このBlogにある通り、従来のWatson Discovery V1 が非推奨となったため、Watson Discovery のデータをV1からV2に移行してみました。
移行概要
以下のような移行をしてみました。
赤字で記載している箇所はDiscovery V1とV2で異なる点や注意が必要な箇所です。詳細は各手順の中で補足します。
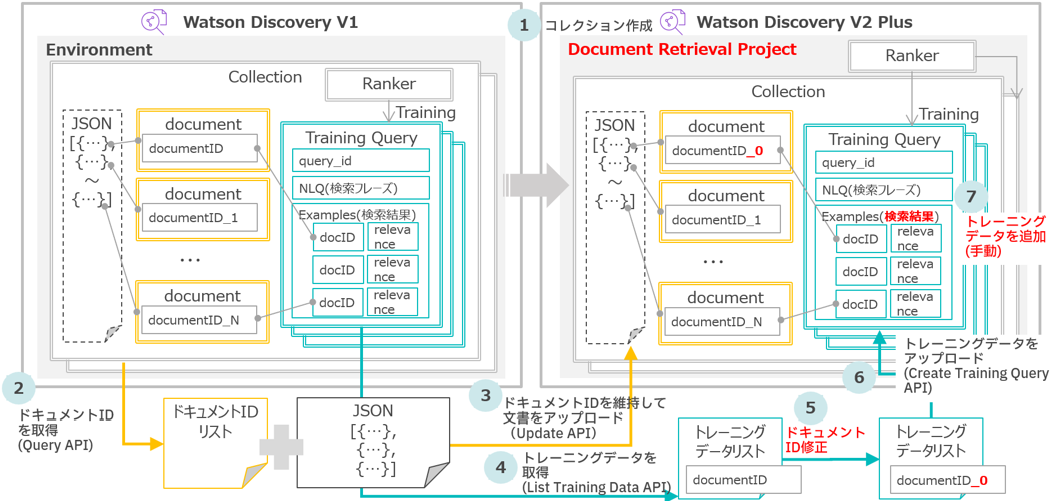
移行対象
検索対象の文書はJSON形式で配列でデータが入っている1ファイルです。
Discovery V1ではこのファイルをDiscovery V1の画面から直接アップロードしました。
関連性トレーニングもDiscovery V1で実施しています。
移行対象は、検索対象の文書データと関連性トレーニングデータです。
作業ステップ
基本的にはマニュアル Migration to Discovery v2 に記載されている手順に従って移行しました。
移行の作業ステップは以下の通りです。
- Discovery V2 に空のコレクションを作る
- Discovery V1の全てのドキュメントIDを取得する
- ドキュメントIDを維持した状態で Discovery V2 に文書をアップロードする
- Discovery V1の関連性トレーニングデータを取得する
- 取得したトレーニングデータのドキュメントIDを修正する
- Discovery V2にトレーニングデータをアップロードする
- トレーニングデータが足りない場合、Discovery V2にトレーニングデータを手動で追加する
移行作業
1. Discovery V2 に空のコレクションを作る
プロジェクトと空のコレクションを作成します。
- Document Retrievalタイプのプロジェクトを作成

- APIで手動で文書をアップロードするので、Upload dataを選択

- コレクション名と言語を指定

- この画面まで進んだら、左のフォルダーマーク(Manage collections)をクリック

- 空のコレクション完成

Discovery V1 では、Environmentに対して複数のコレクションを作りますが、Discovery V2 では、プロジェクトという概念が登場し、プロジェクトの中にコレクションを作ります。
2. Discovery V1の全てのドキュメントIDを取得する
今回は、関連性トレーニングもDiscovery V1からV2に移行するため、同じトレーニングデータが使えるように、Discovery V1とV2でドキュメントIDを合わせる必要があります。
コレクションに投入されている移行対象の文書データのドキュメントIDを全て取得します。
Discovery V1 の Query API を使って全データを取得します。
ここで紹介するコードは Watson Developer Cloud Python SDK を使用しています
query_result = discovery.query(
environment_id,
collection_id,
query='',
count=300
).get_result()
| パラメータ | 解説 |
|---|---|
| environment_id | Discovery V1 の Environment ID |
| collection_id | Discovery V1 の コレクションID |
| query | 全文書を検索するため空白とする |
| count | 取得する文書数 今回は全部で250文書存在するため250以上の数字を指定 |
Query APIの結果から、ドキュメントIDを取得します。
for data in query_result['results']:
doc_id = data['id']
今回は1つのJSONファイルに配列でデータが入っているものを使用しており、Discovery へのファイルアップロード時にデータが自動的に分割され、以下のようにドキュメントIDが割り振られていました。
b8f94e8f843d7a5afbb19a632e43ba87_22
b8f94e8f843d7a5afbb19a632e43ba87_17
b8f94e8f843d7a5afbb19a632e43ba87_23
b8f94e8f843d7a5afbb19a632e43ba87_18
b8f94e8f843d7a5afbb19a632e43ba87_14
Discovery V1では特にドキュメントIDを指定してアップロードしなかったため、ランダムに割り振られたIDに続いて _xx と番号が割り振られたようです。
マニュアルには最初の1万文書のみ移行する方法が記載されていますが、1万文書以上のデータを取得する場合は以下をご参照ください。
How to enumerate id‘s of documents in watson discovery service
3. ドキュメントIDを維持した状態で Discovery V2 に文書をアップロードする
Discovery V1にアップロードしたJSONファイルを使って、Discovery V2にも文書をアップロードします。
Discovery V2 のUpdateDocument API を使ってドキュメントIDを指定してファイルをアップロードします。
input_filename = "xxxx.json"
input_document_id = "b8f94e8f843d7a5afbb19a632e43ba87"
file_content = open(input_filename, 'r', encoding='UTF-8')
response = discovery.update_document(
project_id = project_id_v2,
collection_id = collection_id_v2,
document_id = input_document_id,
file = file_content,
filename = input_filename,
file_content_type = 'application/json'
).get_result()
| パラメータ | 解説 |
|---|---|
| project_id | Discovery V2 のプロジェクトID |
| collection_id | Discovery V2のコレクションID |
| document_id | 指定するドキュメントID 作業ステップ2. で取得したDiscovery V1のドキュメントIDを指定 |
| file | ファイルの中身 |
| filename | アップロードするファイル名 |
今回は1つのJSONファイルに配列でデータが入っているものを使用したため、指定するドキュメントIDは頭の部分だけです(_xxは不要。自動的に割り振られる)。
アップロードするファイルが手元に残っていない場合は、Discovery V1 の出力結果を加工して Discovery V2 にアップロードする必要があります。
詳細は、マニュアル Recovering documentsをご参照ください。
Discovery V1では、1つのJSONファイルが配列になっている場合、最初のデータはドキュメントIDのみ割り振られ、次の配列データからドキュメントID_1 ドキュメントID_2と割り振られます。
Discovery V2では、1つのJSONファイルが配列になっている場合、最初のデータはドキュメントID_0が割り振られ、ドキュメントID_1 ドキュメントID_02と続きます。
この違いは、関連性トレーニングのトレーニングデータの移行に影響しますので、後続を参照してください。
| Discovery V1 の場合 | Discovery V2 の場合 |
|---|---|
| b8f94e8f843d7a5afbb19a632e43ba87 | b8f94e8f843d7a5afbb19a632e43ba87_0 |
| b8f94e8f843d7a5afbb19a632e43ba87_1 | b8f94e8f843d7a5afbb19a632e43ba87_1 |
| b8f94e8f843d7a5afbb19a632e43ba87_2 | b8f94e8f843d7a5afbb19a632e43ba87_2 |
| : | : |
4. Discovery V1の関連性トレーニングデータを取得する
文書が移行できたことを確認したら、関連性トレーニングのデータをDiscovery V1からV2へ移行します。
Discovery V1にはこのようなトレーニングデータが入っています。
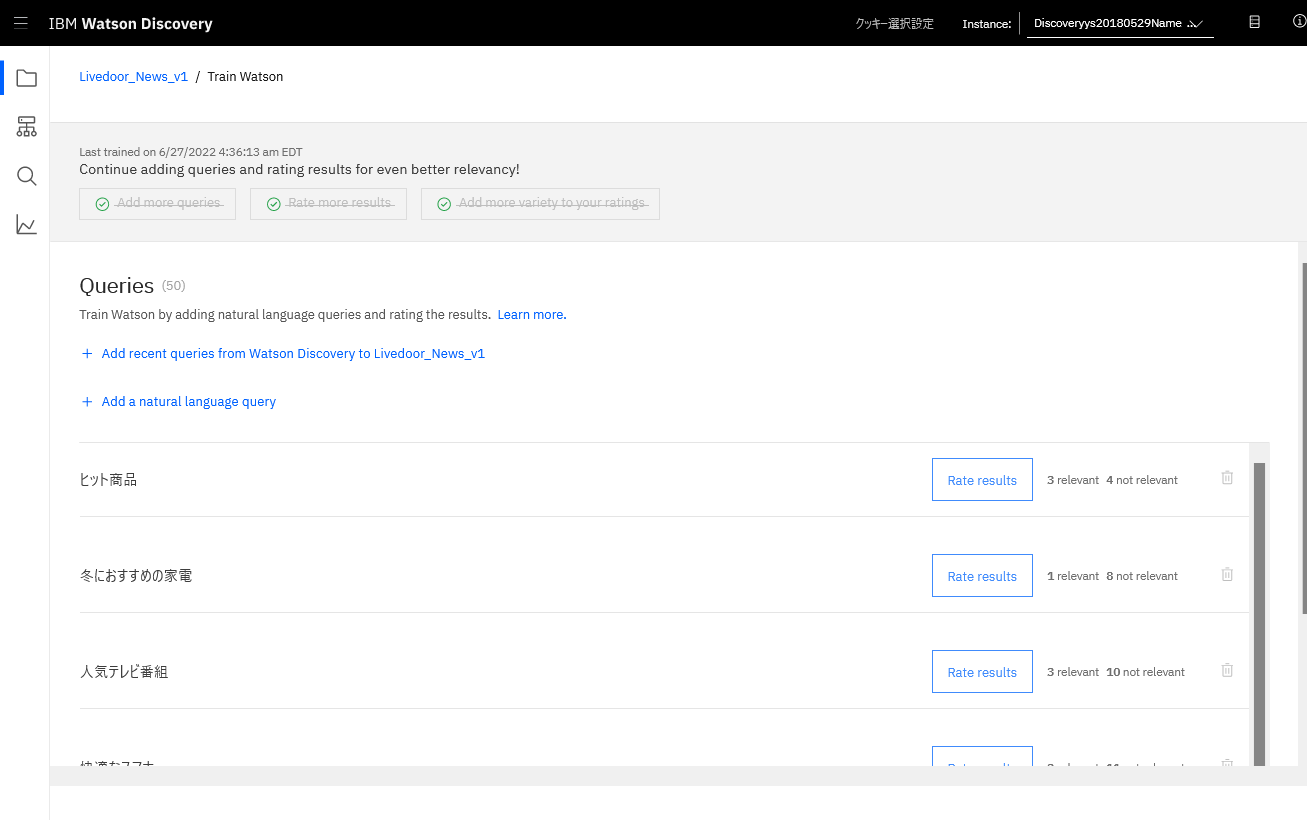
Discovery V1 の List training data API を使ってトレーニングデータを取得します。
response = discovery.list_training_data(
environment_id,
collection_id
).get_result()
| パラメータ | 解説 |
|---|---|
| environment_id | Discovery V1 の Environment ID |
| collection_id | Discovery V1 の コレクションID |
トレーニングデータは以下のようなJSON形式で取得できます。
"relevance"が関連度のスコアで、UIからRelevantを指定した場合は10が、Not Relevantを指定した場合は0がセットされています。
{
"collection_id": "<コレクションID>",
"environment_id": "<Environment ID>",
"queries": [
{
"natural_language_query": "ヒット商品",
"filter": "",
"examples": [
{
"document_id": "b8f94e8f843d7a5afbb19a632e43ba87",
"cross_reference": "",
"relevance": 0,
"created": "2022-06-27T08:22:00.756Z",
"updated": "2022-06-27T08:22:00.883Z"
},
{
"document_id": "b8f94e8f843d7a5afbb19a632e43ba87_26",
"cross_reference": "",
"relevance": 10,
"created": "2022-06-27T08:21:50.878Z",
"updated": "2022-06-27T08:21:51.115Z"
},
5. 取得したトレーニングデータのドキュメントIDを修正する
この作業はドキュメントのファイルタイプがJSONの場合に特有のもので、他のファイルタイプであればこの作業は不要と考えられます
作業ステップ3. に記載したように、JSONファイルをDiscoveryにアップロードした場合、Discovery V1の1文書目とDiscovery V2の1文書目ではドキュメントIDのSuffixが異なります。
作業ステップ4. でDiscovery V1から取得したトレーニングデータの中に、
"document_id": "b8f94e8f843d7a5afbb19a632e43ba87"
という_xxのSuffixが無いドキュメントIDがある場合、このままトレーニングデータをV2に投入するとV2のドキュメントIDと整合性が取れなくなるため
"document_id": "b8f94e8f843d7a5afbb19a632e43ba87_0"
と、_0を追加します。
| Discovery V1 の場合 | Discovery V2 の場合 |
|---|---|
| b8f94e8f843d7a5afbb19a632e43ba87 | b8f94e8f843d7a5afbb19a632e43ba87_0 |
6. Discovery V2にトレーニングデータをアップロードする
Discovery V2 のCreate training query API を使ってトレーニングデータをアップロードします。
まず最初に、ドキュメントIDと関連度を含むTraining Examplesのリストを作ります。
examples_list = []
for data in df1.itertuples(): #ご自身のプログラムロジックでループ
training_example = TrainingExample(
document_id=data.examples_document_id,
collection_id=collection_id,
relevance=data.examples_relevance
)
examples_list.append(training_example)
| パラメータ | 解説 |
|---|---|
| document_id | ドキュメントID 作業ステップ4. で取得したDiscovery V1のトレーニングデータに含まれるドキュメントIDを指定 |
| collection_id | Discovery V2のコレクションID |
| relevance | 関連度 作業ステップ4. で取得したDiscovery V1のトレーニングデータに含まれる関連度を指定 |
そして、Discovery V2に対してトレーニングクエリを作成します。
response = discovery.create_training_query(
project_id=project_id,
natural_language_query=natural_language_query,
examples=examples_list
).get_result()
| パラメータ | 解説 |
|---|---|
| project_id | Discovery V2のプロジェクトID |
| natural_language_query | 検索クエリ |
| examples | 検索クエリに対するTrainingExampleのリスト |
Discovery V2へアップロードされました!
7. トレーニングデータが足りない場合、Discovery V2にトレーニングデータを追加する
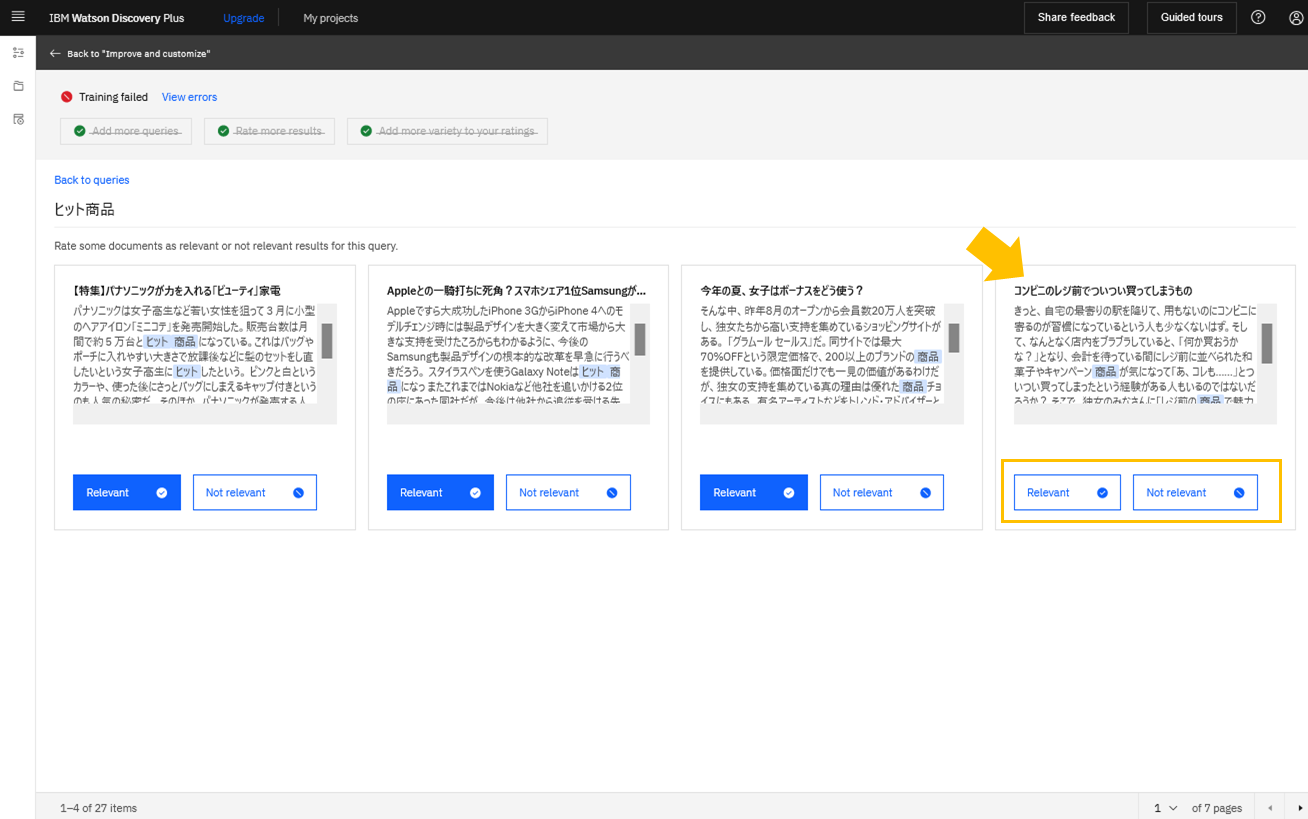
画面上部に"Training failed"のエラーメッセージがあるので"View errors"をクリックしてみます。

「検索クエリに対して指定したドキュメントが検索結果の上位100位に含まれないため、トレーニングに使用されない」というメッセージです。
マニュアルInterpreting relevancy training errors and warningsに記載があるように、このメッセージ自体は警告であってトレーニングが完了していない直接の問題ではないようです。
画面からトレーニングクエリを確認すると、評価がついていない文書が上位に表示されていました。Discovery V1とV2で検索ランキングが変わるためのようです。
サポートに問い合わせたところ、このメッセージのとおりトレーニングに使用されないデータがいくつかあったため、関連度トレーニングに最低限必要なクエリ数が足りなくなりトレーニングが完了しなかった、とのこと。
トレーニングクエリと各ドキュメントに対する関連度の評価を手動で追加すると、無事トレーニングが完了しました!
今回はDiscovery V1から移行したトレーニングデータが少なかったのですが、十分なトレーニングデータがある環境であれば、いくつかのトレーニングデータが無効になったとしてもこの問題は発生しないかもしれません。
2022年7月末時点では、トレーニングデータを追加してトレーニングが正常に完了しても、画面の「Training failed」のメッセージが表示されたままですが、これは既知の問題で今後修正されるそうです。
結果の確認
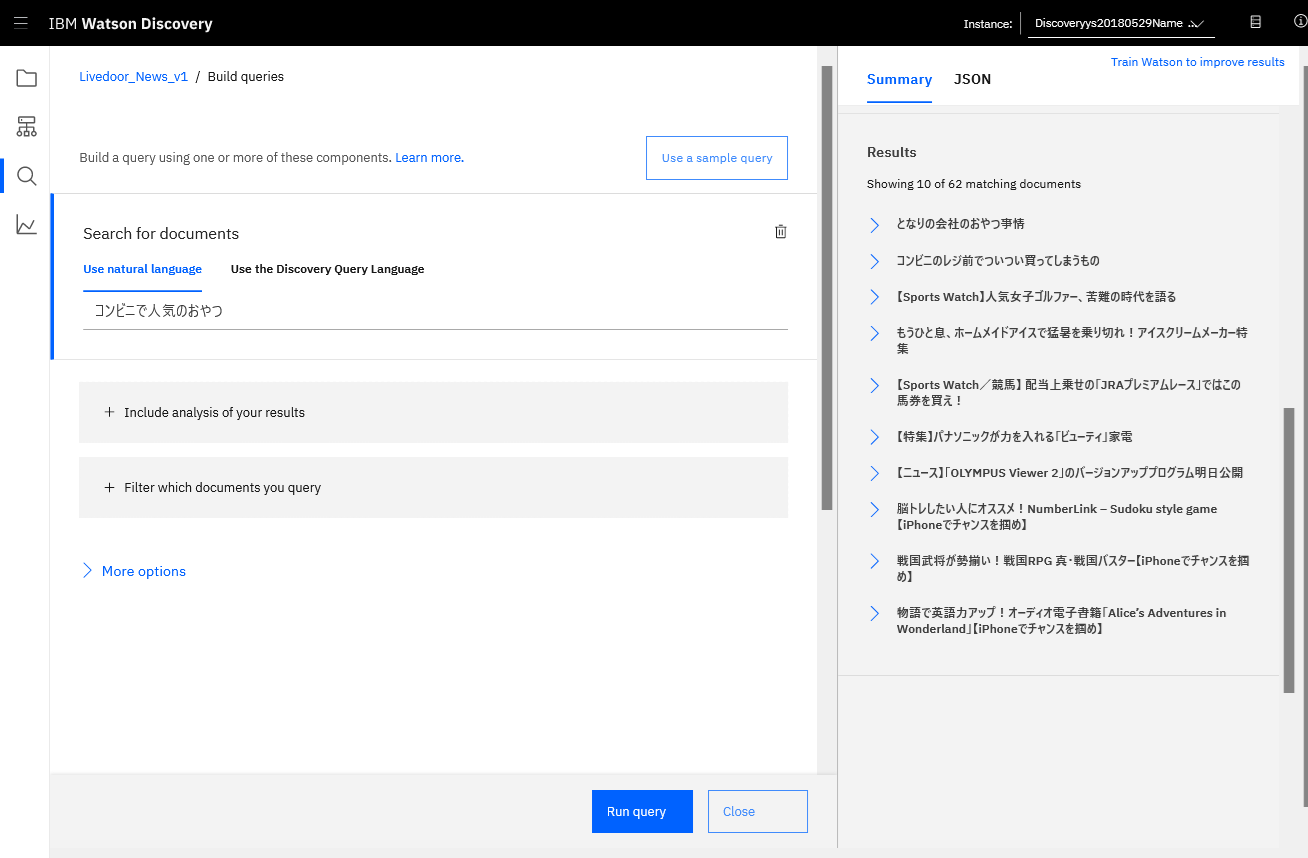
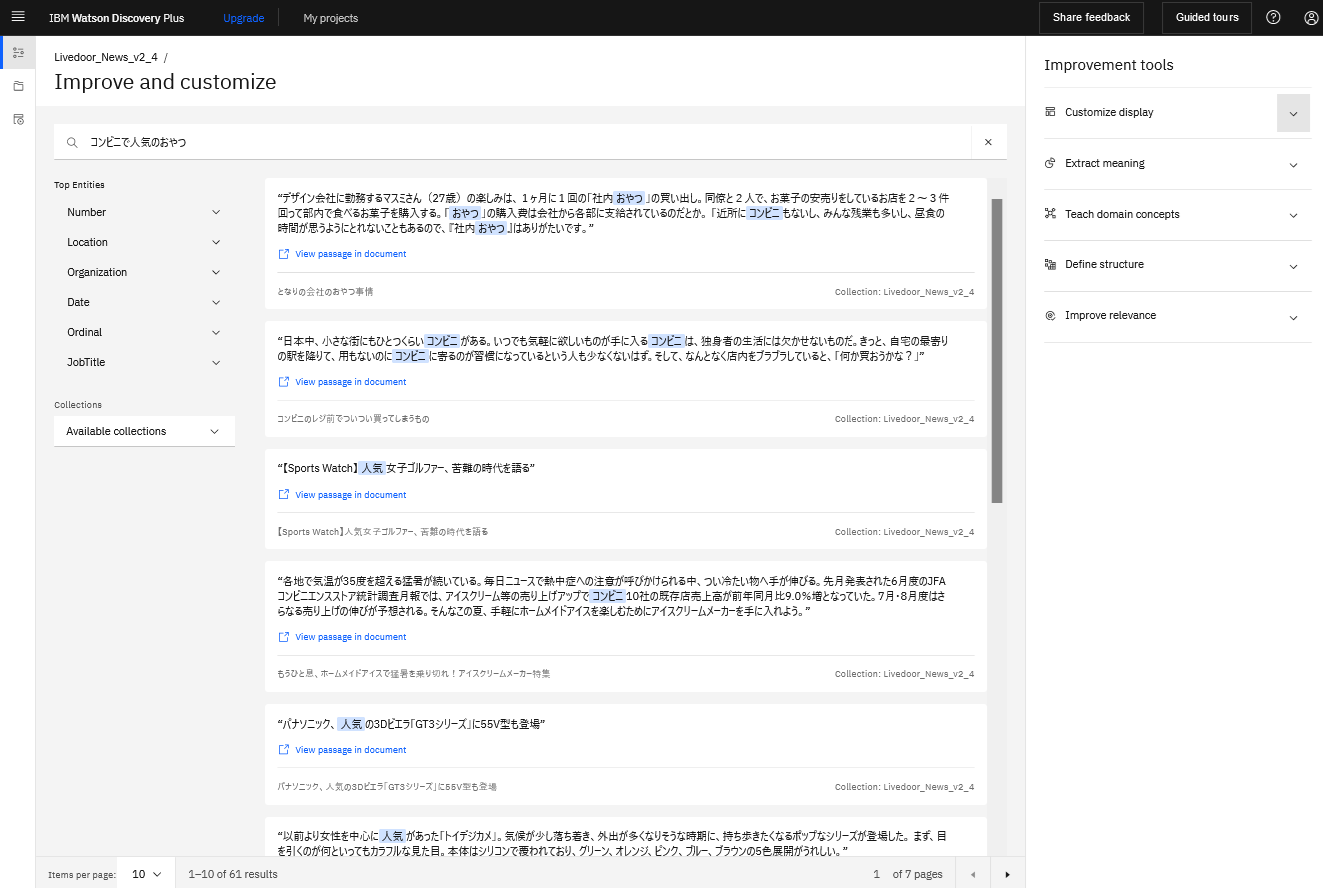
文書とトレーニングデータが移行できたということで、検索結果を確認してみます。5番目の結果が異なりますがだいたい一緒でした!
-
Discovery V1(トレーニング済み)の検索結果
-
Discovery V2(トレーニング済み)の検索結果
APIを使ってトレーニング状況を確認することもできます。
Discovery V2 の Query API を使います。
response = discovery.query(
project_id=project_id,
natural_language_query='<検索クエリ>',
#その他は必要に応じたオプションを付けます
).get_result()
| パラメータ | 解説 |
|---|---|
| project_id | Discovery V2のプロジェクトID |
| natural_language_query | 検索クエリ ' 'のようにブランクにすると結果が"untrained"になってしまうので、何かしらの検索クエリを指定します |
このAPIを使うと、"document_retrieval_strategy": "relevancy_training"という結果が返ってきて、関連性トレーニングが有効になっていることを確認できました!
関連性トレーニングを実施していないプロジェクトでは、"document_retrieval_strategy": "untrained"という結果となりました。
{
"matching_results": 61,
"retrieval_details": {
"document_retrieval_strategy": "relevancy_training"
},
このQuery APIを使うと、各ドキュメントのスコアも見ることができます。
トレーニング前後ではスコアが異なっていることも確認できました。
"results": [
{
"document_id": "b8f94e8f843d7a5afbb19a632e43ba87_235",
"result_metadata": {
"collection_id": "<コレクションID>",
"document_retrieval_source": "search",
"confidence": 0.74352
},
"date": "2010-06-27T14:30:00+0900",
"enriched_text": [
まとめ
- Discovery V1 から V2 へ、ドキュメントIDを維持したまま文書移行ができました!
- Discovery V1 から V2 へ、関連性トレーニングのデータを移行できました!
- Discovery V1 と V2 では全く同じ検索結果になるとは限りませんでした
- そのため、Discovery V1のトレーニングデータがDiscovery V2では有効とならないケースがあります
- Discovery V1 の関連性トレーニングのモデルはコレクション単位ですが、Discovery V2 ではプロジェクト単位となります。Discovery V2 のプロジェクトには複数のコレクションを構成できるので、V2 の関連性トレーニングのモデルはコレクションを跨って動作します
- よって、Discovery V1 に複数コレクションを構成して移行する場合は、Discovery V2 のプロジェクトを分けた方がよさそうです
- 今回は文書と関連性トレーニングのデータのみを移行しましたが、Discovery V1 と V2 には他にも違いがあるので、マニュアル Comparing v1 and v2 featuresを確認されるとよいと思います
- Discovery APIもV1からV2に変更されるため、Discovery を利用するアプリケーションを開発されている場合は、APIの移行も必要になりそうです。マニュアル Update your application to use the v2 API に説明があります
その他の移行に関する注意点
-
トレーニングデータの前提について
Discovery V1のマニュアルTraining data requirementsでは、「トレーニングクエリ数は50以上」「各トレーニングクエリは Relevant と Not relevantの両方の評価を付けることが推奨」とされています。
Discovery V2のマニュアルInterpreting relevancy training errors and warningsでは、「トレーニングクエリ数は50以上」「トレーニングクエリは最低でも一つはRelevantで評価する必要がある」「トレーニングクエリの25%はRelevantとNotRelevantの両方の評価が必要」という記載があります。
トレーニングデータの前提が少し異なるようです。 -
同義語検索について
Discovery V1で日本語の同義語検索をする場合は、Query ExpansionとTokenization Dictionaryの両方の機能を組み合わせて実現していました。
Discovery V2ではTokenization Dictionaryの機能が無くなりましたが、Query Expansionの機能だけでも日本語の同義語検索ができるようです。Qiita [Watson Discovery] 同義語を使って検索する で試してみた結果を紹介しています。
参考資料
- IBM Watson Blog>IBM Watson Discovery v1 の非推奨の発表
- IBM Watson Blog>Discovery v2 への移行(マニュアルの翻訳版)
- Discoveryマニュアル>Getting the most from Discovery(V1とV2の機能比較)
- Discoveryマニュアル>Migrating to Discovery v2(V1からV2への移行)
- IBM Watson APIs Github>How to enumerate id's of documents in watson discovery service(QueryAPIのcount+offset<10,000 という制約の回避策)