0. 私は誰?
数学科博士課程の院生です。専門は解析であり計算機代数やまして機械学習の知識はほとんどありませんが研究のために計算機を使うことはあり、Pythonだけはなんとか使うことができます。第一回のNNCチャレンジ(画像分類)にも参加しましたが明確な目的意識がなく、知識不足もあってめぼしい成果物は得られませんでした(提出だけはしました)。
1. SONY NNCチャレンジとは
SONYが運営する機械学習の統合開発環境「Neural Network Console (NNC)」を使った機械学習のコンテストです。
コンテストの運営はSONYと株式会社ledgeさんらしいです。概要は以下のURLにあります。
https://nnc-challenge.com/
2. 今回のテーマ
今回の公募で扱うのは音声データということで、自分の中でやりたいことがはっきり決まりました。私はいわゆる"音ゲー"が趣味で、普段から聞いているのはほとんどゲーム楽曲です。その中でも特に大好きな作曲家であるt+pazolite("とぱぞらいと"と読みます。)さんは非常に独特な音楽を作ります。その独特な世界観は機械にも判別できるのではないか、というのが今回のテーマです。つまり「機械はt+pazolite曲を判別できるか」ということです。コンテストテーマに即した言い方をすれば、「お気に入りの楽曲を学習してユーザーに新しい曲をレコメンドする機能を作る」でしょうか。すでにAmazon Prime Musicなどではユーザーに楽曲をお勧めする機能は実装されています。"チャレンジ"としては独自性がないかもしれませんが自分の実力とコンテストの期限を鑑みるとあまりテーマ選択に時間をかけられません。何より自分が興味のあるテーマの方がチャレンジにも気合が入ります。今回はこちらのテーマでいきます。
3. 何が必要か
私の今回のテーマは入力された楽曲がt+pazoliteさん(以下"とぱぞ")によるものかどうか判定する"識別器"を作ることです。つまり何らかの楽曲データを入力したとき、"0"("とぱぞ曲"ではない)または"1"("とぱぞ曲"である)を返すプログラムを(機械が自ら学習して)作ることになります。どんな曲が"0"でどんな曲が”1”かを"0"または"1"のラベル付きの大量の楽曲たちで学習させ、未知の曲に対してこの判定ができるプログラムを作るのです。NNCでは入力は配列なので楽曲データを何らかの形で配列にする必要があります。wav形式の音楽ファイルが配列形式なので楽曲をこの形式に変換します。
(NNC公式ドキュメント、https://support.dl.sony.com/wp-content/uploads/sites/2/2017/11/19120828/starter_guide_sound_classification.pdf)
また、入力データの配列はすべて同じ形の配列であることが必要です。今回はNNC公式から一万曲以上の楽曲データが同じサイズのwav形式で配布されたので(学習用データ提供:Audiostock)こちらに合わせて"とぱぞ曲"を整形します。
4. 楽曲データの整形
"1"判定のデータとしてとぱぞ曲を整形します。手持ちのとぱぞ曲はm4a形式だったのでwav形式に変換する必要があります。こちらの投稿を参考にPythonでプログラミングしました。
(M4AをWAVに変換する(その逆も)
https://wave.hatenablog.com/entry/2017/01/29/160000)
楽曲がwav形式に変換できたら、次はサイズを提供された学習用データと同じサイズに揃えます。楽曲の配列サイズは1.ステレオかモノラルか、2.サンプリングレート、3.楽曲の長さ(秒数)
によって決まります(NNC公式ドキュメント参照)。ステレオモノラルに関しては提供データと手持ちデータが両方ともモノラルだったので変える必要はありませんでした。サンプリングレートに関しては公式配布のものが8kHz、手持ちの楽曲が48kHzだったのでダウンサンプリングする必要があります。ただし、単純にサンプリングレートを6分の1にすると間延びした(遅くなった)楽曲データが生成されるので方法は選ぶ必要があります。こちらの記事の方法で簡単に目当てのサンプリングレート変換を達成できました。
(Downsampling wav audio file
https://stackoverflow.com/questions/30619740/downsampling-wav-audio-file)
最後に楽曲の長さを揃えます。提供データはすべて24秒に整形されていたので手持ち楽曲も24秒に"切りそろえ"ます。こちらの記事を参考に出力ファイルの名前を元楽曲の名前に通し番号を振ったものに変え、フォルダ内のすべての楽曲に対して同様の操作を繰り返すプログラムを書きました。
(【Python】WAVファイルを等間隔に分割するプログラム【サウンドプログラミング】
http://tacky0612.hatenablog.com/entry/2017/11/21/164409)
5. アノテーションCSVファイルの作成
NNCにデータを入力するために、最後にアノテーション作業を行います。アノテーションとは各楽曲に対してそれが"1"であるか"0"であるかのラベルをつけることです。NNCではこの入力を楽曲のパスとその曲に対応する"0"または"1"を書き込んだCSVファイルとしてアップロードすることで行います。楽曲データはCSVに書き込んだパスから自動的にアップロードされます(NNC公式ドキュメント参照)。Pythonで楽曲の入ったフォルダからパスを取得し、CSVに書き出すプログラムを書きました。"とぱぞ曲"と"そうでない曲"を別々のフォルダに配置して、とぱぞ曲のパスに”1”を、そうでない曲に"0"を対応させました。
私はCSVを作った時点で楽曲の順番をシャッフルしましたがNNC上で上がってきたデータをシャッフルする機能があるので特に必要なかったです。
6. 学習
データが揃ったのでいよいよ学習です。なのですがこの時点で締め切り当日の午後2時になっていました。学習にもそれなりの時間がかかることはわかっていたのでNNCのサンプルプロジェクトから音声データ用のものを借りて、入出力を今回のテーマに合わせたものを使うことにしました。具体的にはwav_keyboard_soundというプロジェクトの入力を(96000, 1)、出力前の処理をAffine -> Sigmoid -> Binarycrossentropyに変えたものを使いました。時間配分がうまくいかなかったのは悔しい限りです。
- 結果
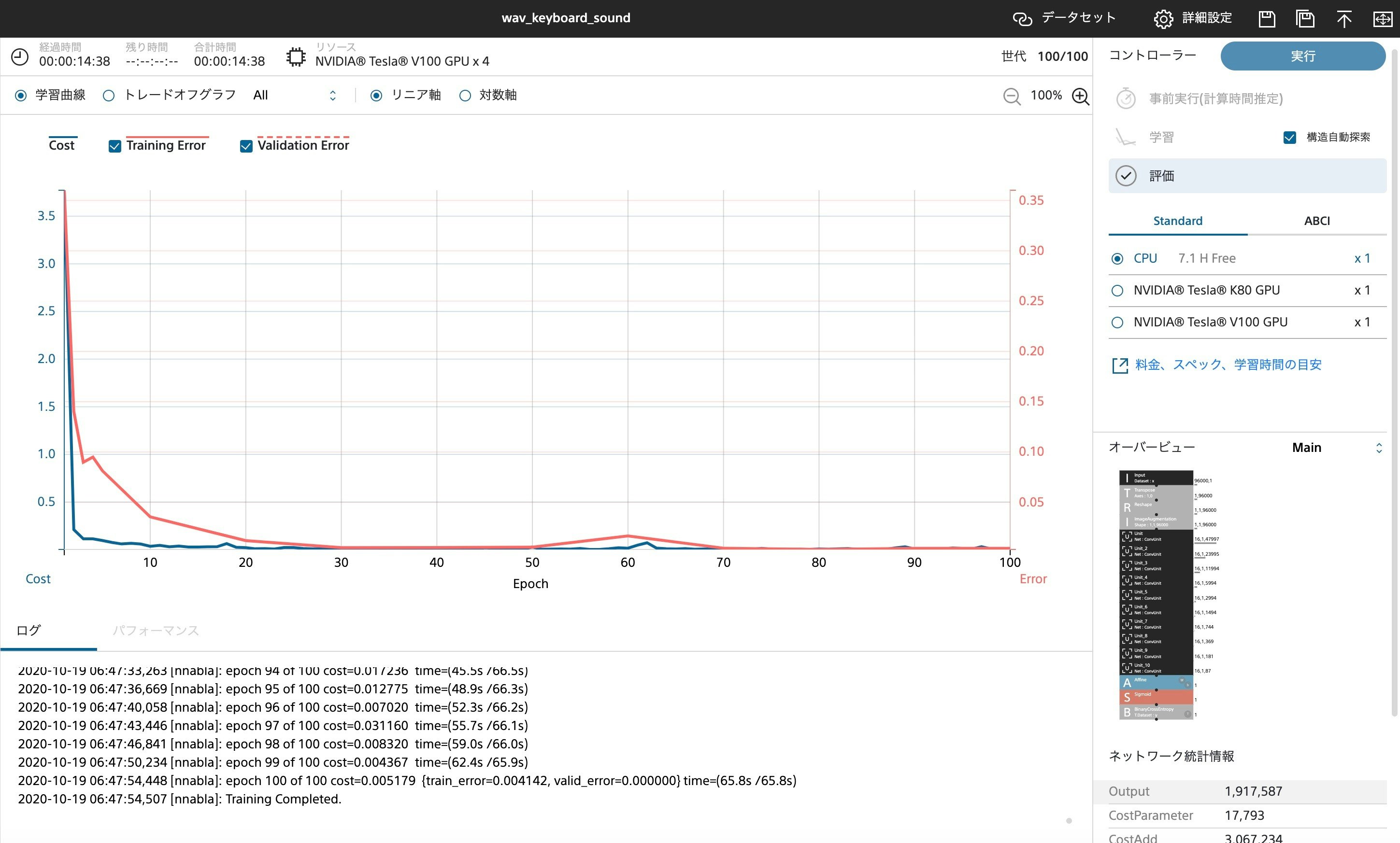
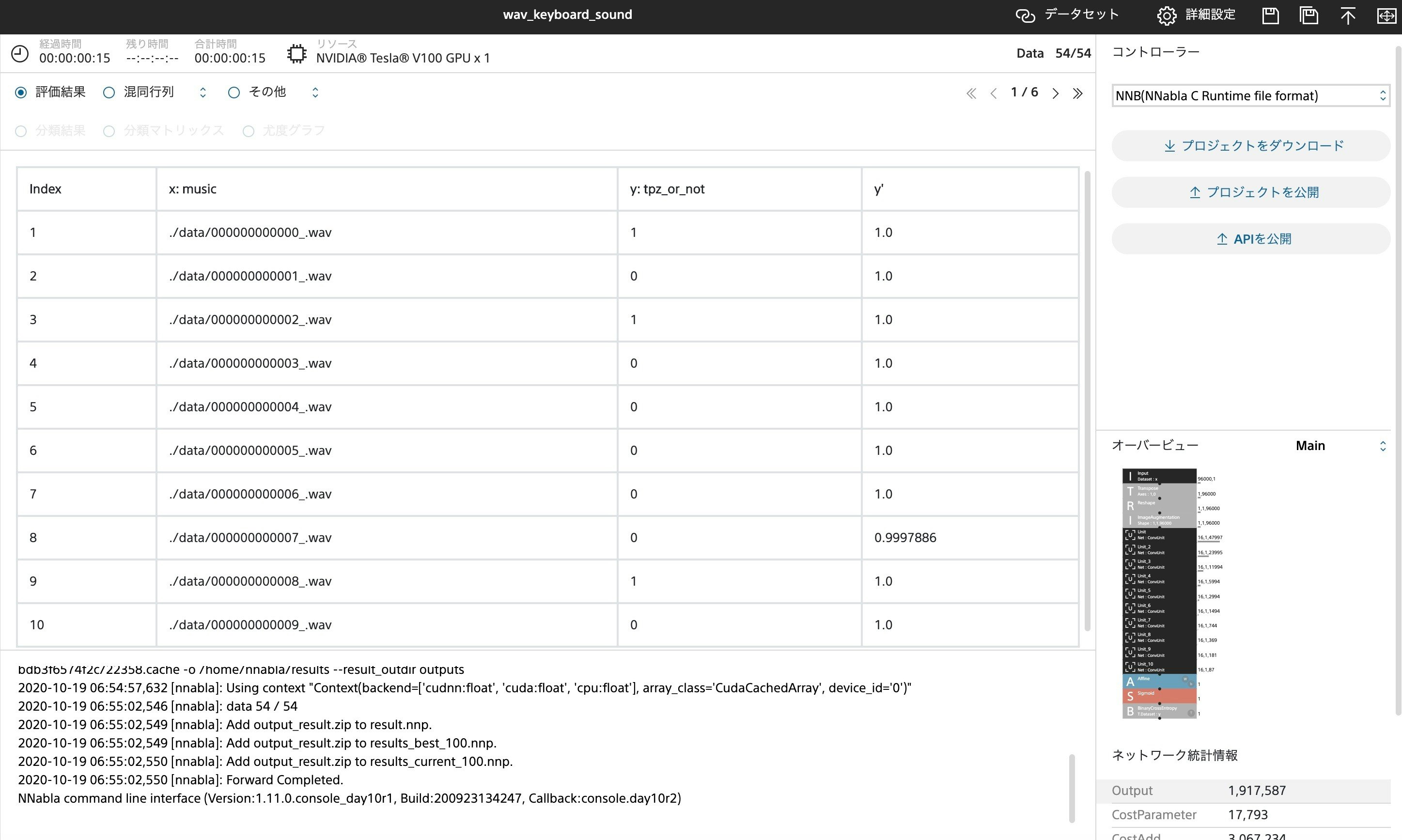
結果はまさに圧倒的で、機械に対しても"とぱぞ曲"が圧倒的な認識率を誇っていることがわかります。写真は楽曲データを12秒に切りそろえたもの5450個を学習に使っています。TESLA V100 4機を用いた学習でこれらの処理に14分でした。CPUでの学習も試みたのですが2時間以上学習にかかり結果を出すことを断念しました。返す返すも時間配分のまずさが悔やまれます。次回があれば与えられた時間をうまく使ってデータの前処理、効率の良い学習等の比較も試せるようにしたいです。