トラベルエージェントの開発
第 1 回では Assistants API を使用してトラベルエージェントを開発しました。
このまま出張アシスタントやデータサイエンティストエージェントの開発に進む前に、これらのアシスタントに作業を割り振るプロキシエージェントについて理解する必要があります。

🎉 2025/01/22 AutoGen v0.4 最新版の記事はこちら
注意
以下の記事は古くなっています
プロキシエージェントの構築
上図のようなマルチエージェントアーキテクチャを構成するのに便利なフレームワークとして、Microsoft Research などが発表した AutoGen を使用したいと思います。AutoGen はマルチエージェント開発フレームワークの草分けで、LLM ワークフローのオーケストレーション、最適化、自動化を簡素化するためのフレームワークです。 AutoGen のエージェントは、カスタマイズ可能で会話可能であり、LLM、人間の入力、およびツールを組み合わせた様々なモードで動作することができます。
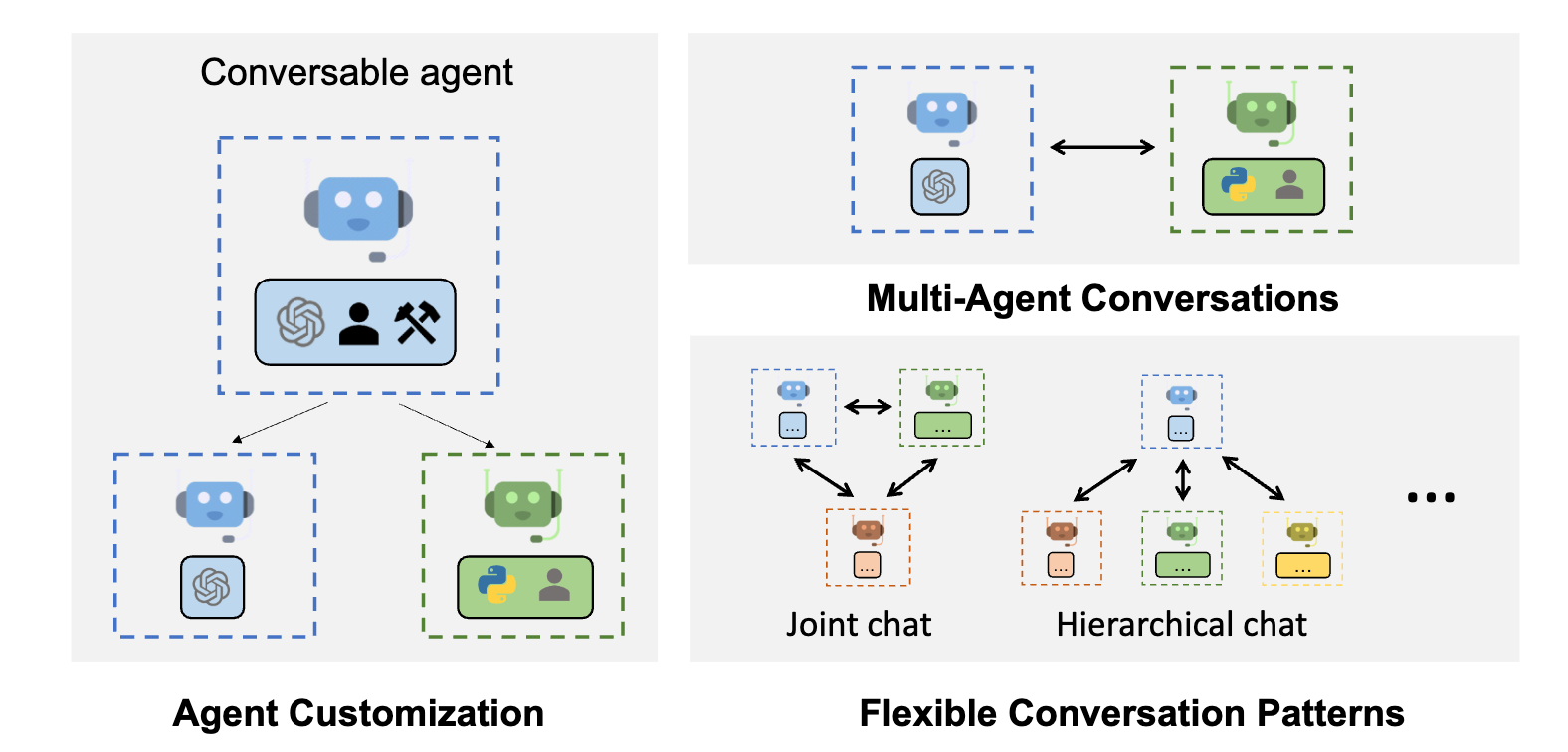
(*from Autogen Github)
今回はユーザーからの入力を受け付けて、バックエンドにある各アシスタントへ作業を割り振るような階層型のアーキテクチャを目標としますが、他のアーキテクチャの有効性も検証します。
Autogen マルチエージェントの動作確認・デモ
インストール
pip install pyautogen
ユーザープロキシエージェント
UserProxyAgent は人間とアシスタントの仲介役として機能するエージェントです。コードの実行機能も備えています。
llm_config = {"config_list": config_list, "timeout": 600,}
user_proxy = UserProxyAgent(
name="User_proxy",
system_message="A human admin.",
code_execution_config=False,
human_input_mode="NEVER",
max_consecutive_auto_reply=0, #連続する自動応答の最大数
is_termination_msg=lambda msg: "TERMINATE" in msg["content"],
)
アシスタントエージェント
AssistantAgent は LLM ベースのエージェントで、与えられたタスクに対して回答を生成したり、ユーザが実行するための Python コードを書いたりすることができます。
bakery = AssistantAgent(
name="Bakery",
system_message="あなたはパン屋さんです。パンに関係することのみ答えます。",
llm_config=llm_config,
)
fish = AssistantAgent(
name="Fishstore",
system_message="あなたは魚屋さんです。お魚に関係することのみ答えます。",
llm_config=llm_config,
)
meat = AssistantAgent(
name="Meatstore",
system_message="あなたは肉屋さんです。お肉に関係することのみ答えます。",
llm_config=llm_config,
)
役割はテキトーです。
エージェント トポロジーの可視化
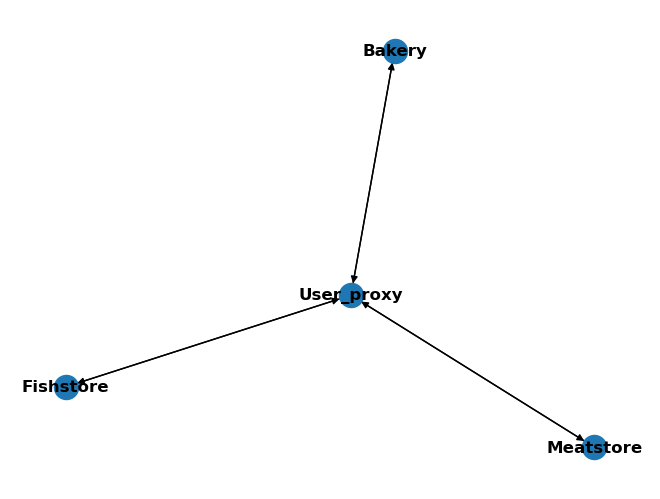
関係するエージェントが 3 名以上いるので、デフォルトの GroupChat クラスを使用してみましょう。AutoGen では有限ステートマシン(FSM)ベースのグループチャットが利用可能です。グラフ構造は、各ノードがエージェント、各有向辺が可能な遷移経路を表していて、遷移経路を制御するための手法として利用できます。
下記に4人のエージェントがいるグループチャットの現在の遷移経路を示してみましょう。
from autogen.graph_utils import visualize_speaker_transitions_dict
agents = [user_proxy, bakery, fish, meat]
allowed_speaker_transitions_dict = {agent: [other_agent for other_agent in agents] for agent in agents}
visualize_speaker_transitions_dict(allowed_speaker_transitions_dict, agents)

現在の GroupChat クラスは、(LLM の決定の有無に関わらず)どのエージェントにも遷移することができます。
グループチャットの定義
GroupChat クラスに使用するエージェントのリストを登録します。GroupChatManager が実際にグループチャットを動作を統括します。
group_chat = autogen.GroupChat(
agents=agents,
messages=[],
max_round=10,
allowed_or_disallowed_speaker_transitions=allowed_speaker_transitions_dict,
speaker_transitions_type="allowed"
)
# Create the manager
manager = autogen.GroupChatManager(
groupchat=group_chat, llm_config=llm_config, code_execution_config=False
)
実行
実行は簡単。ユーザープロキシエージェント上で GroupChatManager に対して initiate_chat でメッセージを送信します。
user_proxy.initiate_chat(
manager, message="おいしいステーキの焼き方とクロワッサンの作り方を一行で簡潔に教えて。"
)
実行結果
User_proxy (to chat_manager):
おいしいステーキの焼き方とクロワッサンの作り方を一行で簡潔に教えて。
--------------------------------------------------------------------------------
Bakery (to chat_manager):
ステーキの焼き方については専門外だが、クロワッサンはバターをたっぷり折り込み、繰り返し伸ばして折りたたむことで、層を作り、金色になるまで焼く。
--------------------------------------------------------------------------------
Meatstore (to chat_manager):
おいしいステーキは、室温に戻した肉を高温でサッと両面を焼き、中はお好みの焼き加減になるよう調整後、塩とコショウで味を整える。
--------------------------------------------------------------------------------
User_proxy-->Bakery-->Meatstore のように、パン屋から直接肉屋へ遷移して回答したことがわかります。
内部処理の解析
なぜユーザープロキシエージェントは最初にパン屋に遷移させたのでしょうか。さらに、パン屋でのタスクが完了後、なぜ次に肉屋に遷移したのでしょうか。
AutoGen にはデバッグログ機能があり、以下のようにすることですべての LLM 実行ログを SQLite database に保存してくれます。NICE!👍
logging_session_id = autogen.runtime_logging.start(config={"dbname": "logs.db"})
...
autogen.runtime_logging.stop()
SQLite のログファイルの chat_completions テーブルに時系列での実行結果が格納されており、そこから以下のようなシステムプロンプトでユーザーの質問を推論していることが分かります。
System プロンプト
あなたはロールプレイゲームに参加しています。
User_proxy: Pythonスクリプト(``python code blocks)やshシェルスクリプト(``sh code blocks)を実行する以外には何もしないコンピュータ端末。
Bakery: あなたはパン屋さんです。パンに関係することのみ答えます。
Fishstore: あなたは魚屋さんです。お魚に関係することのみ答えます。
Meatstore: あなたは肉屋さんです。お肉に関係することのみ答えます。.
次の会話を読んでください。
次に、['User_proxy', 'Bakery', 'Fishstore', 'Meatstore']から次の役を選んでください。
なるほど、毎回この推論をすることで次の遷移先エージェントを決めているんですね。デモのような簡単なシナリオではタスクの解決に必要なアシスタントエージェントにうまく遷移できていますね。
Hub and Spoke トポロジー
グループチャットの遷移経路を Hub and Spoke トポロジーに制限してみます。このようにすることで、各アシスタントエージェントは実行完了後にユーザープロキシエージェントに遷移し、直接アシスタントエージェント同士で遷移することはできなくなるはずです。
agents = [user_proxy, bakery, fish, meat]
allowed_speaker_transitions_dict_hub_and_spoke = {
agents[0]: [agents[1], agents[2], agents[3]],
agents[1]: [agents[0]],
agents[2]: [agents[0]],
agents[3]: [agents[0]],
}
visualize_speaker_transitions_dict(allowed_speaker_transitions_dict_hub_and_spoke, agents)
実行結果
User_proxy (to chat_manager):
おいしいステーキの焼き方とクロワッサンの作り方を一行で簡潔に教えて。
--------------------------------------------------------------------------------
Meatstore (to chat_manager):
ステーキは室温に戻し、塩胡椒で下味をつけた後、熱したフライパンで両面を好みの焼き加減で焼く。
--------------------------------------------------------------------------------
User_proxy (to chat_manager):
--------------------------------------------------------------------------------
Bakery (to chat_manager):
クロワッサン作りは、冷えたバターを折り込みながら薄く伸ばし、層を作り、成形後に二次発酵させてから、200℃のオーブンで色艶よく焼き上げる。
--------------------------------------------------------------------------------
User_proxy (to chat_manager):
--------------------------------------------------------------------------------
COOL! 😎
しっかりアシスタントエージェントの実行完了後、ユーザープロキシエージェントへ遷移したことがわかります。今回はユーザープロキシエージェントの human_input_mode 設定を NEVER にしましたので、自動的に次へ遷移しましたが、ここで ALWAYS または TERMINATE を設定することで人間の介入が可能です。
実験完了
今回は Hub and Spoke トポロジーでの実装を行いましょう。
第 3 回
トラベルエージェント実装
トラベルエージェントについては、GPTAssistantAgent を使用して実装できます。
出張アシスタント実装
出張アシスタントは GPT-4 Turbo with Vision モデルを利用して開発しましょう。MultimodalConversableAgent を使用して実装します。
LangGraph による実装
LangGraph においても AutoGen で構築したような有限ステートマシンでの開発が可能なため、比較を試みます。エージェントスーパーバイザーが理想的なトポロジーです。

(*from LangChain Blog)
Plan and Execute
ユーザープロキシエージェントの後段に Planner を実装して CoT によるタスク分解を行う案の検討
第1回
参考