AIエージェントを使いこなすための「コンテキスト」入門ガイド
~「記憶喪失の天才」と協業するための技術~

AIエージェント(Coding Agent。例:Claude Code, Cursor, Windsurf, GitHub Copilotなど)を使いこなす上で、 「コンテキスト(文脈・背景情報)」 の質は、AIの出力品質を決定づける最も重要な要素です。
本記事では、AIエージェント初学者の方に向けて、コンテキストの重要性、具体的な設定方法、そしてAIを「ただのチャットボット」から「自律的なパートナー」へと進化させるためのワークフローを詳細に解説します。
はじめに
- ITエンジニア初学者向けに作成した記事です。
- この記事はAIによるレビューを得て作成しています。
- 記事中の画像はAIを利用して作成しています。
- 筆者は大事なのはAIに対しての思いやりだと確信しています。
序章:AIは「記憶喪失の優秀な新人」

AIエージェントを、以下のような人物だと想像してください。
「技術力はシニア級に高いが、昨日までの記憶がなく、あなたのプロジェクトのことも全く知らない新人エンジニア」
彼らに正確な仕事をしてもらうためには、 「今、何について話していて、どんなルールに従うべきか」 を常に明確にセットし続ける必要があります。これが「コンテキストを与える」ということです。
適切なコンテキストがなければ、AIは一般的な(しばしばあなたのプロジェクトには合わない)コードを書き散らすだけです。しかし、適切なコンテキストを与えれば、彼らはあなたのプロジェクト専属の熟練エンジニアとして振る舞い始めます。
この記事の対象読者と前提

- 対象: 初心者エンジニア(AIエージェントを初めて/触り始めた人)
- ゴール: 「1タスクを最短で終わらせる」ための、コンテキスト投入の型を身につける
- 前提: ツールによって「できること」が違います
- チャット型(例: Copilot Chat): 基本は提案・会話中心
- エージェント型(例: Calude Code/Cursor/WindsurfのAgent): ファイル参照/検索/(設定次第で)コマンド実行まで可能
- 注: この記事の「自律調査」「コマンド実行」は、主にエージェント型を想定しています
- コード例の前提: 主にJavaScript/TypeScript(Web開発寄り)の例を使います(他言語でもだいたい“型”は同じです)
- この記事の手順でVC6, VB6, Unity2019のコードや、独自フレームワークも扱わせることができるようになります
【初心者向けに最重要】 まずはこれだけ:60秒クイックスタート

VSCode + ClaudeCode、Cursor 等で動かしてみてください。
1) 参照ファイルを3点だけ用意する(Active Context)
- 変更したいファイル(対象)
- 依存ファイル(どれか1つ): 型定義・API呼び出し・共通部品(Input/Buttonなど)
- 参照(Reference)ファイル(お手本): 似たUI/似た処理が既にあるもの
2) 後述のコピペ用テンプレをコピペして依頼する(Instruction)
- コツ: まず「A. 理解チェック」→ 「B. 実装許可」、の順にする
コピペ用テンプレ
A. 理解チェック(まだコードを書かせない)
あなたはシニアエンジニアとして振る舞ってください。
以下のファイルを読んでください:
- 変更対象: <ファイル名>
- 依存: <ファイル名>
- 参照(Reference): <ファイル名>
やりたいこと:
- <目的を1〜3行>
制約:
- 既存の命名/スタイル/構成を踏襲
- エラーハンドリング方針: <例: 例外は上位で握る / nullは早期return>
- テスト: <例: 可能ならユニットテスト追加>
お願い:
- まず「私の意図の要約」と「実装ステップ(箇条書き)」だけ出してください。コードはまだ書かないでください。
B. 実装許可
先の実装ステップに従って変更してください。以下も一緒に出力してください。
- 変更箇所の一覧
- 追加/更新するテスト
- 影響範囲(壊れやすい点)の注意
依存ファイルの選び方
迷ったらこの順を参考にしてください。
- UI変更: 対象コンポーネント + 参照(Reference)コンポーネント + 共通UI部品(Input/Buttonなど)
- API/データ不具合: 対象呼び出し元 + APIクライアント + 実レスポンスJSON(あれば最強)
- バリデーション: フォーム + スキーマ/型 + 表示コンポーネント(エラーメッセージの出し方)
- さらに一段だけ具体化(おすすめ):
- 依存の範囲: 「直接importされているもの + その型定義 + API境界(クライアント/route/controller等)」まで
- 迷ったら: まず“直接import”を優先(依存が深いほどノイズが増えます)
ログ/JSON/スクショを渡す前のマスキング 【重要】
- 絶対に伏せる: アクセストークン、Cookie、APIキー、メール、電話番号、住所、氏名、社内URL/リポジトリの秘密情報
- 迷ったら: まず該当箇所を
*に置換してから渡す - 目的: 「現実(ファクト)共有」は強力ですが、情報漏えいは一発アウトです
第1章:コンテキストの3つの階層
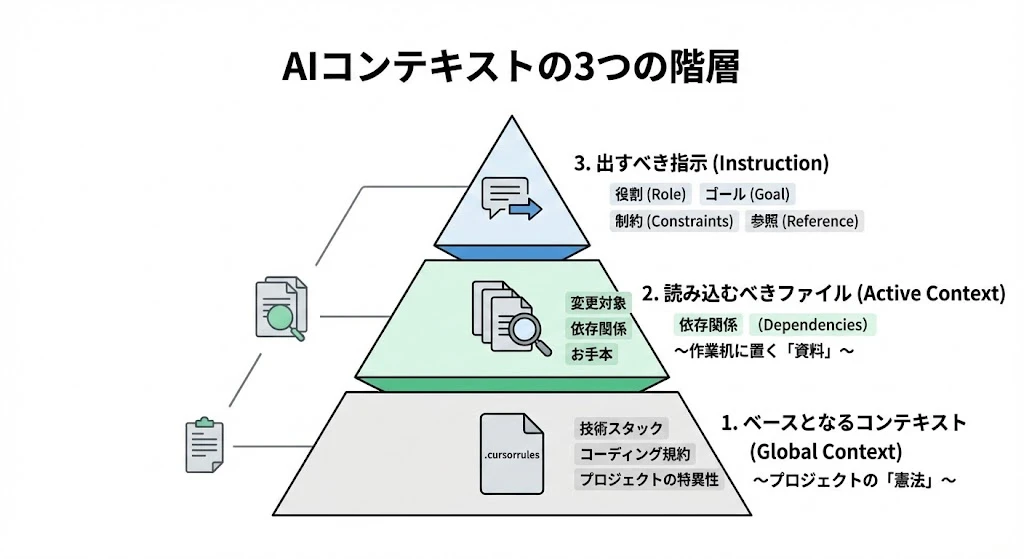
AIエージェントにおけるコンテキストは、ピラミッドのように積み重なる3つの層で構成されています。これらを意識的に管理することが最初のステップです。
1. ベースとなるコンテキスト(Global Context)
~プロジェクトの「憲法」~
会話の最初から常に適用されるべき、プロジェクト全体の基本ルールです。これを設定ファイル(.cursorrules, .windsurfrules 等)に定義しておくことで、毎回同じ指示をする手間が省けます。
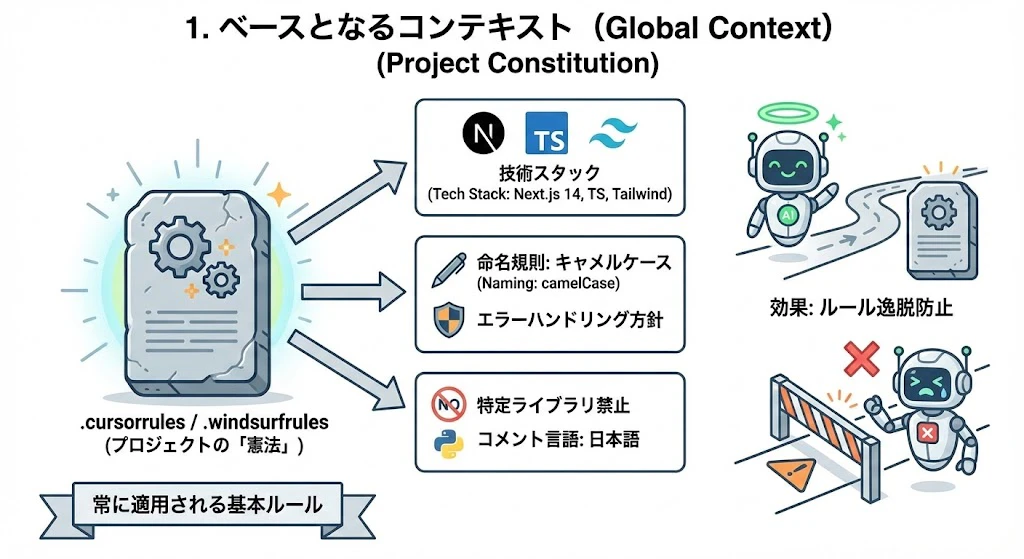
- 定義場所:
.cursorrules,.windsurfrules, システムプロンプト設定 - 含めるべき情報:
- 技術スタック: フレームワーク、言語、ライブラリのバージョン(例: Next.js 14, TypeScript, Tailwind CSS)
- コーディング規約: 命名規則、使用するコンポーネントの種類、エラーハンドリングの方針(例: 関数型コンポーネント必須、変数はキャメルケース)
- プロジェクトの特異性: 特定ライブラリの使用禁止、コメントの言語指定など
- 効果: AIが勝手に古い構文を使ったり、禁止されているライブラリを使ったりするのを防ぎます。
2. 読み込むべきファイル(Active Context)
~作業机に置く「資料」~
AIが特定のタスクを実行するために「今すぐ参照する必要がある資料」です。ここでのファイル選定がAIの回答精度を左右します。
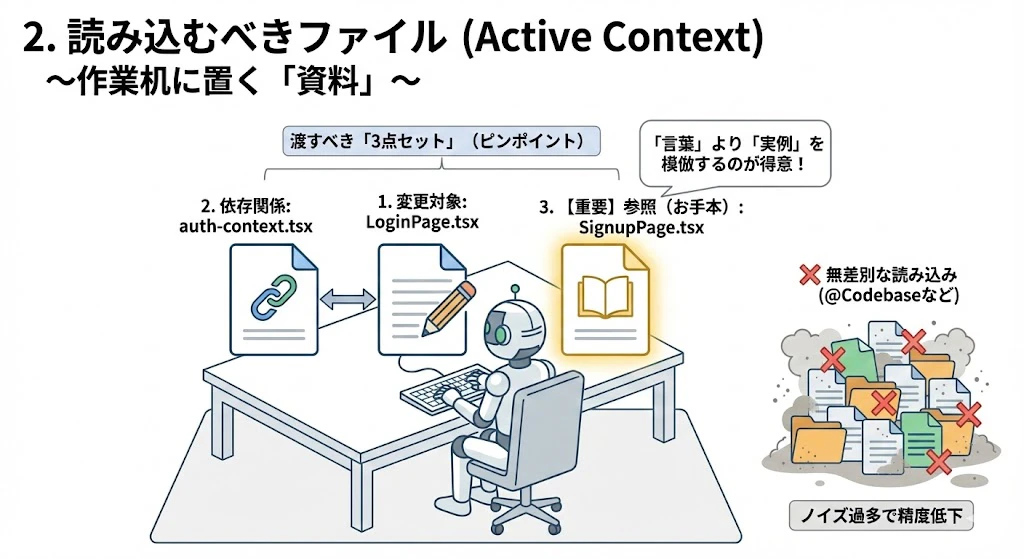
- 渡すべき「3点セット」:
- 変更対象のファイル: 編集したいファイルそのもの(例:
LoginPage.tsx) - 依存関係のあるファイル: そのファイルがインポートしているロジックや型定義(例:
auth-context.tsx) - 【重要】参照(Reference)となる「お手本」ファイル :
- これが最も強力なテクニックです。
- 似たような機能やデザインが実装済みのファイル(例: すでに完成している
SignupPage.tsx)を渡します。 - AIは「言葉での指示」よりも「コードの実例」を模倣する能力に長けています。
- 変更対象のファイル: 編集したいファイルそのもの(例:
- 注意点: プロジェクト全体(
@Codebaseなど)を無差別に読み込ませると、ノイズが増えて精度が落ちます。 「必要なものだけをピンポイントで」 渡すのが鉄則です。
3. 出すべき指示(Instruction)
~具体的な「作業命令」~
AIに対する具体的なチャットでの指示です。曖昧な指示は曖昧な結果を生みます。
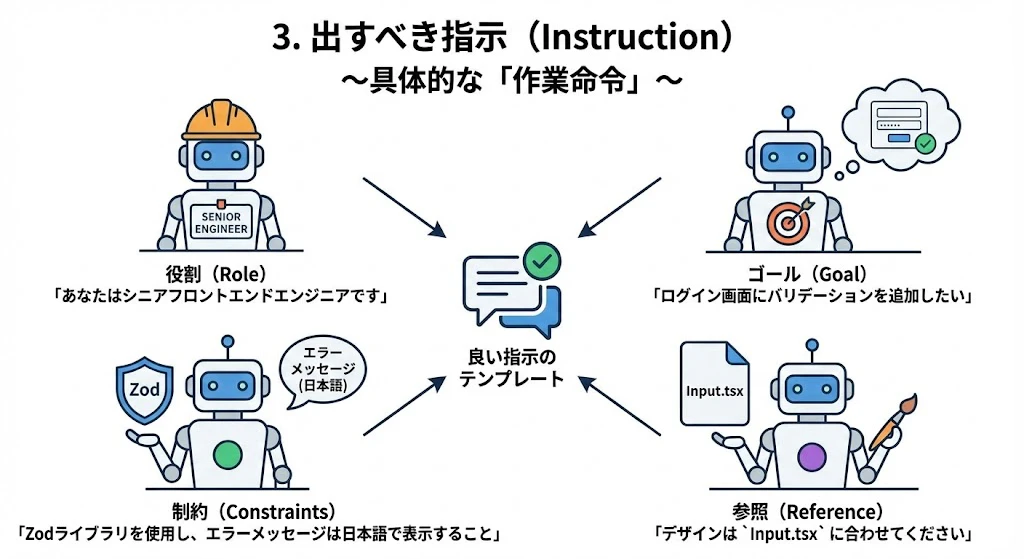
- 良い指示のテンプレート:
- 役割 (Role): 「あなたはシニアフロントエンドエンジニアです」
- ゴール (Goal): 「ログイン画面にバリデーションを追加したい」
- 制約 (Constraints): 「Zodライブラリを使用し、エラーメッセージは日本語で表示すること」
- 参照(Reference): 「デザインは
Input.tsxに合わせてください」
第2章:コンテキストを維持する日々のワークフロー
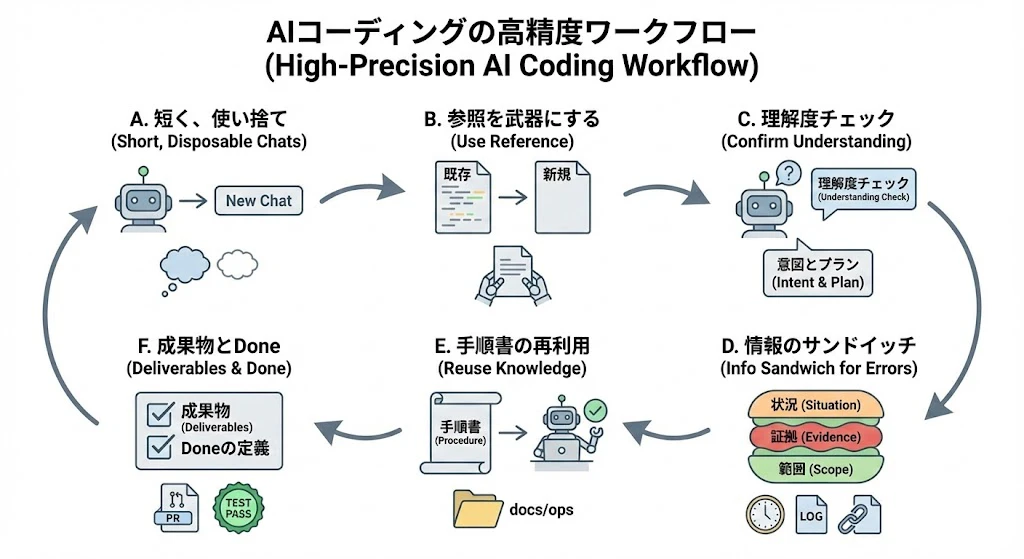
日々のコーディングでコンテキストを汚染させず、高精度を保つための具体的なアクション(Workflow)です。
A. チャットセッションは「短く、使い捨て」にする(1タスク・1チャット)
AIのコンテキストウィンドウ(短期記憶)には限界があります。会話が長引くと、AIは初期の重要なルールを忘れたり、途中の試行錯誤(間違ったコード)に引きずられたりします。
- ルール: 1つのタスク(機能実装やバグ修正)が終わったら、 必ず新しいチャット(New Chat)を開く 。
- 感覚: ノートのページをめくる感覚で、常に真っ白な状態で次のタスクを始めます。
B. 「参照(Reference)」を武器にする
新しい機能を作るとき、ゼロから書かせるのではなく、常に「既存の類似コード」をコンテキストに入れます。
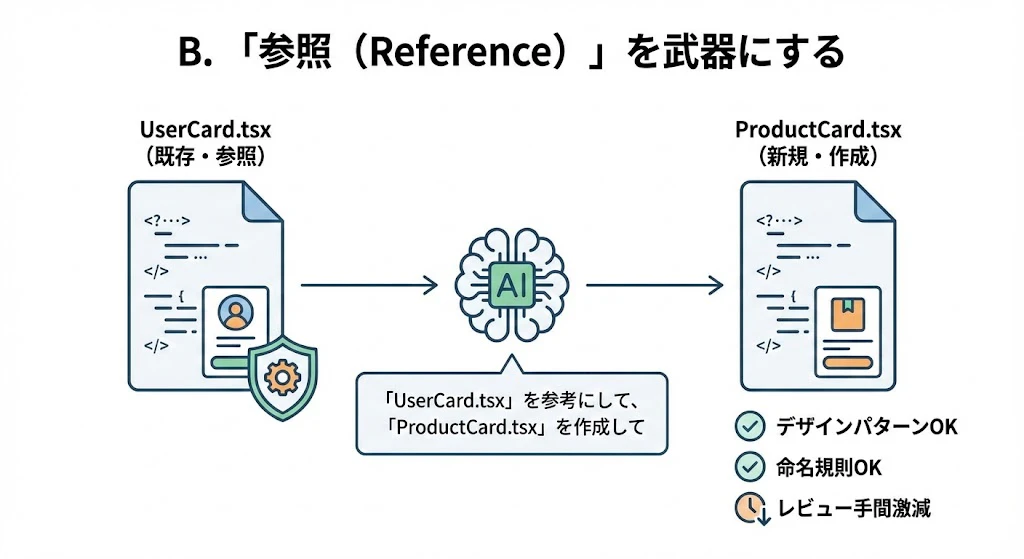
- 指示例: 「
UserCard.tsx(既存)を参考にして、同じスタイルとロジック構造でProductCard.tsx(新規)を作成して」 - 効果: プロジェクトのデザインパターンや命名規則が自動的に守られ、レビューの手間が激減します。
C. AIに「理解度チェック」をさせる
複雑な指示を出す場合、いきなりコードを書かせず、まずコンテキストを正しく理解しているか確認します。

- 魔法のプロンプト:
「これから機能Xを実装します。関連ファイルを読み込んで、コードを書く前に、私の意図とあなたの実装プランをまず言葉で説明してください 」
- 効果: AIの認識ズレを未然に防ぎ、誤った方向への暴走(コンテキスト汚染)による手戻りを防げます。
D. エラー修正時の「情報のサンドイッチ」
エラーが出た際、エラーログだけを貼り付けるのは不十分です。以下の3点をセットで提供します。
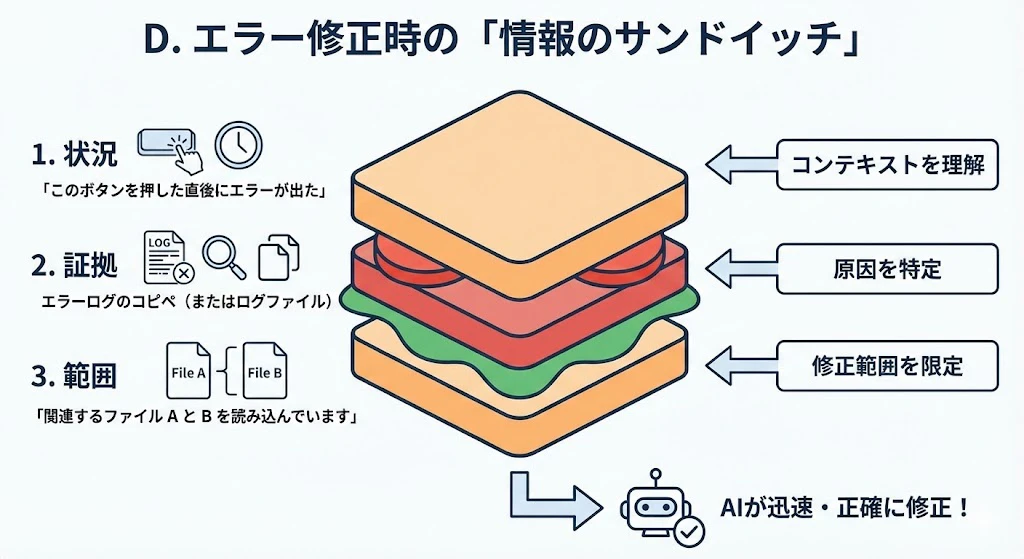
- 状況: 「このボタンを押した直後にエラーが出た」
- 証拠: エラーログのコピペ(またはログファイル)
- 範囲: 「関連するファイル A と B を読み込んでいます」(範囲はAIの足がかりとなる情報です)
E. 「手順書」による成功パターンの再利用 (Knowledge Reuse)
一度成功した複雑な作業(例:ビルド手順、コンテナ構築手順、デプロイ手順、特定のライブラリ導入、DBマイグレーション)は、その手順をドキュメントとして残し、次回以降の強力なコンテキストとして利用します。
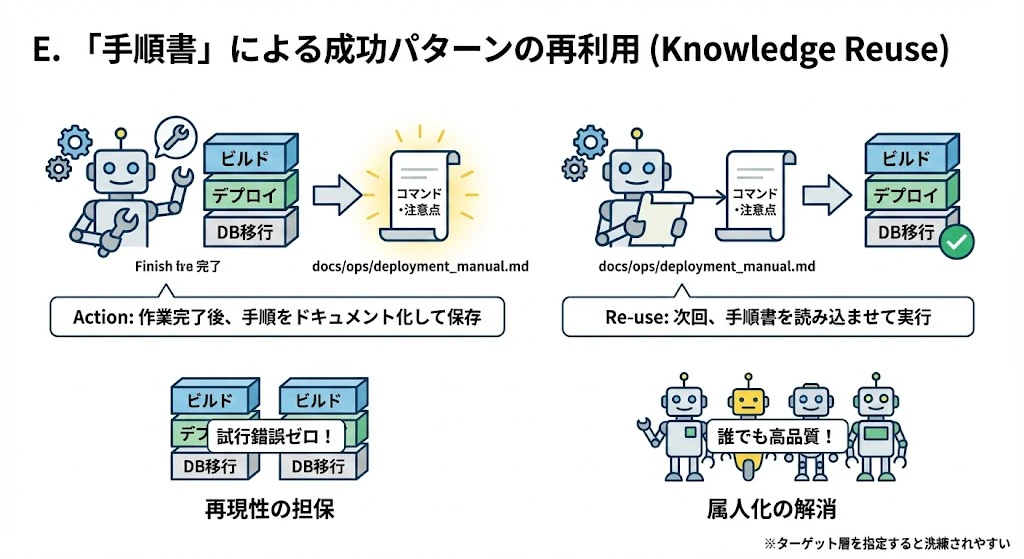
- Action: 作業完了後、AIに「今回の作業手順を再現可能な形(コマンドや注意点含む)で
docs/ops/deployment_manual.mdにまとめて」と指示し、ファイルを保存します。 - Re-use: 次回、同様の作業を行う際に、そのドキュメントをコンテキストとして読み込ませ、「この手順書に従って実行して」と指示します。
- Effect:
- 再現性の担保: 「前回どうやったっけ?」という試行錯誤がゼロになります。
- 属人化の解消: 誰が(あるいはどのAIが)やっても同じ高品質な結果が得られます。
※ このとき、ドキュメントのターゲット層を指定するとドキュメントが洗練されやすいです。
F. 成果物とDoneの定義(運用に落とす)
曖昧な「動いた気がする」を避けるため、最低限の“期待する出力”と“Done”を決めます。
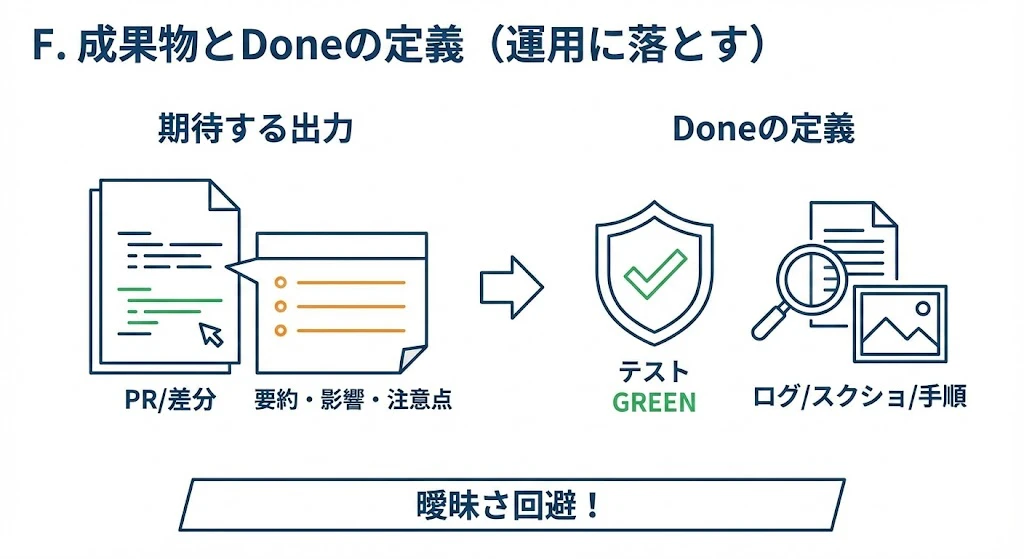
- 期待する出力(例):
- 変更はPR(または差分)単位で提示される
- 変更点の要約・影響範囲・壊れやすい点が併記される
- Doneの定義(例):
- テストが
GREEN(少なくとも該当範囲のユニットテスト/静的解析が通る) - 必要ならログ/スクショ/再現手順が添付される
- テストが
※ playwrite等で、e2eテストを作ると実現しやすいです。
G. その他の高度なコンテキスト共有テクニック
さらに精度を高めるための、情報の「渡し方」の工夫です。
G-1. プロジェクトの「地図」を共有する (Tree Structure)
AIは全体像を見るのが苦手です。「どこにファイルを置くべきか」を正しく判断させるために、ディレクトリ構造図を渡します。

- Action:
tree -L 2 -I "node_modules|.git" > project_structure.txtを実行し、このテキストファイルを読み込ませます。 - Effect: プロジェクトの構成意図(どこに何があるか)をAIが理解し、適切な場所にファイルを配置してくれます。
- Claude Code, Cusror 等のAIエージェントはこの作業を行ってくれる場合がほとんどです。AIエージェントが読み込んでくれない場合は、「プロジェクト全体を確認してから」などを付加すると、読み込んでくれることが多いです。読み込んでくれないなら Action のように自分で渡すか、「treeコマンドで全体を読んでください」とワンショットの会話を挟みます。
G-2. 「用語集」で言葉の定義を揃える (Glossary)
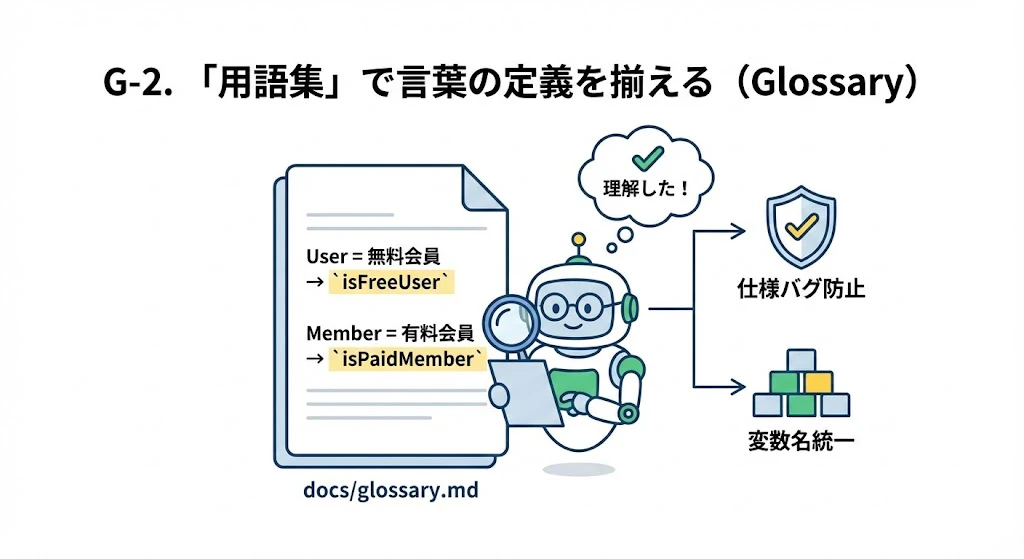
特定の業務知識(ドメイン知識)が必要な場合、言葉の定義ファイルを作ります。
- Action:
docs/glossary.mdを作成。「User=無料会員、Member=有料会員とする」のように定義し、変数名のルールとしても適用させます。 - Effect: 「意味の取り違え」による仕様バグや、変数名の不統一を完全に防げます。
G-3. 「擬似コード」でロジックの骨子を伝える (Pseudo Code)
日本語で長々と説明する代わりに、ざっくりとしたロジックだけのコード(擬似コード)を渡します。
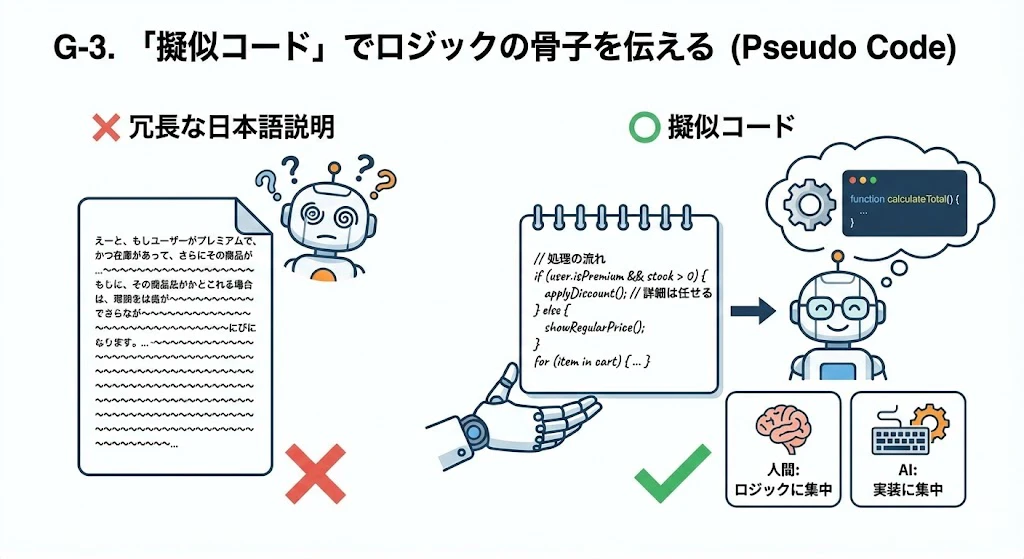
- Action: 「詳細は任せるけど、処理の流れはこうして」と、
ifやforを使ったメモ書きを渡します。- Effect: AIは実装の詳細(構文やエラー処理)に集中でき、人間はロジックの正しさに集中できます。
H. 『現実(ファクト)』を共有する入出力テクニック
AIはコード(設計図)は見えても、実際の画面やデータ(現実)は見えません。入出力を共有することで、このギャップを埋めます。
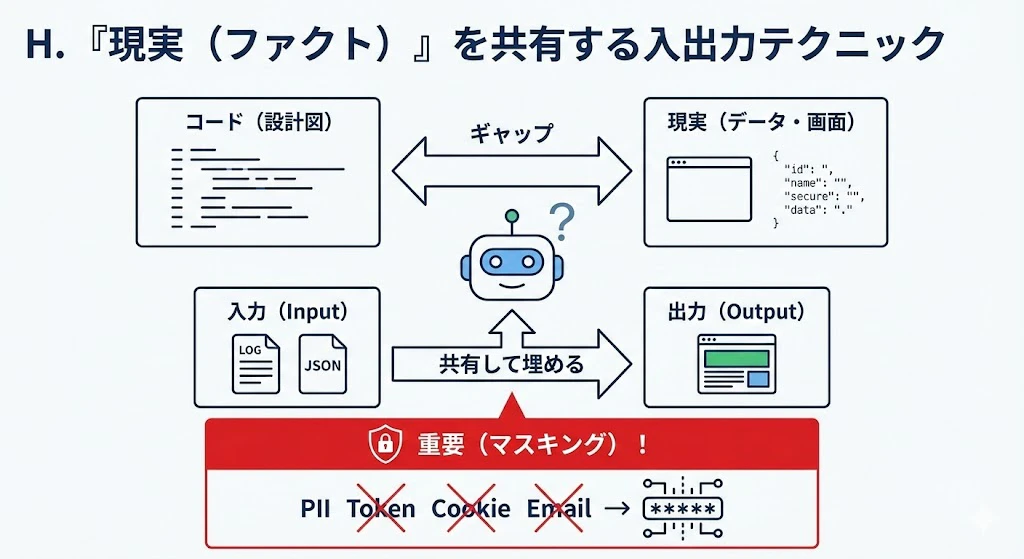
重要(マスキング): ログ/JSON/スクショにはPII(個人情報)やトークンが混入しやすいです。共有前に、アクセストークン・Cookie・APIキー・メール・電話番号・住所・氏名・社内URLなどを
*に置換してください。
H-1. ログファイルの直接参照と解析 (Direct Log Analysis)
エラーログをチャット欄にコピペするのは非効率です。長いログは省略されたり、AIのトークン制限を圧迫したりします。
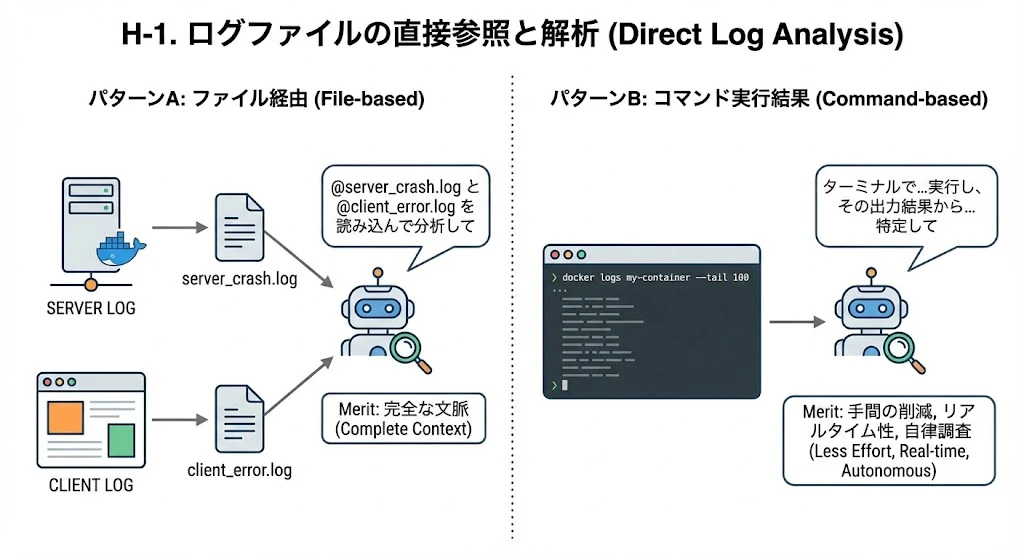
パターンA: ファイル経由で渡す(汎用的な方法)
- Action:
- サーバー/コンテナログ:
docker logs my-container > docs/logs/server_crash.logのようにファイルに書き出します。 - クライアントログ: ブラウザコンソールを
client_error.logとして保存します。 - 指示: 「
@server_crash.logと@client_error.logを読み込んで分析してください」と、ファイルを直接コンテキストとして渡します。
- サーバー/コンテナログ:
- Merit:
- 完全な文脈: AIはログの全文(エラー発生前の警告など)を含めて解析できます。
パターンB: コマンド実行結果を直接読ませる(Cursor/Windsurf等の場合)
- Action: チャット欄やターミナル連携機能を使って、コマンドの結果を直接コンテキストに入れます。
- 指示: 「ターミナルで
docker logs my-container --tail 100を実行し、その出力結果からエラーの原因を特定してください」
- 指示: 「ターミナルで
- Merit:
- 手間の削減: わざわざファイルを作る必要がありません。
- リアルタイム性: 最新のログを即座に解析対象にできます。
- 自律調査: エージェント機能を持つAIなら、
grep等を使って巨大なログから必要な行を自ら探し出せます。
H-2. データの正体を見せる (JSON Dump)
「データが表示されない」という時、型定義(interface)だけ渡しても解決しません。実際のデータ構造が違うことが多いからです。
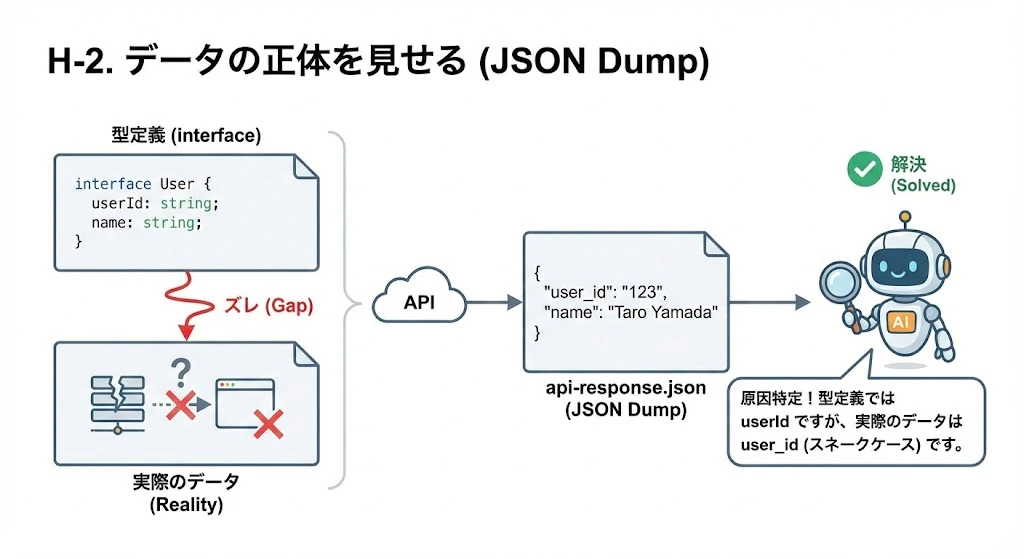
- Action: 実際にAPIから返ってきた生データ(JSON)を
api-response.jsonとして保存し、直接読み込ませます。 - Effect: 「型定義では
userIdですが、実際のデータはuser_id(スネークケース) で返ってきています」といった原因特定が一瞬で終わります。
H-3. 「見た目」を見せる (Screenshots)
CSSの崩れを言葉で説明するのは困難です。
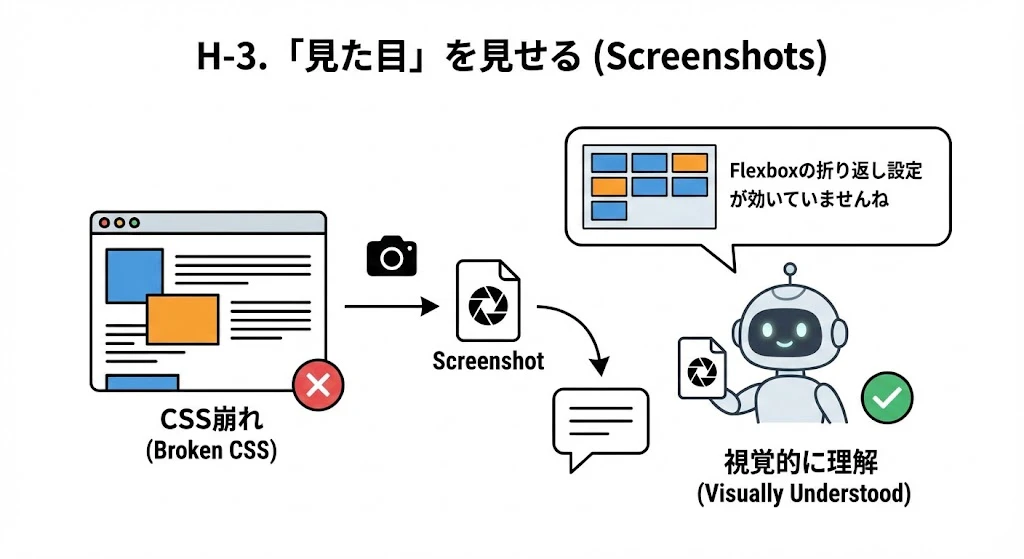
- Action: 崩れている画面のスクリーンショットを撮り、そのままチャットに貼り付けます(マルチモーダル対応AIの場合)。
- Effect: 「Flexboxの折り返し設定が効いていませんね」と、視覚的に問題を理解してくれます。
H-4. テストによる入出力の自動検証 (Automated Verification)
「動いた気がする」で終わらせず、テストコードという「動く仕様書」を使って、入出力の正しさを自動的に保証させます。
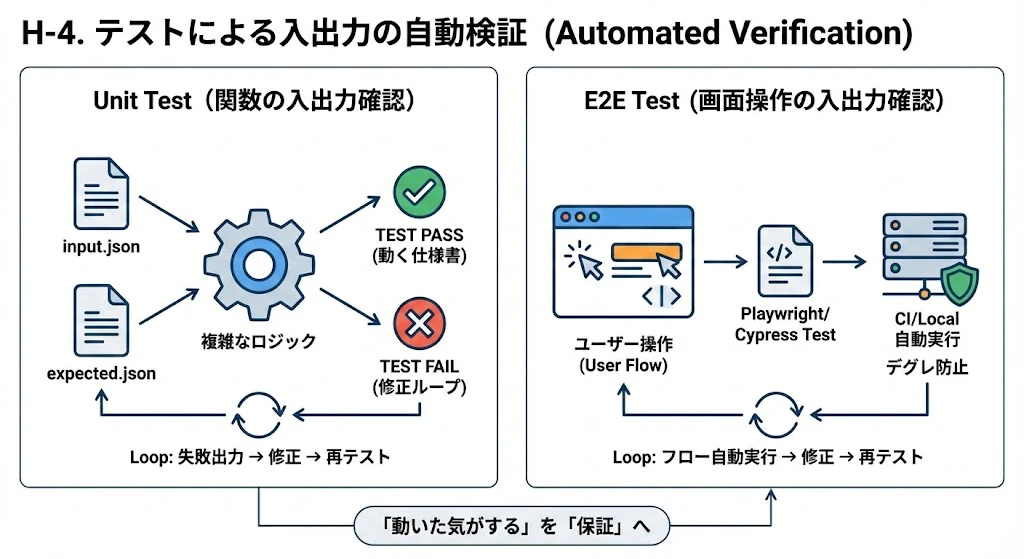
- Unit Test(関数の入出力確認):
- Action: 複雑なロジック(計算やデータ変換)の場合、「この入力(
input.json)に対し、この結果(expected.json)を返すユニットテストを作成して」と指示します。 - Loop: テストを実行し、失敗時の出力結果をファイルで渡して修正させます。
- Action: 複雑なロジック(計算やデータ変換)の場合、「この入力(
- E2E Test(画面操作の入出力確認):
- Action: ユーザーの一連の操作(クリック、入力、遷移)が正しく機能するか、PlaywrightやCypressなどのE2Eテストで検証させます。
- Loop: 「ログインして記事を投稿するまでのフロー」をテスト化し、CIやローカルで自動実行することで、修正によるデグレ(破壊)を防ぎます。
I. AIのためのロギング戦略 (Logging for AI)
デバッグ時にAIが迷わないよう、「AIに読ませることを前提としたログ出力」 をコードに仕込んでおくテクニックです。

I-1. 構造化ログ(JSONログ)の導入
AIにとって、自由な文章形式のログよりも、キーと値が明確なJSON形式の方が解析精度が格段に上がります。
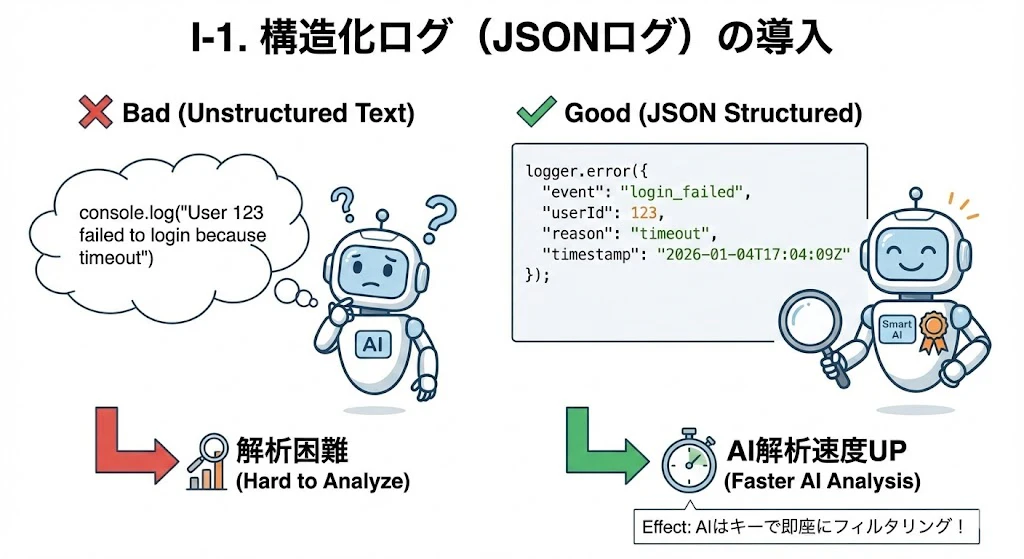
- Good:
console.log("User " + userId + " failed to login because " + reason) - Bad:
logger.error({ event: "login_failed", userId: userId, reason: reason, timestamp: new Date().toISOString() }); - Effect: AIは
event: "login_failed"などのキーで即座にフィルタリングでき、原因分析の速度が向上します。
I-2. コンテキスト情報の付与
エラーログ単体では情報不足です。AIが「その時何が起きていたか」を推論できるよう、変数の状態も一緒に出力します。
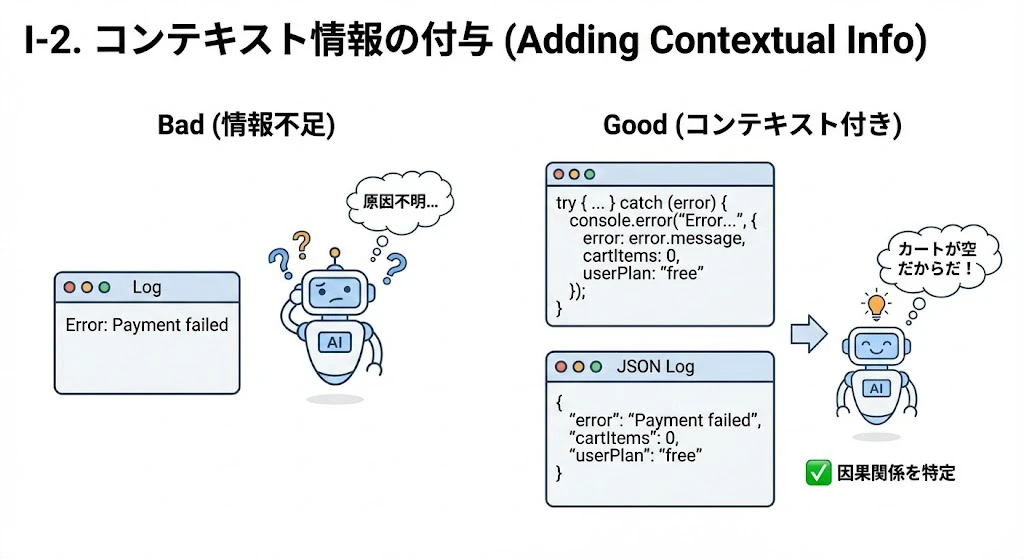
- Action: エラーハンドリング箇所で、関連する変数をダンプします。
try { // ...処理... } catch (error) { console.error("Error in processPayment:", { error: error.message, cartItems: cart.items.length, // カートの中身の数 userPlan: user.plan, // ユーザーのプラン inputData: input // 入力されたデータ }); } - Effect: 「カートが空だったからエラーになった」というような因果関係を、AIがログから直接読み取れるようになります。
第3章:[応用編] エージェント型ワークフローとDDDA
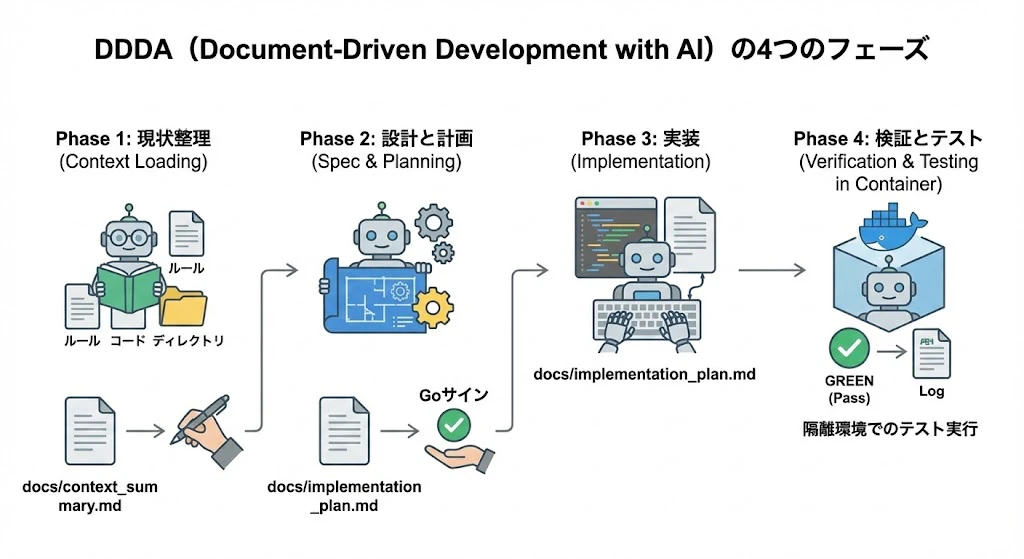
AIを単なるチャットボットとしてではなく、「手を動かして検証まで行うエンジニア」として扱う手法です。これを DDDA (Document-Driven Development with AI) と呼びます。
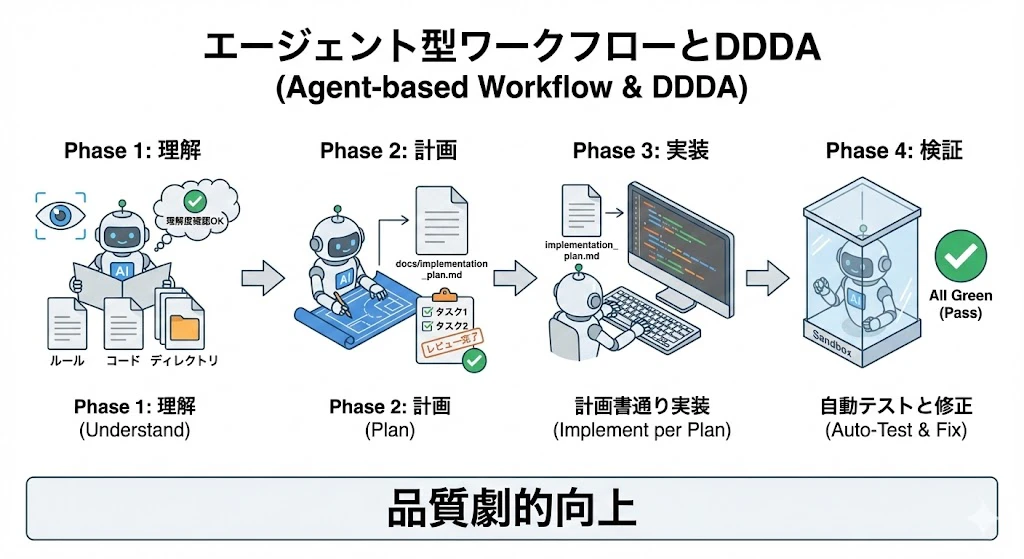
DDDAの4つのフェーズ
いきなりコードを書かせず、「理解→計画→実装→検証」のプロセスをAIに踏ませることで、品質を劇的に向上させます。
Phase 1: 現状整理 (Context Loading)
まずは手を動かさず、AIに「状況認識」をさせます。
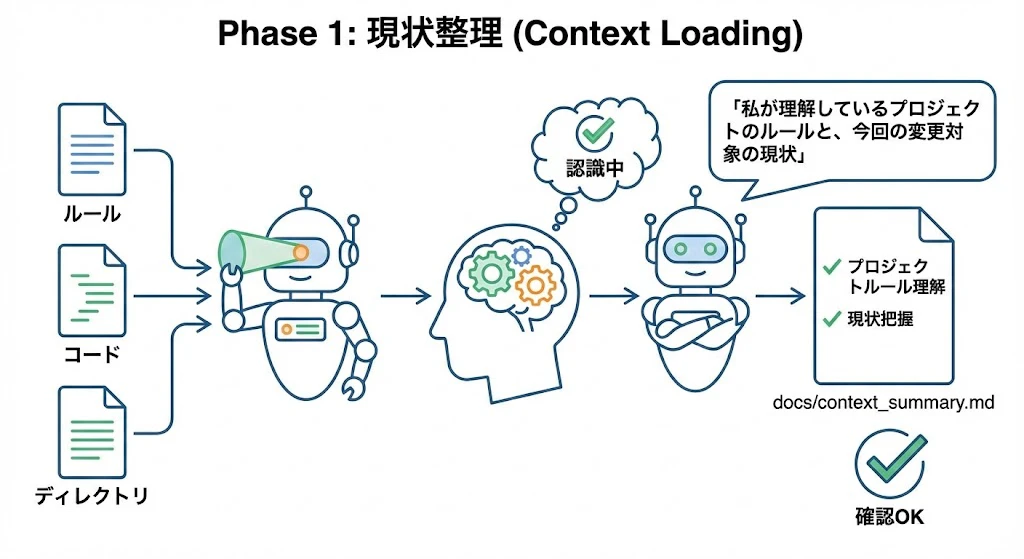
- Action: プロジェクトのルール、関連コード、ディレクトリ構成を読み込ませる。
- Output:
docs/context_summary.md- AIに「私が理解しているプロジェクトのルールと、今回の変更対象の現状」を書かせ、認識のズレがないか人間が確認します。
Phase 2: 設計と計画 (Spec & Planning)
コードを書く許可をまだ出しません。次に「計画」を立てさせます。
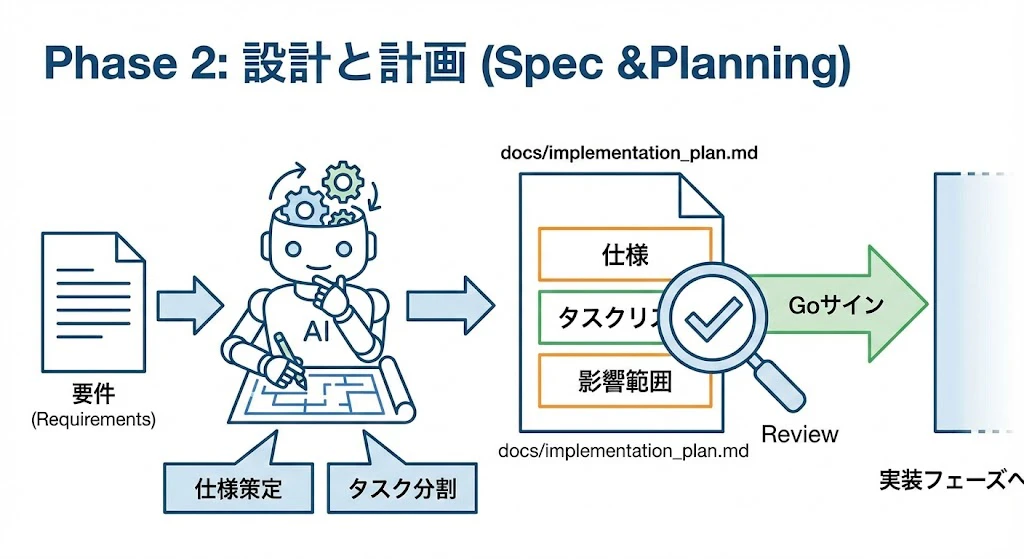
- Action: 要件を伝え、仕様策定とタスク分割を行わせる。
- Output:
docs/implementation_plan.md(実装計画書)- 仕様、タスクリスト、影響範囲を記述させます。
- Review: 人間がこのドキュメントをレビューし、「Goサイン」を出して初めて実装フェーズへ移行します。
Phase 3: 実装 (Implementation)
計画書に従ってコードを書きます。
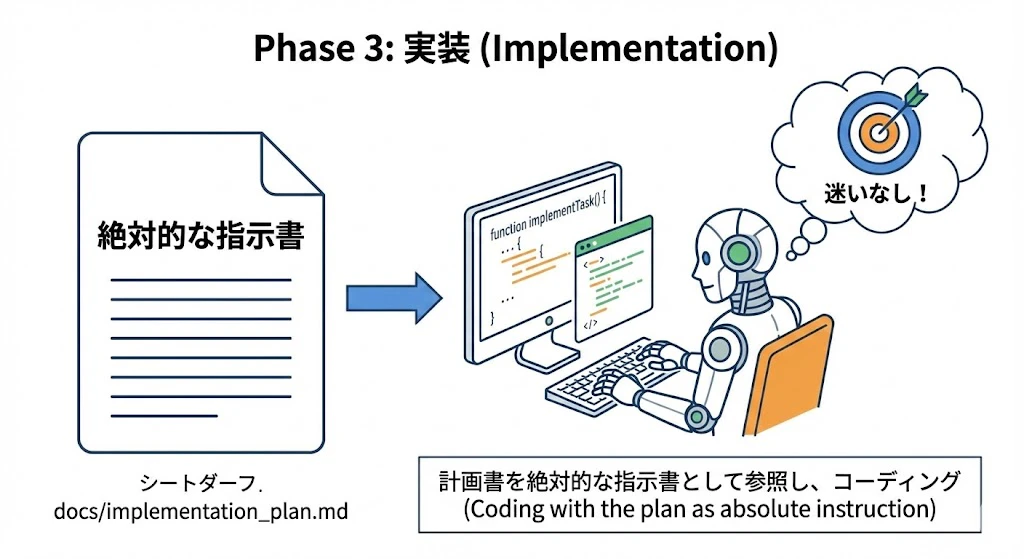
- Action: AIは
docs/implementation_plan.mdを「絶対的な指示書」として参照しながらコーディングします。迷いやブレがなくなります。
Phase 4: 検証とテスト (Verification & Testing in Container)
「動いた気がする」で終わらせず、テストコードで証明させます。特にDockerコンテナなどの隔離環境で行うのが理想的です。
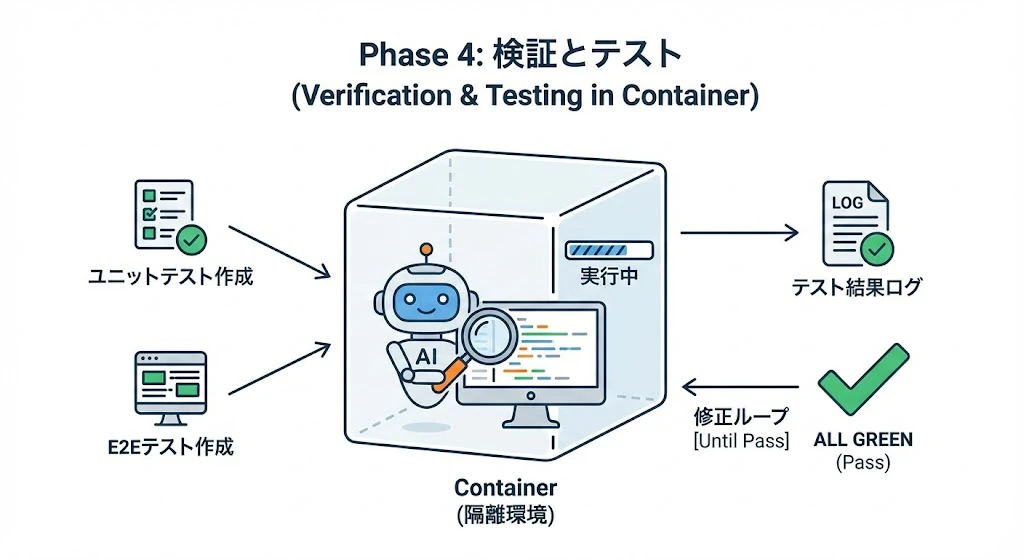
- Action: ユニットテストとE2Eテストを作成・実行させる。
- Output: テスト結果のログ。全てが
GREEN(Pass) になるまでAIに修正させます。
第4章:ステップアップのための応用テクニック (Advanced Tips)
基本を押さえた上で、さらにコンテキストの「鮮度」と「純度」を保つための実用的なテクニックです。
- 読み方:
- まず見出しだけ眺め、気になる項目から拾い読みでOKです。
- 実務で詰まった時は「いま困っている種類(UI/API/バグ/運用)」に近い項目だけ適用してください。
1. 「コンテキストの掃除」と要約リセット (Context Pruning)
チャットが長くなると、初期の指示が薄れたり、途中の間違った試行錯誤の履歴がノイズとなって回答精度が落ちます。
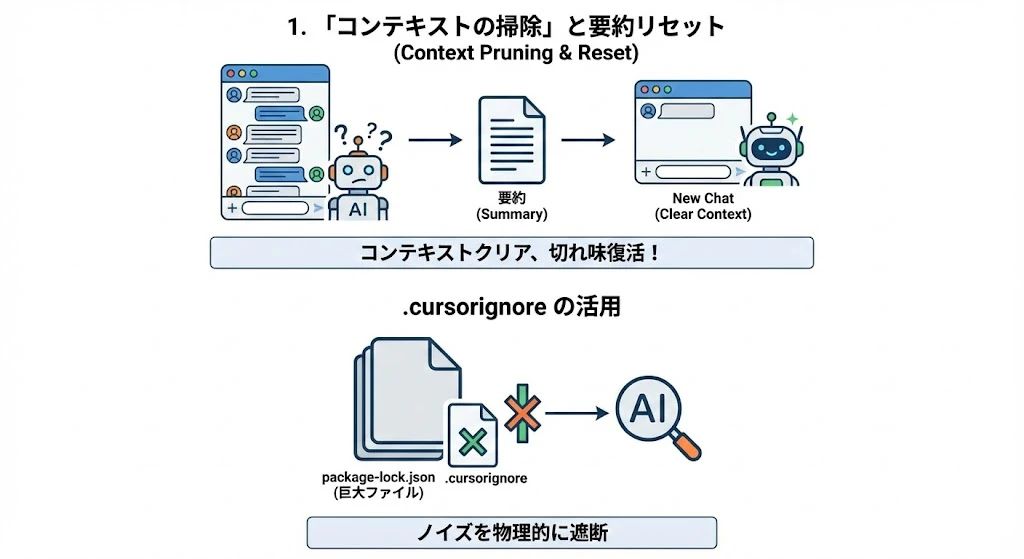
- 要約リセット (Summary & Reset):
- 会話が20往復を超えたら、AIに「これまでの経緯、決定事項、次のタスクを要約してください」と指示します。
- その要約文をコピーし、New Chat を開いて最初のプロンプトとして貼り付けます。
- これにより、脳内メモリ(コンテキストウィンドウ)がクリアになり、AIの切れ味が復活します。
-
.cursorignoreの活用:- 巨大な自動生成ファイル(
package-lock.jsonなど)や、AIに見てほしくないファイルを.cursorignoreに定義し、検索ノイズを物理的に遮断します。
- 巨大な自動生成ファイル(
2. プロジェクト固有の「知識ベース」 (Docs-as-Context)
人間用ではなく、「AIに読ませる専用のドキュメント」 をプロジェクト内に配置します。
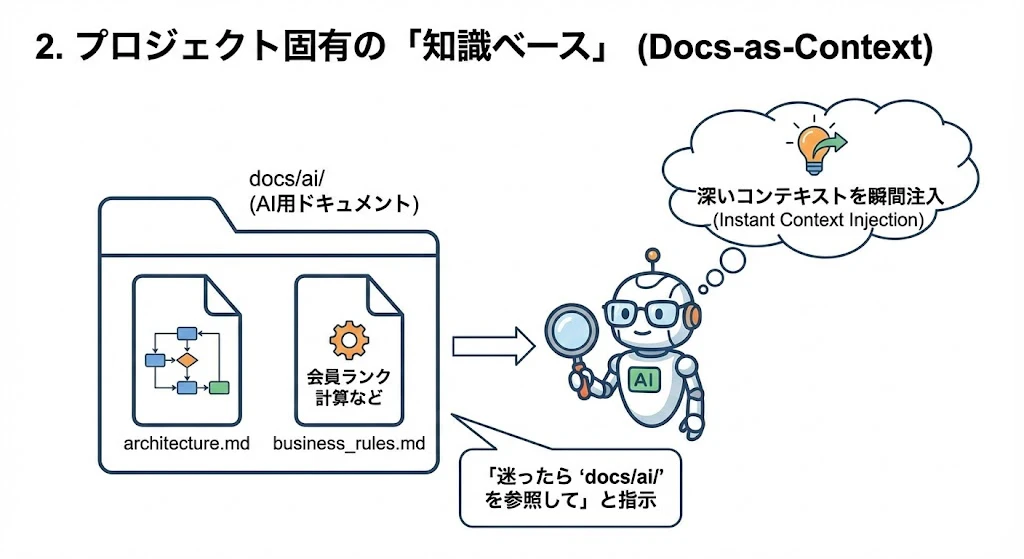
- Action:
docs/ai/ディレクトリを作成し、Markdownファイルを置きます。-
docs/ai/architecture.md: システム構成図やデータフローの説明。 -
docs/ai/business_rules.md: 「会員ランクの計算ロジック」など、コードからは読み取りにくいビジネスルール。
-
- Effect: 迷った時に「
docs/ai/以下のルールを参照して」と指示するだけで、深いコンテキストを一瞬で注入できます。
3. コメント駆動開発 (Comment-Driven Development)
コードを書かせる前に、詳細な「コメント」だけを先に書くことで、AIの補完精度を極限まで高める手法です。

- Method: 実装したい関数の上に、JSDoc形式で仕様を書きます。
/ * ユーザーのランクを計算する関数 * - 入力: 購入履歴(History[]) * - ルール: * - 直近3ヶ月の購入額が10万円以上なら "Gold" * - それ以外で5万円以上なら "Silver" * - それ以外は "Bronze" * - 例外: Historyが空の場合は "Bronze" */ // ここにカーソルを置くと、AIが仕様通りのコードを自動生成します - Merit: チャットで長々と説明するよりも、コードの中に仕様が残るため、メンテナンス性が向上します。
4. マルチモーダル入力の活用 (Visual Context)
テキストだけでなく「画像」をコンテキストとして使います。
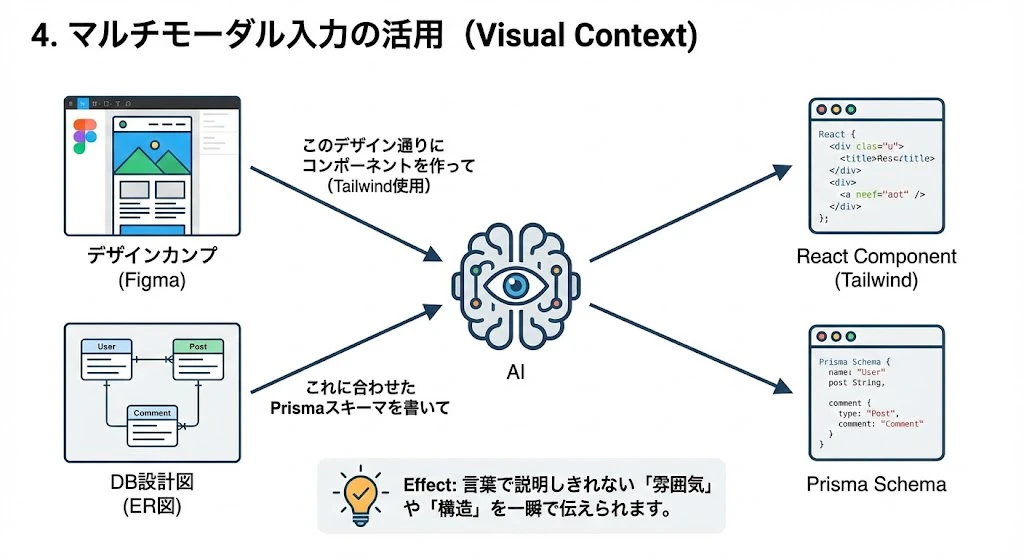
- デザインカンプ: Figmaのデザイン画を貼り付け、「このデザイン通りにコンポーネントを作って(Tailwind使用)」と指示。
- DB設計図: ER図のスクショを貼り付け、「これに合わせたPrismaスキーマを書いて」と指示。
- Effect: 言葉で説明しきれない「雰囲気」や「構造」を一瞬で伝えられます。
5. ルールファイルの「育成」 (Iterative Refinement)
.cursorrules などの設定ファイルは、一度作って終わりではありません。
- Action: AIがコーディング規約違反や好ましくない実装をした際、その場で修正させるだけでなく、「なぜ間違えたか」をルールファイルに追記します。
- Effect: プロジェクトが進むにつれてAIが学習(ルールが最適化)し、同じミスをしなくなります。これは「AIを育てる」感覚に近いです。
6. AIフレンドリーなコード構造 (AI-Friendly Structure)
人間にとって読みやすいコードは、AIにとっても読みやすい(コンテキストとして理解しやすい)コードです。
- Action:
- ファイルを小さく保つ: 1ファイル300行程度を目安にします。AIに関連ファイルとして読み込ませる際、トークン節約になります。
- 命名を具体的にする:
dataやhandlerといった曖昧な名前ではなく、userProfileDataやsubmitRegistrationHandlerのように、名前だけで中身が推測できるようにします。
- Effect: ファイル名や関数名だけで内容を推論できるようになり、中身を全部読まなくても正しい提案ができるようになります。
7. 「肯定形」で指示する (Positive Instructions)
AI(LLM)は仕組み上、「~しないで(否定形)」という指示よりも、「~して(肯定形)」という指示に従いやすい特性があります。
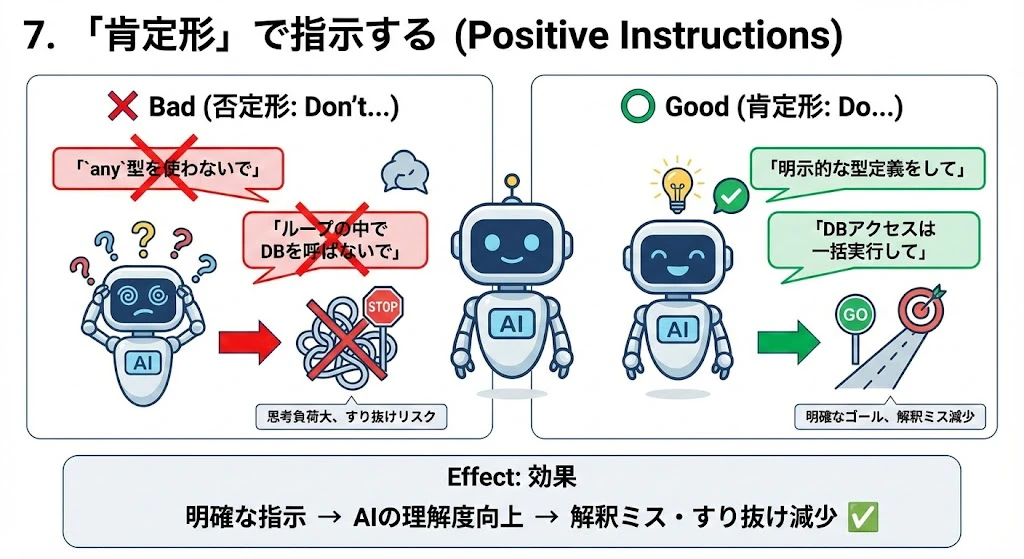
- Bad: 「
any型を使わないでください」「ループの中でDBを呼ばないでください」 - Good: 「すべての変数に明示的な型定義をしてください」「DBアクセスはループの外で一括実行してください」
- Effect: 指示の解釈ミスや、禁止事項のすり抜けが減ります。
8. ペルソナ(役割)の詳細定義 (Persona Locking)
単に「エンジニア」とするのではなく、具体的なレベル感や思想を定義することで、出力コードの品質基準(ベースライン)を引き上げます。
- Action:
.cursorrulesやシステムプロンプトに以下のように記述します。あなたはGoogleのL5(シニア)ソフトウェアエンジニアとして振る舞ってください。
あなたは「Clean Architecture」と「SOLID原則」の熱心な信奉者であり、可読性とテスタビリティを最優先します。 - Effect: AIが「動けばいいコード」ではなく、「保守性の高いプロフェッショナルなコード」を提案する確率が上がります。
9. 「思考の連鎖」を促す (Chain of Thought)
複雑なアルゴリズムや設計を依頼する際、いきなり答えを出させると間違えやすいです。
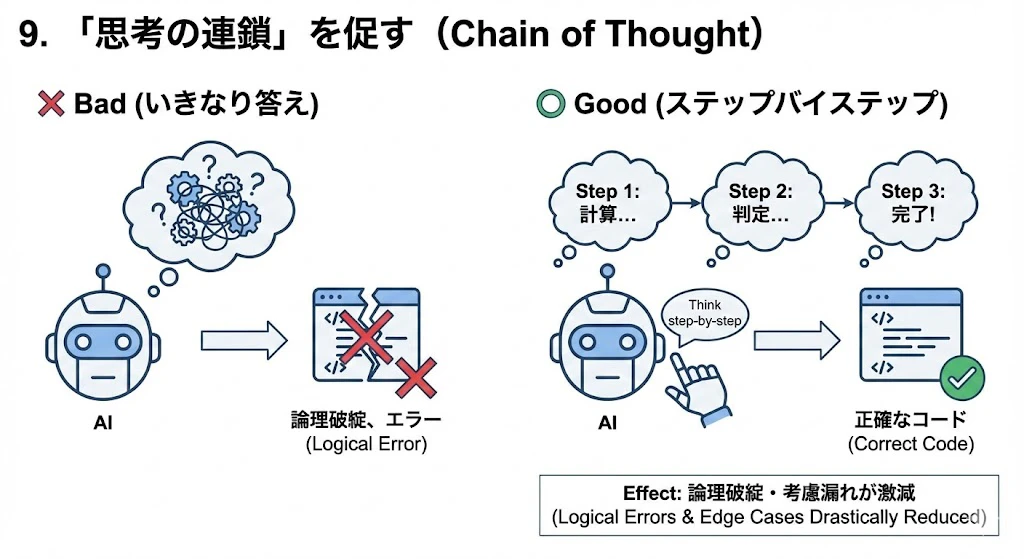
- Action: 指示の最後に 「ステップバイステップで考えてください (Think step-by-step)」 と一言添えます。
- Effect: AIが内部的に推論プロセス(Step 1: まずこれを計算し... Step 2: 次に判定し...)を経てからコードを出力するため、論理破綻やエッジケースの考慮漏れが激減します。
第5章:ストーリーで学ぶコンテキスト・マネジメント
~新人エンジニア「ケンタさん」の成長記録~
理論だけではイメージしにくい部分も、具体的な「成功ストーリー」と「失敗ストーリー」を比較すると、なぜコンテキストが重要なのかが肌感覚でわかるようになります。
架空の新人エンジニア「ケンタさん」が、ブログアプリ開発を通してAIの扱い方を学んでいく成長の記録です。
Episode 1: コンテキスト不足の「あてずっぽう開発」
(失敗パターン)
ケンタさんは急いでいました。「とりあえずAIに投げればなんとかなるだろう」と思い、チャットを開いてすぐにこう打ち込みました。
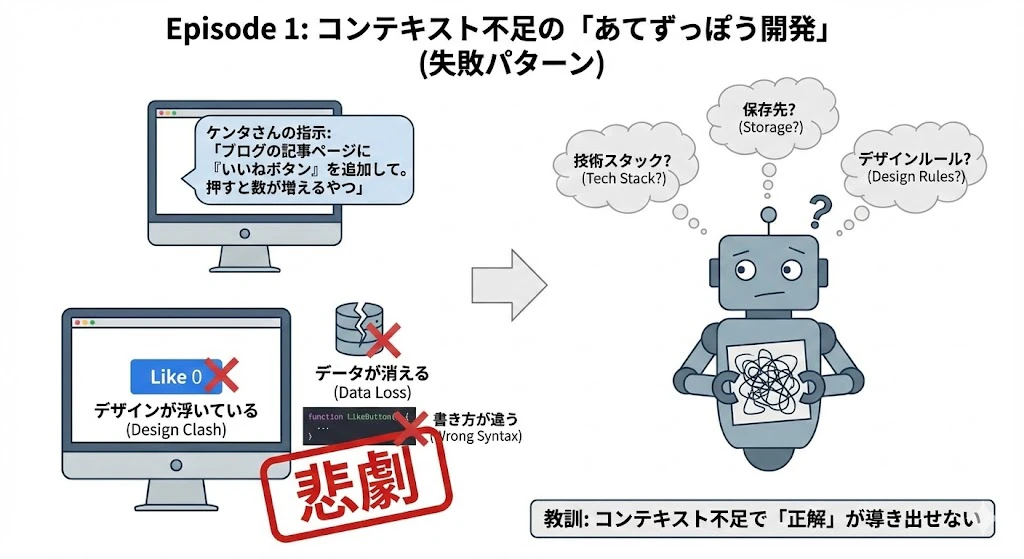
- ケンタさんの指示:
「ブログの記事ページに『いいねボタン』を追加して。押すと数が増えるやつ」
- AIの思考 (コンテキストなし):
(うーん、このプロジェクトのルールがわからないな…とりあえず一般的なReactの書き方で作ろう。デザインも普通のCSSでいいか)
- 結果 (悲劇):
- デザインが浮いている: サイト全体はオシャレなTailwind CSSなのに、ボタンだけ普通の青いHTMLボタンになった。
- データが消える: ページを更新すると「いいね」の数が0に戻る(サーバーに保存せず、その場だけの変数で作ってしまった)。
- 書き方が違う: チームでは Arrow Function を使う決まりなのに、AIは古い function 構文で書いてしまった。
教訓: コンテキストの3階層(技術スタック、保存先、デザインルール)が全て欠けていたため、AIは「正解」を導き出せませんでした。
Episode 2: コンテキスト・フル装備の「爆速開発」
(成功パターン)
ケンタさんは反省し、気を取り直して 「新しいチャット」 を開きました。そして、コンテキストを整える準備をしました。

- 準備(コンテキスト):
-
.cursorrulesに「Next.js, Tailwind使用」「データ取得はSWR」と明記されていることを確認。 - お手本ファイル (
CommentSection.tsx) を読み込ませる(ここにはすでに良い感じのアイコン付きボタンがある)。 - ロジックファイル (
useLikeApi.ts) を読み込ませる。
-
- 依頼(Instruction):
「
BlogPost.tsxにいいねボタンを追加してください。
デザインは読み込んでいるCommentSection.tsxの返信ボタンと 全く同じスタイル(色、サイズ、ホバー挙動) にし、アイコンだけハートマークに変えてください。
ロジックはuseLikeApi.tsのtoggleLike関数を使ってください」
- AIの思考 (コンテキストあり):
(なるほど!
.cursorrulesがあるからTailwindを使うんだな。デザインはCommentSection.tsxをコピーしてアイコンだけ変えれば完璧だ。ロジックも指定通りにつなぎこもう) - 結果 (成功):
- 出力されたコードは、サイトのデザインに完全に馴染み、機能も正しく動作する完璧なボタンでした。ケンタさんがやったのは、生成されたコードを「Accept(適用)」するだけです。
教訓: 「お手本ファイル」を渡すことは、言葉で100回説明するより効果的です。
Episode 3: エラー発生!からの「文脈共有リカバリー」
(トラブルシューティング編)
順調かと思いきや、ボタンを押した瞬間に 500 Internal Server Error が発生しました!

- 悪い対処法:
- ケンタ: 「エラーが出た!直して!」
- AI: 「コードを見せてくれないとわかりませんが、とりあえずサーバーを再起動してみては?」(解決しない)
- 良い対処法 (コンテキスト重視):
- ケンタさんは落ち着いて、「情報のサンドイッチ」 を作りました。
- 上 (状況): 「ログインしていない状態で『いいね』を押したらエラーが出ました」
- 中 (証拠): エラーログのコピペ
Error: User ID is null... - 下 (範囲): 「サーバー側の
route.tsと DB定義のschema.prismaを読み込んでいます。修正案を出してください」
- AIの反応:
「ログとコードを確認しました。
schema.prismaによるとLikeテーブルにはuserIdが必須ですが、route.tsでログインチェックが漏れていました。修正コードを提示します」
教訓: エラーログだけではなく、「どこで」「何をした時」という文脈をセットで渡すことで、AIは名医になります。
Episode 4: ログファイルという名の「捜査資料」
(高度なログ共有テクニック)
その後、ケンタさんは「記事保存時に画面がフリーズする(エラーも出ない)」という難解なバグに遭遇しました。

- ケンタさんのアクション:
- 「これは根が深い」と直感し、コピペではなく 「証拠資料のファイル化」 を行いました。
- クライアントの証言: ブラウザのコンソールログを
browser-console.logに保存。 - サーバーの証言: バックエンドのターミナルログを
server-debug.logに保存。
- AIへの指示:
「2つのログの時刻を突き合わせて、クライアントがリクエストを送った瞬間にサーバー側で何が起きているか(あるいは起きていないか)を分析し、原因を特定してください」
- AIの分析 (名探偵モード):
「分析しました。ブラウザからはリクエストが出ていますが、サーバー側に着信ログがありません。その直前に
Database connection pool is fullという警告が出ています。DB接続数上限によるフリーズです」 - 結果: コード修正ではなく、設定ファイルの数値を変更するだけで5分で解決しました。
教訓: AIは現場(実行環境)を見ることができません。ログファイルという「動かぬ証拠」を渡すことで、AIに現場検証をさせることができます。
Episode 5: 見えないデータの可視化
(JSON共有とスクショ活用)
ログ分析でサーバーは直りましたが、今度は「画面にユーザー名が出ない」上に「スマホで見るとレイアウトが崩れる」という問題が発生。
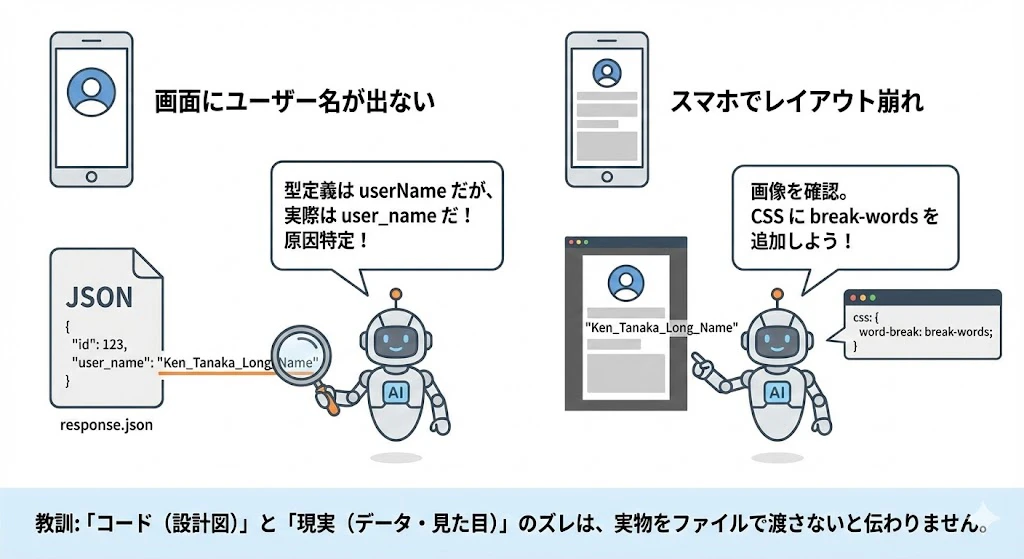
- データの証拠 (JSON):
- ケンタさんは「コードは合ってるはず」と思い、実際のAPIレスポンスを
response.jsonに保存してAIに見せました。 - AI: 「型定義では
userNameですが、実際のJSONはuser_name(スネークケース) ですね。これが原因です」
- ケンタさんは「コードは合ってるはず」と思い、実際のAPIレスポンスを
- 視覚の証拠 (Screenshot):
- 崩れている画面のスクショを貼り付けました。
- AI: 「画像を見ると、長い名前が改行されずに枠を突き抜けています。CSSに
break-wordsを追加しましょう」
教訓: 「コード(設計図)」と「現実(データ・見た目)」のズレは、実物をファイルで渡さないと伝わりません。
Episode 6: 隔離された密室(Dockerコンテナ)での実験
(自律エージェントの活用)
本番環境でのみ発生する「謎のメモリリーク」の調査を任されたケンタさん。ローカルでは再現せず手詰まりです。
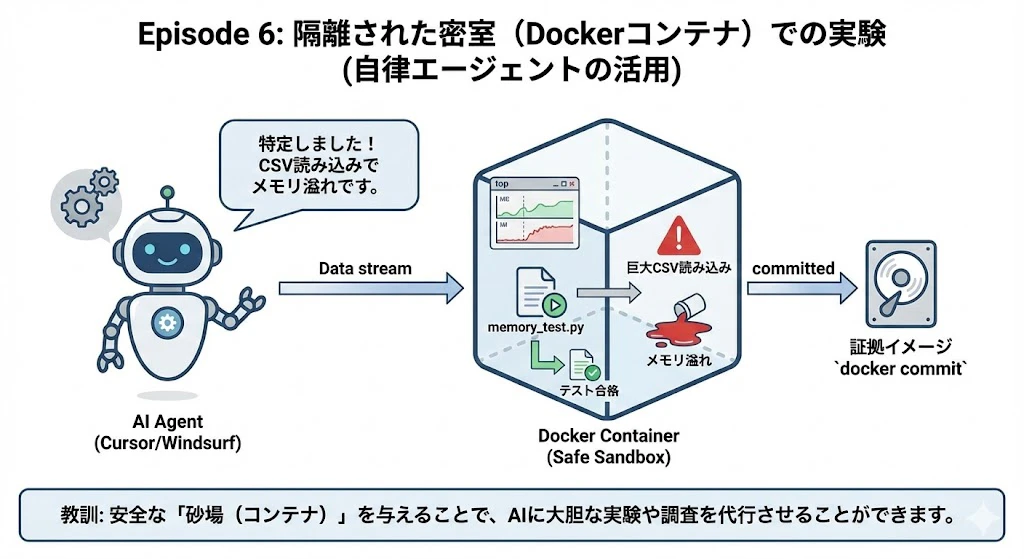
- ステップ1: 本番と同じ環境をDockerコンテナで立ち上げ、AI(Cursor/Windsurf)を接続。
- ステップ2: ケンタさんの指示。
「ここは壊してもいい環境(コンテナ内)です。メモリ使用量を監視しながら、負荷テスト用のPythonスクリプトを自作して実行し、問題箇所を特定してください」
- ステップ3: AIの自律行動。
-
topコマンドで現状確認。 -
memory_test.pyを勝手に作成して実行。 - エラーが出ないので、外部ライブラリを使うパターンに書き換えて再実行。
- 「特定しました。巨大なCSV読み込み時にメモリが溢れています」と報告。
-
- ステップ4: 修正と保存。
- AIに修正させ、再テストで解決を確認。ケンタさんはそのコンテナの状態をイメージとして保存(
docker commit)し、チームリーダーに「動く証拠」として提出しました。
- AIに修正させ、再テストで解決を確認。ケンタさんはそのコンテナの状態をイメージとして保存(
教訓: 安全な「砂場(コンテナ)」を与えることで、AIに大胆な実験や調査を代行させることができます。
Episode 7: 完全分業体制
(DDDA: ドキュメント駆動開発の実践)
最後にケンタさんは、「有料会員限定機能」という重要機能の実装に挑みました。
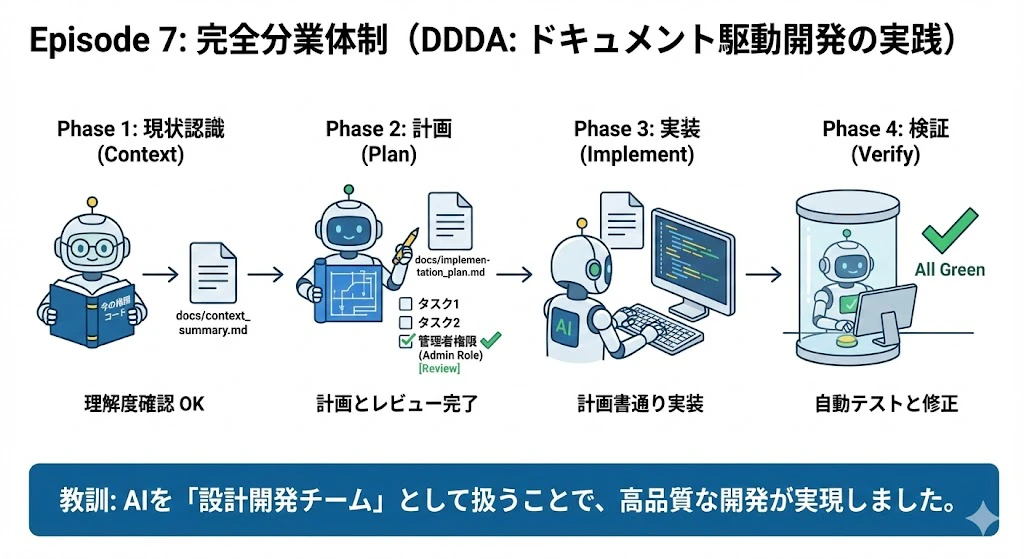
- Phase 1 (現状認識):
- 「今の権限周りのコードを読んで、
docs/context_summary.mdにまとめて」と指示。AIの理解度が正しいか確認。
- 「今の権限周りのコードを読んで、
- Phase 2 (計画):
- 「仕様はこうです。
docs/implementation_plan.mdに実装計画とタスクリストを書いて」と指示。ケンタさんがレビューし、考慮漏れ(管理者権限など)を指摘して修正。
- 「仕様はこうです。
- Phase 3 (実装):
- 「計画書の Step 1 と Step 2 を実装して」と指示。AIは計画書通りに迷わずコーディング。
- Phase 4 (検証):
- 「E2Eテストを書いて、コンテナ内で実行して」と指示。最初はテストが落ちたが、AIが自力で修正し
All Greenに。
- 「E2Eテストを書いて、コンテナ内で実行して」と指示。最初はテストが落ちたが、AIが自力で修正し
教訓: AIを「ただのコーダー」ではなく「設計開発チーム」として扱うことで、手戻りのない高品質な開発が実現しました。
まとめ
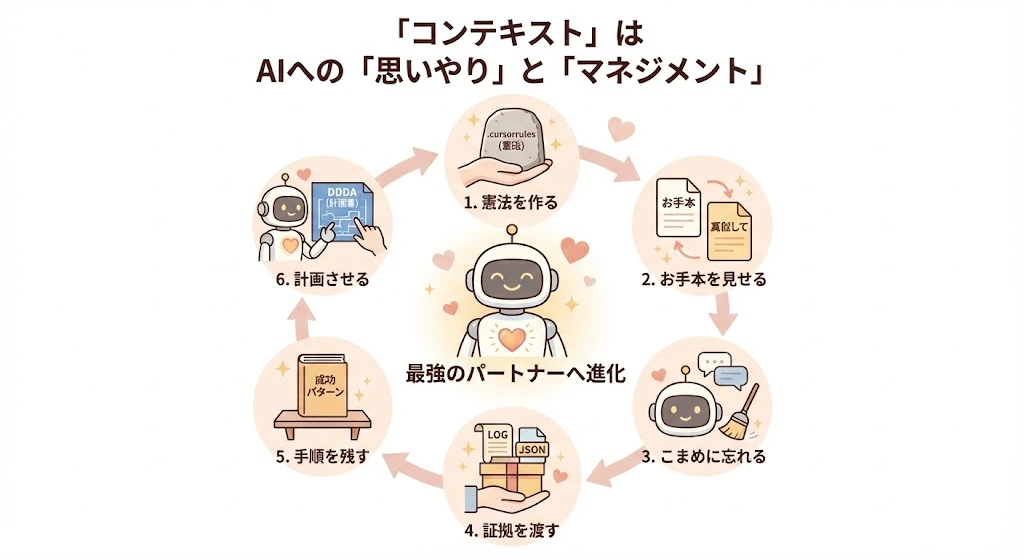
AIエージェントとの協業における「コンテキスト」とは、AIに対する 「思いやり」と「マネジメント」 そのものです。
- 憲法を作る:
.cursorrules等で土台を固める。 - お手本を見せる: 類似ファイルを渡して「真似して」と言う。
- こまめに忘れる: タスクごとにチャットをリセットする。
- 証拠を渡す: ログやJSONデータをファイルで共有する。
- 手順を残す: 成功パターンをドキュメント化し、次回に読み込ませる。
- 計画させる: 複雑なタスクはドキュメント(DDDA)から始める。
このサイクルを回すことで、AIはあなたのプロジェクトを深く理解した、パートナーへと進化します。
さいごに
かんたんでしたね。