↑5000万ポイント・500MBのParquet
はじめに
最近、点群データはParquetにするのも悪くないんじゃなかろうか、と思っています。
LASファイルのような点群データに特に特化した形式の場合、仕様がカチッと決められておりそれはもうパースしやすくプログラムで大変処理しやすいです。
LAZなんかは、列ごとに超最適圧縮されているため、そもそも効率の良いLASと比較しても、ファイルサイズが1/10になることもあります。
なので、データ配布・分析などの用途では当然これらのファイルを利用するのが良いです。
が、とはいえ、意外とLAS形式で定義されている以外の属性情報を利用したいタイミングはあるのかなーとも思います。
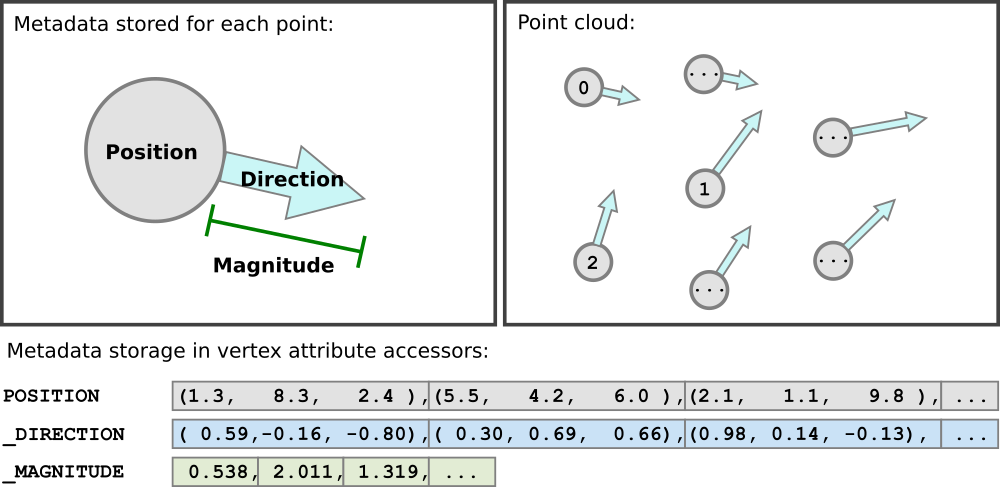
例えば「気象データのパーティクルアニメーションを作りたい!」と思うと、(当然、テクスチャに埋め込む方が軽量ではあるが)各ポイントにu, v, wのような3次元のベクトルを埋め込んでおけばそれだけでアニメーションできてしまったり、他にも各ポイントに地物idを振り分けてポイントを区別したり、RGB以外で色の表現をしてみたり…
3D TilesのEXT_structural_metadataなんかはそんなイメージですよね。
(https://github.com/CesiumGS/glTF/tree/3d-tiles-next/extensions/2.0/Vendor/EXT_structural_metadata )
こういったことをするためには、自由形式のフォーマットを利用することなるわけですが、今まではcsvのようなデータ形式を利用していたのかなと思います。
であれば!Parquetはそこに差し込むには最適なデータフォーマットなのかもしれません。
今回はParquetで点群データを作成し、それをDeck.glで描画してみることまでやります。
ただ、描画はまぁ普通にできてしまうので、Parquetらしいことができるように
- row group単位のmin/maxを利用して範囲指定で表示点群を間引く
- 間引きが出来るように点群を整列してから書き出す
をやってみます。
点群データを作ってみる
ParquetにGISデータを入れたい場合、特殊なメタデータを持つGeoParquetを利用できます。
ただ、こちらはジオメトリをWKBで格納する必要があり、ラインとかポリゴンならいいと思うんですが、ポイントだとちょっと重たくなっちゃいます。
(v1.1.0からは効率良くなってるっぽいですが: https://geoparquet.org/releases/v1.1.0/ )
今回は今までCSVだったものを、置換していきたいと思ったのがモチベなので、余計なことはせずありのままの表形式データをParquetに落とし込んでいきます。
Parquetは列指向データですが、それ以前にrow groupという一定レコードの行の塊単位で保存されており、そのrow groupの中で列ごとのチャンクに分かれています。
(さらに、ページ分割もされているようです。)
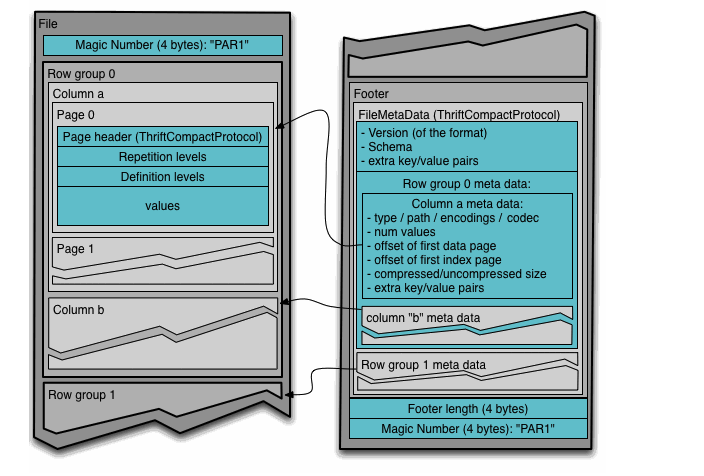
(https://parquet.apache.org/docs/file-format/ )
こちらも参考になりました。
今回は「大容量ファイルに対して、必要最小限のデータのみ取得して、描画する」というのが目的なので、row groupの統計情報(min/max)を利用して、余計なところは読み飛ばしていくのが正攻法に思えます。
となると、空間的に近い点同士はなるべく同じrow groupに存在しているのが良いです。
経度と緯度のどちらか一方でソートしてしまうと、一方は綺麗に整列しても他方はバラバラになってしまいます。
なので基本的にはモートンオーダーとかヒルベルト曲線のような空間充填曲線でソートしてあげるのが良いでしょう。
なので、こんな感じのコードを書いてみました。
- 5000万ポイント
- 100万レコードごとにrow groupを作成
- 東京都を中心に、ポイントを散らす
- モートンオーダーでソート(ソート後は破棄)
以下のようなものができました。
scripts/generate_points_parquet_3d.py
from pathlib import Path
import numpy as np
import pyarrow as pa
import pyarrow.parquet as pq
N = 50_000_000
ROW_GROUP = 1_000_000
SEED = 2025
CENTER_LON = 139.76
CENTER_LAT = 35.68
LON_STD = 0.12
LAT_STD = 0.10
QUANT_BITS = 32
OUT = Path(__file__).resolve().parent.parent / "static" / "points_static_3d.parquet"
def part1by1_u32(x: np.ndarray) -> np.ndarray:
x = x.astype(np.uint64, copy=False) & np.uint64(0xFFFFFFFF)
x = (x | (x << np.uint64(16))) & np.uint64(0x0000FFFF0000FFFF)
x = (x | (x << np.uint64(8))) & np.uint64(0x00FF00FF00FF00FF)
x = (x | (x << np.uint64(4))) & np.uint64(0x0F0F0F0F0F0F0F0F)
x = (x | (x << np.uint64(2))) & np.uint64(0x3333333333333333)
x = (x | (x << np.uint64(1))) & np.uint64(0x5555555555555555)
return x
def _quantize_linear_bits(
x: np.ndarray,
lo: float,
hi: float,
bits: int,
) -> np.ndarray:
if not (1 <= bits <= 32):
raise ValueError("bits must be in [1, 32]")
x64 = x.astype(np.float64, copy=False)
t = (x64 - lo) / (hi - lo)
t = np.clip(t, 0.0, 1.0)
maxv = np.float64((1 << bits) - 1)
q = (t * maxv).astype(np.uint32)
if bits < 32:
q = q << np.uint32(32 - bits)
return q
def morton_lonlat_linear(
lon: np.ndarray, lat: np.ndarray, bits: int = 32
) -> np.ndarray:
lon_q = _quantize_linear_bits(lon, -180.0, 180.0, bits)
lat_q = _quantize_linear_bits(lat, -90.0, 90.0, bits)
a = part1by1_u32(lon_q)
b = part1by1_u32(lat_q) << np.uint64(1)
return a | b
def main():
rng = np.random.default_rng(SEED)
OUT.parent.mkdir(parents=True, exist_ok=True)
lon = (CENTER_LON + rng.normal(0, LON_STD, size=N)).astype(np.float32)
lat = (CENTER_LAT + rng.normal(0, LAT_STD, size=N)).astype(np.float32)
alt = rng.uniform(0.0, 3000.0, size=N).astype(np.float32)
r = rng.integers(0, 256, size=N, dtype=np.uint8)
g = rng.integers(0, 256, size=N, dtype=np.uint8)
b = rng.integers(0, 256, size=N, dtype=np.uint8)
morton = morton_lonlat_linear(lon, lat, bits=QUANT_BITS)
order = np.argsort(morton)
lon = lon[order]
lat = lat[order]
alt = alt[order]
r = r[order]
g = g[order]
b = b[order]
table = pa.table({"lon": lon, "lat": lat, "alt": alt, "r": r, "g": g, "b": b})
pq.write_table(table, OUT, compression="zstd", row_group_size=ROW_GROUP)
print(f"done: {OUT}")
if __name__ == "__main__":
main()
実行すると、5000万ポイント・500MBの点群データが出来上がります。
作成したParquetはこんなサイトで確認できます。
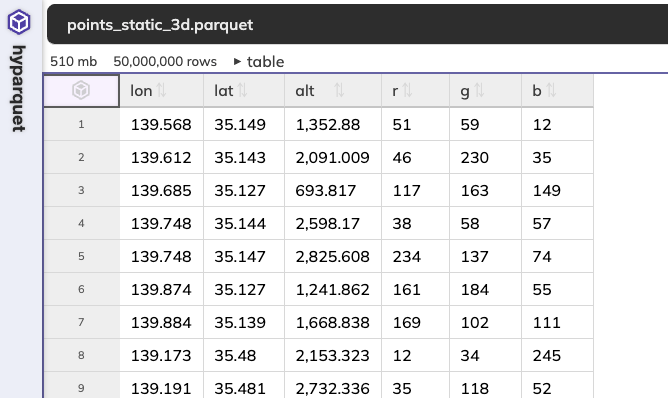
メタデータも確認できる優れものです。
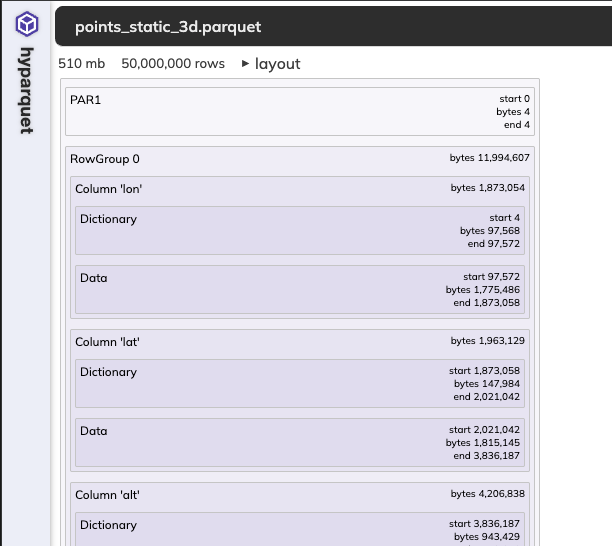
これをDeck.glで読んでいきます。
一部分だけ取得して、表示する
「Parquetにx,y,z,r,g,bを大量に詰め込んだ点群Parquetに対して、BBOXを指定し、空間演算で対象の地物を絞り、一部分だけfetchして描画」ということしたいんですが、それをやろうとするとDucKDB-Wasmでクエリ、ということになるのかなと思います。
ただ、DuckDB-Wasmで色々チャレンジしていたんですが
- BBOXで範囲指定したクエリを書いてもParquet全量fetchされてしまう
- 事前にデータ側をある程度ソートしておいて、さらにbbox列とかを持たせておかないと効かないのかと思ったが、ソートしても全量fetchされる
- Parquetを保存してあるサーバに対し、Range Requestは通るし行グループのpushdownは効いてそうだが、DuckDB-Wasmが全量取得しにいっちゃう
- DuckDBの
registerFileURL()関数でも、read_parquet()でも同様
といった状況で、原因を特定できず断念しました。
(DuckDB-Wasmの実装が僕の想像する実装と異なっている可能性が高いんですが、わからん)
なので、hyparquetでデータ取得のロジックを独自に書いていくことにしました。
今回は楽なのでSvelteで書いていますが、たいしたコードではないのでなんでも良いです。
大容量データをどうにかするコードを書くので、ロジックはワーカーに閉じ込めます。
src/lib/parquet-bbox-worker.ts
import { asyncBufferFromUrl, parquetMetadataAsync, parquetRead } from 'hyparquet';
import { compressors } from 'hyparquet-compressors';
type Envelope = {
minLon: number;
minLat: number;
maxLon: number;
maxLat: number;
limit?: number;
};
type Range = { start: number; end: number };
function concatF32(parts: ArrayLike<number>[]) {
if (parts.length === 0) return new Float32Array();
if (parts.length === 1 && parts[0] instanceof Float32Array) return parts[0] as Float32Array;
let total = 0;
for (const p of parts) total += p.length;
const out = new Float32Array(total);
let off = 0;
for (const p of parts) {
out.set(p as any, off);
off += p.length;
}
return out;
}
function concatU8(parts: ArrayLike<number>[]) {
if (parts.length === 0) return new Uint8Array();
if (parts.length === 1 && parts[0] instanceof Uint8Array) return parts[0] as Uint8Array;
let total = 0;
for (const p of parts) total += p.length;
const out = new Uint8Array(total);
let off = 0;
for (const p of parts) {
out.set(p as any, off);
off += p.length;
}
return out;
}
async function loadFileAndMeta(fileUrl: string) {
const file = await asyncBufferFromUrl({ url: fileUrl });
const meta = await parquetMetadataAsync(file);
return { file, meta };
}
function getColMeta(group: any, name: string) {
const cols = group.columns ?? [];
return cols.find((c: any) => c.meta_data?.path_in_schema?.[0] === name)?.meta_data;
}
function selectTargetRanges(meta: any, env: Envelope): Range[] {
const groups = meta.row_groups ?? [];
const targets: Range[] = [];
let offset = 0;
for (const g of groups) {
const start = offset;
const end = start + Number(g.num_rows);
offset = end;
const lonMeta = getColMeta(g, 'lon');
const latMeta = getColMeta(g, 'lat');
const lonStats = lonMeta.statistics;
const latStats = latMeta.statistics;
const lonMin = Number(lonStats.min_value ?? lonStats.min);
const lonMax = Number(lonStats.max_value ?? lonStats.max);
const latMin = Number(latStats.min_value ?? latStats.min);
const latMax = Number(latStats.max_value ?? latStats.max);
const overlaps =
lonMax >= env.minLon && lonMin <= env.maxLon && latMax >= env.minLat && latMin <= env.maxLat;
if (overlaps) targets.push({ start, end });
}
return targets;
}
function makeParts() {
return {
lon: [] as ArrayLike<number>[],
lat: [] as ArrayLike<number>[],
alt: [] as ArrayLike<number>[],
r: [] as ArrayLike<number>[],
g: [] as ArrayLike<number>[],
b: [] as ArrayLike<number>[]
};
}
async function readRangeColumns(file: any, range: Range) {
const parts = makeParts();
await parquetRead({
file,
compressors,
columns: ['lon', 'lat', 'alt', 'r', 'g', 'b'],
rowStart: range.start,
rowEnd: range.end,
onChunk(chunk: any) {
(parts as any)[chunk.columnName].push(chunk.columnData);
}
});
const lon = concatF32(parts.lon);
const lat = concatF32(parts.lat);
const alt = concatF32(parts.alt);
const r = concatU8(parts.r);
const g = concatU8(parts.g);
const b = concatU8(parts.b);
return { lon, lat, alt, r, g, b };
}
function appendFilteredUpToLimit(
data: {
lon: Float32Array;
lat: Float32Array;
alt: Float32Array;
r: Uint8Array;
g: Uint8Array;
b: Uint8Array;
},
env: Envelope,
limit: number,
positions: Float32Array,
colors: Uint8Array,
rows: number
) {
const n = data.lon.length;
for (let i = 0; i < n && rows < limit; i++) {
const x = data.lon[i];
const y = data.lat[i];
if (x < env.minLon || x > env.maxLon || y < env.minLat || y > env.maxLat) continue;
const base = rows * 3;
positions[base] = x;
positions[base + 1] = y;
positions[base + 2] = (data.alt as any)[i] ?? 0;
colors[base] = (data.r as any)[i] ?? 200;
colors[base + 1] = (data.g as any)[i] ?? 200;
colors[base + 2] = (data.b as any)[i] ?? 200;
rows += 1;
}
return rows;
}
onmessage = async (e: MessageEvent<{ type: string; env: Envelope; fileUrl: string }>) => {
if (e.data?.type !== 'query') return;
const env = e.data.env;
const limit = env.limit ?? 100_000;
const { file, meta } = await loadFileAndMeta(e.data.fileUrl);
const targets = selectTargetRanges(meta, env);
const positions = new Float32Array(limit * 3);
const colors = new Uint8Array(limit * 3);
let rows = 0;
for (const t of targets) {
if (rows >= limit) break;
const data = await readRangeColumns(file, t);
rows = appendFilteredUpToLimit(data, env, limit, positions, colors, rows);
}
const outPositions = positions.slice(0, rows * 3);
const outColors = colors.slice(0, rows * 3);
postMessage(
{ type: 'result', positions: outPositions, colors: outColors, rows },
{ transfer: [outPositions.buffer, outColors.buffer] }
);
};
だいたいこんなことをしています。
- Workerがファイルのパスを受け取る
- Parquetのメタ情報を読み取る
- UIで指定されたBBOX(経緯度)と描画点数を受け取る
- row groupごとの統計を読み取り、BBOXと重なるグループを選ぶ
- 順に読み取り、点の情報を取り出す
- 点がBBOX内に入っているか確認する
- 指定ポイント数になるまで続ける
- 完了次第、メインスレッドに返す
こちらの記事で紹介しているように、バイナリ属性として読み取れるように返却してあげてます。
フロント側はこんな感じでParquetを指定してワーカーに渡し、返ってきた点群をそのままDeck.glのPointCloudLayerに渡します。
src/routes/+page.svelte
<script lang="ts">
import { onDestroy, onMount } from 'svelte';
import { Deck, MapView } from '@deck.gl/core';
import { PointCloudLayer } from '@deck.gl/layers';
type Envelope = {
minLon: number;
minLat: number;
maxLon: number;
maxLat: number;
limit: number;
};
let deck: Deck | null = null;
let worker: Worker | null = null;
let running = false;
let fileUrl = '/points_static_3d.parquet';
let env: Envelope = {
minLon: 139.3,
minLat: 35.5,
maxLon: 139.6,
maxLat: 35.7,
limit: 200_000
};
const initialViewState = {
longitude: 139.76,
latitude: 35.68,
zoom: 10,
pitch: 65,
bearing: 15
};
onMount(() => {
fileUrl = new URL('/points_static_3d.parquet', window.location.href).toString();
deck = new Deck({
views: [new MapView()],
initialViewState,
controller: true,
parent: document.getElementById('deck') as HTMLDivElement
});
});
function initWorker() {
if (worker) return;
worker = new Worker(new URL('../lib/parquet-bbox-worker.ts', import.meta.url), {
type: 'module'
});
worker.onmessage = (e) => {
const msg = e.data as { positions: Float32Array; colors: Uint8Array; rows: number };
running = false;
const { positions, colors, rows } = msg;
deck?.setProps({
layers: [
new PointCloudLayer({
id: 'pc-parquet-bbox',
data: {
length: rows,
attributes: {
getPosition: { value: positions, size: 3 },
getColor: { value: colors, size: 3, normalized: true }
}
},
pointSize: 2
})
]
});
};
}
function runBboxQuery() {
if (!deck) return;
initWorker();
running = true;
worker?.postMessage({ type: 'query', env, fileUrl });
}
onDestroy(() => {
deck?.finalize();
worker?.terminate();
});
</script>
<main class="min-h-screen bg-black px-4 py-10 text-slate-100">
<div class="space-y-4">
<header class="space-y-2">
<h1 class="text-2xl font-bold text-white">Parquet row group pruning + bbox filter</h1>
</header>
<div class="flex flex-wrap items-center gap-3 text-sm">
<div class="flex items-center gap-2">
<label for="minLon" class="text-slate-200">minLon</label>
<input
id="minLon"
type="number"
step="0.1"
bind:value={env.minLon}
class="w-28 rounded border border-slate-300 bg-white px-2 py-1 text-right text-slate-900"
/>
<label for="maxLon" class="text-slate-200">maxLon</label>
<input
id="maxLon"
type="number"
step="0.1"
bind:value={env.maxLon}
class="w-28 rounded border border-slate-300 bg-white px-2 py-1 text-right text-slate-900"
/>
</div>
<div class="flex items-center gap-2">
<label for="minLat" class="text-slate-200">minLat</label>
<input
id="minLat"
type="number"
step="0.1"
bind:value={env.minLat}
class="w-28 rounded border border-slate-300 bg-white px-2 py-1 text-right text-slate-900"
/>
<label for="maxLat" class="text-slate-200">maxLat</label>
<input
id="maxLat"
type="number"
step="0.1"
bind:value={env.maxLat}
class="w-28 rounded border border-slate-300 bg-white px-2 py-1 text-right text-slate-900"
/>
</div>
<div class="flex items-center gap-2">
<label for="limit" class="text-slate-200">LIMIT</label>
<input
id="limit"
type="number"
min="1"
max="2000000"
step="50000"
bind:value={env.limit}
class="w-28 rounded border border-slate-300 bg-white px-2 py-1 text-right text-slate-900"
/>
</div>
<div class="flex items-center gap-2 text-slate-300">
<span class="text-slate-400">Parquet</span>
<code class="rounded border border-slate-700 bg-slate-900 px-2 py-1 text-xs text-slate-100">
{fileUrl}
</code>
</div>
<button
class="inline-flex items-center justify-center gap-2 rounded border border-slate-300 bg-white px-5 py-2.5 text-sm font-semibold text-slate-900 shadow-sm transition hover:-translate-y-[1px] hover:shadow focus:outline-none focus:ring-2 focus:ring-slate-200 disabled:translate-y-0 disabled:opacity-50"
on:click={runBboxQuery}
disabled={running}
>
bbox でフィルタして描画
</button>
</div>
<section id="deck" class="h-[80vh] w-full bg-black"></section>
</div>
</main>
適当に散らした点群なのでもはや背景地図を表示させる意味もないなと思って、してません。
範囲指定も、普通は地図上で矩形を引っ張ってBBOXを指定させるべきなんですが、地図がないのでやりません。
動かしてみる
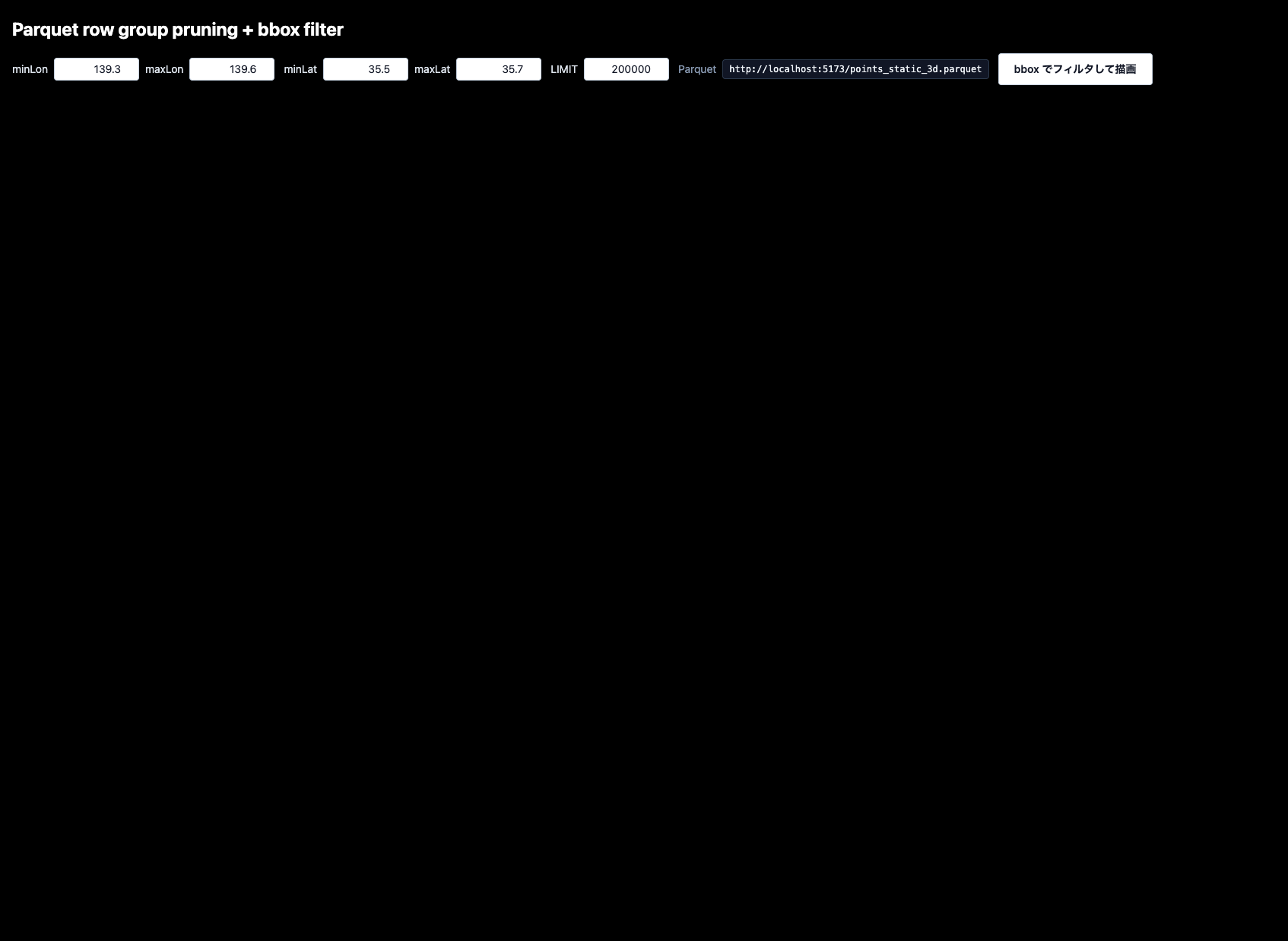
動かしてみると、こんな感じの画面が出てきます。
デフォルトの位置で「bboxでフィルタして描画」ボタンを押すと、想定通り指定範囲かつ指定したポイント数(20万)の点群が描画されます!
fetchも1秒以下かつ転送量も25MB程度で描画されてますね!!
さらに、20万ポイントに到達した時点で読み込み・描画が止まるので、表示が途切れています。
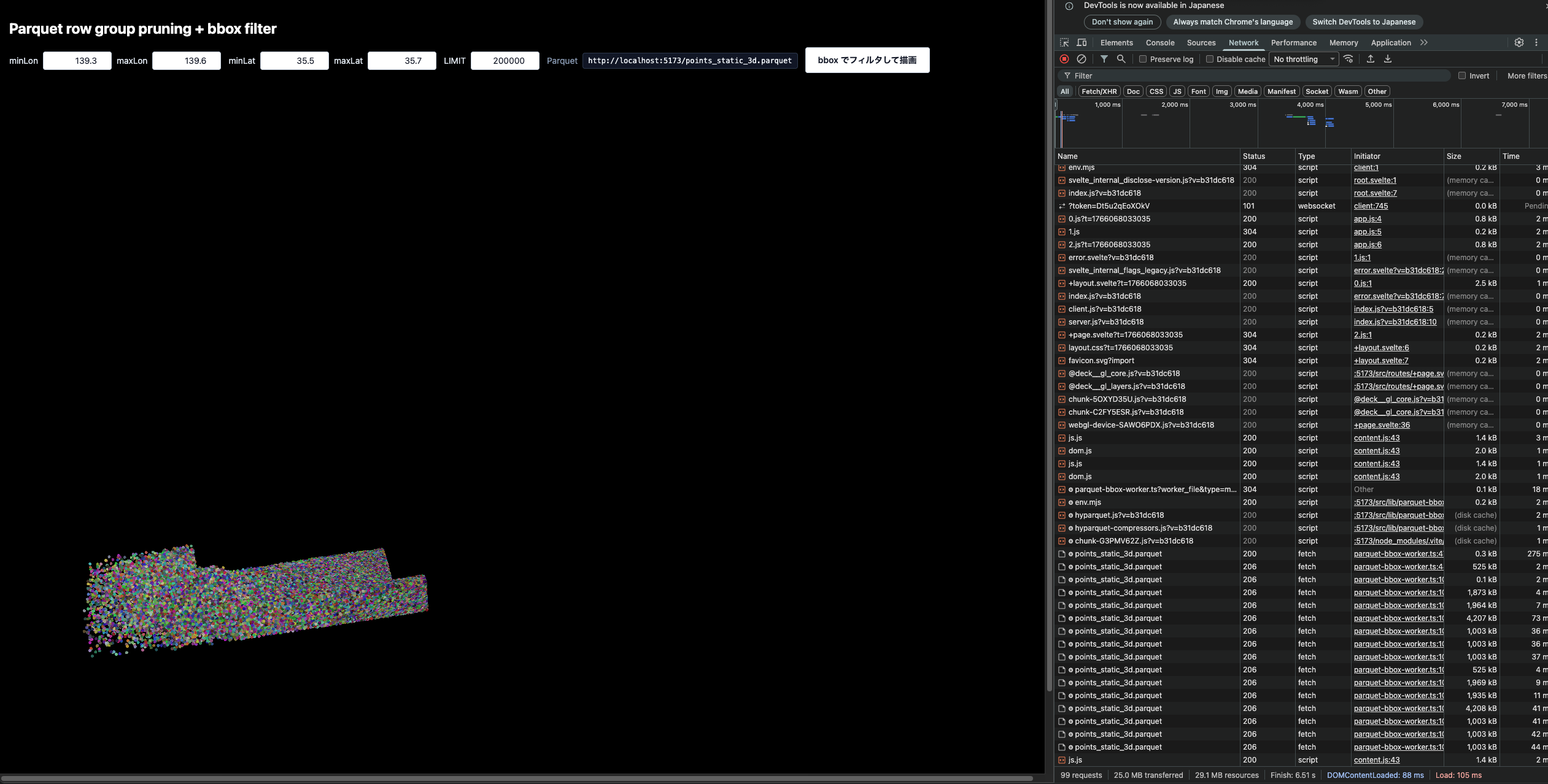
ちなみに200万ポイントだとこんな感じです。
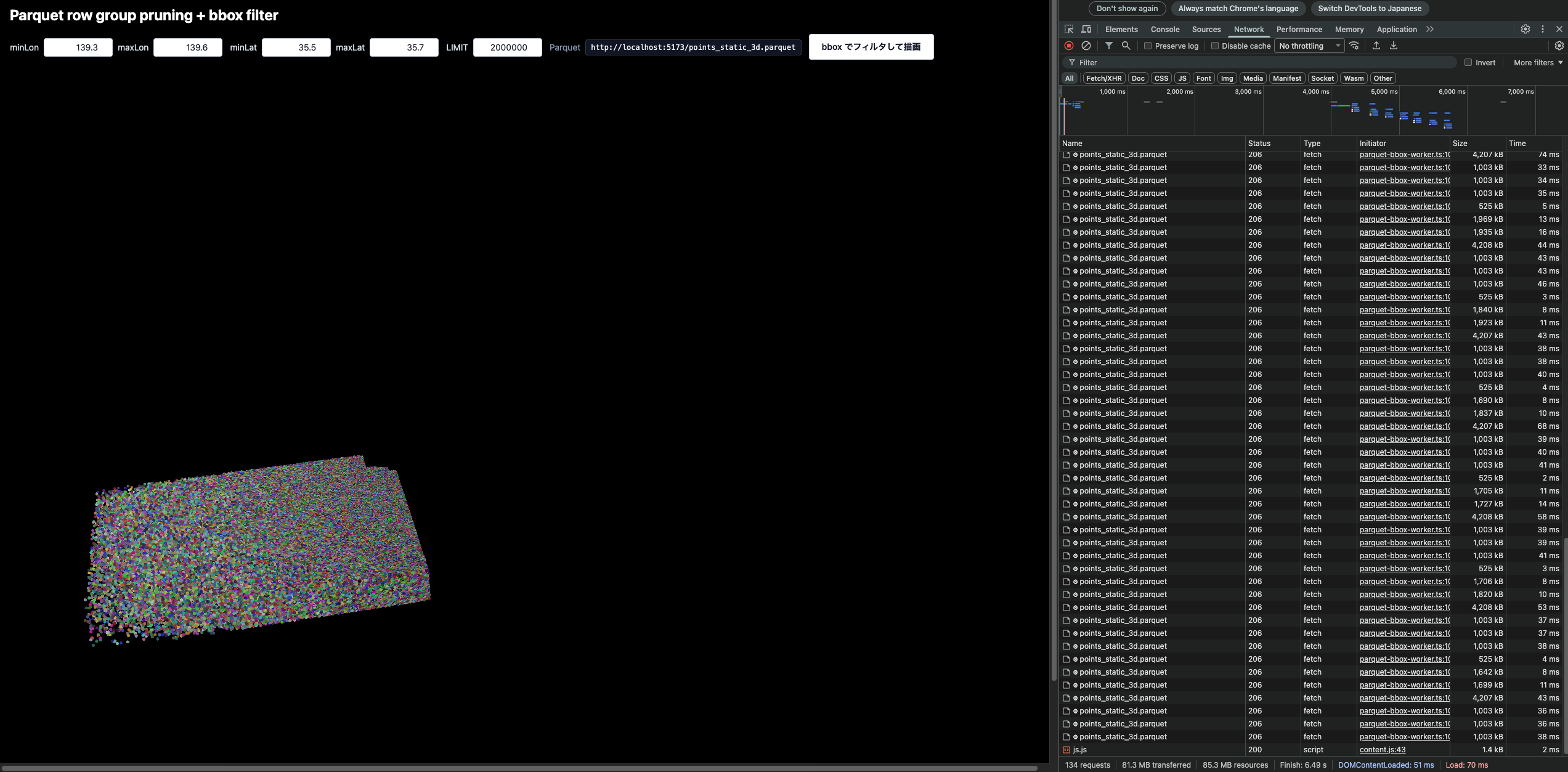
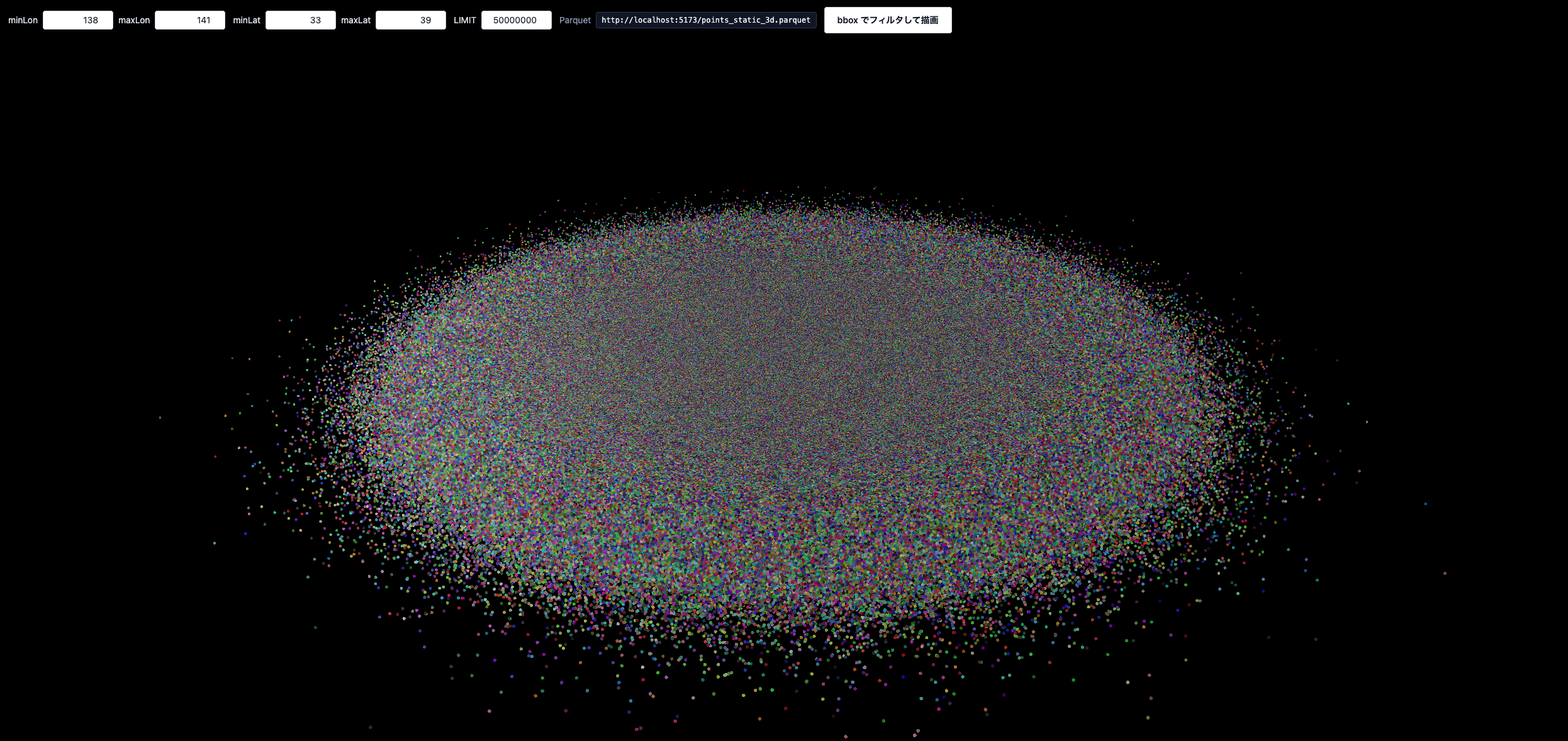
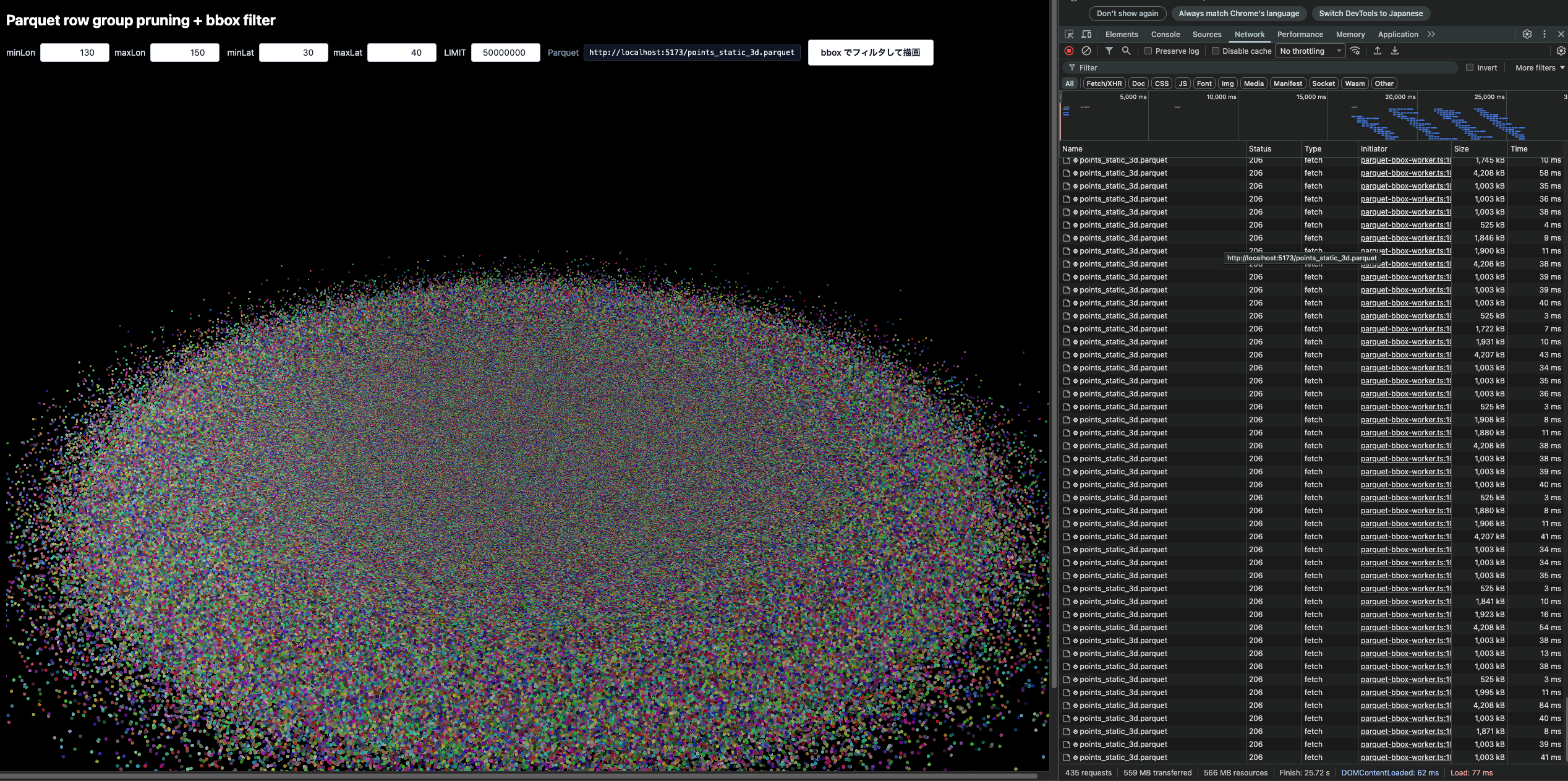
5000万ポイントで、範囲を拡大させるとこんな感じです。
重いですが、結構動きました。
おわりに
ということで、今回はParquetに3次元ポイントを埋め込んで点群を作り、それを部分読み取りして描画してみました。
使い道があるかというと、まぁそうでもなかったりするんですがCSVで点群を作るよりは遥かに可能性が広がるのかなと思いました!
LAS/LAZを触り飽きた点群クラスタの皆さんはぜひParquetを触ってみてください!