ローカルLLMでファイル検索はどこまで使える?建設業の社内文書に焦点を当てて主要モデルの性能を比較してみた【2026年6月版】
はじめに
業務で扱う社内文書は年々増え続けています。設計計算書、議事録、施工計画書、CAD図面——探したいときに「あのファイルどこだっけ」となることが多いのではないでしょうか。
ファイル名での検索には限界があり、関連ファイルをまとめて探したいときにはそもそも対応できません。かといって ChatGPT などの外部サービスに社内文書をアップロードするのはリスクが伴います。機密情報・個人情報・営業情報が混在している文書は、クラウドに送ること自体が問題になりえます。
そこで 完全オフラインで動くローカルLLMシステム を構築しました。クラウドAPIをまったく使わず、埋め込み・検索・回答生成のすべてをローカルで完結させています。
社内共有フォルダ内の文書(PDF / Word / Excel / PowerPoint / テキスト等)をベクトル化してインデックスし、自然言語の質問に対してローカルLLMが「どのファイルに答えがあるか」を出典つきで回答します。データを一切クラウドに送らず、社内ネットワーク内で完結するのが最大の特徴です。
この記事の構成:
- システム全体像 — 取り込み〜検索の2系統パイプラインと動作画面(テストデータの概要を含む)
- できること・できないこと — 建設業目線でのRAG活用範囲と構造的な限界
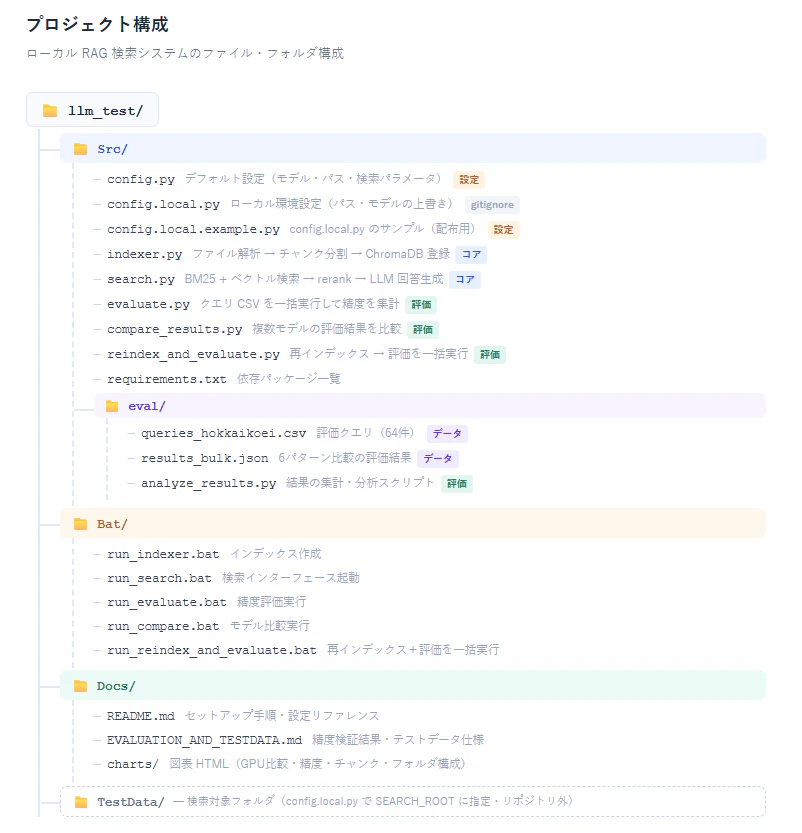
- 対応ファイル形式 — 対応形式一覧・形式別の対応できないケース・差分検出・チャンク分割
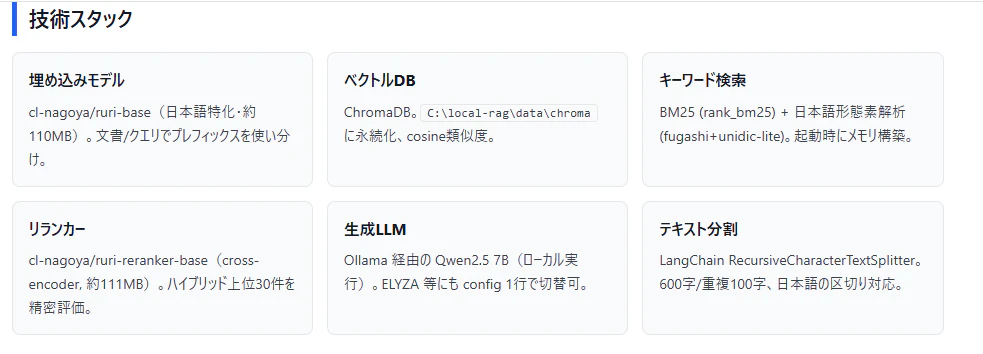
- 検索の仕組み — BM25×ベクトル→RRF→cross-encoderの3段階とキーコード解説
- 精度検証 — 64クエリ・6,204チャンクでのカテゴリ別Hit@K実測
- GPU有無の性能比較 — 精度検証を踏まえた速度面の確認
- モデル比較と選択指針 — 埋め込み×リランカー6パターンの比較と推奨構成
- セットアップ — 導入手順
システム全体像
システムは ① 取り込みパイプライン(バッチ実行) と ② 検索パイプライン(対話CLI) の2系統で、両者がコア基盤(モデル・DB・索引)を介して連携します。
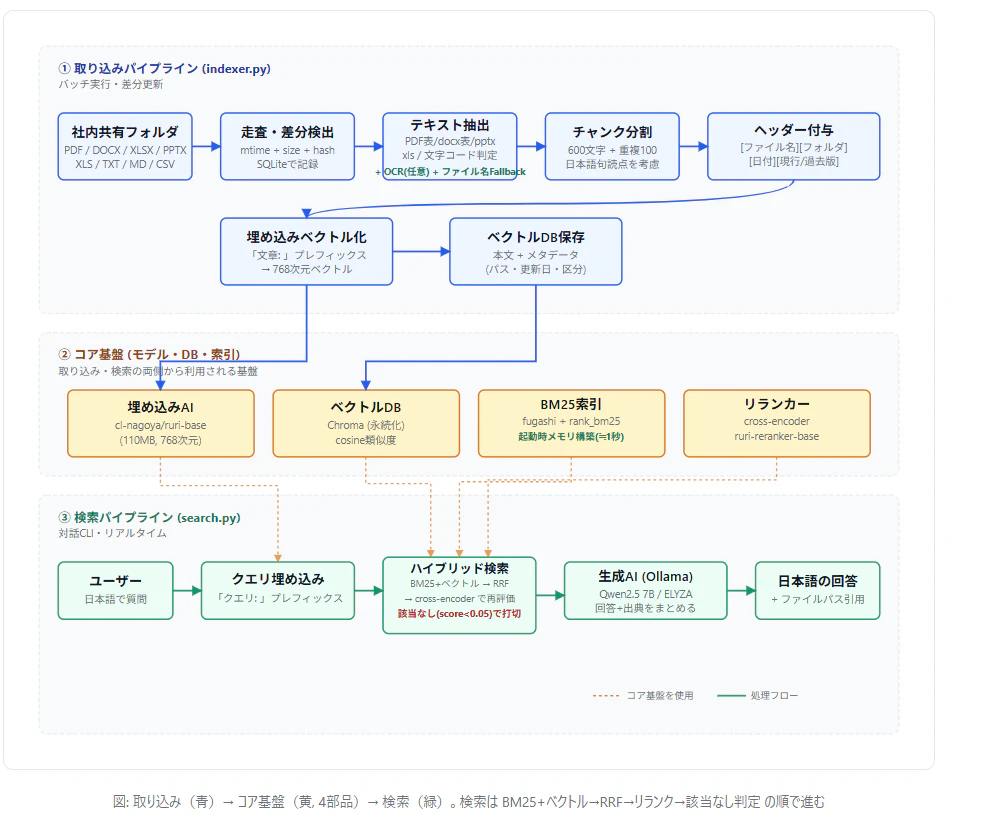
取り込みは run_indexer.bat をダブルクリックするだけで実行できます。差分検出機能により、2回目以降は変更ファイルのみを処理します。検索は run_search.bat で対話CLIが起動し、日本語で質問を入力すると出典つきで回答が返ってきます。
検証用テストデータの概要
本記事の検証には、北海道を舞台にした架空の建設会社の社内フォルダを模したテストデータを使用しています。
| 項目 | 内容 |
|---|---|
| 期間 | H25年度〜R06年度(約12年分、archiveフォルダ含む) |
| ファイル数 / チャンク数 | 604ファイル / 6,204チャンク |
| 工事の種類 | 河川護岸・堤防整備、港湾岸壁補修、道路舗装修繕、橋梁架替・補修 |
| 登場する地名 | 石狩川・豊平川・天塩川・釧路川・留萌川・苫小牧港・函館・帯広など北海道各地 |
フォルダ構成は年度 → 案件番号+工事名 → 施工 / 設計 / 完成図書 / 議事録 / 電子納品(DXF)という階層で、1案件につき施工計画書・設計書・完成報告書・議事録・DXF図面が揃っています。
工事案件フォルダに加えて、以下のフォルダも含んでいます。
- 技術資料ライブラリ:施工指針・設計要領・施工事例集・技術論文・積算基準など
- 業務:石狩川地質調査・流量観測、釧路川水文調査、千歳川治水計画策定、石狩湾海象調査など
- 社内管理:受注実績・品質管理データ・安全管理・業者リスト・議事録など
できること・できないこと
実際に建設業の文書で検証した結果をもとにまとめます。
できること
| 検索の種類 | 精度(Hit@1) | 例 |
|---|---|---|
| 年度での絞り込み | 1.00 | 「R05年度の○○工事」 |
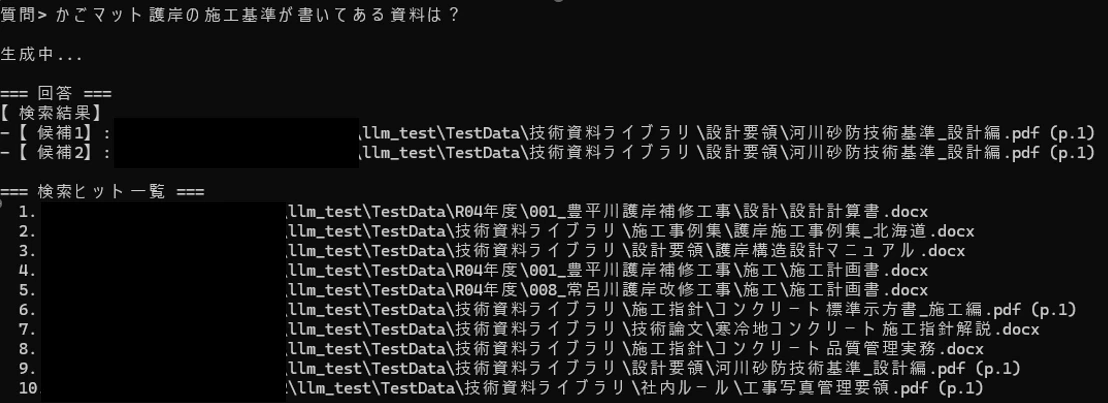
| 技術資料・マニュアルの特定 | 1.00 | 「かごマット護岸の施工基準」 |
| 案件・工事名での検索 | 1.00 | 「豊平川護岸工事の○○」 |
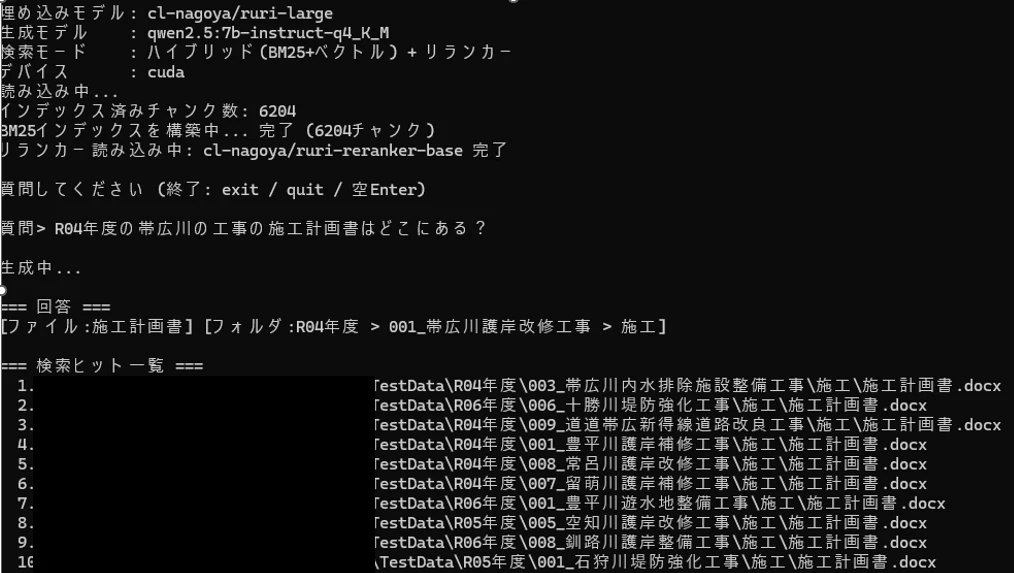
| 複合条件(年度×案件×種別) | 0.92 | 「R04年度、帯広の工事の施工計画書」 |
| 文書種別での絞り込み | 0.90 | 「議事録」「完成検査書類」 |
| 専門技術用語での内容検索 | 0.88 | 「かごマット」「RCP φ600」 |
| DXF図面内の注記・レイヤ名 | — | 「護岸工」「縮尺1/500」のレイヤを持つ図面 |
「いつ・どの工事の・何という書類」という問いには非常に強く、年度・案件・文書種別の組み合わせなら Hit@1 で 90%以上 を達成しています(詳細は「検索精度の実測値」参照)。
できないこと・苦手なこと
RAGの構造的な限界
| できないこと | 理由 |
|---|---|
| 「○○の合計金額はいくら?」 | 複数ファイルにまたがる集計はできない |
| 「最新版はどれ?」 | ファイルの新旧判断はできない(更新日時で並べることも現状は未対応) |
| 「○○と△△の違いは?」 | 複数文書の比較・差分分析はできない |
| 「このXLSXの計算式は正しいか?」 | 数式は検索対象外(計算結果の値は取れる) |
これらはRAGという手法の構造的な限界であり、モデルを変えても解消しません。CAD形式・スキャンPDF・大型Excelなどファイル形式固有の対応状況は、次の「対応ファイル形式」セクションで整理しています。
対応ファイル形式
各形式で「何が取れて、何が取れないか」をまとめます。
対応形式一覧
| 拡張子 | 抽出方法 | 備考 |
|---|---|---|
.pdf |
pdfplumber | ページ単位で抽出 |
.docx |
python-docx | 段落・表・ヘッダー/フッター |
.xlsx / .xls
|
openpyxl / xlrd | シート単位で全セル |
.pptx |
python-pptx | スライド単位 |
.csv / .txt / .md
|
直接読込 | 文字コード自動判定(CP932対応) |
.dxf |
ezdxf | テキスト注記・レイヤ名・タイトル枠属性 |
| 画像(jpg/png等) | Tesseract OCR(任意) | OCR有効時のみ本文抽出 |
形式別の対応できないケース
CAD・図面系
| ケース | 状況 | 対処 |
|---|---|---|
.dwg(AutoCAD標準形式) |
ODA File Converter(無償)未導入の場合はファイル名のみ | 導入すれば自動変換して本文抽出可 |
.sxf .sfc(公共事業電子納品標準) |
ファイル名のみ | OSS変換ツールがほぼなく現状対応困難 |
.jww .jwc(Jw_cad) |
ファイル名のみ | 独自形式のため直接読み取り不可 |
| DXFの図形データ | 取得不可 | 注記・レイヤ名は取れるが、座標・線分・面積などの幾何情報は検索対象外 |
| DXFの埋め込みラスター画像 | 取得不可 | 図面内に貼り付けた写真・スキャン画像の文字は抽出されない |
DXF で取れるのは「テキスト注記」「寸法値の文字」「レイヤ名」「タイトル枠の属性」です。「護岸延長 250m」という注記文字は検索できますが、ポリラインの座標から延長を計算するといった幾何学的な問い合わせはできません。
PDF系
| ケース | 状況 | 対処 |
|---|---|---|
| スキャンPDF(紙の設計図・検査済証等) | OCR無効時はファイル名のみ | OCR有効化(Tesseract導入)で対応可 |
| パスワード付きPDF | 解除不可・スキップ | 事前にパスワードを解除して保存し直す |
| 電子印鑑・電子署名済みPDF | テキスト抽出自体は可能 | 署名情報は検索対象外 |
建設業では完成検査時の書類や官公庁からの通知文書がスキャンPDFで届くことが多く、OCRを有効化しないと本文が取れないケースが相当数ある点は注意が必要です。
Excel・表形式
| ケース | 状況 | 対処 |
|---|---|---|
| 5MB超の大型xlsx(DBダンプ・大規模数量表等) | ファイル名のみ登録 | 設定 LARGE_TABLE_THRESHOLD_KB で閾値変更可 |
| セル内の数式 | 値のみ取得(数式文字列は対象外) | 計算結果の値は取得される |
| グラフ・埋め込み画像内の文字 | 取得不可 | テキストボックス等に転記すれば対応可 |
数量計算書は比較的大きなファイルになることがあり、5MB を超えると本文スキップされます。工事実績の集計表・材料の受払台帳など行数の多いファイルは注意が必要です。
その他
| ケース | 状況 |
|---|---|
| ZIP形式の電子納品パッケージ | 中身は展開されない(中のDXF・PDFは読めない) |
.doc .ppt(旧Office形式) |
ファイル名のみ。LibreOfficeで変換すれば本文対応 |
| 動画(工事記録動画等) | 未対応 |
メール(.eml .msg) |
未対応 |
| IFC(BIMデータ) | 未対応 |
電子納品のZIPパッケージはそのままでは読めません。解凍して格納するか、あらかじめ解凍済みのフォルダを SEARCH_ROOT に指定する運用が必要です。
差分検出
SQLite で各ファイルの mtime + size + MD5ハッシュ を管理し、変化があったファイルだけ再処理します。
初回実行 : 全ファイルをインデックス(数分〜数十分)
2回目以降: 変更ファイルのみ処理(数十秒)
削除検知 : フォルダから消えたファイルはDBからも自動削除
チャンク分割
LangChainの RecursiveCharacterTextSplitter で日本語テキストを 600文字・100文字オーバーラップ で分割します。オーバーラップを持たせることで文脈の断絶を防いでいます。


検索の仕組み:3段階パイプライン
対応ファイル形式とチャンク分割でインデックスができたところで、実際の検索がどう動くかを説明します。単純なベクトル検索ではなく、BM25 × ベクトル検索 → RRF融合 → cross-encoderリランク の3段階で精度を高めています。

① BM25 + ベクトルのハイブリッド検索
| 手法 | 得意 | 苦手 |
|---|---|---|
| BM25(キーワード) | 「20230920_中間検査」など固有名詞・日付 | 言い換え・類義語 |
| ベクトル(意味) | 「締固め管理記録」→ 品質管理記録.xlsx | 固有名詞の完全一致 |
それぞれの弱点を補い合わせることで取りこぼしを減らせます。BM25 の日本語分かち書きには fugashi(MeCab バインディング)を使用しています。
# ベクトル検索(ChromaDB)
query_vec = embed_model.encode(
[f"{config.EMBEDDING_QUERY_PREFIX}{query}"],
normalize_embeddings=True,
)[0]
vec_results = collection.query(query_embeddings=[query_vec.tolist()], n_results=30)
# BM25 検索(fugashi で形態素解析→ランキング)
q_tokens = tokenize(query)
bm25_scores = bm25_index.get_scores(q_tokens)
② RRF(Reciprocal Rank Fusion)で統合
BM25 とベクトル検索のスコアはスケールが異なるため、そのまま加算はできません。RRF は順位ベースで融合するためスコアの正規化が不要で、実装もシンプルです。
def rrf(rank_lists, k=60):
scores = {}
for ranks in rank_lists:
for r, item_id in enumerate(ranks):
scores[item_id] = scores.get(item_id, 0.0) + 1.0 / (k + r + 1)
return sorted(scores.items(), key=lambda x: -x[1])
fused = rrf([vec_ids, bm25_ids], k=60)
k=60 は論文のデフォルト値で、大きいほど下位ランクの影響が緩やかになります。BM25とベクトル双方で上位に来たチャンクが高スコアになる仕組みです。
③ cross-encoder でリランク
RRF 上位30件を cross-encoder で精密スコアリングします。
埋め込みモデル(bi-encoder)は質問と文書を独立してベクトル化して類似度を測りますが、cross-encoder は質問と文書をセットで入力するため、適合度をより精密に判断できます。
def rerank_hits(query, hits, reranker):
pairs = [[query, h["doc"]] for h in hits]
scores = reranker.predict(pairs, show_progress_bar=False)
for h, s in zip(hits, scores):
h["rerank_score"] = float(s)
return sorted(hits, key=lambda x: -x["rerank_score"])
bi-encoder: embed(質問) ↔ embed(文書) のcos類似度 ← 速いが粗い
cross-encoder: [質問 + 文書] を同時入力してスコア出力 ← 遅いが精密
「該当なし」検知
リランクスコアの上位1件が閾値(デフォルト 0.05)を下回る場合、LLMを呼ばずに「関連する文書が見つかりませんでした」と返します。LLMのハルシネーション抑制のために重要な仕組みです。
def is_no_match(hits, has_reranker):
if not hits:
return True
top = hits[0]
if has_reranker and top.get("rerank_score") is not None:
return top["rerank_score"] < NO_MATCH_RERANK_THRESHOLD # デフォルト 0.05
return top.get("vec_sim", 1.0) < NO_MATCH_VEC_THRESHOLD # デフォルト 0.55

検索精度の実測値
64件のテストクエリ(年度・文書種別・技術内容・案件・複合条件・「該当なし」)で評価しました。テストデータは約6,200チャンク(604ファイル)の規模で計測しています。
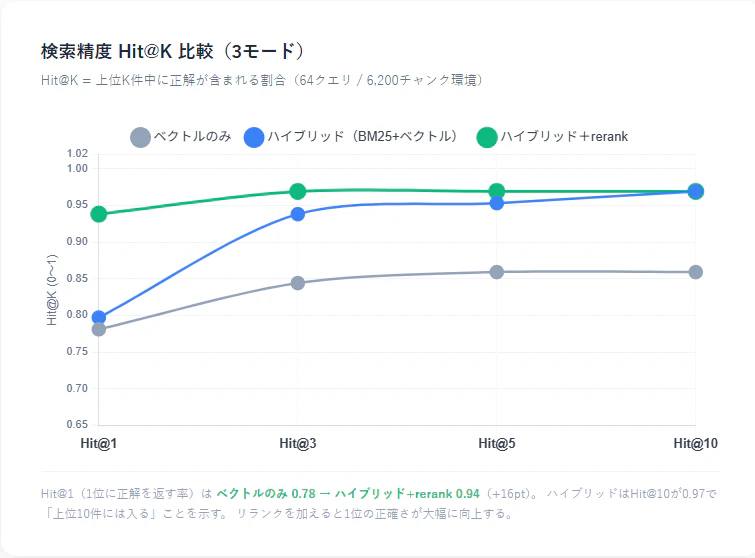
3モード比較(推奨構成 ruri-large + ruri-reranker-base)
| モード | Hit@1 | Hit@3 | Hit@5 | Hit@10 | ms/q |
|---|---|---|---|---|---|
| ベクトルのみ | 0.781 | 0.875 | 0.875 | 0.891 | 14 |
| ハイブリッド(BM25+ベクトル) | 0.859 | 0.938 | 0.938 | 0.953 | 23 |
| ハイブリッド+rerank | 0.953 | 0.984 | 0.984 | 0.984 | 402 |
Hit@K = 上位K件中に正解が1件以上含まれる割合(0〜1)
ベクトルのみ 0.781 → ハイブリッド+rerank 0.953 まで改善しています。BM25の追加で特に Hit@3〜10 が大きく向上し、リランクで Hit@1 が最終的に押し上げられます。
カテゴリ別(ハイブリッド+rerank)
| カテゴリ | Hit@1 | Hit@10 | 件数 | クエリ例 |
|---|---|---|---|---|
| 年度 | 1.00 | 1.00 | 10 | 「R05年度の○○工事」 |
| 技術資料 | 1.00 | 1.00 | 11 | マニュアル・基準書・施工事例集 |
| 案件 | 1.00 | 1.00 | 11 | 工事名・地名での絞り込み |
| 複合条件 | 0.92 | 1.00 | 12 | 年度×案件×文書種別の組合せ |
| 文書種別 | 0.90 | 1.00 | 10 | 「施工計画書」「議事録」 |
| 技術内容 | 0.88 | 0.88 | 8 | 専門用語での検索 |
| 業務 | 0.50 | 0.50 | 2 | 観測業務ファイルの検索 |
強い領域と弱い領域がはっきり分かれます。 「いつ・どの工事の・何の書類」という問いには非常に強い一方、数値データが中心のExcelファイルへの「技術内容」系クエリや、特定業務のニッチなファイルは精度が落ちます。
「該当なし」判定精度
| モード | 正解率(7件) |
|---|---|
| ベクトルのみ | 0/7(0%) |
| ハイブリッド | 0/7(0%) |
| ハイブリッド+rerank | 4/7(57%) |
ベクトルのみ・ハイブリッドは「何でも何かを返してしまう」状態です。リランカーのスコア閾値判定のみが「該当なし」を正しく判定できています。残り3件の見逃しは「リランクスコアは低くないが正解ではない」ケースで、閾値チューニングによる改善余地があります。
GPU 有無の性能比較
精度を確認したところで、速度面の比較を見ます。埋め込みモデルとリランカーはCUDA対応GPUがあれば自動でGPU動作し、なければCPUにフォールバックします。
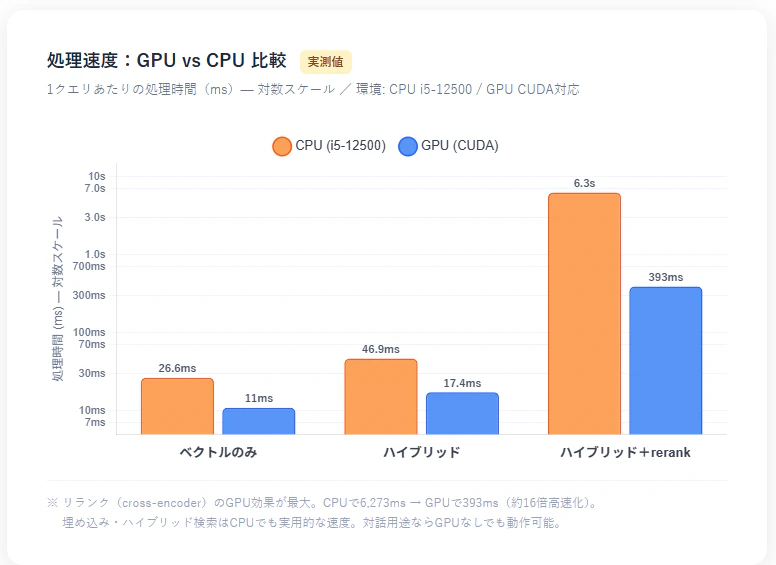
| モード | CPU(i5-12500相当) | GPU(CUDA対応) | GPU倍率 |
|---|---|---|---|
| ベクトルのみ | 26.6 ms/q | 11 ms/q | ×2.4 |
| ハイブリッド | 46.9 ms/q | 17 ms/q | ×2.8 |
| ハイブリッド+rerank | 6,273 ms/q | 402 ms/q | ×16 |
GPU列は ruri-base(270MB)での計測値。ruri-large では GPU 14ms・23ms・402ms。CPU列は ruri-base での計測値。
リランク処理のGPU効果が圧倒的で、CPUで約6秒かかる処理がGPUでは約0.4秒になります。対話用途であればCPUでも実用的な速度ですが、バッチ評価など大量クエリを処理する場合はGPUが有効です。
CUDA検出は自動なので、GPU搭載マシンでは設定変更なしに高速化されます。
モデル比較
埋め込みモデルとリランカーの組み合わせを6パターン評価しました。すべて同一テストセット(64クエリ・6,204チャンク)・ハイブリッド+rerank モードで比較しています。
| パターン | 埋め込みモデル | リランクモデル | Hit@1 | Hit@10 | ms/q |
|---|---|---|---|---|---|
| ベースライン | ruri-base | ruri-reranker-base | 0.938 | 0.969 | 392 |
| A | ruri-base | ruri-reranker-large | 0.906 | 0.984 | 1,295 |
| B ★推奨 | ruri-large | ruri-reranker-base | 0.953 | 0.984 | 402 |
| C | ruri-large | ruri-reranker-large | 0.922 | 0.984 | 1,247 |
| D | ruri-v3-310m | ruri-v3-reranker-310m | 0.891 | 1.000 | 1,332 |
| E | multilingual-e5-large-instruct | ruri-reranker-base | 0.953 | 0.969 | 465 |
わかったこと:
- 埋め込みを large にする効果が大きい(ベースライン→B: +1.5pt)。速度コストもほぼなし(392ms→402ms)
- リランカーを large にすると Hit@1 が下がる(B→C: -3.1pt)。モデルが大きいほどスコア差が均一化され、1位の確信度が落ちると考えられる
- ruri-v3 は Hit@10 が完全一致(1.000) だが Hit@1 は最下位。上位10件のカバレッジは最高だが、正確な1位選択は苦手
- multilingual-e5-large-instruct はパターンBと同率 Hit@1(0.953)。日本語特化の ruri-large と同等の精度を多言語モデルが達成しており、驚きの結果
結論: ruri-large(埋め込み)+ ruri-reranker-base(リランク)が Hit@1・速度のバランス最良。多言語対応が必要な用途では multilingual-e5-large-instruct も有力な選択肢。
この比較結果をもとに、導入時のモデル選択指針をまとめます。
埋め込みモデル(検索精度に直結)
| モデル | サイズ | Hit@1 | 備考 |
|---|---|---|---|
cl-nagoya/ruri-base |
約270MB | 0.938 | 軽量・高速。まず試すならこれ |
cl-nagoya/ruri-large ⭐ |
約560MB | 0.953 | 推奨。精度・速度のバランス最良 |
intfloat/multilingual-e5-large-instruct |
約560MB | 0.953 | 多言語対応が必要な場合に有力 |
cl-nagoya/ruri-v3-310m |
約620MB | 0.891 | Hit@10=1.000 だが Hit@1 は低い |
リランクモデル(Hit@1精度に直結)
| モデル | サイズ | Hit@1(ruri-large組合せ) | 備考 |
|---|---|---|---|
cl-nagoya/ruri-reranker-base ⭐ |
約270MB | 0.953 | 推奨。large より Hit@1 が高い |
cl-nagoya/ruri-reranker-large |
約560MB | 0.922 | Hit@10 は高いが Hit@1 は低下 |
生成モデル(Ollama経由)
| モデル | サイズ | 速度(CPU) | 特徴 |
|---|---|---|---|
qwen2.5:7b-instruct-q4_K_M ⭐ |
約4.7GB | ~6.6 tok/s | 軽量・高速・バランス良 |
qwen2.5:14b-instruct-q4_K_M |
約8.5GB | ~3.4 tok/s | 高精度・回答1問あたり1〜2分 |
elyza/llama-3-elyza-jp-8b |
約5GB | ~6 tok/s | 日本語特化 |
生成モデルもGPU搭載時は大幅に高速化されます(CPU 6.6 tok/s → GPU 30〜60 tok/s 程度)。
セットアップ
モデルが決まったら、以下の手順で環境を構築できます。
# 1. venv 作成
python -m venv .venv
.\.venv\Scripts\Activate.ps1
# 2. 依存ライブラリのインストール
pip install -r Src\requirements.txt
# 3. Ollama で生成モデルを取得
ollama pull qwen2.5:7b-instruct-q4_K_M
# 4. 検索対象フォルダのパスを設定
cp Src\config.local.example.py Src\config.local.py
# config.local.py の SEARCH_ROOT を社内フォルダのパスに変更
# 5. インデックス作成(初回のみ数分〜数十分)
Bat\run_indexer.bat
# 6. 検索開始
Bat\run_search.bat
個人環境の差分は config.local.py か環境変数 LOCAL_RAG_* で上書きできます。このファイルは .gitignore 対象なので社内パスがGitに入りません。
まとめ
| 項目 | 内容 |
|---|---|
| 構成 | ChromaDB + ruri-large + Ollama + BM25。完全ローカル動作 |
| ネットワーク要件 | 初回モデルDLのみ。以降はオフライン可 |
| 検索精度(Hit@1) | ベクトルのみ: 0.781 → ハイブリッド+rerank: 0.953 |
| GPU効果 | リランク処理が約16倍高速化 |
| 対応形式 | PDF / Word / Excel / PowerPoint / CSV / DXF 等 |
| 「該当なし」判定 | リランクスコア閾値で57%正解(ベクトルのみは0%) |
使える場面: 「R05年度の豊平川工事の施工計画書はどれ?」「かごマット護岸の施工基準が書いてあるマニュアルは?」のような、年度・案件・文書種別・技術キーワードを組み合わせた検索。
使えない場面: 「今期の工事費合計はいくら?」(集計)、「最新版の設計書はどれ?」(更新日時の比較)、「この図面の護岸延長を計算して」(幾何演算)。また、スキャンPDF・JWW・SXF は設定追加か別途変換が必要です。
モデル比較の結論として、日本語特化の ruri-large が精度・速度ともに最良でしたが、多言語モデル(multilingual-e5-large-instruct)も同等の Hit@1 を達成しており、多言語ニーズがある環境でも実用水準に達することが確認できました。BM25・ベクトル・cross-encoder の3段階構成は、日本語専門文書の検索において安定した効果があると言えます。GPUがなくても動作しますので、まず手元の環境で試してみてください。