レーベンシュタイン距離の追加
前回の続き、情報検索理論(後編)になります。やり残しのレーベンシュタイン距離の実装を行います。
検索文字列と曲名の長さの違いによって、レーベンシュタイン距離がうまく機能しないこともあるので、文字列を切り取った substring を用意してその中で最小の距離を求める(最小ハミング距離)というアイデアは既に述べました。逆に検索文字列がの方が長い場合は、そのままレーベンシュタイン距離を使ってしまえばよいです。前回までのアルゴリズムの最後にレーベンシュタイン距離を加えると以下のようになります。
[全曲名を for ループ]
- もし検索文字列と完全一致した場合、その曲名を返してループ強制終了
- もし検索文字列と部分一致した場合、部分一致曲名リストに格納しておく
- 検索文字列が曲名より短い場合、文字列長の窓をシフトしながら、最小のレーベンシュタイン距離を求める。検索文字列の方が長い場合、そのままレーベンシュタイン距離を求める。レーベンシュタイン距離リストに記録する
[全曲名 for ループ後]
- 検索文字列内の単語を for ループし、それぞれの単語を含む曲名のセットの intersection (積集合)を求める。つまり、「検索文字列内の全ての単語を含む曲名」のセットを作る。
- もし部分一致した曲名が1曲だけなら、その曲を返す
- もし「検索文字列内の全ての単語を含む曲名」が存在するなら、その中のうち一つをランダムで返す
- もし「検索文字列内の全ての単語を含む曲名」が存在せず、かつ部分一致が2曲以上あるなら、その中のうち一つをランダムで返す
- もし「部分一致」「単語一致」のどちらも存在しないなら、最小のレーベンシュタイン距離となる曲名を返す
これで、どんな文字列に対してもそれなりに近い曲名が得られるようになります。レーベンシュタイン距離を計算する関数は前回も書きましたが、再掲しておきます。
def levenshtein(str1, str2):
str1 = '^' + str1
str2 = '^' + str2
distances = [list(range(len(str2)))]
for i in range(1, len(str1)):
row = [i]
for j in range(1, len(str2)):
insert = row[j-1] + 1
delete = distances[i-1][j] + 1
replace = distances[i-1][j-1] + int(str1[i]!=str2[j])
row.append(min(insert, delete, replace))
distances.append(row)
return distances[-1][-1]
ただ、Levenshtein パッケージをインストールし、from Levenshtein import distance して使ったほうが楽かもしれません。
良い UI/UX としてのボット設計
ですが、「どんな場合でも何かしらの検索結果を返してくれる」というのは、ボットとして合理的であるとは言えないと思っています。たとえば、abcdef という文字列に対しては Being For The Benefit Of Mr. Kite! という曲が返ってきますが、これは Benefit の部分に b__ef という配列があるために、他の曲名と比べてたまたまレーベンシュタイン距離が近くなっているだけにすぎません。
そもそもレーベンシュタイン距離を導入した目的は入力ミスなどによってマッチしなくなることを回避するためです。こんな何の関係もなさそうな曲を引っ張ってくるよりは、「お前の言ってること、よくわからないんだよ!正しく入力しろ!」と言ってくれる方が親切な設計だと考えます。
また、「合理的なボット」という話題に関連して、ここまでやってきた「複数マッチした場合はランダムで返す」という方法も見直してみます。ボットとしてより良いUI/UXを目指すなら、
- ある程度の入力ミスは、曖昧検索によって許容する
- 全然一致しない時は、正直にわからないという
- 候補が複数あって絞り込めない時は、それを提示して選んでもらう
というのが理想です。(2) はレーベンシュタイン距離の閾値を設定したりすることで何とかなるかもしれません。(3) を行うにはまた新しいツールが必要になります。そこでクイックリプライという便利な機能を利用します。
閾値の設定
どこまでを「マッチ」とみなし、どこからは除外するか、閾値を設定していきましょう。大半の場合は「入力文字列長 < 欲しい曲名の長さ」ですから、レーベンシュタイン距離の入力文字列長に対する「割合」を基準にしてみることを考えます。
上の例における、入力文字列6文字に対して、最小レーベンシュタイン距離が3というのは、全ての曲名のうち、最も似ている部分だけ取り出しても半分の文字を置換をしない限り一致しないということです。これは正直言ってマッチしていると言えるか微妙なところです。
ちなみに、歌詞から抽出した各単語の文字列長さの分布は以下のようになっています。

多くの単語は4文字以下、長くても大半は10文字以下に収まります。長い単語は、dissapointment, independence, misunderstanding, grandchildren などがありました。2文字の単語も多いですが、検索文字列に2文字しか入れないというのは流石に考えにくいですし、普通は最低でも 4-5 文字は入れるでしょう。これから、
- 部分一致判定の最低入力文字数は4文字
- レーベンシュタイン距離で半分以上一致しないものは、最小であっても除外する
ということにします。
検索文字列から一意に決まらない時
クイックリプライは、メッセージ画面下部に横並びのボタンを表示してそれを選択させる機能です。テンプレートメッセージなどとは異なり、一度押した後は消えます。
これを用いることで、一つに絞れなかった時に選択肢を提示できます。
クイックリプライの各ボタンには、何かしらのアクションを設定しなければなりません。こちらを参照してください。普通はポストバックアクションで付加データと共に送信し、別処理を行うという使い方が多用されます。
今回は選択肢の曲名を提示してそれを押すことで、「必ず完全一致する曲名をメッセージ送信する」という方法にします。つまりメッセージアクションですね。
これらを使うために、まず必要なクラスをインポートしておきます。従来までは上述のAPIリファレンスのようにJSON(辞書)を編集していたのですが、v3 はオブジェクトの積み重ねだけでできるようになっています。
from linebot.v3.messaging import QuickReply, QuickReplyItem, MessageAction
改良版
ではこれらを実装してしていきましょう。まずは曲名検索用関数 search_song_title() からいじります。部分一致の最小文字数・レーベンシュタイン距離の閾値はキーワード変数として受け取り、変更できるようにしておきます。
部分一致・単語一致・最小レーベンシュタイン距離の結果は、それぞれ partial_match_songs, token_match_songs, min_distance_songs の中にオリジナルの曲名がそのまま格納されています。
単語一致を見るときに、全単語一致 (and) ではなく、collections.Counter() を用いて一致数を数え、最大の一致数のものを取り出すようにしています。これはこれで1単語しか一致しないものをたくさん抽出する羽目になるんですが、選択肢提示して選んでもらうのでこのような方式に変更しました。
from collections import Counters
def search_song_title(query:str, min_partial_len=4, distance_threshold=0.5):
query_lower = re.sub(r'\s\s+', ' ', query).strip().lower() ## shrink space & lowercase
query_no_punct = remove_punct(query_lower) ## a hard day's -> aharddays
query_tokens = query_lower.split(' ')
partial_match_songs = []
min_distance = 1000
min_distance_songs = []
for song in SONGS:
song_lower = song.lower() ## lowercase song title
song_no_punct = remove_punct(song) ## remove punct
### EXACT MATCH ###
if query_lower==song_lower or query_no_punct==song_no_punct:
return [song]
### PARTIAL MATCH - 4 chars or more ###
if (query_lower in song_lower and len(query_lower) >= min_partial_len) or\
(query_no_punct in song_no_punct and len(query_no_punct) >= min_partial_len):
partial_match_songs.append(song)
### LEVENSHTEIN DISTANCE ###
if len(query_no_punct) < len(song_no_punct): ##
window_len = len(query_no_punct)
distance = min(levenshtein(query_no_punct, song_no_punct[i:i+window_len])
for i in range(0, len(song_no_punct)-window_len+1))
else:
distance = levenshtein(query_no_punct, song_no_punct)
if distance < min_distance and distance / len(query_no_punct) < distance_threshold:
min_distance = distance
min_distance_songs = [song]
elif distance == min_distance and distance / len(query_no_punct) < distance_threshold:
min_distance_songs.append(song)
### NUM OF MATCHED TOKEN ###
token_counter = Counter()
for token in query_tokens:
if token in INVERTED_INDEX_SONGTITLE:
token_counter.update(INVERTED_INDEX_SONGTITLE[token])
if len(token_counter) == 0:
max_token_count, token_match_songs = 0, []
else:
max_token_count = token_counter.most_common()[0][1]
token_match_songs = [song for song, count in token_counter.most_common() if count==max_token_count]
## 部分一致が1曲のみの時
if len(partial_match_songs) == 1:
return partial_match_songs
## 単語一致した曲がある時
elif max_token_count >= 1:
return token_match_songs
## 単語一致がなく、部分一致が2曲以上の時
elif len(partial_match_songs) >= 2:
return partial_match_songs
## それ以外の時は最小レーベンシュタイン距離
else:
return min_distance_songs
最後の曲選択のアルゴリズムはまだまだ変更の余地があるのですが、それは今後やっていきます。重要な変更点としては、何曲あるかに関わらず必ず「リストの形として返される」ということです。min_distance_song は閾値を設定したので空リストになることもありますし、完全一致の部分は必ず一曲なのに [song] とリスト化しています。これによって、受け取り側の処理で一々型確認をする必要がなくなり、統一的な処理ができます。
次に返信メッセージ部分です。MessageAction() で各ボタンの表示ラベルと送信テキストを指定して QuickReplyItem オブジェクトのアクションに設定します。その各アイテムは QuickReply オブジェクトの items にリストとして格納し、それを TextMessage の quickReply キーワードに渡します。
クイックリプライのラベルは20文字しか設定できないので、それを超える曲は短くカットしています。また、PC版LINEのバージョン次第ではクイックリプライ機能は使えないので、その場合はスマホ側で行ってください。
## 返信メッセージ
@handler.add(MessageEvent, message=TextMessageContent)
def handle_message(event):
## APIインスタンス化
with ApiClient(configuration) as api_client:
line_bot_api = MessagingApi(api_client)
## 受信メッセージの中身を取得
received_message = event.message.text
## 曲名リスト取得
songtitle = search_song_title(received_message)
## 返信
if len(songtitle) == 0: ## 候補なし
reply = 'NOT FOUND:\nPlease try again with a different words.'
reply = [TextMessage(text=reply)]
elif len(songtitle) == 1: ## 候補1曲のみ
reply = 'https://www.youtube.com/watch?v=' + DATA.loc[songtitle[0], 'official_youtube']
reply = [TextMessage(text=reply)]
else:
quickreply = QuickReply(items=[]) ## クイックリプライインスタンス化
for song in songtitle:
if len(song) > 20: ## ラベル文字最大数
item = QuickReplyItem(action=MessageAction(label=song[:19]+'…', text=song))
else:
item = QuickReplyItem(action=MessageAction(label=song, text=song))
quickreply.items.append(item)
reply = [TextMessage(text='candidate songs:', quickReply=quickreply)]
line_bot_api.reply_message(ReplyMessageRequest(
replyToken=event.reply_token,
messages=reply
))
ここまで修正して、デプロイします。"Get" で検索してみると、複数候補が表示されるのがわかります。
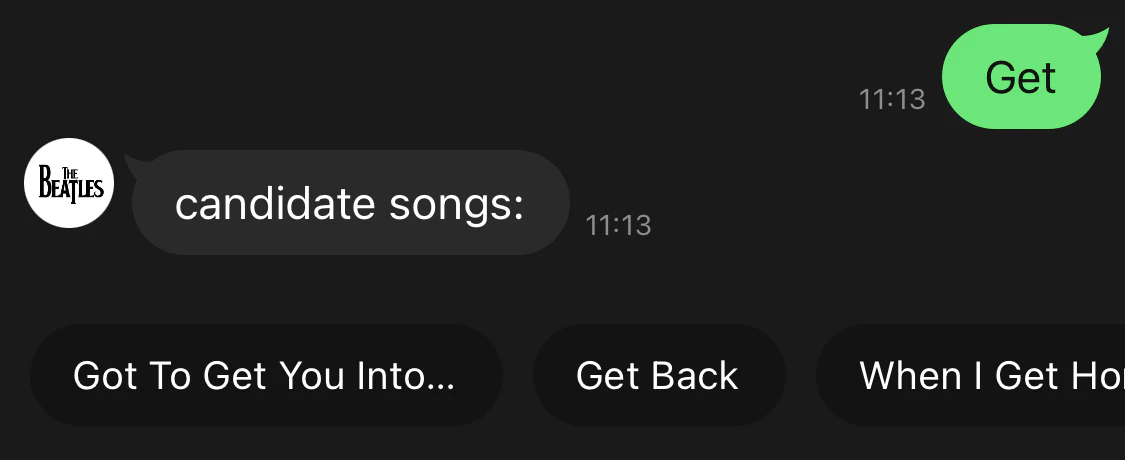
クイックリプライボタンを選択すると、曲名が送信されてYouTubeリンクが取得できます。

マッチしない検索の場合、エラーメッセージを返してくれます。

今回まででコードがだいぶ長くなってしまったので、全コードはもう載せません。↓にもありますが、GitHub レポジトリ の、older_versions/no4 を参照して下さい。ちなみに README は全然書いていません笑
次回は、開発をする上でのコツやお役立ちツールなどを紹介していきます。
目次 : [無料][2024年版] LINE Messaging API v3 + Python(Flask) でボットを作る
GitHub レポジトリ
older_version 内に、各回時点での app.py と requirements.txt があります。