先日、「ソロ旅ねっと」というWebサービスを公開しました。
このサービスは、一人で宿泊可能な施設を、目的候補地、宿泊候補日などを自由に設定して、日本全国から検索できるようなサービスです。
検索対象となる宿泊施設の情報は、楽天トラベルの「Rakuten Developers」というサービスで提供されているWebAPIを利用して取得しています。
サービスを作った経緯などは別記事でまとめているので、もしよろしければ、そちらの記事も読んでみてください。
一人旅が捗るWebサービスを思いついたので、開発から公開まで全部一人でやってみた話
サービスを作った経緯の記事でも書いたのですが、このサービスを作ろうと思ったとき、できる限りお金をかけずにやっていきたかったので、サーバは超ケチケチ構成です。
AWSのt3-micro instanceのサーバ1台ですべての機能を賄っています。
このサーバの中では以下のものが動いています。
- Ubuntu 18.04
- nginx
- 本環境:port80
- テスト環境:port8080
- PHP7.2
- Webアプリケーションとして使用
- 常時動作しているbatchとしても使用
- 楽天トラベルに登録されている宿泊施設、施設の空室状況を取得&更新するためのプログラム
- APIから返却された json をparseし、必要に応じてpostgreSQLのデータベースを更新する
- 楽天トラベルに登録されている宿泊施設、施設の空室状況を取得&更新するためのプログラム
- postgreSQL Server 11
- nginx
この記事では、主にバックエンドの処理に焦点を当てて、エンドユーザさんが「このサイト遅い」って感じないように、性能面で取り組んできたことを書いていきたいと思います。
前提として、少しだけデータ構造の話をします。
楽天の施設情報は、APIのレスポンス形式から推測ですが、以下のようなデータ構造をしているようです。
- 旅館・ホテルの情報
- 各旅館・ホテルが提供している宿泊プランの情報(取得できるのは最大3件)
- 各プランの予約可否と日付ごとの価格情報(価格情報は、ソロ旅ねっとでは日付ごとに管理していますが楽天トラベルは、曜日でグループ化するなど、もう少し効率的に管理しているかも)
- 各旅館・ホテルが提供している宿泊プランの情報(取得できるのは最大3件)
ソロ旅ねっとのデータベースも、宿泊施設基本情報テーブル、宿泊プランテーブル、(宿泊日毎の)予約可否テーブルの3つのテーブルで施設データを管理しています。
テーブルのパーティショニング
楽天トラベルに登録されている一人で宿泊可能な宿泊施設は1万~2万ほどあります。
各施設が持ってるプランの数を平均2件と仮定し、直近30日分の予約可否&価格データを扱うことにしたとすると、予約可否テーブルのレコード数は60万レコード~120万レコードになります。プラン数が予想よりも多かった場合、もっと先まで予約可否データを取得&保存することにした場合、このレコード数はさらに膨れ上がります。
特に性能評価をしたわけではないのですが、予約可否テーブルは、postgreSQLのハッシュパーティションの仕組みを利用し、いくつかのテーブルに分割しています。
create table t_hotel_reservation (
id serial,
plan_id integer not null,
checkin_date date not null,
price integer not null,
)
PARTITION BY hash (checkin_date);
create table t_hotel_reservation_0 partition of t_hotel_reservation for values with (modulus 10, remainder 0);
create table t_hotel_reservation_1 partition of t_hotel_reservation for values with (modulus 10, remainder 1);
create table t_hotel_reservation_2 partition of t_hotel_reservation for values with (modulus 10, remainder 2);
...
宿泊施設の更新、予約可否テーブルの更新は、データ更新用のバッチプログラムが、楽天トラベルのWebAPI経由で、常時情報を更新し続けています。
全国の宿泊施設の宿泊施設、プラン情報、および1日分の予約可否状況を更新するのに約45分~1時間ほどかかっています。
ソロ旅ねっとは28日分の予約可否情報を検索できるようにしているため、更新頻度は1日~1日+4時間程度となっています。
リリースできたけどやっぱり性能はいまいちだった
一応、規模が大きくなりそうなテーブルのパーティショニングは行ったけど、それ以外の実装部分は、特に工夫することもなく、ごくごく普通の方法で実装しました。
最初のリリース当初は、エンドユーザさんが検索を行ったとき、内部で以下のような処理を行っていました。
- 検索条件にヒットする宿泊施設の件数を取得
select count(*) from t_hotel_info where ....
- 検索条件にヒットする宿泊施設のうち、現在のページで表示すべき施設の基本情報を取得
select * from t_hotel_info where ... offset (:page_no - 1) * 10 limit 10 order by prefecture_id, hotel_no
- ヒットした宿泊施設の全宿泊プラン情報を取得
select hotel_no, t_hotel_plans.* from t_hotel_plans where hotel_no in (....)
- ヒットした宿泊施設の予約可能日の一覧/価格(一番安い日の価格と1番高い日の価格)を取得
select hotel_no, checkin_date, min(price), max(price) from t_hotel_reservation, t_hotel_plans where ... group by hotel_no
結果、施設検索の結果を返す際、これらのクエリー処理だけでも5秒以上はかかっていて、実際に使ってみても我慢できるレスポンスタイムとは正直ちょっと言えない状態でした。
いくら趣味プロジェクトとはいえ、大赤字プロジェクトにするつもりはなく、サーバスペックを上げることはしたくなかった(するつもりなかった)ので、随所にキャッシュの仕組みを取り込んで、レスポンスタイムを高速化することにしました。
nginx のリバースプロキシキャッシュを利用することも、少しだけ考えました。
やったことない&調べていないので具体的なやり方は実は解っていないのですが、おそらく実装は楽(nginx側の設定のみで完了する)かと思いますが、キャッシュのクリアタイミングの制御が困難なことや、ソロ旅ネットの場合には検索クエリーのパターンが非常に多いためキャッシュヒットに全く期待できない、の2点により即ボツ案となりました。
twig template のレンダリング済結果をキャッシュ
そこで考えたのが、ページを構成している要素のうち、時間のかかっている部分、かつ、多くのページで共通化されている部分を個別にキャッシュすることでした。
対象として、twig template でレンダリングされる部分のうち、多数のページで共通で使用される部分で、かつ更新タイミングが正確に把握できる箇所、をパーツ毎にキャッシュする方針としています。
検索条件パネルのキャッシュ
キャッシュ対象の一つ目は、すべてのページに表示されている検索条件パネルです。

左側のエリア選択部分は、「都道府県一覧から選択」「全国の温泉スポットから選択」の2つをタブで切り替えられるようになっています(見えているのは温泉スポットの方です)。
都道府県一覧が変わるというのは、都道府県が増減するということなので、これは当面変わることはないでしょう。
温泉スポットは、楽天トラベルで定義された地域ごとに、一人で泊まれる温泉旅館の数と一人で泊まれる全旅館の総数を集計し、温泉旅館の数が一定以上で、かつ温泉旅館の割合が閾値(50%程度)以上だった地域を大雑把にグルーピングして表示しています。
こちらは、宿泊施設情報が更新されたタイミングで、増減することがあるかもしれません。
右側のカレンダー部分は、宿泊候補日の選択枠です。
当日~4週間後の日付まで設定できるようにしているため(現在は、GW最終日前日まで指定できるようにしていますが)、日付が変わって、予約可能施設のデータの更新が完了したタイミングで表示が更新されます。
都道府県一覧と、カレンダー部分のクエリーは一瞬なのですが、温泉地域の表示に若干時間がかかっていました。
キャッシュすることによって、性能的には1秒~2秒程度の時間短縮になっています。
検索結果に表示する宿泊施設情報のキャッシュ
次に、検索結果にずらっと表示される宿泊施設の情報パネルです。
ユーザさんの検索条件によって、表示される施設は異なりますが、同じ施設の表示結果は常に大体一緒です。
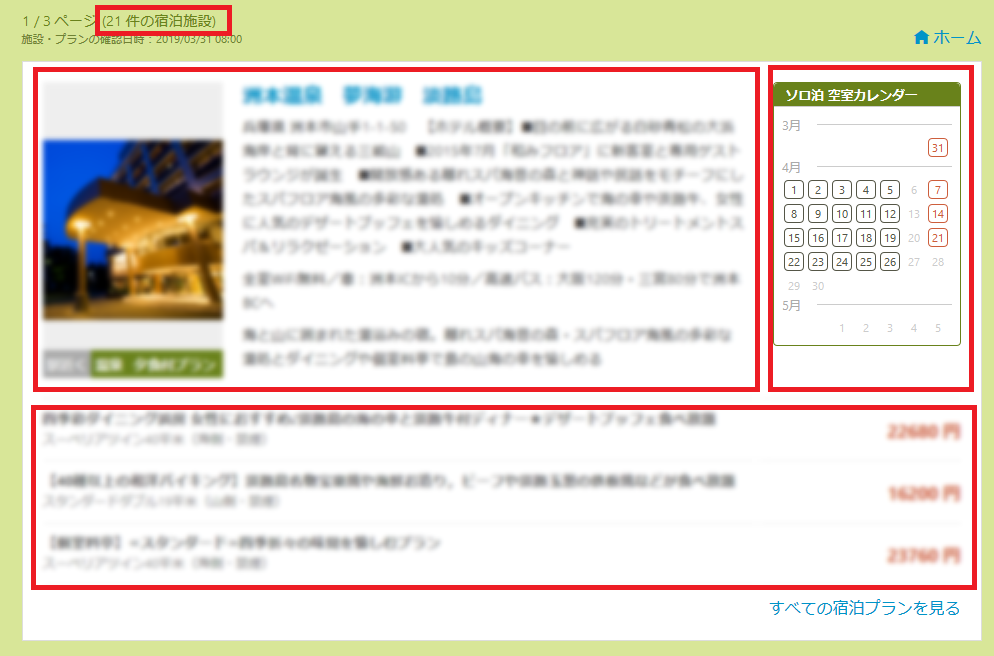
左上隅に表示されているのはは検索結果件数です。
これはユーザさんの検索条件によって変化し、固定されるものではないので、レンダリングの結果のキャッシュとしては対象外です。
宿泊施設情報の左上は、施設の基本情報です。ここには、宿泊施設名、住所、アピールポイントなどが表示されます。
宿泊施設の更新によって変化することもあるかと思いますが、基本的にはあまり変わらない情報です。
右側の「ソロ泊空室カレンダー」は、一人で予約が取れる日を一覧で表示しています。
この部分は、予約データがアップデートされたタイミングで情報が更新される場合もあります。
そして下に表示されているのは施設が提供しているプラン一の覧です。
もろもろの制約により、1つの宿泊施設に対して、最大3件までしか取得できないのですが、「あること」に目を瞑れば、宿泊施設がプランの情報を更新しない限りは更新はありません。
「あること」とは
例えば、平日1万円、土日1万2千円の宿泊プランがあったとします。
この時、平日のみで検索した場合の金額表示は10,000円が正しい表記であり、土日のみで検索したときは12,000円が正しい表記です。また、金・土曜日で検索したときの表示は、ソロ旅ねっとで最初に考えていた仕様では「10,000円~」という表記としていました。
初期は、検索条件によって表示を分けていた(条件にヒットした日付の宿泊価格を考慮)のですが、キャッシュする場合は固定化するしかありません。
ここをどうするかは悩んだのですが、キャッシュの仕組みを入れ込んだタイミングでいったん妥協して 検索条件にかかわらず、10,000円~という表記にしています。
ただ、どうにもならないわけではなく、例えば、キャッシュしたデータの中に各日付ごとのプラン価格をjsonデータで持っておいて、ブラウザレンダリング時にクライアント側で(javascript使って)どうにかする等の方法も考えられるので、いずれやってみるかもしれません。
キャッシュの作成と更新方法
検索パネルの .twigコードやホテル情報の .twigコードは、もともと独立したファイルに分離していました。
そこで、施設&空室状態更新バッチプログラム内の適切なタイミングで、対象の .twigテンプレートのみをレンダリングし、結果をキャッシュファイルに書き出せば、キャッシュの作成&更新をバックグラウンドで行うことができます。
ただ、twigのdisplayメソッドは標準出力にそのまま書き出す機能しかないため、PHPの仕組みを使い、一旦バッファリングし、文字列として結果を受け取り、それをファイルに書き込むことにします。
ob_start();
...
$template = $twig->loadTemplate($this->templateFileName);
$template->display($model->getValues());
$result = ob_get_clean();
file_put_contents($cacheDirectory.$hotelNo.'.html', $result);
これに合わせて、 twigのテンプレートも修正します。
以下、上がもともとのソース、下がキャッシュを利用したソースです。
かなり簡略化して書いていますが、実際のソースはもう少し複雑です。
{# もともとのソース #}
<html>
<body>
{% include('include/search-panel.twig') %}
{% for hotel in allHotels %}
{% include('include/hotel-info.twig', ['hotel' => hotel]) %}
{% endfor %}
</body>
</html>
{# キャッシュを利用したソース #}
<html>
<body>
{% include('cache/search-panel.html') %}
{% for hotelNo in allHotelNos %}
{% include('cache/hotel-info/'~hotelNo~'.html') %}
{% endfor %}
</body>
</html>
ここまでの作業で、検索条件パネルも、検索結果の宿泊施設情報も、静的なファイルの読み込みに置き換えることができたため、エンドユーザからのリクエストに応答するためのSQLクエリーも、その分単純化できます。
- 検索条件にヒットする宿泊施設の件数を取得
select count(*) from t_hotel_info where ....
- 検索条件にヒットする宿泊施設のうち、現在のページで表示すべき施設の基本情報を取得
select hotel_no from t_hotel_info where ... offset (:page_no - 1) * 10 limit 10 order by prefecture_id, hotel_no
ここまでやって、SQLクエリーにかかる時間は2秒弱となりました。
さらなる高速化
ソロ旅ねっとに登録されている宿泊施設の数(=楽天トラベルに登録されている一人で泊まれる宿泊施設のうち、直近1か月以内のどこかで予約が取れる宿泊施設の数)は、1万~2万ほどです。
実用的な検索条件、例えば「ゴールデンウィークのどこかで泊まれる北関東の温泉宿」、くらいの検索条件で検索した場合、ヒットする施設数は100件程度です。
クエリーで取得する情報もHotelNoのみなので、search と count のSQLを別々に投げるのではなく、searchで全件取得し、ページング処理はPHPコード側で行えば、SQL呼び出しは1回で済みます。
つまり内部処理はこんな感じ(↓)になります。
- 検索条件にヒットする宿泊施設のうち、現在のページで表示すべき施設の基本情報を取得
select hotel_no from t_hotel_info where ... order by prefecture_id, hotel_no- 全件数取得と、ページング処理はPHP側で行う
さらに、クエリーで返される数百程度のIDリストであれば十分キャッシュできる量なので、これもキャッシュしてしまいます。
Redis などは使わずに、このキャッシュもpostgreSQLにキャッシュ用のテーブル作り、そこに検索条件=>宿泊施設の結果リストを格納しています。
テーブル定義は下記のような感じになります。
-- テーブル定義
create table t_cache (
id serial,
cache_key text unique not null,
hotel_nos integer[] not null
);
create index on t_cache (cache_key);
create index on t_cache uging gin(hotel_nos);
cache_key は リクエストURLからページ番号を除いたうえで正規化して(パラメータの順序など)、それをハッシュ化したものを使用しています。
valueにあたるのがhotel_nosです。これは宿泊施設idの配列です。
あとは、エンドユーザさんからリクエストが来たら、キャッシュがあるか調べ、あればそれを返却、なければ通常の検索を行うだけです。
検索条件にもよると思いますが、キャッシュヒットの可能性はさほど高くないと思います。
ですが、ユーザがページ送りした時には、キャッシュがフラッシュされていない限りはキャッシュが確実にヒットします。
最後はキャッシュクリアタイミングの話です。
キャッシュフラッシュのタイミングは、キャッシュテーブルの value に含まれている宿泊施設のプラン条件や空室状況に変化があった時となります(検索条件によっては結果が変わらないことももちろんありますが、そこまでは見てません)。
宿泊施設情報の更新を行っているバッチプログラムの適切なタイミング(キャッシュクリアが必要になるタイミング)で、以下のSQLでキャッシュをクリアしています。
delete
from rakuten.t_search_key_cache
where hotel_nos && (
-- 更新された宿泊施設を取得
select array_agg(hotel_no) hotel_nos
from rakuten.t_hotel_basic_info
where ....
)
今回は、個人開発のWebサービス「ソロ旅ねっと」で、応答速度改善のためにやってきたことの一部を紹介させていただきました。
「〇〇というミドルウェアをこんな設定でこういう使い方をして~」的な話でもなく、地道に独自実装をあれこれやった話なので応用が利く話になっているのかはわかりませんが、考え方とかで何かの参考になれば幸いです。