前回はマルチエージェントライブラリである AutoGen を用いて有限ステートマシンエージェントを実装しましたが、今回は LangGraph を使ってサイクルのある RAG アーキテクチャを実装していきたいと思います。
すでに Azure OpenAI Developers セミナー 第3回 で紹介したアーキテクチャで、Corrective-RAG (CRAG) という、自己修正的な RAG というアプローチの実装です。これを公式で提供されている Notebook を GPT-4/Azure AI Search/Bing Web Search API 実装に置き換えていきたいと思います。
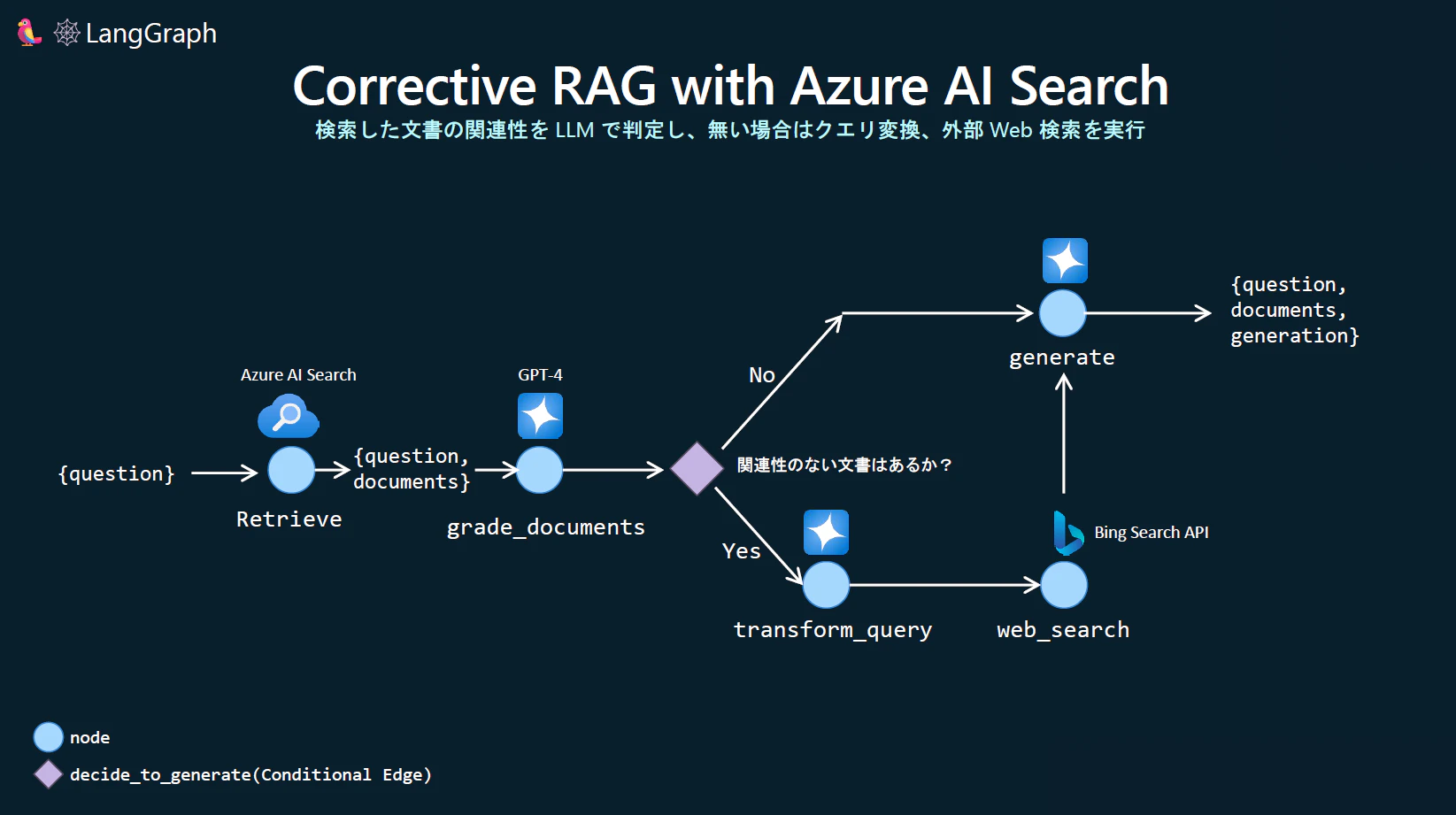
- Azure AI Search から Retrieve します
- GPT-4 で検索された文書が質問に関連しているかどうかを判断します
- 少なくとも一つの文書が関連性ありと判定された場合、回答の生成に進めます
- もしすべての文書が関連性なしと判定された場合、あるいは採点者が確信が持てない場合、追加のデータソースを探しに行きます
- いったんクエリの書き換えを行なってから、追加データソース今回は Bing Web Search API で Web から検索を実施します。
- GPT-4 で回答を生成します
関数の実装
実装はとてもシンプル。LangGraph では各ノードの処理を関数の形で記述していって、最後に関数をワークフローに add_node します。
retrieve (Azure AI Search)
今回はシンプルに Azure AI Search から全文検索で Retrieve するノードです。
retriever = AzureCognitiveSearchRetriever(
service_name="", #Your Azure AI Search service name
index_name="",
api_key="", #Your Azure AI Search API key
content_key="content",
top_k=3,
)
documents = retriever.get_relevant_documents(question)
grade_documents
検索された文書が質問に関連しているかどうかを判断するノードです。
# Prompt
prompt = PromptTemplate(
template="""あなたは、検索された文書とユーザーの質問との関連性を評価する採点者です。 \n
以下は検索された文書である。: \n\n {context} \n\n
以下はユーザーからの質問です。: {question} \n
文書にユーザーの質問に関連するキーワードまたは意味的(semantic)な意味が含まれている場合、関連性があると評価します。 \n
その文書が質問に関連しているかどうかを示すために、'yes' か 'no' の二値スコアを与える。""",
input_variables=["context", "question"],
)
関連性の判定結果を yes か no で出力して、decide_to_generate で遷移先を判定します。このプロンプトテンプレートは色々な場面で再利用できそうです。
decide_to_generate
回答を生成するか、質問を再生成するかの遷移先を決定します。
search = state_dict["run_web_search"]
if search == "Yes":
# All documents have been filtered check_relevance
# We will re-generate a new query
print("---DECISION: TRANSFORM QUERY and RUN WEB SEARCH---")
return "transform_query"
else:
# We have relevant documents, so generate answer
print("---DECISION: GENERATE---")
return "generate"
transform_query
クエリを変換して、より良い質問を作成するノードです。会話や複雑な質問の中から本質的な質問を抽出するのは多くのケースで使えるプロンプトです。
prompt = PromptTemplate(
template="""あなたは検索に最適化された質問を生成しています。\n
入力を見て、根底にある意味的な意図/意味を推論します。\n
これが最初の質問です:
\n ------- \n
{question}
\n ------- \n
日本語で出力してください。
改善された質問: """,
input_variables=["question"],
)
web_search
Bing Web Search API を使用して、修正された質問に基づく Web 検索を実施します。BingSearchAPIWrapper では検索結果のスニペットが得られるので、これを結果として使用します。
from langchain_community.utilities import BingSearchAPIWrapper
search = BingSearchAPIWrapper()
docs =search.results(question, 5)
print(question)
web_results = "\n".join([d["snippet"] for d in docs])
web_results = Document(page_content=web_results)
documents.append(web_results)
Bing Web Search API を LLM で用いるための使用および表示条件が追加されましたのでこちらもチェックしておく必要があります。
グラフの構築
以下のようにしてノードとエッジを構築していきます。
from langgraph.graph import END, StateGraph
workflow = StateGraph(GraphState)
# Define the nodes
workflow.add_node("retrieve", retrieve) # retrieve
workflow.add_node("grade_documents", grade_documents) # grade documents
workflow.add_node("generate", generate) # generatae
workflow.add_node("transform_query", transform_query) # transform_query
workflow.add_node("web_search", web_search) # web search
# Build graph
workflow.set_entry_point("retrieve")
workflow.add_edge("retrieve", "grade_documents")
workflow.add_conditional_edges(
"grade_documents",
decide_to_generate,
{
"transform_query": "transform_query",
"generate": "generate",
},
)
workflow.add_edge("transform_query", "web_search")
workflow.add_edge("web_search", "generate")
workflow.add_edge("generate", END)
# Compile
app = workflow.compile()
実行
inputs = {"keys": {"question": "源範頼ゆかりの地にあるカフェを提案してください"}}
for output in app.stream(inputs):
for key, value in output.items():
# Node
pprint.pprint(f"Node '{key}':")
pprint.pprint("\n---\n")
# Final generation
pprint.pprint(value["keys"]["generation"])
実行結果
---RETRIEVE---
retrieve: 源範頼ゆかりの地にあるカフェを提案してください
documents: 源範頼-1.txt, 源範頼-2.txt, 源範頼-3.txt
"Node 'retrieve':"
---CHECK RELEVANCE---
Score: [grade(binary_score='no')]
---GRADE: DOCUMENT NOT RELEVANT---
Score: [grade(binary_score='no')]
---GRADE: DOCUMENT NOT RELEVANT---
Score: [grade(binary_score='no')]
---GRADE: DOCUMENT NOT RELEVANT---
"Node 'grade_documents':"
---DECIDE TO GENERATE---
---DECISION: TRANSFORM QUERY and RUN WEB SEARCH---
---TRANSFORM QUERY---
"Node 'transform_query':"
---WEB SEARCH---
源範頼に関連する場所にあるカフェを教えてください。
Web Results: page_content='...'
"Node 'web_search':"
---GENERATE---
"Node 'generate':"
"Node '__end__':"
'静岡県伊豆市修善寺にある古民家カフェが源範頼に関連する場所にあります。
このカフェは静岡県伊豆市修善寺の観光の拠点であり、修禅寺の近くに位置しています。
源範頼のお墓についても伊豆・修善寺エリアにあると記載されています。'
Azure AI Search の検索結果 3 件分には関連性ナシ no と判定されたため、web_search ノードが実行され実際のカフェの情報を取得してきました。
今回は Bing Web Search を実装しましたが、このアーキテクチャは色々カスタムしがいがありそうです。例えば質問のクエリ拡張の追加、Web 検索結果の再評価など。また、AutoGen のマルチエージェント遷移よりも細かい粒度で実装できるのもいいですね。
GitHub
参考