はじめに
GPUが載ってないPCでディープラーニングをやってみたい、という人向けです。
機械学習、ディープラーニングの理論はあまりわからずにやってます。
※損失関数グラフの表示等「Raspberry Piではじめる機械学習 基礎からディープラーニングまで」に掲載されているプログラムを元にしています。
環境構築
Anacondaで環境を作成します。
1.Anacondaのインストール
下記のサイトなどを参考にインストールしてください。(既にインストール済みであれば不要です)
https://weblabo.oscasierra.net/python-anaconda-install-windows/
2.仮想環境の作成、アップデート、
1.Anacondaを起動し、「Environment」タブで「Create」ボタンをクリックする
2.Python3.6の環境をを作成する(名前は任意)
3.作成した仮想環境を選択し「Open Terminal」をクリックする
4.起動した仮想環境のコンソールで以下2コマンドを実行する
conda update --all
conda update -n base conda
3.必要なパッケージのインストール
上記手順で起動されていると思いますが、仮想環境のコンソールで以下のコマンドを実行する。(※IDEにSpyderを使う想定でここでインストールしていますが、他のでも構いません)
conda install keras scikit-learn matplotlib pandas spyder
簡単な回帰を試してみる
ディープラーニングは私の理解としてですが、教師データで学習することで、任意の関数を近似できる手法と考えてよいかと思います。
まず初めに、サイン関数を近似してみます。
1.必要なパッケージをインポートします。
import numpy as np
import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.optimizers import Adam
import matplotlib.pyplot as plt
from keras.callbacks import EarlyStopping
2.学習の進捗状況のグラフ表示の関数を定義する(学習後に表示される)
# 損失関数グラフ
def plotHistory(history):
# 損失関数のグラフの軸ラベルを設定
plt.xlabel('time step')
plt.ylabel('loss')
# グラフ縦軸の範囲を0以上と定める
plt.ylim(0, max(np.r_[history.history['val_loss'], history.history['loss']]))
# 損失関数の時間変化を描画
val_loss, = plt.plot(history.history['val_loss'], c='#56B4E9')
loss, = plt.plot(history.history['loss'], c='#E69F00')
# グラフの凡例(はんれい)を追加
plt.legend([loss, val_loss], ['loss', 'val_loss'])
# 描画したグラフを表示
plt.show()
3.学習用のデータを用意する
ネットワークに学習させる特徴量のデータをX、答えとなる教師データをyにセットし、
さらに、それをランダムに並べ替えてから、学習用のデータとテスト用のデータに分割しています。
# 特徴量のセットを変数Xに、ターゲットを変数yに格納
X = np.arange(-10, 10, 0.01)
y = np.sin(X) + (np.random.rand(len(X)) - 0.5) * 0.5
# データの順番を入れ替えるためのランダムなNumPy配列
np.random.seed(10)
indices = np.random.permutation(len(X))
val_len = int(len(X) * -0.1)
# 学習用のデータ。全体から後方の一部データを省いたもの
X_train = X[indices[:val_len]]
y_train = y[indices[:val_len]]
# テスト用のデータ。全体から後方の一部データを取り出したもの
X_test = X[indices[val_len:]]
# y_test = y[indices[val_len:]]
y_test = np.sin(X_test)
4.Kerasのネットワークを定義し、コンパイルする
100個のパーセプトロンを3層定義しています。
入力が1個のnumpy配列なので「input_shape=(1,)」、出力も1個なので「model.add(Dense(units=1))」としています。
学習が完了すると学習済みのモデルデータが「keras_reg_sin.h5」の名前で保存されます。
「useSavedModel = True」に変更することで保存したモデルで予測を行えるようにしています。
savefile = 'keras_reg_sin.h5'
useSavedModel = False
if useSavedModel == False:
# ニューラルネットワークを定義
model = Sequential()
# 中間層と入力層を定義
model.add(Dense(units=100, activation='relu', input_shape=(1,)))
model.add(Dropout(0.1))
model.add(Dense(units=100, activation='relu'))
model.add(Dropout(0.1))
model.add(Dense(units=100, activation='relu'))
model.add(Dropout(0.1))
model.add(Dense(units=1))
# モデルのコンパイル
model.compile(loss='mse', optimizer=Adam(lr=0.001), metrics=['mae'])
#model.compile(loss='mse', optimizer=tf.train.RMSPropOptimizer(0.001), metrics=['mae'])
# モデルの学習
early_stopping = EarlyStopping(monitor='val_loss', mode='min', patience=20)
#history = model.fit(X, y_keras, epochs=4000, validation_split=0.1, batch_size=n_samples, verbose=2)
plotHistory(
model.fit(
X_train, y_train, epochs=300, validation_split=0.1, verbose=2
,callbacks=[early_stopping]
)
)
# 学習結果を保存
model.save(savefile)
else:
# 学習済ファイルを読み込んでmodelを作成
model = keras.models.load_model(savefile)
5.作成したモデルで予測を行い、結果を表示する。
result = model.predict(X_test, verbose=0).flatten()
plt.scatter(X_train, y_train, c='yellow', s=1)
plt.scatter(X_test, result, c='red', s=1)
plt.show()
6.実行する
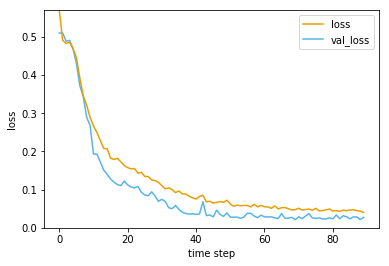
まず以下のようなグラフが表示されます。
「validation_split=0.1」が指定されているので学習データの内1割が学習時に検証用データとして使用されています。
「loss」が学習データへの損失(誤差)、「val_loss」が検証データへの損失と
なりますが、どちらも学習が進むごとに下がっています。学習の際に「epochs=300」と300エポックを上限にしていますが、Earlystoppingの仕組みを入れているため、あまり変化がなくなったところで、学習が自動で終了します。
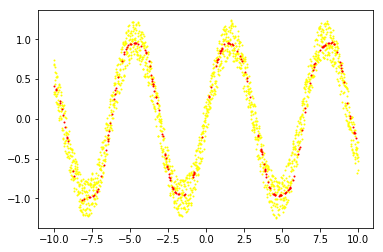
上記グラフの下に、学習データを黄色、予測データを赤で表示するグラフが表示されます。
7.結果について
あまり考慮しないで適当に設定したネットワークですが、高い精度で予測ができることがわかります。
ただ、パラメータの内、学習率(lr=0.001)の部分は上げすぎると収束しないし、下げすぎるとなかなか学習が進まないので、適切な値に設定する必要があります。
8.次回
「UCI Machine Learning Repository」のサンプルデータで、アワビの年齢予測を行います。
https://qiita.com/norikawamura/items/f1134fe6465970a6a819