コードの整理とモジュール化
前回までコードは全て app.py の中にまとめて書いてきました。ただし、既に200行に達しており、今後機能をどんどん拡張していくと可読性が下がります。
そこで、以下のように3つのファイルにコードを分けようと思います。
-
app.py: メインプログラム。受信した Webhook の内容によって「どのように処理を分岐させるか」を指示。この中では処理をせず、処理の結果を受け取って返信するだけにする。 -
botfuncs.py: この中で具体的な処理をする。 -
utils.py: LINE messaging API とは直接関係のない自作関数などはこちらに記載する。
という感じです。
Python では .py ファイルに書いた関数は、同ディレクトリ内では簡単にインポートが可能です。utils.py に書いた自作関数を botfuncs.py 内でインポートして使い、app.py 内で botfuncs.py の関数をインポートする、という構造になります。このように関数をまとめて一つのファイルにすることをモジュール化といいます。さらにファイルを一つのライブラリのようにまとめるパッケージ化というものもありますが、おそらくそこまで複雑化はしないでしょうから、とりあえずはこの3分割に留めておきます。
今回の場合、levenshtein()、 tokenize() などの関数は utils.py に移動してもらうことになります。モジュール化した別ファイル内の関数・変数は、以下のようにインポートできます。インポート先のファイルと同一ディレクトリにあることが前提です。
from utils import levenshtein, tokenize
ただ、関数が増えると一々記載するのもめんどくさくなります。その場合、* を使って全て一気にインポートも可能です。ただし、名前の衝突にはくれぐれも気をつけて下さい。
from utils import *
以下のように、モジュール名だけインポートし、その中の関数は utils.levenshtein() のようにモジュール名を明示して使うこともできます。np.array() と同様です。こちらだと名前の衝突の危険性は無くなりますが、そもそも衝突するような名前を付けるべきでないとも言えます。
import utils
機能の追加と処理の分岐
現時点でボットが持っている機能は「曲名を入れると、その YouTube リンクを返信してくれる」というものですが、実際はもっと多くの機能を搭載予定です。どのようにしてそれぞれの機能を呼び出すかには工夫が必要になります。
リッチメニューの利用なども良いですが、もっと単純にメッセージ送信だけで機能を分けられるようにしたいと思います。そこで、prefix (接頭語) を付ける方式を検討します。例えば
- 曲名のみ送信 → YouTube ビデオの検索
-
"歌詞 曲名"と送信 → 歌詞の表示 -
"ベース 曲名"と送信 → ベース楽譜の表示
といったようにです。ここでは各機能を「モード」と呼ぶことにします。
処理の流れは以下のようになります。
- Webhookを受信
- メッセージを取得し、prefix からモードを判断
- 各モードに対応した処理を呼び出し、返信内容を作成してメッセージオブジェクト化
- メッセージオブジェクトを返信
このうち、(1)(2)(4) は app.py 内で、(3) は botfuncs.py 内で行おうと思います。
まずは「曲名から歌詞を表示」する機能を追加します。対応 prefix は 歌詞 lyric(s) とします。
app.py
メッセージ処理系の関数を他の2ファイルに移したことで、コードがだいぶスッキリしました。########## で挟まれた部分が実際のイベントハンドラです。正規表現を使い、prefix があるかどうかでモードを判断し、呼び出す関数(get_official_youtube、get_lyrics)を変えます。どの関数であれ、メッセージオブジェクトとして受け取るようにし、全く同じメソッドで返信できるようにしています。
prefix は大文字小文字を区別しないように、正規表現に flags=re.I (ignorecase) を入れています。ただ、この後の処理で結局全てを小文字化するので、受け取ったメッセージを最初に強制小文字化してしまうのもアリかもしれません。
# -*- coding: utf-8 -*-
from flask import Flask, request, abort
from linebot.v3 import WebhookHandler
from linebot.v3.exceptions import InvalidSignatureError
from linebot.v3.messaging import (
ApiClient, Configuration, MessagingApi,
ReplyMessageRequest, TextMessage
)
from linebot.v3.webhooks import (
FollowEvent, MessageEvent, TextMessageContent
)
import os, re
from botfuncs import *
## load `.env` file
## if test bot, use `load_dotenv('test.env')` instead
from dotenv import load_dotenv
load_dotenv()
## environment variables
CHANNEL_ACCESS_TOKEN = os.environ["CHANNEL_ACCESS_TOKEN"]
CHANNEL_SECRET = os.environ["CHANNEL_SECRET"]
## Flask instantiation
app = Flask(__name__)
## LINE instantiation
configuration = Configuration(access_token=CHANNEL_ACCESS_TOKEN)
handler = WebhookHandler(CHANNEL_SECRET)
## callback function (copy & paste)
@app.route("/callback", methods=['POST'])
def callback():
signature = request.headers['X-Line-Signature']
body = request.get_data(as_text=True)
app.logger.info("Request body: " + body)
try:
handler.handle(body, signature)
except InvalidSignatureError:
app.logger.info("Invalid signature. Please check your channel access token/channel secret.")
abort(400)
return 'OK'
##################################################
## When someone follow the bot
@handler.add(FollowEvent)
def handle_follow(event):
## API instantiation
with ApiClient(configuration) as api_client:
line_bot_api = MessagingApi(api_client)
## reply
line_bot_api.reply_message(ReplyMessageRequest(
replyToken=event.reply_token,
messages=[TextMessage(text='Thank You!')]
))
## When received TEXT MESSAGE
@handler.add(MessageEvent, message=TextMessageContent)
def handle_message(event):
with ApiClient(configuration) as api_client:
line_bot_api = MessagingApi(api_client)
## get the text content
received_message = event.message.text
## MODE : LYRICS MODE
if re.match(r'(歌詞|lyrics?)', received_message, flags=re.I): ## ignore case
query = re.sub(r'^(歌詞|lyrics?)', '', received_message, flags=re.I) ## remove prefix
messages = get_lyrics(query)
## MODE : OFFICIAL YOUTUBE
else:
messages = get_official_youtube(received_message)
## send reply message
line_bot_api.reply_message(ReplyMessageRequest(
replyToken=event.reply_token,
messages=messages
))
##################################################
## toppage of website - Hello world!
@app.route('/', methods=['GET'])
def toppage():
return 'Hello world!'
if __name__ == "__main__":
app.run(host="0.0.0.0", port=8000, debug=True)
botfuncs.py
app.py の中にあった、曲名検索用関数と、返信時のメッセージオブジェクト作成のコードをこちらに移植しました。get_official_youtube と get_lyrics がそれぞれのモードに対応した関数になっています。また、レーベンシュタイン距離の計算など、その他の関数は全て utils.py からインポートする仕様になっています。ちなみに、私の用意したデータでは歌詞の改行部分は <br> にしているため(csvファイルで崩れないように)、それを置換する作業も行なっています。
勘の良い方はお気付きだと思いますが、get_official_youtube と get_lyrics はほとんど同じ処理をしています。これからモードをどんどん増やしていく時に、この同じようなコードをコピペしていたらあっという間に冗長なコードになります。なので、次回でクラス化を行う予定です。
# -*- coding: utf-8 -*-
import re
import pandas as pd
from collections import Counter
from linebot.v3.messaging import (
TextMessage, QuickReply, QuickReplyItem, MessageAction
)
from utils import levenshtein, tokenize, remove_punct
## LOAD DATA
DATA = pd.read_csv('data/beatles.csv', index_col='song') ## set song title as index
SONGS = DATA.index ## list of song title
##### MODE : GET OFFICIAL YOUTUBE #####
def get_official_youtube(text:str) -> list:
songtitles= search_song_title(text)
if len(songtitles) == 0: ## no candidate
reply = 'NOT FOUND:\nPlease try again with different words.'
messages = [TextMessage(text=reply)]
elif len(songtitles) == 1: ## only one candidate -> return URL
reply = 'https://www.youtube.com/watch?v=' + DATA.loc[songtitles[0], 'official_youtube']
messages = [TextMessage(text=reply)]
else:
quickreply = QuickReply(items=[]) ## instantiation
for song in songtitles:
if len(song) > 20: ## max characters : 20
item = QuickReplyItem(action=MessageAction(label=song[:19]+'…', text=song))
else:
item = QuickReplyItem(action=MessageAction(label=song, text=song))
quickreply.items.append(item)
messages = [TextMessage(text='candidate songs:', quickReply=quickreply)]
return messages
##### MODE : GET LYRICS #####
def get_lyrics(text:str) -> list:
songtitles= search_song_title(text)
if len(songtitles) == 0: ## no candidate
reply = 'NOT FOUND:\nPlease try again with different words.'
messages = [TextMessage(text=reply)]
elif len(songtitles) == 1: ## only one candidate -> return URL
reply = DATA.loc[songtitles[0], 'lyrics'].replace('<br>', '\n') ## original data uses <br> instead of \n
reply = f'{songtitles[0]} :\n\n' + reply ## add song title as header
messages = [TextMessage(text=reply)]
else:
quickreply = QuickReply(items=[]) ## instantiation
for song in songtitles:
if len(song) > 20: ## max characters : 20
item = QuickReplyItem(action=MessageAction(label=song[:19]+'…', text=f'lyrics {song}')) ## add prefix for next reply
else:
item = QuickReplyItem(action=MessageAction(label=song, text=f'lyrics {song}'))
quickreply.items.append(item)
messages = [TextMessage(text='candidate songs:', quickReply=quickreply)]
return messages
##################################################
## CREATE INVERTED INDEX FOR SONG TITLE
## { token : {set of songs that contain the word} }
INVERTED_INDEX_songtitles= {'64': {"When I'm Sixty-Four"}}
for song in SONGS:
for token in tokenize(song):
INVERTED_INDEX_songtitles [token] = INVERTED_INDEX_songtitles .get(token, set()) | {song}
## FUNCTION TO FIND THE MOST SIMILAR SONG TITLE
def search_song_title(query:str, min_partial_len=4, distance_threshold=0.5) -> list:
"""
find song title from input text
ambiguous matching ranked by
1. exact match
2. partial match (if only one song)
3. token match - refer INVERTED_INDEX_songtitles
4. Levenshtein Distance
output is LIST regardless of the number of matched songs (0 or more)
"""
query_lower = re.sub(r'\s\s+', ' ', query).strip().lower() ## shrink space & lowercase
query_no_punct = remove_punct(query_lower) ## a hard day's -> aharddays
query_tokens = query_lower.split(' ')
partial_match_songs = []
min_distance = 1000
min_distance_songs = []
for song in SONGS:
song_lower = song.lower() ## lowercase song title
song_no_punct = remove_punct(song) ## remove punct
### EXACT MATCH ###
if query_lower==song_lower or query_no_punct==song_no_punct:
return [song]
### PARTIAL MATCH - 4 chars or more ###
if (query_lower in song_lower and len(query_lower) >= min_partial_len) or\
(query_no_punct in song_no_punct and len(query_no_punct) >= min_partial_len):
partial_match_songs.append(song)
### LEVENSHTEIN DISTANCE ###
if len(query_no_punct) < len(song_no_punct): ##
window_len = len(query_no_punct)
distance = min(levenshtein(query_no_punct, song_no_punct[i:i+window_len])
for i in range(0, len(song_no_punct)-window_len+1))
else:
distance = levenshtein(query_no_punct, song_no_punct)
if distance < min_distance and distance / len(query_no_punct) < distance_threshold:
min_distance = distance
min_distance_songs = [song]
elif distance == min_distance and distance / len(query_no_punct) < distance_threshold:
min_distance_songs.append(song)
### NUM OF MATCHED TOKEN ###
token_counter = Counter()
for token in query_tokens:
if token in INVERTED_INDEX_songtitles :
token_counter.update(INVERTED_INDEX_songtitles [token])
if len(token_counter) == 0:
max_token_count, token_match_songs = 0, []
else:
max_token_count = token_counter.most_common()[0][1]
token_match_songs = [song for song, count in token_counter.most_common() if count==max_token_count]
## only one partial match
if len(partial_match_songs) == 1:
return partial_match_songs
## if token match exists
elif max_token_count >= 1:
return token_match_songs
## no token match AND multiple partial match
elif len(partial_match_songs) >= 2:
return partial_match_songs
## else, minimum Levenshtein distance
else:
return min_distance_songs
utils.py
これはその他の補助関数をそのまま移植しただけです。
import re
## function to get Levenshtein distance between 2 strings
def levenshtein(str1, str2) -> int:
str1 = '^' + str1
str2 = '^' + str2
distances = [list(range(len(str2)))]
for i in range(1, len(str1)):
row = [i]
for j in range(1, len(str2)):
insert = row[j-1] + 1
delete = distances[i-1][j] + 1
replace = distances[i-1][j-1] + int(str1[i]!=str2[j])
row.append(min(insert, delete, replace))
distances.append(row)
return distances[-1][-1]
## function to tokenize English text
## full stop . is excluded as word boundary (due to song title)
def tokenize(text:str) -> set:
## rough_token includes empty string ''
rough_tokens = re.split(r'[\s;:,\-\(\)\"!?]', text.lower())
tokens = set() ## Bag of Words (i.e. order is ignored)
for token in rough_tokens:
if token == '':
continue
if token.endswith("\'s"):
tokens.add(token.replace("\'s", '')) ## day's - > day
if "\'" in token:
tokens.add(token.replace("\'", '')) ## don't -> dont
tokens.add(token)
return tokens
## function to remove whitespaces/punctuations
## e.g. A Hard Day's Night -> aharddaysnight
def remove_punct(text:str) -> str:
return ''.join(c for c in text if c.isalnum()).lower()
動作確認
lyrics の prefix と共にキーワードを入れると、絞り込めない場合は候補曲が出てきます。
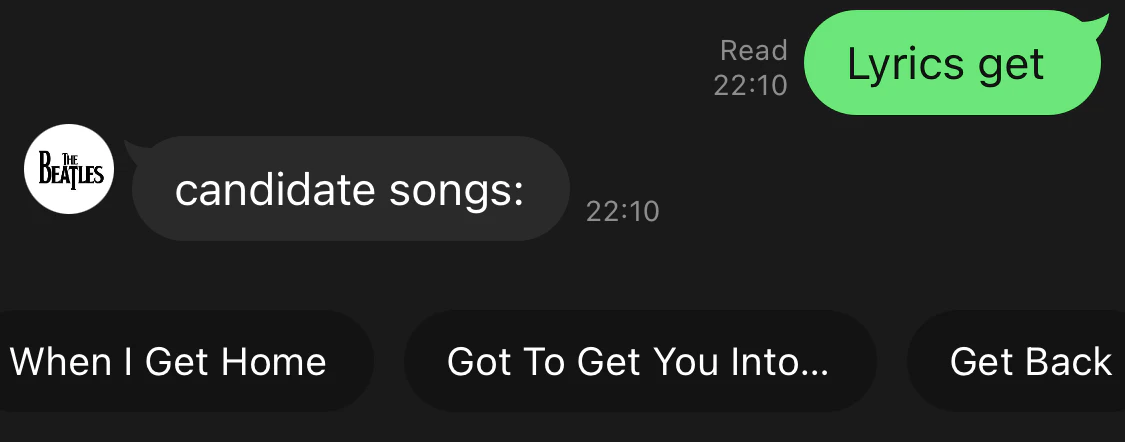
クイックリプライから曲名を選択すると、歌詞がきちんと表示されます。
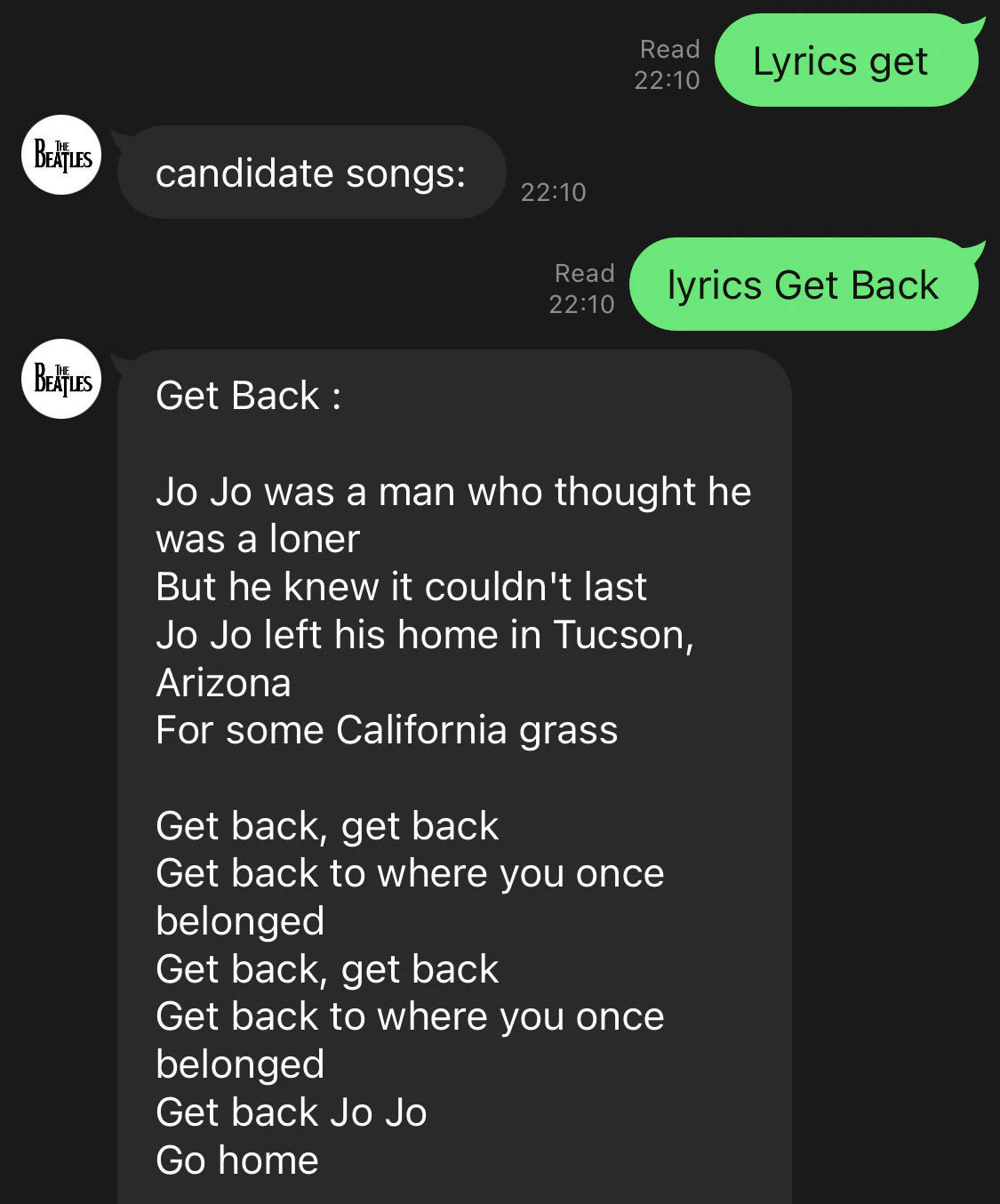
今回はこれで終了です。次回はクラス化を行い、さらに機能を追加していきます。
目次 : [無料][2024年版] LINE Messaging API v3 + Python(Flask) でボットを作る
GitHub レポジトリ
older_version 内に、各回時点での app.py と requirements.txt があります。