スクレイピングの管理
みなさん、スクレイピングの管理はどのようにしていますか。
自分でサーバで立ち上げたり面倒な作業がいらない方法をご紹介します。
scrapyでスクレイピングする部分を作成する。
プロジェクトの作成
pip install scrapy
scrapy startproject yahoo_scrapy
cd yahoo_scrapy
scrapy genspider yahoo yahoo.co.jp
spiderの作成(スクレイピング部分)
cd yahoo_scrapy
scrapy genspider yahoo yahoo.co.jp
yahoo_scrapy/items.py
class YahooScrapyItem(scrapy.Item):
link = scrapy.Field()
yahoo_scrapy/spiders/yahoo.py
# -*- coding: utf-8 -*-
import scrapy
from ..items import YahooScrapyItem
class YahooSpider(scrapy.Spider):
name = 'yahoo'
allowed_domains = ['yahoo.co.jp']
start_urls = ['http://yahoo.co.jp/']
def parse(self, response):
for sel in response.css("a"):
article = YahooScrapyItem()
article['link'] = sel.css('a::attr(href)').extract_first()
yield article
ローカルでの動作確認
scrapy crawl yahoo
標準出力に、結果が出力されます。
scrapinghub
https://app.scrapinghub.com
こちらのほうに登録してください。
ログインして、プロジェクトを作成します。
yahooをスクレイピングしようかと思うので、yahooプロジェクトにします。
Code & Deploys で作成したレポジトリと接続します。
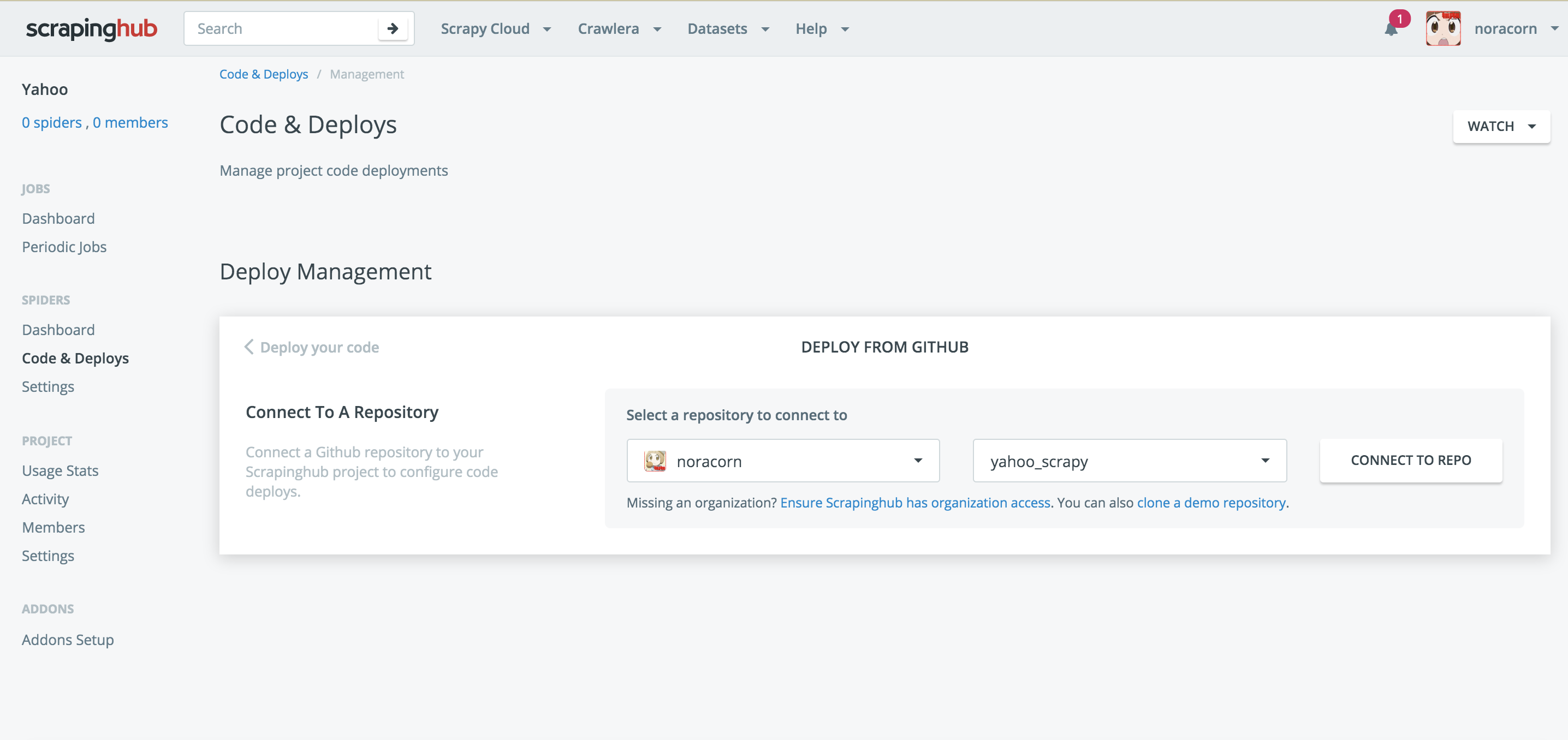
接続完了後に、Gitのほうを、コミットしてプッシュしちゃってください。
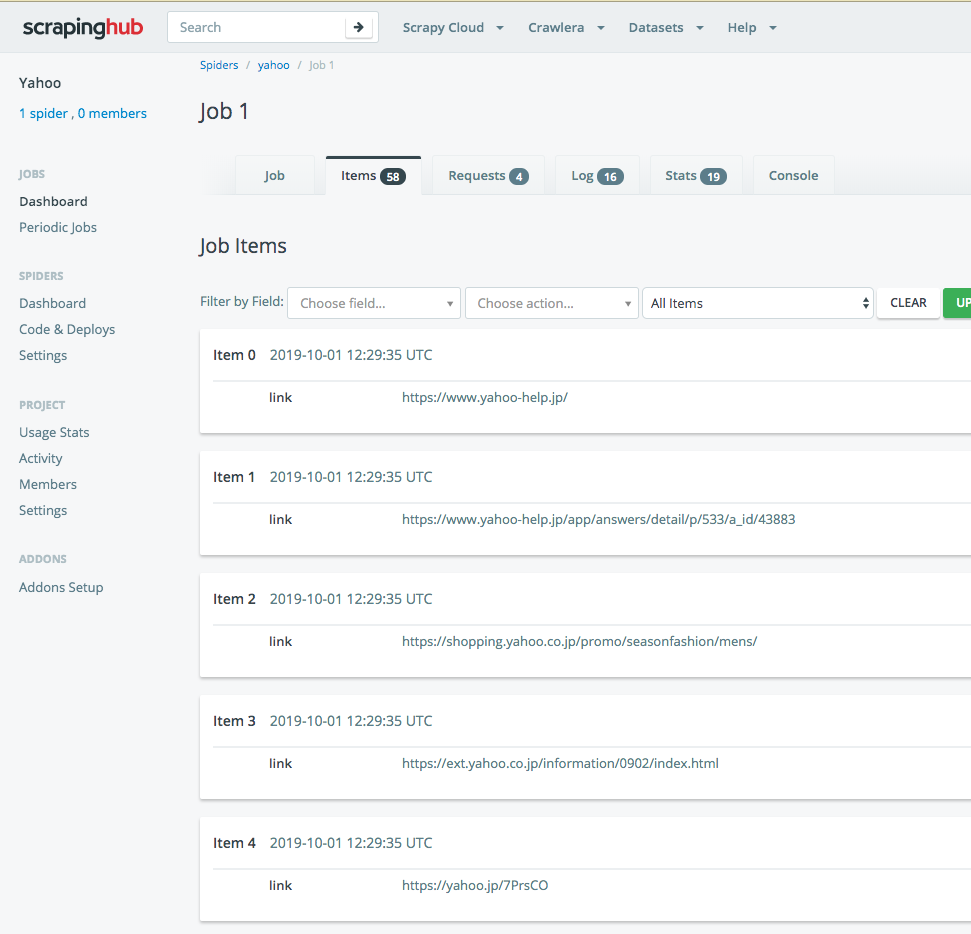
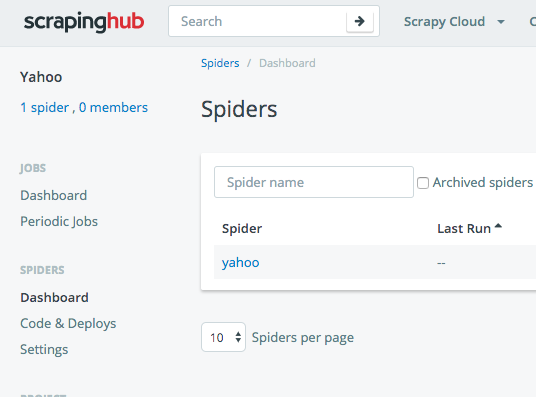
SPIDERSメニューのDashboardをみると、yahooのspiderが登録されます。
RUNボタンを押して動かしてみましょう。
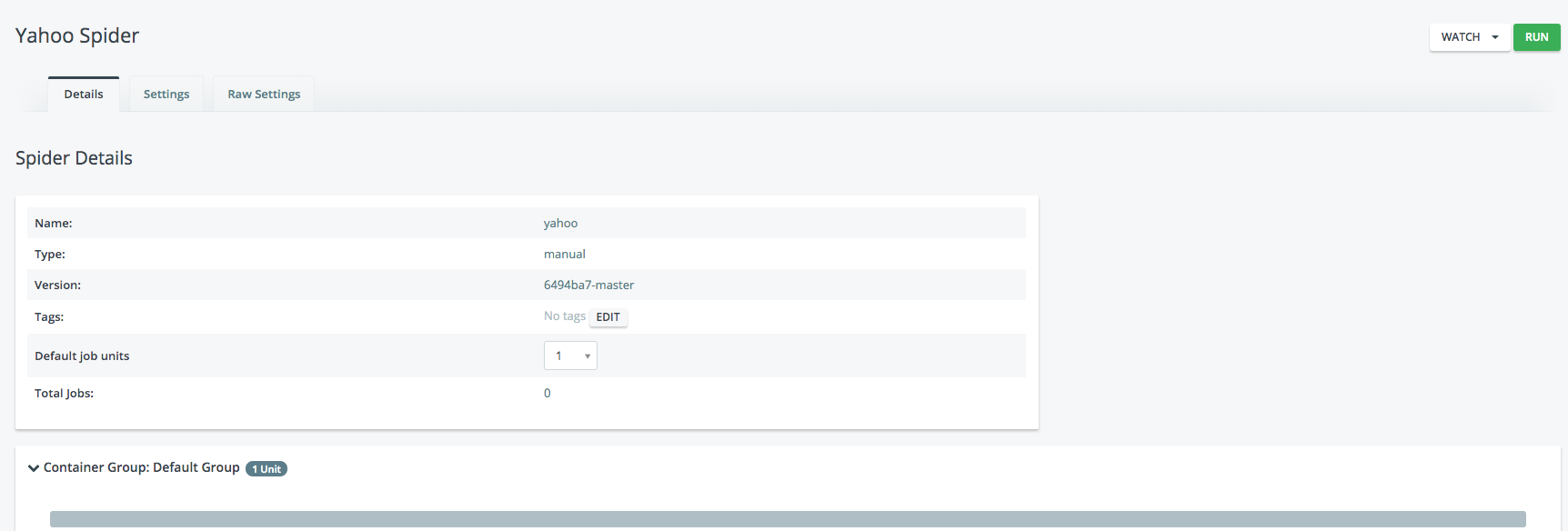
終了するとこんな感じで、結果が出ます。
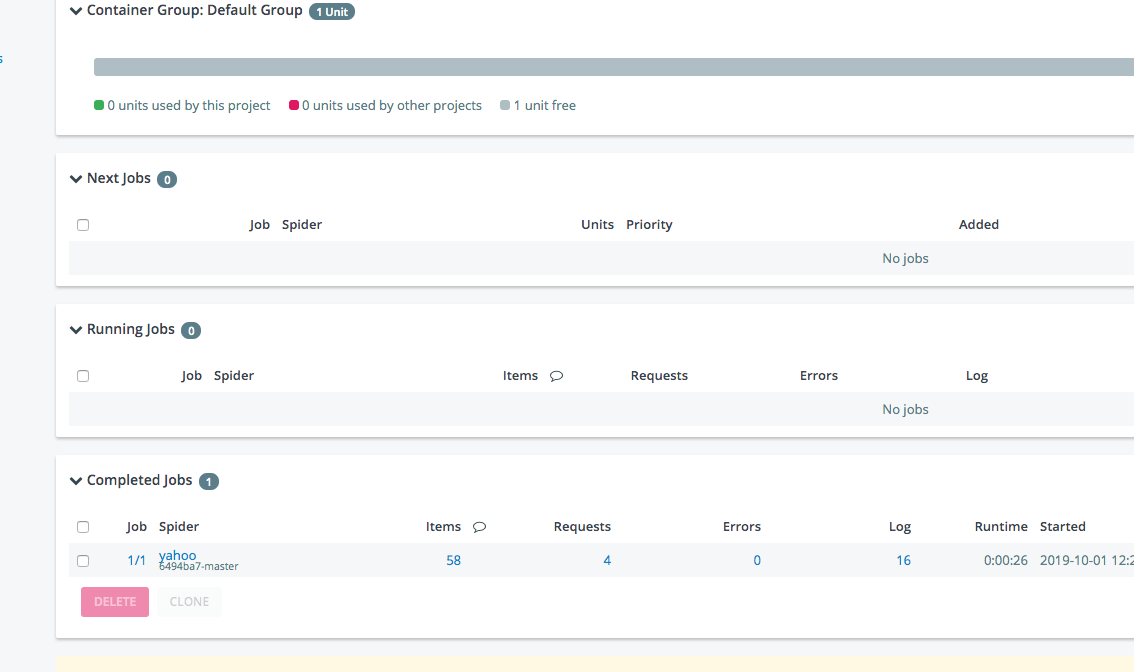
さらにItemsを押すと、1つずつ見れます。
EXPORTからCSVやJSONなどに出力できます。便利です。
このScrapinghubには、apiもあり、結果がすぐAPIの結果して提供されます。
そちらも時間があれば書こうかと思います。