はじめに
- データエンジニアリングの基本知識の内、AIチームでも特に使いそうな要素をかいつまんで簡単にまとめました。
- (追記)その後、Google Cloud Professional Data Engineer取得に向けて勉強し直したときのメモ: GCPでデータエンジニアリング入門
参考書籍
データエンジニアリングとは
- データ活用のためのインフラストラクチャを設計・構築・運用するための技術
- (上記の参考書籍に書かれているような内容)
データエンジニアリングの必要性について
- MLシステムを構築する際に、データエンジニアリングを全く考慮しないと、下記のような課題が発生し得ります。

①DWH
DWHとは
- 分析のためにデータを格納しておくためのシステム
- 使いどころ
- 集約することで、データのサイロ化を防ぐ(Dx条件の一つ)
- データベースとの違いは、「データ分析が目的であること」「膨大なデータを高速に処理する必要があること」
- (補足)データレイク・データマートとは
- データレイク: 未加工のデータを収集して蓄積するための場所。非構造化データ含めて。
- データ分析基盤の基本と構築のポイントから引用

- (参考)列指向データベース
- データ分析では、しばしば一部のカラムだけが集計の対象になる
- -> データをあらかじめカラム単位にまとめておくことで、必要なカラムだけを読み込むことでディスクI/Oを減らす。
- -> 同じカラムには、しばしば同じようなデータが並ぶので、圧縮できる
- 設計のポイント
- データ保存量の拡張手段(制約がないか)
- データの取り出し手段
実用イメージ

【GCP】BigQuery
- BigQuery は、Google Cloud のペタバイト規模の費用対効果に優れたフルマネージド型の分析データウェアハウスであり、膨大な量のデータに対してほぼリアルタイムで分析を行うことができる
- BQの仕組み

- RDBとの使い分け
- データマート用途であれば、1千万レコード/5GB(1レコード/500バイト仮定)くらいならRDBでも問題ないかも?
- GCSデータのクエリ
- BigQuery では、次の形式の Cloud Storage データのクエリがサポートされています。
- -> カンマ区切り値(CSV),JSON(改行区切り),Avro,ORC,Parquet,Datastoreエクスポート,Firestoreエクスポート
- データの取り込み方法
- バルクロード: BigQuery Data Transfer Service, など
- ストリーミング挿入: Fluentd, Dataflowのコネクタ, StriimなどのCDCソリューション(MySQLなどと同期)
- フェデレーション: 外部テーブルを指定
- コスト
- マルチテナント方式であるため、事前のプロビジョニングのコストが発生しない
- コンピュートまたはストレージのどちらか大きいほうのピークに合わせてサイジング調整する必要などがない
- クエリでスキャンした容量に対して課金
- マルチテナント方式であるため、事前のプロビジョニングのコストが発生しない
- BigQueryML
- SQLを用いて、機械学習のステップを完結できる
- BQが予測リクエストをSQL形式で受付け、推論結果をサービングできる
- サポートしているモデル
- 線形回帰(予測)
- 2項ロジスティック回帰(分類)
- 多項ロジスティック回帰(分類)
- K平均法クラスタリング(データセグメンテーション)
- 行列分解(商品のレコメンデーションシステムの作成)
- 時系列(時系列予測)
- ブーストツリー(XGBoostベースの分類モデルと回帰モデルの作成)
- ディープ ニューラル ネットワーク(DNN)(分類、回帰)
- AutoML Tables: 特徴量エンジニアリングやモデル選択を行わずに、最適なモデルを作成する
- TensorFlow モデルのインポート
- SQLを用いて、機械学習のステップを完結できる
②データ処理-Spark
Sparkとは
- ビッグデータ分析に最適なオープンソースの分散処理システム。データ処理で最大のオープンソースプロジェクト。
- Netflix、Yahoo、eBay などのインターネット大手も、Spark を大規模にデプロイし、8000 を超えるノードのクラスターで、複数のペタバイトデータをまとめて処理しています
- Cluster Mode Overviewから引用
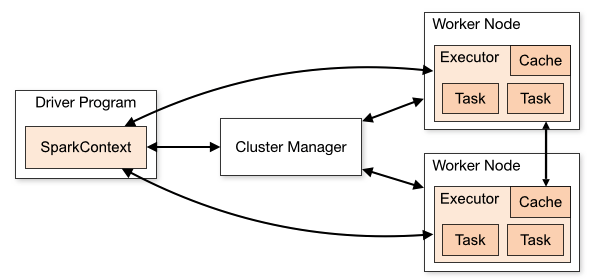
実用イメージ

【GCP】DataProc
- マネージドHadoop/Spark
- メモリを追加してPresto, GPUを追加してSparkで機械学習もできる
- データソース
- ファイルパスの接頭辞をhdfs://からgs://へ変更するだけでGCSにアクセスすることができる
- BQのストレージをDataProcから直接触ることもできる(BigQueryStorageAPIの利用)
- DataProcでGCS上にHiveパーティションデータを作る→それをBQで直接触る、などもできる
- 90sで起動する
- コスト
- プリエンプティブル VM で実行することによって費用をさらに節約できる
- -> プリエンプティブルワーカーは、他のタスクで Google Cloud が必要とする場合に、再利用(クラスタから削除)されます
- サンプルコード
③データ処理-Beam
Beamとは
- Implement batch and streaming data processing jobs that run on any execution engine

- データ読み込み用のコネクタは、BQ,GCS,PubSub,Kafka,Kinesis,SQS,Cassendra,JDBCなどに対応
- Apache Beam で記述したデータ処理のジョブはさまざまなビッグデータ基盤で動作させることができる。Spark,Hadoop MapReduce,Dataflow,,,
- SpotifyはリアルタイムレコメンドにApacheBeamを利用。ピークで800万イベント/sのストレーミングイベントを処理
- 複数の TFX ライブラリではタスクの実行に Beam が使用されているため、コンピュートクラスタでの高度なスケーラビリティが可能
- (参考)ラムダアーキテクチャとカッパアーキテクチャ
- ストリーム処理で対応すべき課題として「間違った結果をどのように修正するか」「遅れてくるデータの扱い」
- ラムダアーキテクチャ: バッチ処理とストリーム処理の両方を組み合わせた
- 最新のデータは、ストリーム処理から生成されたリアルタイムビューを参照し、それより前はバッチ処理されたバッチビューを参照する
- カッパアーキテクチャ: スピードレイヤとバッチレイヤの処理を同じツールで行う
- やり直しに備えて、メッセージブローカのデータ保持期間を十分に長くする
実用イメージ
-
Machine Learning on Streaming Data using Kafka, Beam, and TensorFlowから引用
- ストリーミング処理として、キューから受け取って処理をして、BQやMLサービング環境に投げる、など
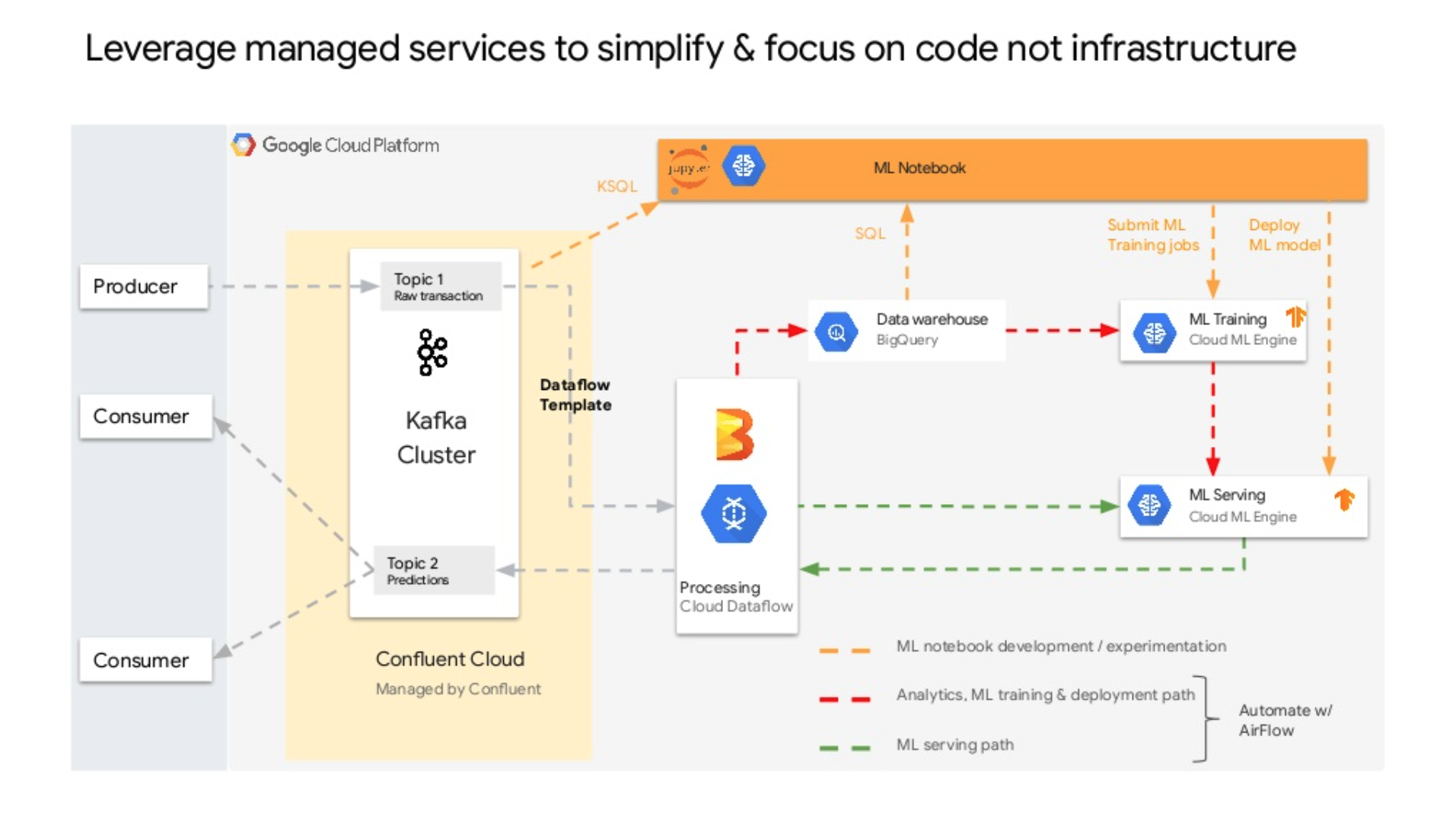
- ストリーミング処理として、キューから受け取って処理をして、BQやMLサービング環境に投げる、など
【GCP】Dataflow
- BigQueryユーザのためのCloud Dataflow入門が分かりやすい
- リアルタイムに整形・集計などのデータ処理をするパイプラインを構築する
- 他GCPサービスとの連携
- Pub/Subで収集→Dataflowで処理→BQで蓄積、など
- S3に書き出すこともできる
-
リアルタイムなアーキテクチャは、GCPだと以下2パターンが多い
- DataflowでGCSに保管してフェデレーション
- BQのストリーミング挿入機能
- サンプルコード
④ワークフロー管理
ワークフロー管理とは
- 処理の依存関係を制御、処理のタイミングを適切にコントロールする
- データパイプライン(データがどこから来てどの処理を経てどこに行くのか)を管理するツールであり、多くはDAG(有向非循環グラフ)で一連の処理を記述する
- メリット
- 依存関係が複雑になりがちな処理フローを管理できる
- 実装を共通化できる
- 実験環境から本番環境への移行がしやすい
- エラー通知、リカバリーの支援などの運用管理面
- サンプルコード
実用イメージ
-
Machine Learning in Production using Apache Airflowから引用
- 図は前処理のみ分岐しているが、前処理は共通だがtrainを分岐させたいパターンなども多い

- 図は前処理のみ分岐しているが、前処理は共通だがtrainを分岐させたいパターンなども多い
【GCP】CloudComposer
- Airflowに必要なコンポーネントが自動で起動してくれる
- GKE
- GCS
- CloudLogging
- CloudMonitoring
- CloudSQL(バックエンドDB)
⑤特徴量ストア
特徴量ストアとは
- 特徴量の読み書きに特化したデータストア
- 「組織内の誰もが特徴量にアクセスできるように」「ビッグデータと機械学習の世界を隔てる境界線」
- 特徴
- オンラインとオフラインという性質の異なる2つのシステムにデータを供給
- オンラインはNoSQLで高頻度の読み書きに耐えられるように。オフラインは長期的な保存のためオブジェクトストレージ、など
- バージョニング: 変更履歴を記録
- タイムトラベル: 任意の時点にデータを巻き戻す
- データリネージ: データの依存関係追跡
- データの検証: スキーマを定義
- オンラインとオフラインという性質の異なる2つのシステムにデータを供給
実用イメージ
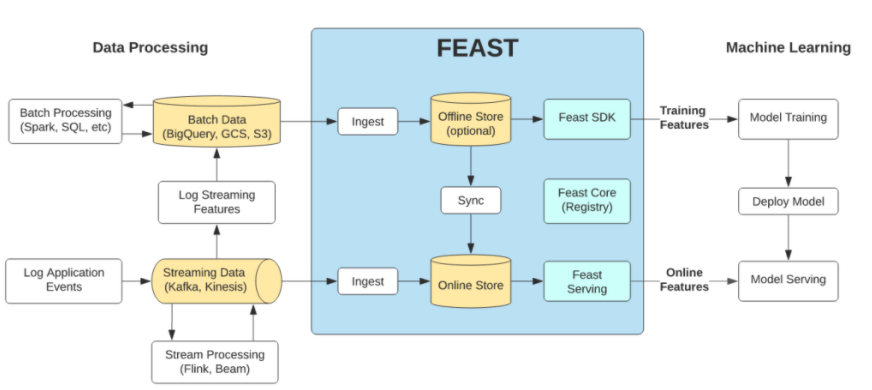
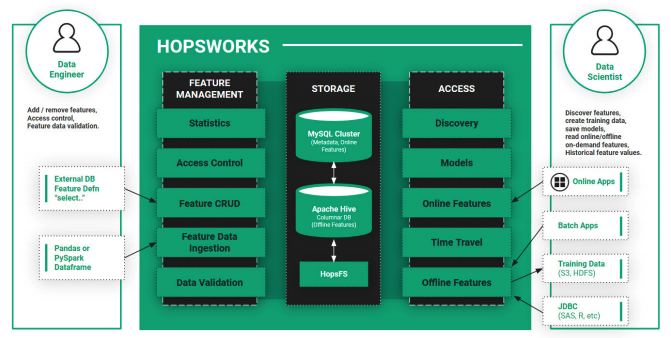
【GCP】Vertex Feature Store
- ML特徴の整理、保存、サービングで使用される一元化されたリポジトリを提供
- 検索機能とフィルタ機能により、他のユーザーも既存の特徴を簡単に見つけて再利用できる
- オンライン予測をタイムリーに行うために低レイテンシのデータ サービングインフラストラクチャを構築
- 本番環境で使用する特徴データの分布が、モデルのトレーニングに使用された特徴データの分布と異なることを回避