ、幅広い支援を行っておりますので、何かありましたらお気軽にお問合せください。