はじめに
- SageMakerを使って(個人で)開発したときのフローをまとめました。
- ちょこちょこ、私なりのおすすめの使い方とかフォーマットとか参考リンクも書いています。
SageMakerとは
-
データサイエンティストやエンジニアが素早くプロセスを回せるようにするための、機械学習ワークフロー全体をカバーする完全マネージド型サービス。
※ 今回はSageMakerの提供する機能のうち、構築→トレーニング→デプロイの機能について記載する。 -
概要
 https://aws.amazon.com/jp/sagemaker/
https://aws.amazon.com/jp/sagemaker/
- 料金
- Amazon SageMaker の料金
- ex.
- ノートブックインスタンス(ml.t2.large/2vCPU, 8GiB): 0.1702 USD/h
- 学習コンテナ(ml.p2.xlarge/4vCPU, 61GiB, 1×K80): 2.159 USD/h
- 推論エンドポイント(ml.m5.large/2vCPU, 8GiB): 0.174 USD/h
SageMakerのメリット
-
環境構築がラク
- 構築環境、トレーニング環境、推論エンドポイント
- ライブラリセットアップ、推論エンドポイント構築等
- マネジメントコンソールから数クリックで、ライブラリセットアップ済のノートブックインスタンスが起動する。
- トレーニング環境・推論エンドポイントも、ノートブックからメソッド一発で起動できる。
-
リソースを有効活用できる
- 構築環境とトレーニング環境が同一だと、大量のGPUを遊ばせがち。逆に、ローカルで一人一台GPUマシンを持つ場合、学習処理を並列で実行することが難しい。
- -> トレーニング環境が構築環境とは別コンテナとして、トレーニング時のみ起動する。また、学習処理ごとに別コンテナとして起動するので、並列実行可能。
-
運用機能が備わっている(自前で構築する必要がない)
- 学習結果、モデルの管理
- マネジメントコンソールから履歴が確認できる
- 推論エンドポイントへのデプロイの仕組み、スケールの仕組み
- 学習結果、モデルの管理
SageMakerでの機械学習モデル開発フロー
開発フローサマリ
-
構成図
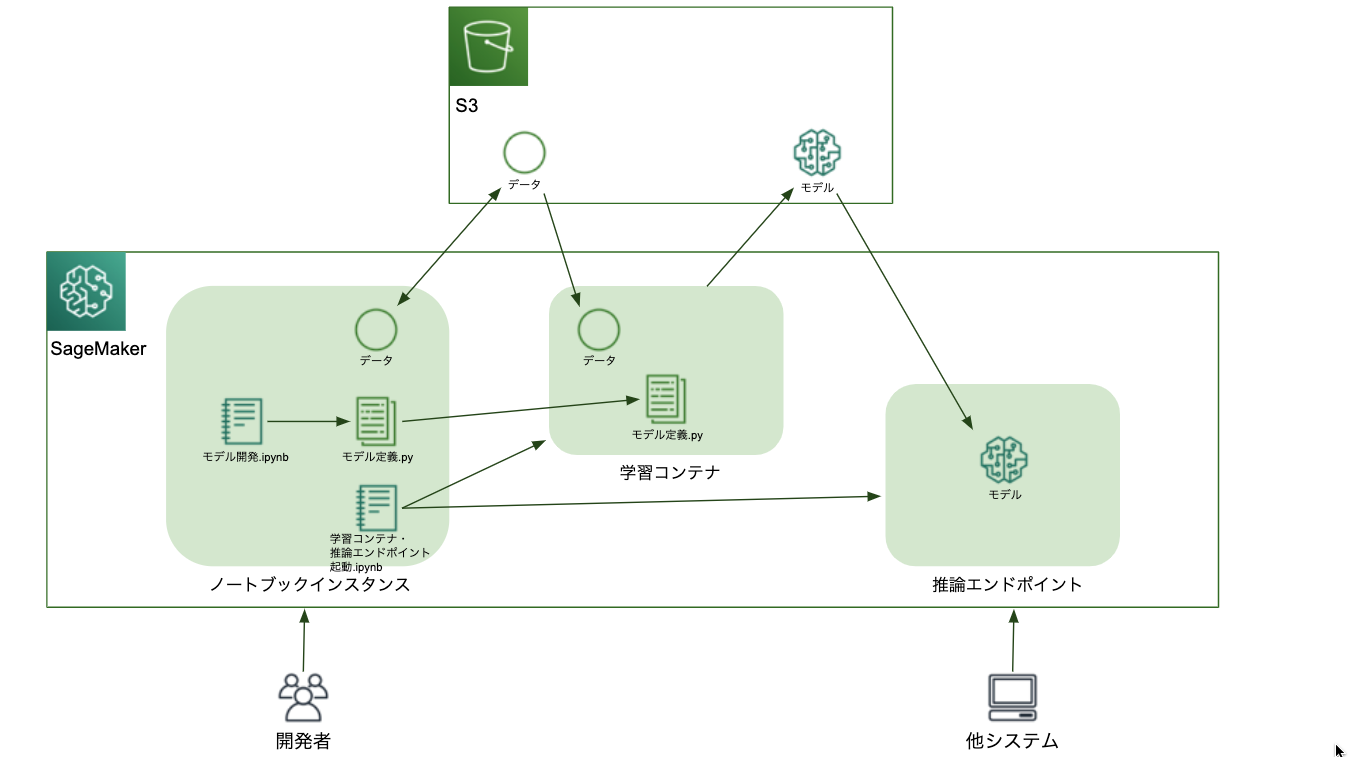
-
開発フロー
| No | 分類 | 項目 |
|---|---|---|
| 1-1 | 構築 | ノートブックインスタンス起動 |
| 1-2 | 構築 | データ準備 |
| 1-3 | 構築 | モデル開発 |
| 2-1 | トレーニング | データ準備 |
| 2-2 | トレーニング | 学習スクリプト準備 |
| 2-3 | トレーニング | 学習コンテナ起動 |
| 3-1 | デプロイ | 推論エンドポイント起動 |
| 3-2 | デプロイ | 推論実行 |
開発フロー詳細
1-1. [構築]ノートブックインスタンス起動
[optional]ライフサイクル設定
- マネジメントコンソール -> Amazon SageMaker -> ライフサイクル設定
- ノートブックの開始 or 作成時に実行する処理を設定できる
- 日本語のコメントがあるとエラーになる?
- エラー発生時は、CloudWatchの/aws/sagemaker/NotebookInstances を確認する
- (参考)ノートブックインスタンスをカスタマイズする
- ex. パッケージインストール + ディレクトリ作成の設定
- 対象の環境(下記例はpython3)、作業ディレクトリ名(下記例はmyProject)、インストールしたいパッケージ(下記例はmyPackage)を変更して下さい
- 環境の一覧は、下記で確認 /home/ec2-user/anaconda3/envs/
- ディレクトリ構成は下記を参考にしています
- 対象の環境(下記例はpython3)、作業ディレクトリ名(下記例はmyProject)、インストールしたいパッケージ(下記例はmyPackage)を変更して下さい
ライフサイクル設定例
# !/bin/bash
sudo -u ec2-user -i <<'EOF'
TARGET_ENV=python3
PROJECT_NAME=myProject
# install package
# This will affect only the Jupyter kernel called "conda_python3".
source activate ${TARGET_ENV}
# Replace myPackage with the name of the package you want to install.
pip install myPackage
# You can also perform "conda install" here as well.
source deactivate
# mkdir
mkdir -p /home/ec2-user/SageMaker/${PROJECT_NAME}/configs
mkdir -p /home/ec2-user/SageMaker/${PROJECT_NAME}/data
mkdir -p /home/ec2-user/SageMaker/${PROJECT_NAME}/features
mkdir -p /home/ec2-user/SageMaker/${PROJECT_NAME}/logs
mkdir -p /home/ec2-user/SageMaker/${PROJECT_NAME}/models
mkdir -p /home/ec2-user/SageMaker/${PROJECT_NAME}/notebook
mkdir -p /home/ec2-user/SageMaker/${PROJECT_NAME}/scripts
mkdir -p /home/ec2-user/SageMaker/${PROJECT_NAME}/utils
EOF
[optional]Gitリポジトリ紐付け
- リポジトリがCloneされた状態でノートブックインスタンスを起動させることができる
- Git リポジトリの URL にGitHubのURLを書けばよい
- /home/ec2-user/SageMaker 配下にCloneされる
- (参考)Amazon SageMakerにてGit連携が行えるようになりました。
ノートブックインスタンス作成
- マネジメントコンソール -> Amazon SageMaker -> ノートブックインスタンス -> ノートブックインスタンスの作成
- デフォルトでS3バケットが作成されるが、必要に応じて自分で作成しておいてもよい
- デフォルトでIAMロールが作成されるが、必要に応じて自分で作成しておいてもよい
- ポリシーとしては、AmazonSageMakerFullAccessと、上記S3バケットへアクセスするためのポリシー
- (参考)【初心者向け】Amazon SageMakerではじめる機械学習
1-2. [構築]データ準備
ノートブックインスタンスへのアップロード
- 基本的には、Jupyterの画面からデータをアップロードすればよい
[optional]s3へのデータアップロード、ダウンロード
- マイルールで、rawデータをs3で管理 -> ノートブックインスタンス他で色々加工 -> キリのいい断面をs3で管理 としています
- バックアップ、他メンバーとのデータ断面共有のため
- s3, ローカルのdata配下ディレクトリの構成、命名規則は下記としています
ディレクトリ構成例
data
├── raw <- The original, immutable data dump.
│ └── dataType_date
│ ├── image
│ └── csv
├── interim <- Intermediate data that has been transformed.
│ └── ${rawDir}_howToProcess
│ ├── image
│ └── csv
├── processed <- The final, canonical data sets for modeling.
│ └── ${rawDir}_howToProcess
│ ├── image
│ └── csv
└── external <- Data from third party sources.
└── dataType_date
├── image
└── csv
s3コマンド
# ls(s3)
$ aws s3 ls s3://myBucket/data/raw/
# download(s3 -> local)
$ aws s3 cp s3://myBucket/data/raw/ ./data/raw/ --recursive
# upload(local -> s3)
$ aws s3 cp ./data/processed/ s3://myBucket/data/processed/ --recursive
1-3. [構築]モデル開発
開発
- いつも通りJupyterNotebook/Labで開発すればよいです
- (参考)PyTorchによるディープラーニング実装の流れ
PyTorchによるディープラーニング実装の流れ
1. 前処理、後処理、そしてネットワークモデルの入出力を確認
2. Datasetの作成
3. DataLoaderの作成
4. ネットワークモデルの作成
5. 順伝播(forward)の定義
6. 損失関数の定義
7. 最適化手法の設定
8. 学習・検証の実施
9. テストデータで推論
pytorch_tutorial_cifar10.ipynb
# Datasetの作成
import torch
import torchvision
import torchvision.transforms as transforms
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='../data/raw', train=True,
download=True, transform=transform)
testset = torchvision.datasets.CIFAR10(root='../data/raw', train=False,
download=True, transform=transform)
# DataLoaderの作成
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,
shuffle=True, num_workers=2)
testloader = torch.utils.data.DataLoader(testset, batch_size=4,
shuffle=False, num_workers=2)
# ネットワークモデルの作成, 順伝播(forward)の定義
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
# 損失関数の定義
criterion = nn.CrossEntropyLoss()
# 最適化手法の設定
import torch.optim as optim
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
# 学習・検証の実施
for epoch in range(2): # loop over the dataset multiple times
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# get the inputs; data is a list of [inputs, labels]
inputs, labels = data
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
if i % 2000 == 1999: # print every 2000 mini-batches
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
2-1. [トレーニング]データ準備
s3へのデータアップロード
- 学習コンテナが利用するため、データをS3にアップロードする
pytorch_tutorial_cifar10-sagemaker.ipynb(1)
import sagemaker
sagemaker_session = sagemaker.Session()
bucket = sagemaker_session.default_bucket() # ex. 'sagemaker-us-east-2-xxxxxxxxxxxx'
role = sagemaker.get_execution_role() # ex. arn:aws:iam::xxxxxxxxxxxx:role/service-role/...
# We use the sagemaker.Session.upload_data function to upload our datasets to an S3 location.
# The return value inputs identifies the location -- we will use this later when we start the training job.
inputs = sagemaker_session.upload_data(path='../data/raw', bucket=bucket, key_prefix='data/raw/cifar10')
2-2. [トレーニング]学習スクリプト準備
学習スクリプト作成
-
学習コンテナが利用するため、Datasetの作成->学習・検証の実施までをスクリプト化する
-
下記から構成される
-
main()
- Because the SageMaker imports your training script, you should put your training code in a main guard (if name=='main':)
- In order to save your trained PyTorch model for deployment on SageMaker, your training script should save your model to a certain filesystem path called model_dir. This value is accessible through the environment variable SM_MODEL_DIR. -> def _save_model(model, model_dir)
- [optional]**class Net(nn.Module)とdef _train(args)とdef _save_model(model, model_dir)**を切りだす
-
def model_fn(model_dir)
- The SageMaker PyTorch model server loads your model by invoking a model_fn function
-
-
1-3で作成したモデル開発ノートブック->学習スクリプトへの移行手順例
- main()で、まず引数として各種パラメータを受け取る(テンプレ参照)
- _train()を切り出し、2. Datasetの作成-8. 学習・検証の実施(4. ネットワークモデルの作成, 5. 順伝播(forward)の定義 以外)をそのまま書く
- -> パラメータは、argsから受け取るように変更する
- -> returnで_save_modelを呼び出すようにする
- _save_modelを書く(テンプレ参照)
- class Netとして4. ネットワークモデルの作成, 5. 順伝播(forward)の定義を書く
- 推論用に、model_fnを書く(テンプレ参照)
cifar10_sagemaker.py
# main()
import argparse
import sagemaker_containers
# class Net(nn.Module)
import torch.nn as nn
import torch.nn.functional as F
# def _train(args)
import torch
import torchvision
import torchvision.transforms as transforms
import torch.optim as optim
# def _save_model(model, model_dir), def model_fn(model_dir)
import os
## Network, Forward
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def _train(args):
## Dataset
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root=args.data_dir, train=True,
download=True, transform=transform)
testset = torchvision.datasets.CIFAR10(root=args.data_dir, train=False,
download=True, transform=transform)
## DataLoader
trainloader = torch.utils.data.DataLoader(trainset, batch_size=args.batch_size,
shuffle=True, num_workers=args.workers)
testloader = torch.utils.data.DataLoader(testset, batch_size=args.batch_size,
shuffle=False, num_workers=args.workers)
net = Net()
## Loss function
criterion = nn.CrossEntropyLoss()
## Optimizer
optimizer = optim.SGD(net.parameters(), lr=args.lr, momentum=args.momentum)
##Train and Validation
for epoch in range(args.epochs): # loop over the dataset multiple times
# for epoch in range(1): # loop over the dataset multiple times
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# get the inputs; data is a list of [inputs, labels]
inputs, labels = data
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
if i % 2000 == 1999: # print every 2000 mini-batches
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
return _save_model(net, args.model_dir)
def _save_model(model, model_dir):
path = os.path.join(model_dir, 'model.pth')
# recommended way from http://pytorch.org/docs/master/notes/serialization.html
torch.save(model.cpu().state_dict(), path)
def model_fn(model_dir):
device = "cuda" if torch.cuda.is_available() else "cpu"
model = Net()
if torch.cuda.device_count() > 1:
model = nn.DataParallel(model)
with open(os.path.join(model_dir, 'model.pth'), 'rb') as f:
model.load_state_dict(torch.load(f))
return model.to(device)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--workers', type=int, default=2, metavar='W',
help='number of data loading workers (default: 2)')
parser.add_argument('--epochs', type=int, default=2, metavar='E',
help='number of total epochs to run (default: 2)')
parser.add_argument('--batch_size', type=int, default=4, metavar='BS',
help='batch size (default: 4)')
parser.add_argument('--lr', type=float, default=0.001, metavar='LR',
help='initial learning rate (default: 0.001)')
parser.add_argument('--momentum', type=float, default=0.9, metavar='M', help='momentum (default: 0.9)')
parser.add_argument('--dist_backend', type=str, default='gloo', help='distributed backend (default: gloo)')
env = sagemaker_containers.training_env()
parser.add_argument('--hosts', type=list, default=env.hosts)
parser.add_argument('--current-host', type=str, default=env.current_host)
parser.add_argument('--model-dir', type=str, default=env.model_dir)
parser.add_argument('--data-dir', type=str, default=env.channel_input_dirs.get('training'))
parser.add_argument('--num-gpus', type=int, default=env.num_gpus)
_train(parser.parse_args())
2-3. [トレーニング]学習コンテナ起動
インスタンスタイプ設定
- instance_typeにlocalを指定すると、ローカルで学習コンテナが起動する(docker-composeにより)
pytorch_tutorial_cifar10-sagemaker.ipynb(2)
import subprocess
# instance_type = 'local'
instance_type = 'ml.m5.large'
if subprocess.call('nvidia-smi') == 0:
## Set type to GPU if one is present
instance_type = 'local_gpu'
print("Instance type = " + instance_type)
学習コンテナ起動
- ノートブックインスタンスとは別で、学習コンテナを起動させる
- [optional]32文字制限はあるが、job_nameをつけることもできる。(指定しなければランダムな名前が割り振られる。)
pytorch_tutorial_cifar10-sagemaker.ipynb(3)
from sagemaker.pytorch import PyTorch
from datetime import datetime, timedelta, timezone
# estimator
hyper_param = {
'workers': 2,
'epochs':2,
'batch_size': 4,
'lr': 0.001,
'momentum': 0.9,
}
cifar10_estimator = PyTorch(entry_point='../models/cifar10_sagemaker_org.py',
hyperparameters=hyper_param,
role=role,
framework_version='1.1.0',
train_instance_count=1,
train_instance_type=instance_type)
# fit
# date = datetime.now(timezone(timedelta(hours=+9), 'JST')).strftime("%Y%m%d%H%M")
cifar10_estimator.fit(
inputs=inputs,
# job_name='' + date,
)
-
実行結果はマネジメントコンソールから確認できる
- inputsデータのパス
- ハイパーパラメータ
- 学習スクリプト
- loss etc
-
Amazon SageMaker Search により、過去の学習結果を横断的に検索することができる

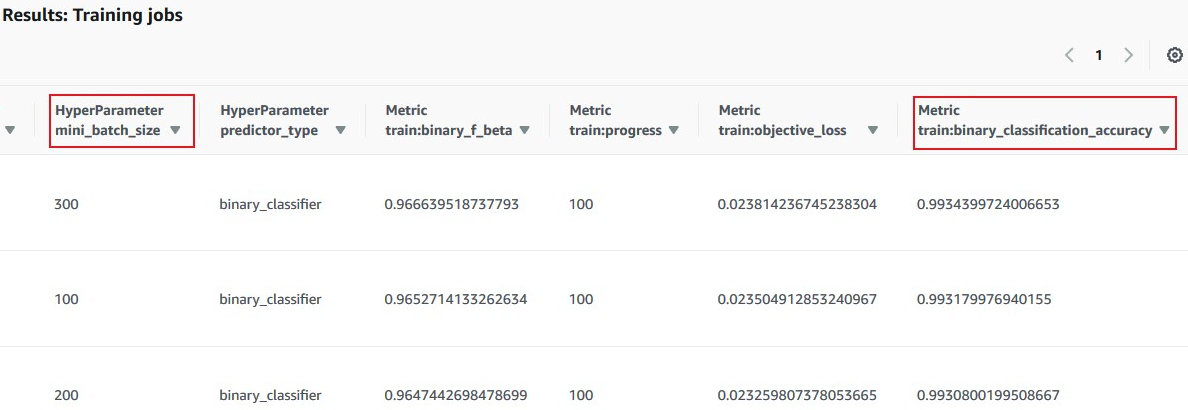
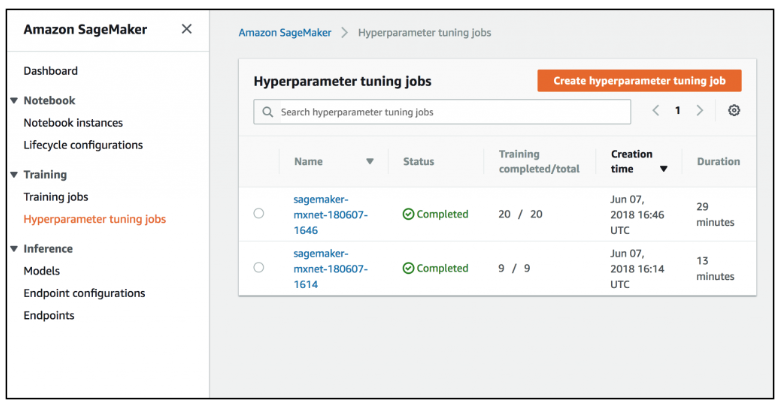
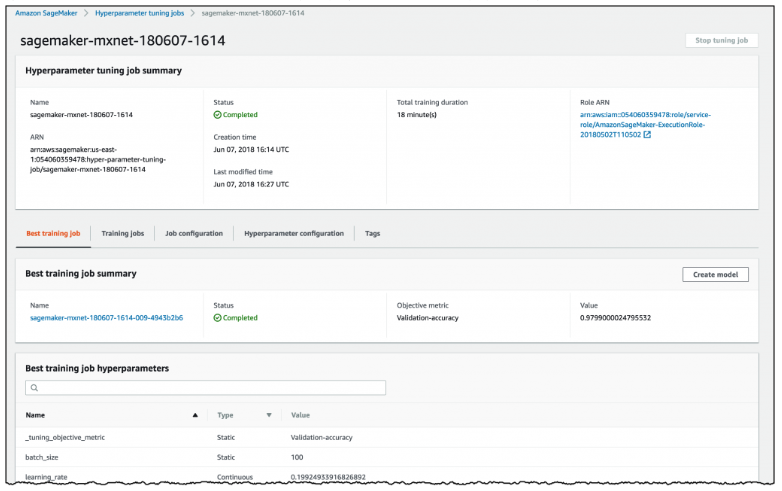
[optional]学習コンテナ起動(HyperparameterTuner)
- ハイパーパラメーターのレンジを指定すると、ハイパーパラメータチューニングジョブにより、完了したトレーニングジョブの結果をもとに様々な値の組み合わせで複数のトレーニングジョブを起動する。
- (参考)Amazon SageMaker 自動モデルチューニング: 機械学習のために機械学習を使用する
pytorch_tutorial_cifar10-sagemaker.ipynb(3)_2
from sagemaker.pytorch import PyTorch
from datetime import datetime, timedelta, timezone
from sagemaker.tuner import IntegerParameter, ContinuousParameter, HyperparameterTuner
# estimator
hyper_param = {
'workers': 2,
'epochs':2,
'batch_size': 4,
'lr': 0.001,
'momentum': 0.9,
}
cifar10_estimator = PyTorch(entry_point='../models/cifar10_sagemaker_org.py',
hyperparameters=hyper_param,
role=role,
framework_version='1.1.0',
train_instance_count=1,
train_instance_type=instance_type)
# tuner
hyperparameter_ranges = {
'batch_size': IntegerParameter(4, 64),
'lr': ContinuousParameter(1e-4, 0.1),
'momentum': ContinuousParameter(0.5, 0.9)
}
metric_definitions = [
{'Name': 'loss', 'Regex': 'loss: (\S+)'}
]
cifar10_tuner = HyperparameterTuner(estimator=cifar10_estimator,
objective_metric_name='loss',
objective_type='Minimize',
hyperparameter_ranges=hyperparameter_ranges,
metric_definitions=metric_definitions,
max_jobs=1,
max_parallel_jobs=1,
early_stopping_type='Auto')
# fit
# date = datetime.now(timezone(timedelta(hours=+9), 'JST')).strftime("%Y%m%d%H%M")
cifar10_tuner.fit(
inputs=inputs
# job_name='' + date,
)
3-1. [デプロイ]推論エンドポイント起動、削除
モデルをデプロイする(Amazon SageMaker Python SDK)
- エンドポイントをホストするインスタンスを起動->モデルをデプロイ
from sagemaker.pytorch import PyTorchModel
cifar10_predictor = cifar10_estimator.deploy(initial_instance_count=1,
instance_type=instance_type)
推論エンドポイントの削除(Amazon SageMaker Python SDK)
cifar10_estimator.delete_endpoint()
3-2. [デプロイ]推論実行
推論実行(Amazon SageMaker Python SDK)
# テストデータ準備
import torch
import torchvision
import torchvision.transforms as transforms
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4,
shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
# 画像表示準備
import matplotlib.pyplot as plt
import numpy as np
%matplotlib inline
def imshow(img):
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
# 推論実行(サンプル)
dataiter = iter(testloader)
images, labels = dataiter.next()
imshow(torchvision.utils.make_grid(images))
print('GroundTruth: ', ' '.join('%4s' % classes[labels[j]] for j in range(4)))
outputs = cifar10_predictor.predict(images.numpy())
_, predicted = torch.max(torch.from_numpy(np.array(outputs)), 1)
print('Predicted: ', ' '.join('%4s' % classes[predicted[j]]
for j in range(4)))
# 推論実行(精度算出)
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = cifar10_predictor.predict(images.numpy())
_, predicted = torch.max(torch.from_numpy(np.array(outputs)), 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / total))
おわりに
- 今後は下記あたりを検証していきます(SageMakerが直接関係ないものも含む)
- 学習データの保存先として、S3の代わりにEFSを利用(料金と処理時間を比較)
- 学習にスポットインスタンスを利用
- 学習ジョブにタグを付与
- 学習が完了したことを通知(Slack, Hangout)
- 学習させたモデルをダウンロードしてローカルでload
- 推論エンドポイントとして、Elastic Inferenceを利用
- 推論エンドポイントのスケールの挙動を検証
- データ(元)と前処理コードとデータ(加工後)とモデル定義とハイパーパラメータとモデルと学習結果とテスト結果を整合性の取れた管理、再現性の担保。