動機
- 免許証の情報を写真から読み取りたい!
- 画像処理を楽しみたい!
概要
-
免許証と同じサイズのカード(nanacoカード)の輪郭を OpenCV で検出し、射影変換することでカードの内容が読みやすいようにしました
- OCRで内容を読み取る準備ができました(内容の読み取りは次の記事で紹介予定)
- OCRまでやらないので、サイズが同じnanacoカードで今回は代用
-
斜め上から撮ったカードを...
→ こんな感じで角度を補正してカードを表示できるようになりました
 →
→ 
他の類似記事との差別化ポイント
- カード検出のための**二値化の閾値を動的に決定する**ロジックを入れています
- (精度がほんの少し良いように見えます)
- ここはちゃんと検証していないのでお気持ちレベルです。
想定読者
- OpenCV で輪郭検出(エッジ検出)してみたい人
- 写真からカードの情報を読み取りたい人
作業手順
- 環境構築
- 二値化 1
- 輪郭抽出
- 射影変換
環境構築
Pipenv 使います。
Pipenv
brew install pipenv
関係パッケージ
pipenv install numpy matplotlib opencv-contrib-python pyocr
pipenv install jupyterlab --dev
※ この記事の範囲内では、 opencv-contrib-python は opencv-python 大丈夫です。2
ディレクトリ構成
以下のような構成にして、3つの画像
-
nanaco.jpeg(一番わかりやすく撮影) -
nanaco_skew.jpeg(斜めからカードの形が歪むように撮影) -
nanaco_in_hand.jpeg(白背景で手で持った状態で撮影)
を試してみます。
ソースコードはjupyter notebook card.ipynb を利用します。
.
├── Pipfile
├── Pipfile.lock
├── images
│ ├── nanaco.jpeg
│ ├── nanaco_in_hand.jpeg
│ └── nanaco_skew.jpeg
└── notebooks
└── card.ipynb
OpenCV でカードの写った写真を表示してみる
- Jupyter Lab を起動
pipenv run jupyter lab
-
notebooks/card.ipynbを作成し、以下をセル実行(他のスクリプトも全てセルで実行)
%matplotlib inline
import cv2
import matplotlib.pyplot as plt
img = cv2.imread('../images/nanaco_skew.jpeg')
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
matplotlib の目盛りが気になりますが、あまり気にせず、むしろ座標がわかりやすいということで、今回はそのまま進めます。
二値化(Binarization)
グレースケール化
# グレイスケール化
gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
plt.imshow(gray_img)
plt.gray()
二値化の閾値決定
多くのチュートリアルや記事では二値化の際の閾値は、200 くらいの値をハードコードしており手動で決めるような扱いでした。
この記事では、動的に(自動で)閾値を決めるロジックを入れてみました
import numpy as np
# nanacoは0.2くらいが良さそう。免許証の場合はまたチューニングが必要かも
card_luminance_percentage = 0.2
# TODO: パフォーマンス度外視
def luminance_threshold(gray_img):
"""
グレースケールでの値(輝度と呼ぶ)が `x` 以上のポイントの数が20%を超えるような最大のxを計算する
ただし、 `100 <= x <= 200` とする
"""
number_threshold = gray_img.size * card_luminance_percentage
flat = gray_img.flatten()
# 200 -> 100
for diff_luminance in range(100):
if np.count_nonzero(flat > 200 - diff_luminance) >= number_threshold:
return 200 - diff_luminance
return 100
threshold = luminance_threshold(gray_img)
print(f'threshold: {threshold}')
今回の3種類の画像での閾値は以下のように計算されました。
例えば、nanaco_skew.jpegでは反射光の加減のためか、閾値が(よく使われている)200だと上手くいきませんでした。上記のソースコードで計算した138で行うことでのちのカードの輪郭の取得が上手くいくようになりました。
| nanaco.jpeg | nanaco_skew.jpeg | nanaco_in_hand.jpeg | |
|---|---|---|---|
| 二値化の閾値 | 200 | 138 | 199 |
| 画像 |  |
 |
 |
|
二値化
_, binarized = cv2.threshold(gray_img, threshold, 255, cv2.THRESH_BINARY)
plt.imshow(cv2.cvtColor(binarized, cv2.COLOR_BGR2RGB))

輪郭抽出(Contour extraction)
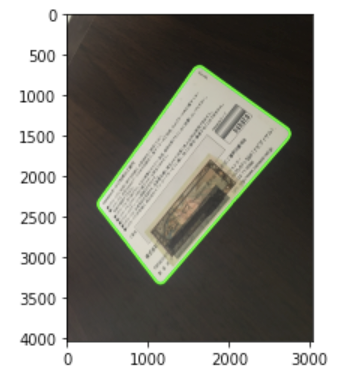
contours, _ = cv2.findContours(binarized, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
# 面積最大のものを選択
card_cnt = max(contours, key=cv2.contourArea)
# 画像に輪郭を描画
line_color = (0, 255, 0)
thickness = 30
cv2.drawContours(img, [card_cnt], -1, line_color, thickness)
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
射影変換(Projection transformation)
上記で捕捉できた輪郭の情報を元に射影変換(角度の補正)をしていきます。
# 輪郭を凸形で近似
# 輪郭の全長に固定値で 0.1 の係数をかけるので十分
# ある程度まともにカードを写す前提では係数のチューニングはほぼ不要と思われる(OCRの調整では必要かも)
epsilon = 0.1 * cv2.arcLength(card_cnt, True)
approx = cv2.approxPolyDP(card_cnt, epsilon, True)
# カードの横幅(画像がカードが縦になっているので、射影変換の際にはwidthとheightが逆になっている)
card_img_width = 2400 # 適当な値
card_img_height = round(card_img_width * (5.4 / 8.56)) # 免許証のration(=nanacoのratio)で割って産出
src = np.float32(list(map(lambda x: x[0], approx)))
dst = np.float32([[0,0],[0,card_img_width],[card_img_height,card_img_width],[card_img_height,0]])
projectMatrix = cv2.getPerspectiveTransform(src, dst)
# 先ほどで線が上書きされたので再度画像を取得
img = cv2.imread('../images/nanaco_skew.jpeg')
transformed = cv2.warpPerspective(img, projectMatrix, (card_img_height, card_img_width))
plt.imshow(cv2.cvtColor(transformed, cv2.COLOR_BGR2RGB))
できた!! 斜めだったの文字がきちんと真っ直ぐになっていますね!
おまけ
この後、実際の免許証を使って内容の読み取りをOCRを使ってやってみようかと考えていますが、現状のnanacoでも少し試してみました。
ただし、本来なら読み取る部分に制限を加えるなどの必要がありますが、ざっくりやっちゃっています。
nanaco_in_hand.jpeg の画像を使って、最後に得られた画像を pyocr を使って画像全体に関してOCRをかけてみました。
上記と同じスクリプトを nanaco_in_hand.jpeg に対して行うとこちらが得られます(ちょっと斜めってる...)

この画像に対して、pyocr + tesseract をチュートリアル通りに使ってテキスト化してみました。3
結果は...
nanaco カ ー ド ご 利用 の こ 案 内
あこ の カー ド の ご 利用 に 関す る 詳細 は 、 会 員 規約 を ご 確認 くだ さい 。 5
あこ の カー ド は 、 右 記 nanaco マ ー ク が ある 加盟 店 で 、 電 子 マ ネー の ご 利用 、 お よび カー ド 内 の 電子 マネ ー
残高 の 確認 が で きま す 。
あこ の カー ド は 、 折 り 曲げ た り 、 大 き な 衝 撃 を 与え た り 、 高 温 、 磁 気 を 帯び た と ころ に 放置 し な いで くだ さい 。
あこ の カー ド お よび カー ド 内 の 電子 マネ ー は 換金 で きま せん 。
あこ の カー ド の チャ ー ジ 上 限 額 は 5 万 円 で す 。
あこ の カー ド は 、 会 員 規約 を 承認 され 、 会 員 署 名 欄 に 署名 され た 会 員 ご 本 人 以外 は 使用 で きま せん 。
あこ の カー ド の 所 有 権 は 、 株 式 会 社 セ ブン ・ カ ー ドサ ービス に 属し 、 他 人 に 貸与 ・ 譲 渡す る こと は で きま せん
と荒くやったわりにはぼちぼち、というところでしょうか。この辺りを免許証で精度上げて続きをやっていこうと思います。
("●"が"あ"と認識されていてなかなか面白いですね)
-
各点(256x256x256)の情報があるRGBの画像 → 各点(2=1/0)の二値情報の二値画像の変換を行います。これは、輪郭抽出をしやすくするための加工です。 ↩
-
opencv-contrib-pythonはopen-pythonに加えてcontribのモジュールも一緒にインポートしてくれます。opencv-pythonのところはcv2でも大丈夫らしいです。ただ、公式のドキュメントを見る限り、新しく入れる分にはこっちの表記にするのが良いみたいです。(参考: https://pypi.org/project/opencv-python/) ↩