前回は Azure AI Document Intelligence による文書構造の解析というテーマで Markdown や図、段落、セクションを抽出しました。今回は、作成した処理をカスタムスキルにして Azure AI Search のスキルパイプラインに統合し、インデクサーの処理と同期的に実行させます。
このカスタムスキルによって PDF の中身がスキャンされた 1 枚の画像であっても Azure AI Document Intelligence が特定の画像の領域のみを検出できるため、Azure AI Search 標準の機能では不可能だった高精度な類似画像検索エンジンを開発可能です。そして今後のマルチモーダル RAG システムの精度向上に役立つこと間違いナシです。
アーキテクチャ
以下に簡易的なカスタムスキルのアーキテクチャを示します。このカスタムスキルは、Azure AI Document Intelligence のレイアウトモデルを使用して PDF などのドキュメントから画像を抽出します。抽出した画像データは Azure Data Lake Storage Gen2 に保存します。
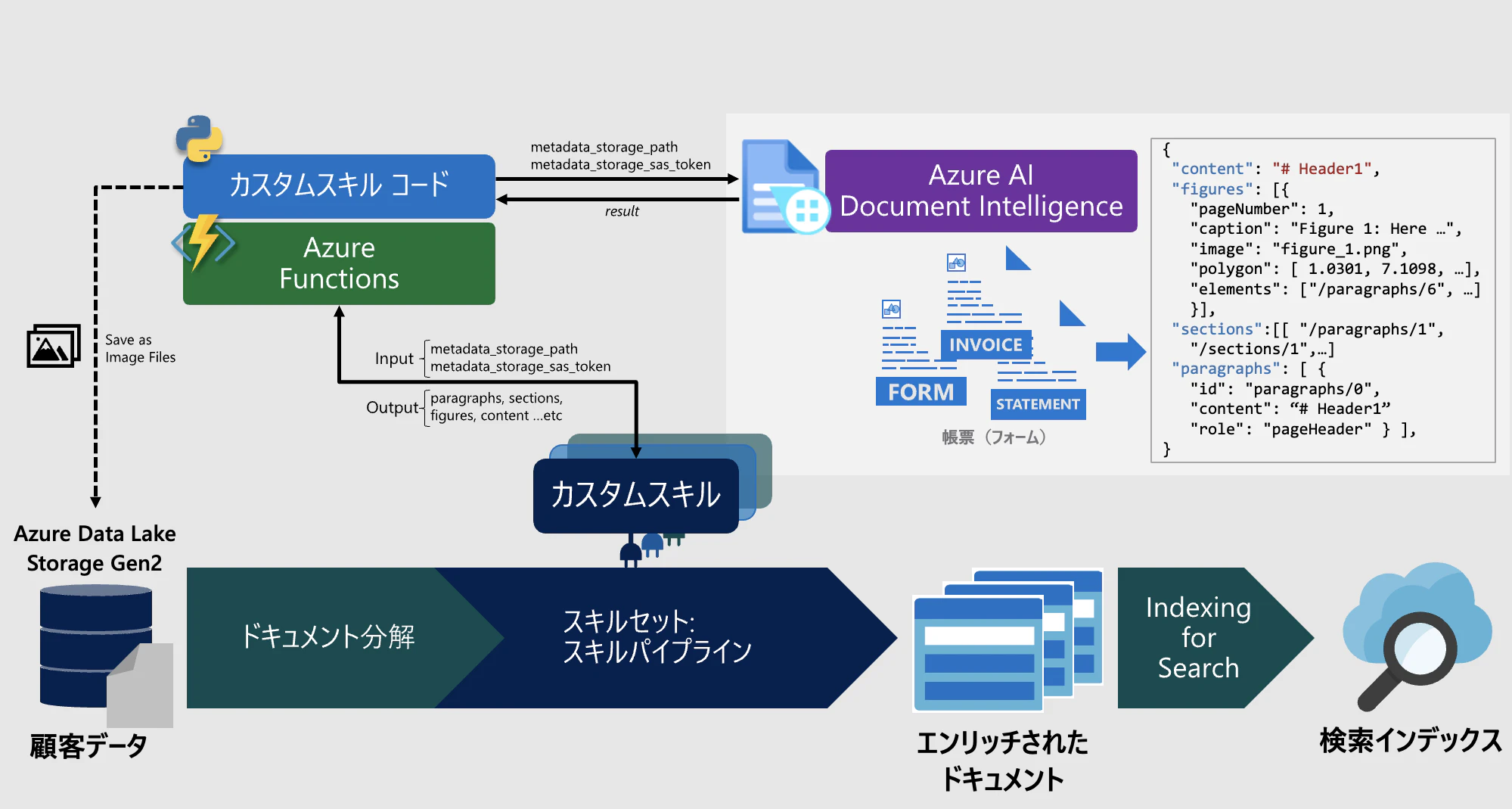
スキルを Azure Functions へデプロイ
本スキルは、Azure AI Document Intelligence リソースおよび、Azure Data Lake Storage Gen2(ストレージアカウント)リソースが必要です。また、DOCUMENT_INTELLIGENCE_ENDPOINTと DOCUMENT_INTELLIGENCE_KEY および、AZURE_STORAGE_CONNECTION_STRING、AZURE_STORAGE_CONTAINER_NAME が必要です。Azure Functions にデプロイする際は、「環境変数」項目に設定する必要があります。
手順
- Azure portal で、Azure AI Document Intelligence リソースを作成します。
- Azure AI Document Intelligence の API キーとエンドポイントをコピーします。
- ストレージアカウント リソースを作成します。
- ストレージブラウザーや Azure Storage Explorer を使用して画像ファイル出力先のコンテナを作成します。
- ストレージアカウントの接続文字列とコンテナ名をコピーします。
- レポジトリを clone します。
- Visual Studio Code でレポジトリのフォルダを開き、Azure Functions にリモートデプロイします。
- Functions にデプロイが完了したら, Azure Portal の Azure Functions の設定→環境変数から、
DOCUMENT_INTELLIGENCE_ENDPOINTとDOCUMENT_INTELLIGENCE_KEY、およびAZURE_STORAGE_CONNECTION_STRING、AZURE_STORAGE_CONTAINER_NAME環境変数を作成してそれぞれ値を貼り付けます。
Azure AI Search 側の設定
このスキルセットを実行するための Azure AI Search コンポーネントを一発で作成する Postman 用コレクションを用意しています。
この Postman コレクションには以下のリクエストおよび環境変数が含まれます。
- 01 - Create a datasource
- 02 - Create an Index
- 03 - Create a Skillset
- 04 - Create an Indexer
- 05 - Skill Execution Test
Postman のワークスペースでダウンロードしたコレクションファイル(azure-document-intelligence-image-extract-skill.postman_collection.json)をインポートします。環境変数(search-service1.postman_environment.json)をインポートしたら、以下のように準備したリソースの情報をセットします。
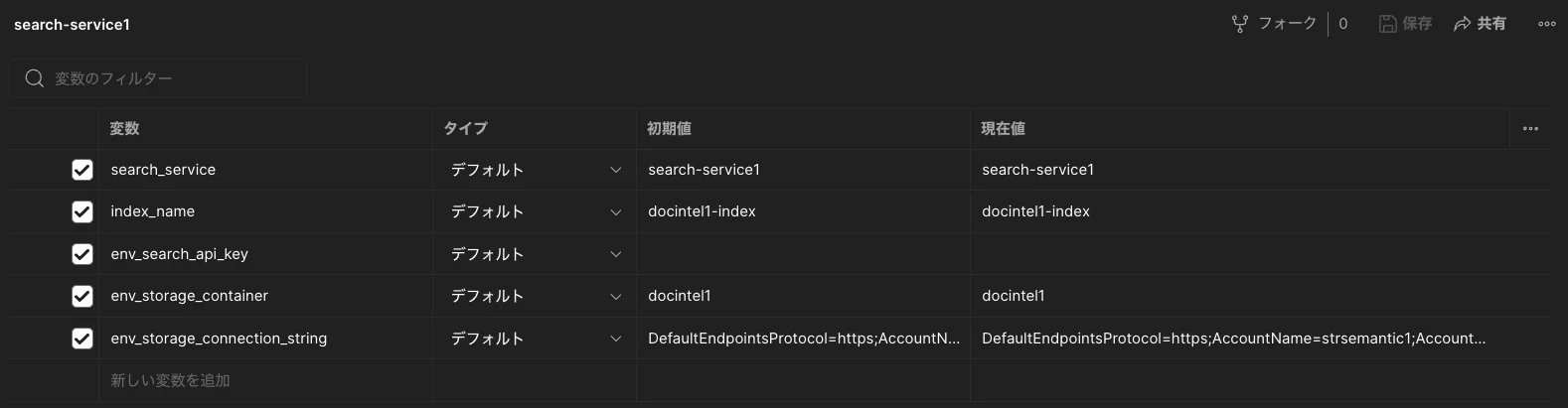
データソース準備
インデクサーで取り込むデータソースを準備します。Azure Data Lake Storage Gen2 に Blob コンテナーを作成して PDF や DOCX、PPTX などをアップロードします。
インデックスの作成
今回は以下のようなインデックスフィールドを用意します。paragraphs、sections、figures、markdown がメインのエンリッチデータとなります。必要に応じて、pages や tables も指定することができます。また、metadata_storage_path_raw は base64Encode しない生のストレージパスを格納します。
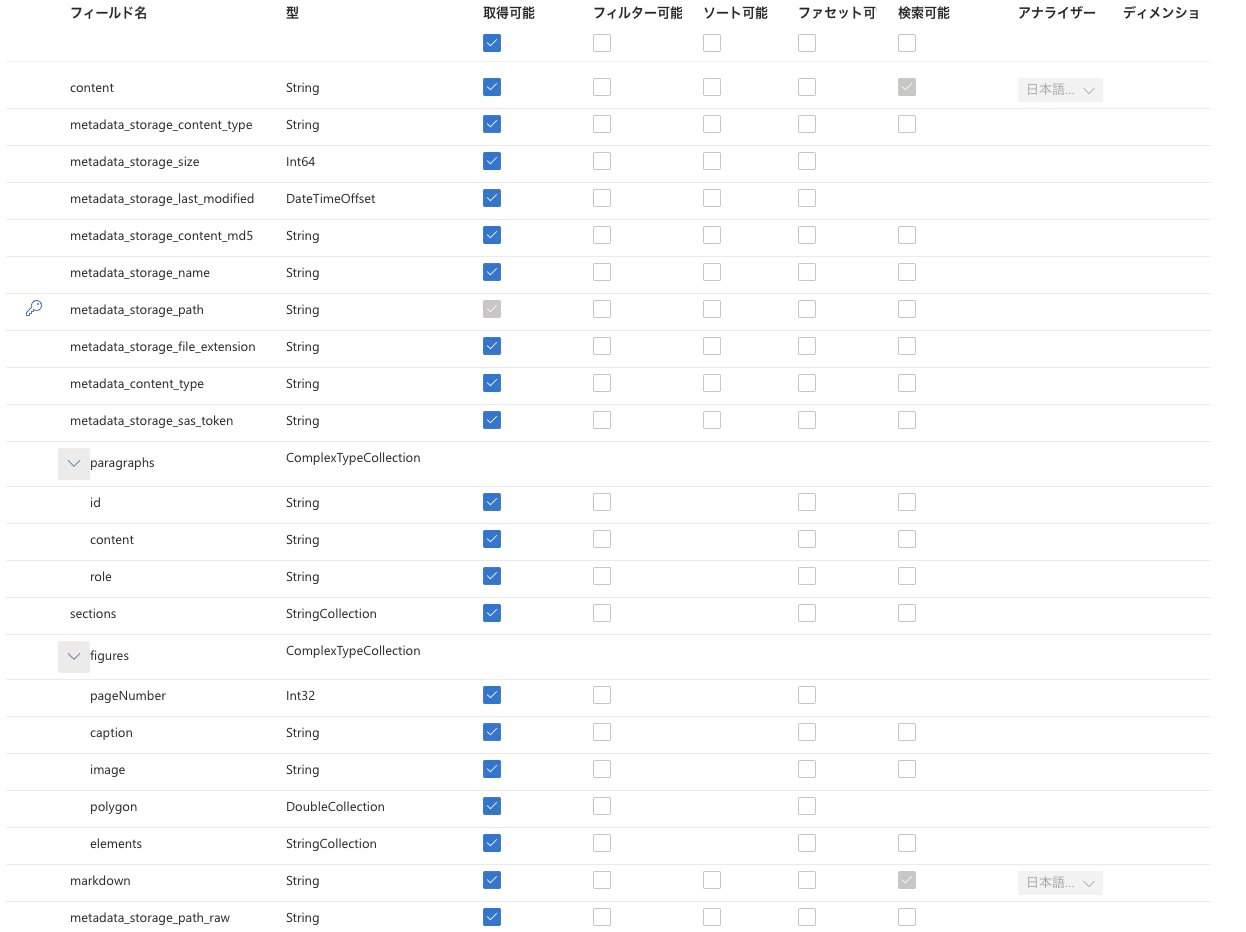
スキルセットの作成
今回追加するカスタムスキルの設定を挿入します。
{
"@odata.type": "#Microsoft.Skills.Custom.WebApiSkill",
"name": "ImageExtractSkill",
"description": "Extracts images and fields from a form using a pre-trained layout model",
"uri": "[AzureFunctionEndpointUrl]/api/analyze?code=[AzureFunctionDefaultHostKey]",
"context": "/document",
"httpMethod": "POST",
"timeout": "PT3M50S",
"batchSize": 1000,
"inputs": [
{
"name": "formUrl",
"source": "/document/metadata_storage_path_raw"
},
{
"name": "formSasToken",
"source": "/document/metadata_storage_sas_token"
},
{
"name": "model",
"source": "= 'prebuilt-layout'"
}
],
"outputs": [
{
"name": "paragraphs",
"targetName": "paragraphs"
},
{
"name": "sections",
"targetName": "sections"
},
{
"name": "content",
"targetName": "markdown"
},
{
"name": "figures",
"targetName": "figures"
}
]
-
uri: Azure Functions にデプロイした際の関数 URL をセットします。 -
formUrl:base64Encodeしない生のストレージパス -
formSasToken: インデックスフィールドにmetadata_storage_sas_tokenを追加すると、自動的に Azure Data Lake Storage Gen2 インデクサーが一時的に利用可能な SAS トークンを発行して格納します。 -
model: 基本的にprebuilt-layoutを使用します。
インデクサーの作成
インデクサーに出力フィールドのマッピングを設定します。これを行わないと、エンリッチ処理されたツリーから取得したデータを検索フィールドへマッピングすることができません。
{
"outputFieldMappings": [
{
"sourceFieldName": "/document/paragraphs",
"targetFieldName": "paragraphs"
},
{
"sourceFieldName": "/document/sections",
"targetFieldName": "sections"
},
{
"sourceFieldName": "/document/markdown",
"targetFieldName": "markdown"
},
{
"sourceFieldName": "/document/figures",
"targetFieldName": "figures"
}
]
}
metadata_storage_path_raw については、以下のように指定することによって base64Encode されていない生のストレージパスを格納することができます。
"fieldMappings": [
{
"sourceFieldName": "metadata_storage_path",
"targetFieldName": "metadata_storage_path_raw",
"mappingFunction": null
}
],
インデクサーの実行
すべての設定が完了したら、インデクサーを実行します。それぞれのターゲットフィールドにデータが格納されていることを確認します。
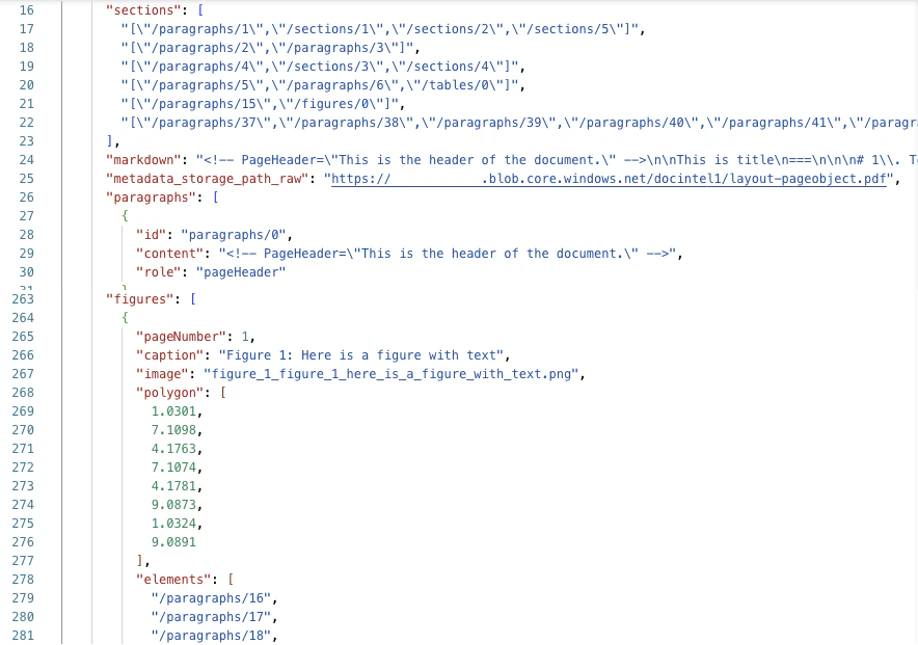
出力画像の確認
画像出力先のコンテナを確認します。サンプル PDF から抽出された図が正しく抽出されていることが確認できました。それに加えてカスタムスキルの機能で Blob のメタデータに figures の項目や親 PDF ファイル名もセットしているので Blob ファイル単独でも画像のコンテキストを把握可能です。

未実装の機能
チャンク分割
今回は content のチャンク分割機能は入れてません。本来は後段に配置した Split Skill および Index Projection 機能に任せたいところですが、まだセマンティックチャンキングは実装されていません。現状は LangChain の MarkdownHeaderTextSplitter と連携すれば簡単にセマンティックチャンキングを実現できます。
画像ベクトル検索
すでに紹介している記事を参考に実装が可能です。
GitHub
nohanaga/azure-document-intelligence-image-extract-skill
Postman コレクション
nohanaga/azure-document-intelligence-image-extract-skill-postman