概要
Factorization Machines(FM)という機械学習の手法と量子アニーリング(QA)を組み合わせてマテリアルズ・インフォマティクス(MI)へ応用した次の論文についてレビューしたいと思います。
- 題名 : Expanding the horizon of automated metamaterials discovery via quantum annealing
- URL : https://arxiv.org/abs/1902.06573
私の理解の整理のためにも書いたので誤っている箇所があれば指摘してください。
内容としては、そもそもQUBOの係数自体を決めるのが難しい問題設定に対して、実験やシミュレーションで得られたいくつかの訓練データからQUBOの係数値を推定して、そのQUBOを量子アニーリングで解くといった手法になります。
量子アニーリングで解いた結果のコンフィグレーションとエネルギーをさらに訓練データとしてFMに食わせて学習させ、QUBOの係数をiterativeに更新していくというアルゴリズムになっています。
この手法のことをFMQA(Factorization Machines + Quantum Annealing)と呼んでいます。
背景
マテリアルズ・インフォマティクス(MI)では自由度の多い構造を持つ物質の物性を効率的に計算することが重要のようです。
自由度が多くなると設定する組み合わせが多くなるので実験やシミュレーションを行う時間や労力が増えてしまいます。
自由度の数に対して組み合わせは指数的に増えてしまうので、そもそも全パターンを試すことが現実的な時間では不可能な場合がほとんどかもしれません。
ベイズ最適化の1種であるブラックボックス最適化を利用して、現在得られているデータから次に試すべき設定の候補を絞り出して実験・シミュレーションを行い、その結果を加えてさらにブラックボックス最適化により次の候補を絞り込むというiterativeなプロセスで計算を行って所望の物性を持つ物質を探索しています。
(ブラックボックス最適化のわかりやすい解説動画:https://www.youtube.com/watch?v=pQHWew4YYao)
この様なベイズ最適化では代理関数(acquisition function)を定義して、この代理関数を最大化・最小化して次の実験候補を求めにいきます。
FMQAではQUBOが代理関数になります。
立ちはだかる壁
上記のプロセスで計算を行っていく上でStatisticalな壁とComputationalな壁がある様です。
- Statisticalな壁 : 訓練データが限られいて物性を予測するのが難しい。
- Computationalな壁 : 代理関数の最適解(Global Minimum)を得るのが難しい。
この2つ壁が破るためにFMQAを提案されています。
FMではStatisticalな壁を、QAではComputationalな壁を破ろうという試みです。
問題設定
細かい物質の情報は抜きにすると、図2の左端に記載されているブロック内の赤色(SiC)と青色(SiO$_2$)のブロックの配置場所を変更してできた物質に対して上から光を当て、その放射強度(Emission Power)を測定します。
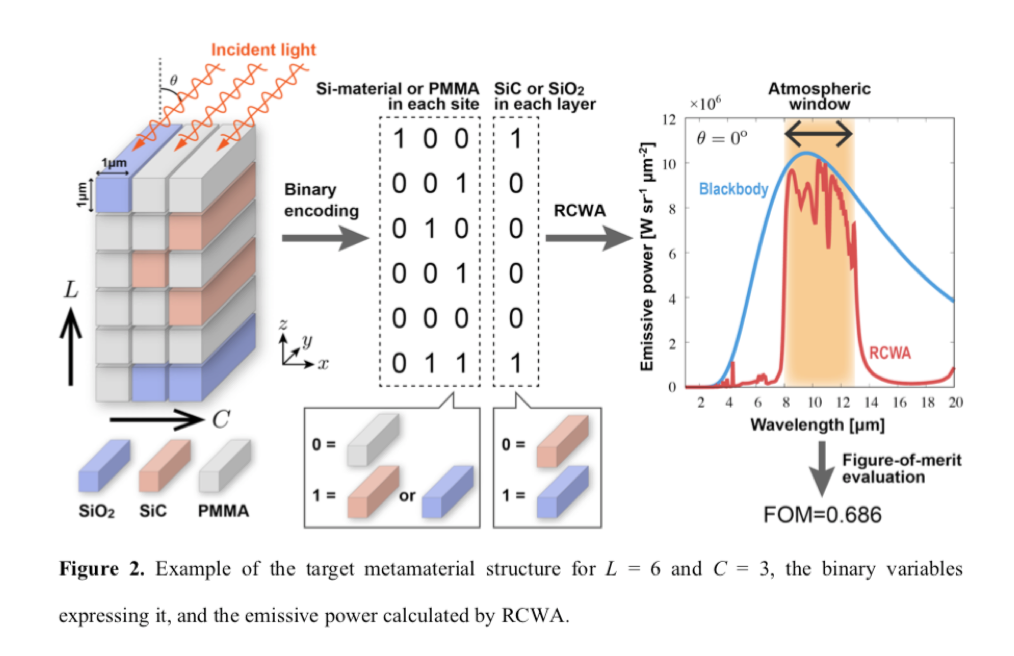
その放射強度のピークが波長の8~12$\mu m$に現れる様な物質が目標の物質になります。
この波長の範囲8~12$\mu m$のことをAtmospheric Windowと呼ぶらしいです。
この範囲に高いピークがあると暑くて湿潤な地域においても放射強度の高い物質が作成できて、地球温暖化とかにも役に立つみたいです。(間違っていたらすいません。)
条件
図2の左端に記載されているブロックの集合体ですが、y軸方向には無限に伸びていると仮定されています。
つまりy軸方向に複数の種類の物質を配置することはできません。
基本的にy軸方向は無視して、残りの(x, z)軸方向で問題を考えて構いません。
x軸方向には周期境界条件を課しています。
周期的に繰り返されるx軸方向のブロックの数を指定すれば、後はその数の中だけでブロックに配置する色を決めれば良いです。
例えば図2の様に3個と設定すればその3個にどの様に色を塗るかを決めて、その色の塗り方が決まればそれと同じパターンがx軸方向に繰り返されているという感じです。
z軸には特に条件は課せられていません。
x軸のことをC、z軸のことを**L(Layer)**と改めて名付けられています。
後は色の塗り方の条件ですが、各レイヤーで1色までしか塗ってはいけません。
赤色と青色のブロックが同じレイヤーにあってはいけません。
入力データ
図2の真ん中にあるように、色を塗ったブロックの構造をバイナリ変数のリストとして定義する必要があります。
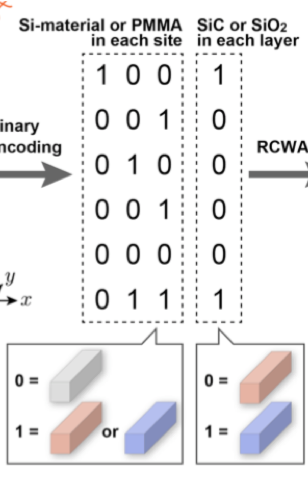
まず左側のリストでは赤色か青色で塗られたブロックがあればその位置に1をそうでなければ0が格納されています。
右側のリストではレイヤーごとに青色で塗られたブロックがあれば1をそうでなければ0が格納されています。
これらのリストを入力データとして吸収強度を計算します。
吸収強度は**Rigorous Coupled Wave Analysis(RCWA)**と呼ばれる計算手法(シミュレーター?)で計算されます。
計算結果として図2の右端のようなどの波長にどのような吸収強度が現れているのかを示すデータが得られます。
FOMと書かれているのはFigure-of-Meritの略で性能指数を意味します。
多分、波長がAtmospheric Window(8~12$\mu m$)の範囲では吸収強度が高い方が、それ以外の波長の範囲では吸収強度が0に近い方が高い値になる評価指数のことだと思います。
このFOMがFMの学習時の教師データになります。
FMでFOMを現す代理関数の係数を求めることになります。
手順
- 各レイヤーには1色までしか配置できないという制約を守りながらブロックの配置を決める。
- 上で配置したブロックのパターンを表現するバイナリのリストを作成する(Binary Encoding)。
- 上のリストを入力データとしてRCWAを実行する。
- RCWAの結果を見て、何らかの方法で次に配置するブロックのパターンを決めて1に戻る。
4の結果を見て、1のブロックのパターンをどのようにするのかを決めるのが重要になります。
論文ではFMQAを利用してこのパターンの効率的な決め方が提案されています。
従来のQUBO
まずは純粋に上記の問題設定を反映したQUBOを作成してみたいと思います。
図2の真ん中の左側のリストを2次元の行列として、その成分のインデックスを$(i, j)$とします。
色を指定するインデックスを$k$として次のバイナリ変数を定義します。
\begin{align}
x_{i, j, k} = \begin{cases}
1 & (リスト(i, j)に色kが塗られた場合) \\
0 & (otherwise)
\end{cases}
\end{align}
$k=0$を赤色、$k=1$を青色とします。
各レイヤーは1色までしか塗ってはいけないという制約条件は次のように定式化することができます。
\begin{align}
\sum_{i \in \boldsymbol{L}}\biggl[ \biggl(\sum_{j \in \boldsymbol{C}}x_{i,j,0} \biggr)\cdot \biggl(\sum_{j \in \boldsymbol{C}}x_{i,j,1} \biggr) \biggr]
\end{align}
$\boldsymbol{L}$はレイヤーの集合、$\boldsymbol{C}$はx軸方向に置けるブロックの数の集合を表しています。
ブロック間の相互作用を$Q_{(ijk,i^{\prime}j^{\prime}k^{\prime})}$として、この相互作用を元にFOMが計算できるとします。
そうすると全体のQUBOは次のように表すことができます。
\begin{align}
\mathcal{H} = -\sum_{(i,j,k), (i^{\prime},j^{\prime},k^{\prime})}Q_{(ijk,i^{\prime}j^{\prime}k^{\prime}) }x_{i,j,k}x_{i^{\prime},j^{\prime},k^{\prime}} + A\sum_{i \in \boldsymbol{L}}\biggl[ \biggl(\sum_{j \in \boldsymbol{C}}x_{i,j,0} \biggr)\cdot \biggl(\sum_{j \in \boldsymbol{C}}x_{i,j,1} \biggr) \biggr]
\end{align}
第2項の$A$は制約条件を成立させるための係数で、少なくとも
\begin{align}
A >> \sum_{(i,j,k), (i^{\prime},j^{\prime},k^{\prime})}Q_{(ijk,i^{\prime}j^{\prime}k^{\prime})}
\end{align}
に設定する必要があります。
定式化自体はこのように簡単に出来るのですが1つ問題があります。
それはそもそも$Q_{(ijk,i^{\prime}j^{\prime}k^{\prime})}$を準備しようとすると時間がかかることです。
$Q_{(ijk,i^{\prime}j^{\prime}k^{\prime})}$を求めるためにはブロック内の異なる2箇所(または1箇所だけ)に色を塗った全てのパターンに対してRCWAを行いFOMを計算する必要があります。
図2の例で概算してみます。
ブロック内の一番左上のブロックを赤色に塗った場合を考えます。

これ以外の別のブロックを塗るときの組み合わせの数を計算して見ます。
同じレイヤーには異なる色は塗れないので一番上のレイヤーでは残りの2箇所に赤色を塗る2パターン。
一段下のレイヤーでは3箇所のどれを赤色で塗るかの3パターンと青色で塗るかの3パターンの計6パターン。
同様に残りの4つのレイヤーに対しても同様に6パターンずつ存在する。
よって一番左上のブロックを赤色に塗った場合の残りの色の配置の仕方の組み合わせ数は$2+6*5=32$パターン。
一番左上のブロックを青色に塗った場合も同様に32パターン。
よって1ブロックあたり64パターンあります。
同様の計算をさらに横のブロックに移って組み合わせの数を計算して行きます。
重複するパターンがあるので2で割ることに注意すると全ての組み合わせは$64*18÷2=576$パターン。
$Q_{(ijk,ijk)}$についてもパターンを列挙すると、これは1つのブロックにどの色を塗るかの組み合わせだけなので$18*2=36$パターンあります。
よって$L=6, C=3$で$Q_{(ijk,i^{\prime}j^{\prime}k^{\prime})}$のパターン数は612になります。
より一般的に表すと$(C-1+2C(L-1))*CL + 2CL$パターンとなります。
RCWAのシミュレーションではハイスピードなものを利用しても1分間はかかるみたいなので$L=6, C=3$の場合だと約10時間かかってしまいます。
このぐらいの計算時間であれば1日以内で済みますが$L,C$の値が大きくなったり、他のパターンで計算しようとするに時間が増えて気軽に計算することが難しくなります。
このようにそもそも$Q_{(ijk,i^{\prime}j^{\prime}k^{\prime})}$を準備するのが難しいことが分かります。
提案手法(FMQA)
QUBOの係数$Q_{ijk}$を全て準備することが難しい・効率的ではないので、Factorization Machines(FM)を利用していくつかの訓練データから$Q_{ijk}$の値を推定します。
FMは図2のバイナリのリスト(行列っぽいものが横に重なっていてもおk)とそれに対応するスコア値から2次以下の評価関数を推定する手法になっており、まさにQUBO作成にぴったりな機械学習の手法です。
FMの詳しい説明に関しては以下を参考にしてください。
- https://tech-blog.fancs.com/entry/factorization-machines
- http://www.housecat442.com/?p=676
- Factorization Machinesについて調べてみた
libFMというライブラリがpythonで提供されているので簡単に実行できそうです。
さらに上で素直に定義したバイナリ変数$x_{i,j,k}$ではなく下の図のように図2の真ん中ので現れた2つのリストの要素をそのままバイナリ変数に設定することが出来ます。
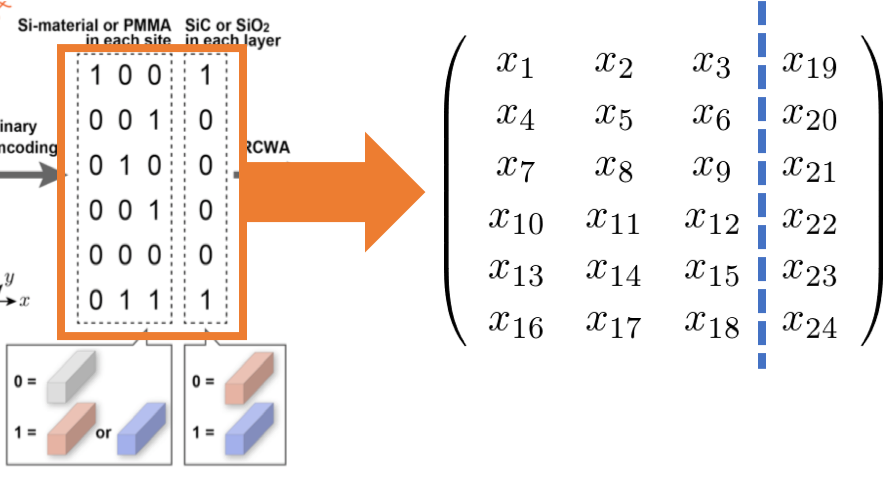
従来のQUBOだと必要なビット数は左側のリストの要素数の2倍だったので36ビットでしたが、FMを利用すると24ビットに削減できます。
より一般的には従来のQUBOだと2CLビットだったものがL(C+1)ビットで済むので、L(C-1)ビットも削減することができます。
故に用意する相互作用$Q_i$も従来に比べると少なくなります。
FMの訓練データにはブロックのビット列の配置とそれを用いてRCWAで求めたFOM(性能指数)を正解データにして$Q_{i}$の値を学習していきます。($N=L(C+1)$)
\begin{align}
FOM(\boldsymbol{x}) &= \sum^N_{i=1}w_{i}x_{i} + \sum^N_{i=1}\sum^N_{j=1}\biggl(\sum^K_{k=1}v_{i,k}v_{j, k}\biggr) x_i x_j
\end{align}
上で学習した結果で得られた$w, v$を用いて
\begin{align}
Q_{ii} &= w_i \\
Q_{ij} &= \sum^K_{k=1}v_{i,k}v_{j, k}
\end{align}
$K$はハイパーパラメータになっており、どれだけ$v_{i,k}$を冗長に用意するかを決定づけます。
libFMではデフォルトは$K=8$に設定されているようです。
($K$が大きすぎると過学習する?収束時間が遅い?)
FMによりStatisticalな壁を破る事ができそうです。
手順
- 適当にブロックの配置パターンを用意して従来通りにRCWAでFOMを計算して訓練データを用意する。
- 訓練データを用いてFMによりQUBOの係数を学習して決定する。
- 量子アニーリングで2で得られたQUBOの最小エネルギーとその状態(ブロックの配置パターン)を求める。
- 3の結果を訓練データに加えて2に戻る。
量子アニーリングによりComputationalな壁を破れそうです。
これにより次の候補を効率的に選ぶ事ができます。
結果
学習部分ではFM, ガウス過程(GP), ランダムサーチによる比較を行っています。
最初の訓練データにはランダムに生成した50個のブロックパターンとFOMを用意して学習を初めています。
量子アニーリングによる最適化には独立した16組の施行を並列に行っています。
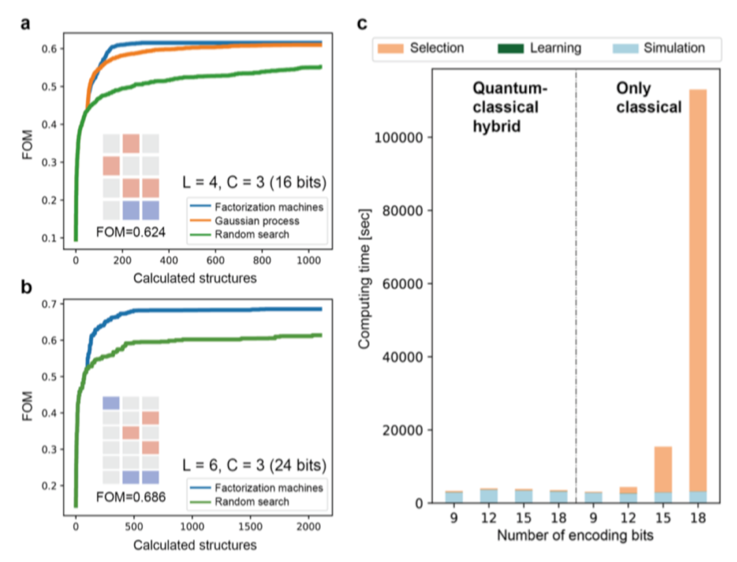
図3の(a)と(b)は学習部分にどの手法を用いるかの比較を行っています。
(FM以外はQAによる最適化を行っているわけではない?)
図3(c)はビット数ごとの500iterationsを行うのに必要な時間をQAと全探索で比較した結果を示しています。
学習時間とシミュレーション時間は両方ともどのビットでもある程度一定ですが、次の候補を選択する時間がビット数が増えると大幅にFMQAの方が削減されています。
(全探索ではなく古典的なSAや他のメタヒューリスティックスと比較するとどうなるんだろう....。)
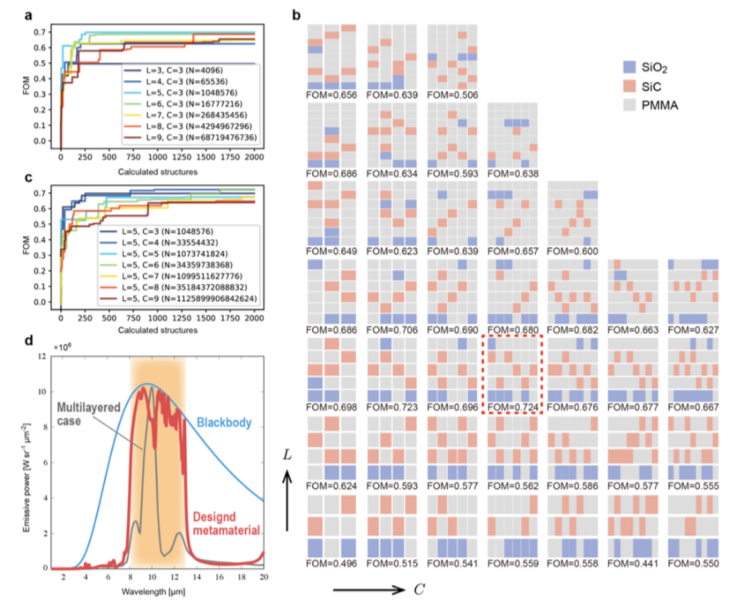
図4の(b)ではレイヤー$L$や$C$の数を変えた時のFOMの変化を表しています。
赤枠で囲まれた設定がこの中でベストなFOMの値を持つようです。
その構造を用いて放射強度を計算した結果が図4の(d)でMultilayer Optimum Case(付録に詳しい説明があるようですが、追えていません)よりも良いし、ちゃんと**8~12$\mu m$**の範囲にピークが集中していることも確認できます。
まとめ
そもそも設定上QUBOの係数を準備するのが難しい問題でもFMを用いれば訓練データからQUBOの係数を推定することができる。
量子アニーリングを用いればD-waveで計算できるビット数の範囲であればガウス過程、全探索よりも短時間で良いFOMのブロックの配置を計算することができる。
(ここでの比較対象は全探索で良いのかという疑問はあります。量子アニーリングではなくSAなどの他のメタヒューリスティックスだとどうなのか。)
(また$L=6, C=3$の規模だと私の計算が間違っていなければ10時間ですべてのQUBO係数を準備することが出来るので、FMで推定したQUBO係数ではなく本来のQUBO係数で計算した時の比較などもみてみたいと思いました。)
FMを利用するとビット数の削減にも繋がる可能性がある。
量子アニーリングとFMは相性が良さそう!
(他にもこのような機械学習の手法があれば教えてください。)
もっと大きな規模の問題にも適用してみたいですね。