はじめに
GPUが載ってないPCでディープラーニングをやってみたい、という人向けです。
「Kerasでとりあえず動かしてみるディープラーニング#1」で作ったプログラムを改変します。
https://qiita.com/norikawamura/items/f748b9bbf597a5953235
CSVデータで回帰を行う
1.サンプルデータの用意
「UC Irvine Machine Learning Repository」からアワビ(abalone)に関するデータを取得します。
下記のURLから「abalone.data」「abalone.names」の2ファイルをダウンロードします。
https://archive.ics.uci.edu/ml/machine-learning-databases/abalone/
2.サンプルデータの確認
abalone.namesがデータの内容の説明、abalone.dataが実際のデータのCSVファイルになっています。
一番最後の列のRingsの値を予測します。
こちらの記事で知りましたが、実際の年齢はこれを1.5で割るようです。
https://qiita.com/tomo_20180402/items/a519fcc0aba6de03824e
2.PandasでCSVからデータを読み込む
前回の記事の「3.学習用のデータを用意する」の部分の前に以下のコードを追加します。
ヘッダー行が無いCSVなので「header=None」を指定しています。
import pandas as pd
# CSVからデータを読み込む
filename = 'abalone.data'
ab_data = pd.read_csv(filename, header=None)
3.学習用のデータを用意する
最初の列が「I」「F」「M」の文字になっているため、これを0~の整数に変更するための関数を定義します。
# クラス文字列の数値化
def classtonum(c):
if c == 'I':
return 0
if c == 'F':
return 1
if c == 'M':
return 2
else:
return -1
~.valuesでnumpy配列を取り出し、一番最後の列を教師データ、それ以前の列を特徴量データになるように切り出します。
特徴量データ「X」の1列目を数値に変える処理を行った後、前回同様に学習用、テスト用に分割します。
# 特徴量のセットを変数Xに、ターゲットを変数yに格納
X = ab_data.values[:,:8]
y = ab_data.values[:,8]
for index, item in enumerate(X):
item[0] = classtonum(item[0])
# データの順番を入れ替えるためのランダムなNumPy配列
np.random.seed(10)
indices = np.random.permutation(len(X))
val_len = int(len(X) * -0.01)
# 学習用のデータ。全体から100データを省いたもの
X_train = X[indices[:val_len]]
y_train = y[indices[:val_len]]
# テスト用のデータ。全体から100データ取り出したもの
X_test = X[indices[val_len:]]
y_test = y[indices[val_len:]]
# サンプル数、特徴量の次元、クラス数の取り出し
(n_samples, n_features) = X_train.shape
n_classes = len(np.unique(y))
4.Kerasのネットワークを定義し、コンパイルする
前回同様に100個のパーセプトロンを3層定義しています。
入力は特徴量の数のnumpy配列なので、上記処理で取得したn_featuresの値を使用し「input_shape=(n_features,)」にしていますが、出力は1個なので「model.add(Dense(units=1))」としています。
学習が完了すると学習済みのモデルデータが「keras_reg_abalone.h5」の名前で保存されます。
「useSavedModel = True」に変更することで保存したモデルで予測を行えるようにしています。
savefile = 'keras_reg_abalone.h5'
useSavedModel = False
if useSavedModel == False:
# ニューラルネットワークを定義
model = Sequential()
# 中間層と入力層を定義
model.add(Dense(units=100, activation='relu', input_shape=(n_features,)))
model.add(Dropout(0.1))
model.add(Dense(units=100, activation='relu'))
model.add(Dropout(0.1))
model.add(Dense(units=100, activation='relu'))
model.add(Dropout(0.1))
model.add(Dense(units=1))
# モデルのコンパイル
model.compile(loss='mse', optimizer=Adam(lr=0.001), metrics=['mae'])
#model.compile(loss='mse', optimizer=tf.train.RMSPropOptimizer(0.001), metrics=['mae'])
# モデルの学習
early_stopping = EarlyStopping(monitor='val_loss', mode='min', patience=20)
#history = model.fit(X, y_keras, epochs=4000, validation_split=0.1, batch_size=n_samples, verbose=2)
plotHistory(
model.fit(
X_train, y_train, epochs=300, validation_split=0.1, verbose=2
,callbacks=[early_stopping]
)
)
# 学習結果を保存
model.save(savefile)
else:
# 学習済ファイルを読み込んでmodelを作成
model = keras.models.load_model(savefile)
5.作成したモデルで予測を行い、結果を表示する。
# 結果の表示
result = model.predict(X_test, verbose=0).flatten()
for index, item in enumerate(result):
print('正解={0}, 予想値={1}, 誤差={2}'.format(y_test[index], result[index], result[index] - y_test[index]))
from sklearn.metrics import r2_score
print('score={0}'.format(r2_score(y_test, result)))
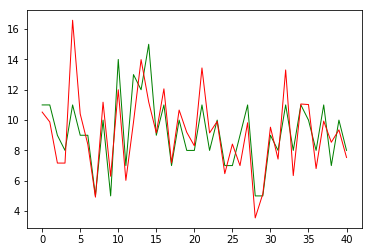
plt.plot(np.arange(len(X_test)), y_test, color='green', linewidth=1)
plt.plot(np.arange(len(X_test)), result, color='red', linewidth=1)
plt.show()
6.実行する
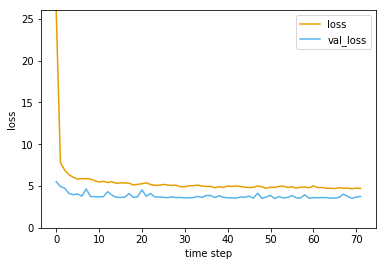
まず以下のようなグラフが表示されます。前回同様に適当に学習が進んだところで自動で停止します。
次に以下の様に正解、予想値、誤差が表示されます。
「score=~」の値は決定係数 (R2)ですが、これを表示するためにscikit-learnを使用しています。
正解=11, 予想値=10.528636932373047, 誤差=-0.4713630676269531
正解=11, 予想値=9.877708435058594, 誤差=-1.1222915649414062
…
正解=10, 予想値=9.357595443725586, 誤差=-0.6424045562744141
正解=8, 予想値=7.53438138961792, 誤差=-0.4656186103820801
score=0.49060378487354894
「score=~」の表示の下に、正解データを緑色、予測データを赤で表示するグラフが表示されます。
7.結果について
前回のプログラムと基本的に同じニューラルネットワークで異なるタイプのデータの予測もできることがわかります。
今回は「I」「F」「M」を0~2の整数に変換して試しましたが、Pandasのget_dummies()を使って
ダミー変数化した方が、学習の効率的にも良いらしいです。
8.次回
分類の場合について試します。
https://qiita.com/norikawamura/items/4653ca4788d787f7007c