初めに
点群データに限らずjupyterでデータ処理しながら、可視化を行うという作業はよくあると思いますが、点群データ(特にlasデータ)をjupyter上で可視化しようとすると、実はちょっと手間です。
- Open3Dでは点群データを読み取るメソッドが存在しているが、lasは未対応
- pyntcloudではインスタンスをOpen3Dの点群インスタンスにコンバートする機能があるが、pyntcloud自体に、las読み取りのバグが存在する
- leafmapではサクッと読み取れるが、ビューワーのカスタマイズができないため、高度(Z座標)を使って勝手に色付けされる
など、痒いところに手が届かない感じです。
この記事では、jupyterを使ってlaspyで読み取った点群データをうまいことnumpyに処理させながら、Open3Dのインスタンスを作成し、ビューワーをカスタマイズ(色味・ポイントの大きさ・背景色など)する方法を伝えていきます。
データのダウンロードと加工
今回は以下の記事で作成したLAZ形式(LASの圧縮形式)のデータを利用していきます。
古いlasデータをLAStoolsで最新版にアップグレードして、さらにLAZに圧縮にしてファイルサイズを1/4以下にする
が、お手持ちのlasデータでも問題ありません。
手頃なlasデータをお持ちでない方は、以下のサイトから沢山ダウンロードできますので活用してみてください。
laspyで読み込み
データは上記サイトからダウンロードし、LAZに圧縮し、さらにバージョンを上げた08OF1348_1_4.lazを利用していきますが、お手持ちのファイル名に適宜読み替えてください。
また、jupyterをインストールしていない!というかたはこちらを参考にしてみてください。
- MacでGISデータ分析を始めるためにサクッとAnacondaとjupyter labをインストールしてみる
- jupyter labで最低限これだけは入れとけっていう拡張機能の紹介!
- Pythonで地理空間情報(GIS)やるために必要なパッケージ全部入りの「geospatial」が便利すぎた
まずは必要なモジュールをインポートします。
import laspy as lp
import numpy as np
import open3d as o3d
import pandas as pd
laspyにファイルを読み込ませます。
古いlasデータをLAStoolsで最新版にアップグレードして、さらにLAZに圧縮にしてファイルサイズを1/4以下にする を参考にされた方はインストール済みかと思いますが、laspyはそのままではLAZ形式を取り扱うことはできず、拡張版をpypiからインストールして利用する必要がありますのでご注意ください。
file_path = "08OF1348_1_4.laz"
laz = lp.read(file_path)
lazの情報を見てみましょう。
laz
# <LasData(1.4, point fmt: <PointFormat(7, 0 bytes of extra dims)>, 10647410 points, 0 vlrs)>
ポイントが持っているデータを確認してみましょう。
point format 7という形式なので、xyzとrgbを持ってることが確認できます。
list(laz.point_format.dimension_names)
# ['X',
# 'Y',
# 'Z',
# 'intensity',
# 'return_number',
# 'number_of_returns',
# 'synthetic',
# 'key_point',
# 'withheld',
# 'overlap',
# 'scanner_channel',
# 'scan_direction_flag',
# 'edge_of_flight_line',
# 'classification',
# 'user_data',
# 'scan_angle',
# 'point_source_id',
# 'gps_time',
# 'red',
# 'green',
# 'blue']
numpyの配列を見てみる
読み込んだlazのXYZやRGBなどプロパティは、numpyのndarrayになっています。
lasデータは以下の記事に記載の通り、XYZには整数しか格納できません。
後ほど諸々いじっていきますが、正しい座標を取得するにはscaleやoffsetを考慮する必要があることを頭に入れておきましょう。
iPhoneでも使えるようになったLiDARの標準ファイル形式「LAS」ってどんなデータなの?を、PDAL/Laspyを使って調べてみる。
そのうえで、X座標を見てみると以下のように整数値が格納されているのが確認できます。
laz.X
# array([55200070, 55200090, 55200090, ..., 55599975, 55599985, 55599995],
# dtype=int32)
Xだけ取り出すと、当然1次元の配列になっていることがわかります。
laz.X.ndim
# 1
形状を確認するとn行1列の配列に見えますが、numpyでは1次元配列は行と列の区別がないらしく、行ベクトルとして扱われる上、転置しても形状は変わりません。
laz.X.shape
# (10647410,)
laz.X.T.shape
# (10647410,)
余談ですが、n行1列の列ベクトルを明示的に示したいときはreshapeを利用して2次元配列にする必要があります。
laz.X.reshape((-1, 1))
# array([[55200070],
# [55200090],
# [55200090],
# ...,
# [55599975],
# [55599985],
# [55599995]], dtype=int32)
laz.X.reshape((-1, 1)).shape
# (10647410, 1)
scaleとoffsetを考慮して再計算し、XYZを持ったOpen3Dのインスタンスを作成する
Open3Dのインスタンスを作るには、Open3DのVector3dVectorという形式に合わせる必要があるので、形状を修正していきましょう。
とはいえ難しいことではなく、n行3列の形式に結合・変更してあげれば良いだけです。
numpyのstackメソッドには同じ形状を持った複数の配列を、配列に入れて渡すことで、入力よりも1次元多い配列が返されます。
例えばstackを行方向(axis=0)で使うと垂直に繋がるので3行n列になります。
前述の通り、1次元配列は行と列の区別がなく、行ベクトルであるため、垂直方向に要素が結合され、3行n列の2次元配列ができました。
points = np.stack([laz.X, laz.Y, laz.Z], axis=0)
points.shape
# (3, 10647410)
ちなみにvstackというメソッドは縦(行)方向に結合するので、stack(axis=0)と同様の結合ができます。
points = np.vstack([laz.X, laz.Y, laz.Z])
points.shape
# (3, 10647410)
列方向(axis=1)でstackを使うと当然n行3列の2次元配列ができます。
points = np.stack([laz.X, laz.Y, laz.Z], axis=1)
points.shape
# (10647410, 3)
stackをaxis=0で利用した場合や、vstackを使った2次元配列に対して、transposeを利用すると、axis=1を利用した時と同じ結果を得られます。
points = np.stack([laz.X, laz.Y, laz.Z], axis=0).transpose()
points.shape
# (10647410, 3)
似たようなメソッドにhstackというものがありますが、これは横(列)方向に結合するので、1次元配列をaxis=1でstackするのとはちょっとイメージが異なり、今回の場合は1次元配列のまま、配列長が伸びます。
points = np.hstack([laz.X, laz.Y, laz.Z])
points.shape
# (31942230,)
ごちゃごちゃと話しましたが結果的に、XYZの1次元配列3つに対して、stackをaxis=1で利用してn行3列の配列を作っていきます。
points = np.stack([laz.X, laz.Y, laz.Z], axis=1)
ただし、これではscaleとoffsetが考慮されていないので、座標が整数のままです。
これを修正していきましょう。
以下のようにして、lazのヘッダーが持つscalesとoffsetsを考慮して座標を計算していきましょう。
data = pd.DataFrame(las.points.array)
data.columns = (x.lower() for x in data.columns)
data.loc[:, ["x", "y", "z"]] *= las.header.scales
data.loc[:, ["x", "y", "z"]] += las.header.offsets
その後、再計算されたポイントデータを利用して再度変数を作ります。
points = np.stack([data.x, data.y, data.z], axis=1)
Open3Dの点群インスタンスを作成し、そこにデータを格納していきます。
geom = o3d.geometry.PointCloud()
geom.points = o3d.utility.Vector3dVector(points)
これで点群を可視化できる基盤ができました!
実際にビューワーで確認してみましょう。
o3d.visualization.draw_geometries([geom])
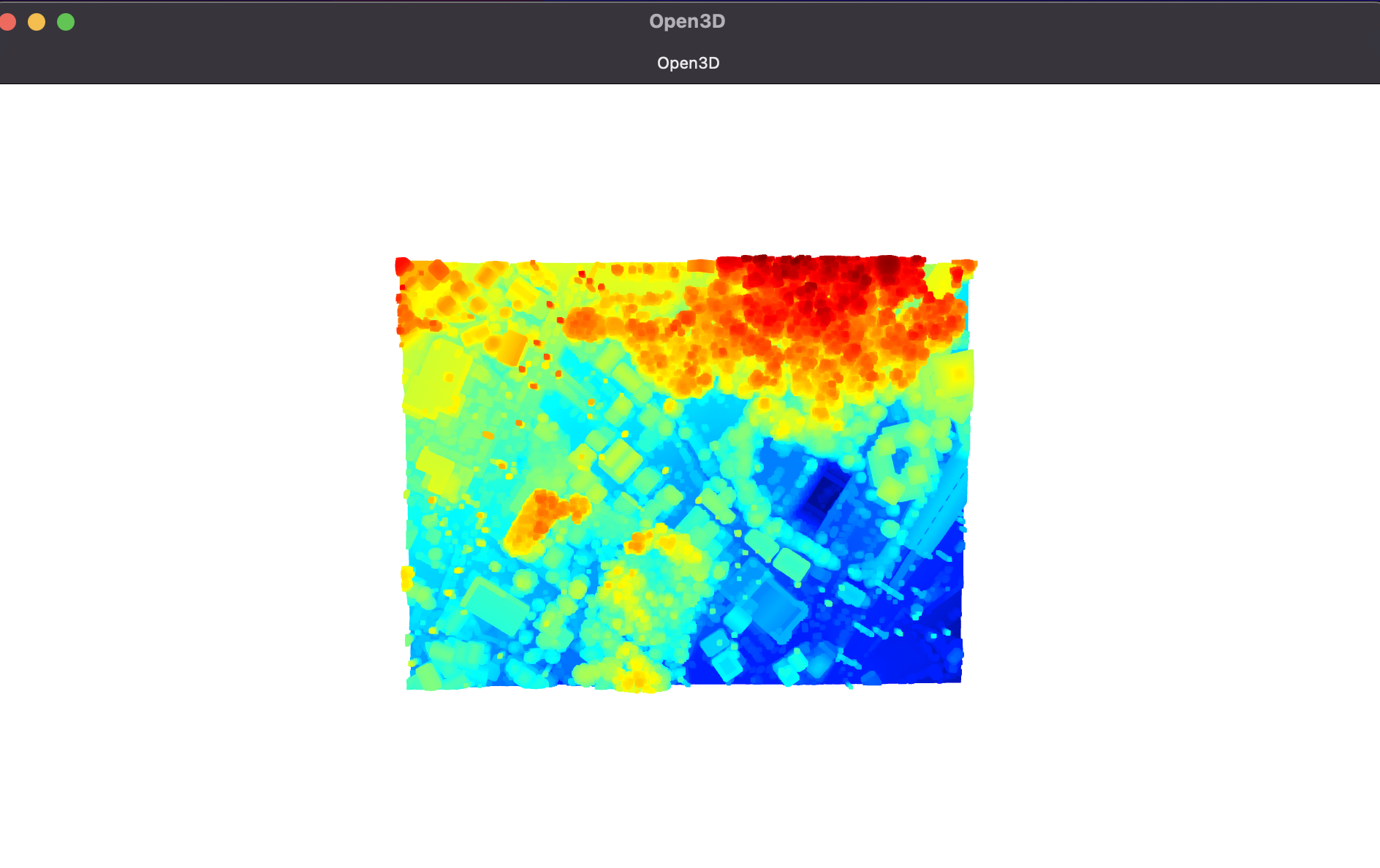
うーん。RGBを取り込んでいない上、デフォルトでは高度ごとに勝手に色分けされて表示されるため、色々微妙ですね。
また、このビューワー、閉じるのがめっちゃめんどくさくて、起動するのに利用したインタープリターを強制的に停止させてあげないとなかなか閉じてくれません。
ひとまずビューワーを改善していきましょう。
Open3Dのビューワーをカスタマイズ
こんな関数を定義してあげましょう。
import open3d.visualization.gui as gui
import open3d.visualization.rendering as rendering
def visualize(data):
app = gui.Application.instance
app.initialize()
vis = o3d.visualization.O3DVisualizer("Open3D visualizer", 1024, 768)
vis.show_settings = True
vis.add_geometry("data", data)
vis.reset_camera_to_default()
app.add_window(vis)
app.run()
詳しい設定方法は以下ですが、これでこのようなことが出来るようになっています。
http://www.open3d.org/docs/release/python_api/open3d.visualization.O3DVisualizer.html
- 1024 * 768の解像度で表示
Open3D visualizerという名称でビューワーを表示- 点群のサイズなど変更できるメニューを追加
字面だけでは分かりづらいと思いますので、実際に見てみましょう!
visualize(geom)
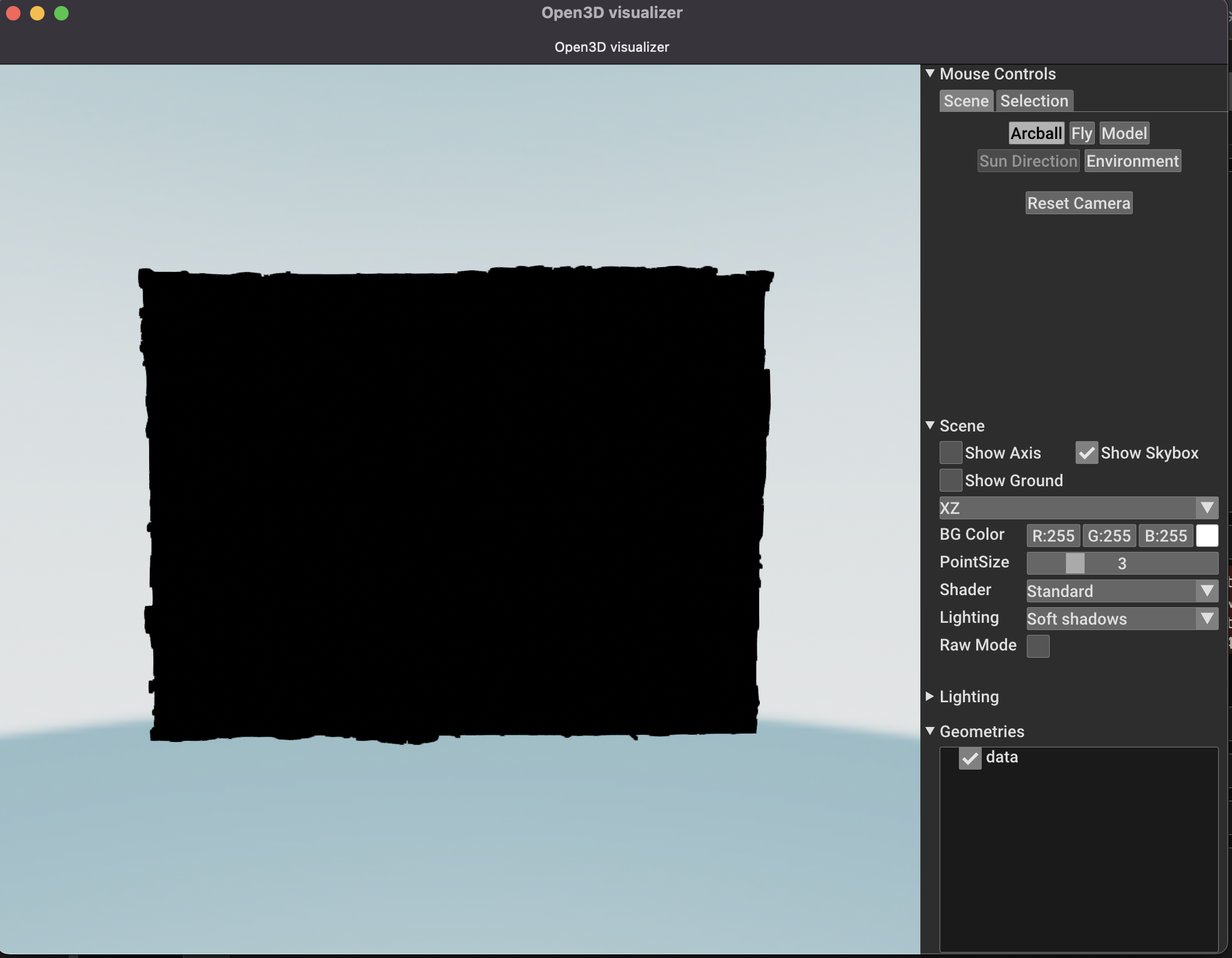
だいぶリッチになりましたね!
ただ、肝心の色情報がないので、そちらを追加していきましょう。
RGBをインスタンスに付与
lasの仕様として、RGBはuint16じゃないといけなかったはずですが、たまに守られていないデータもあるっぽいので、正規化していきます。
uint8だった場合は値に256を掛けていきます。
color_dtypes = [data[column_name].dtype for column_name in ["red", "green", "blue"]]
color_dtype = color_dtypes[0]
if color_dtype == "uint8":
data.loc[:, ["red", "green", "blue"]] *= 256
data = data["points"].astype({"red": "uint16", "green": "uint16", "blue": "uint16"})
その後pointと同様に2次元配列にまとめて、Vector3dVectorに変換して先ほど作成したgeometryに格納していきましょう。
このとき、colorの範囲に制限(0~1?)があるので、RGB値を65535で割っていきましょう。
先ほど正規化したおかげで、ちゃんとしたカラーで表示されるようになるはずです。
colors = np.stack([data.red, data.green, data.blue], axis=1)
geom.colors = o3d.utility.Vector3dVector(colors / 65535)
では可視化していきましょう。
visualize(geom)
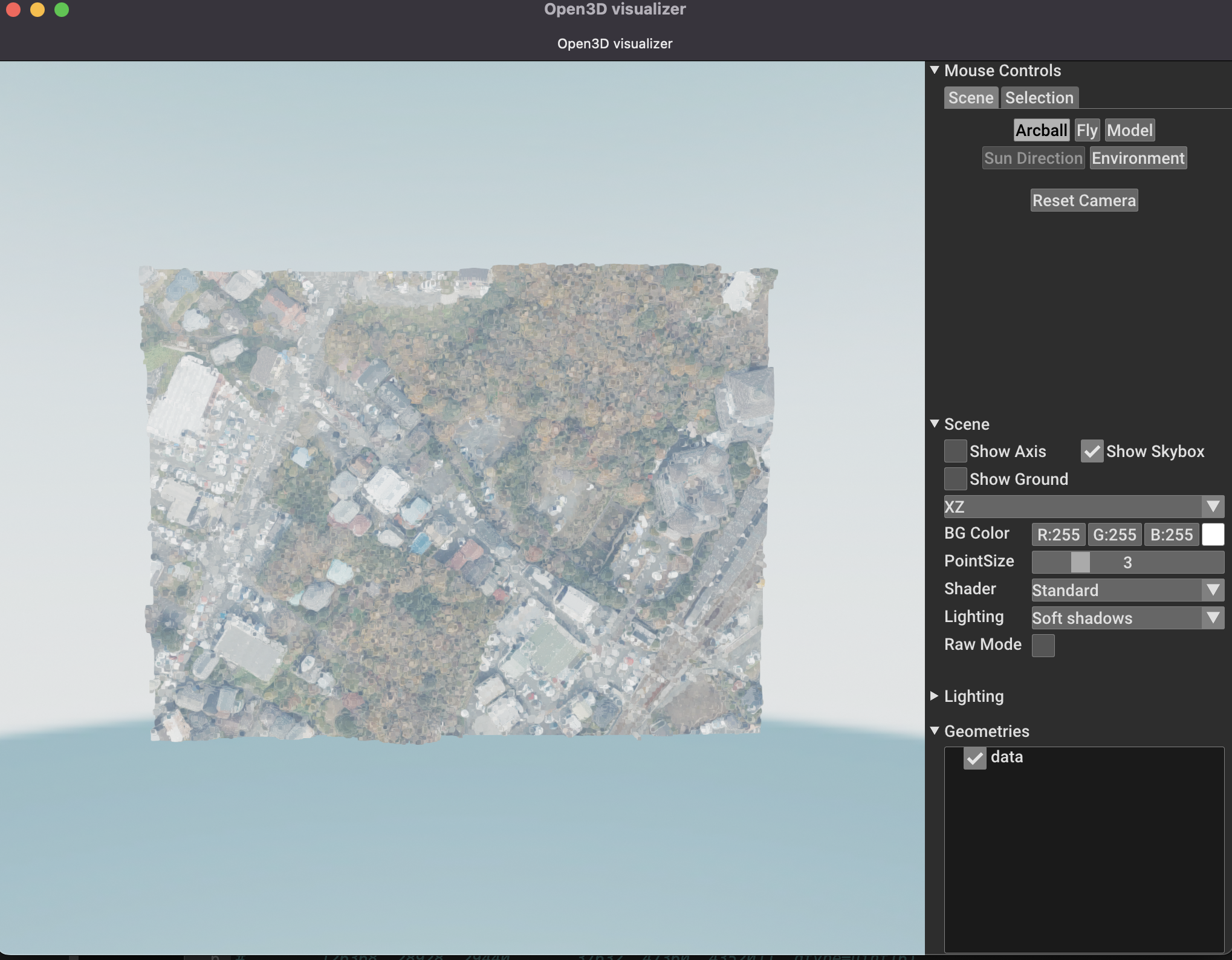
色もしっかり表示されましたね!
終わりに
ということで、jupyterとlaspyとOpen3Dを利用して、ただ表示するだけではなく、Open3Dのgeometryの作り方を学びながら、かつビューワーをカスタマイズして表示させていきました。
これでデータ処理しながら点群を可視化できるようになったと思いますので、みなさんどんどん点群を活用していきましょう!