数多くのパートナー様が生成 AI と検索エンジンを組み合わせた RAG アーキテクチャの実装を進めています。そんな中 GPT-4V の登場によりマルチモーダルな世界が一気に近づいてきております。今後のユーザーニーズとしては画像や音声を含めた対話が求められるでしょう。そして画像や音声データをオンデマンドな分析だけでなくナレッジマイニングのシナリオで用いることは必然でしょう。
画像ベクトル検索アーキテクチャ
Azure Blob Storage に保存されている画像ファイルや PDF に埋め込まれた画像を、画像もしくはテキストクエリーで検索できるようなシステムを考えます。
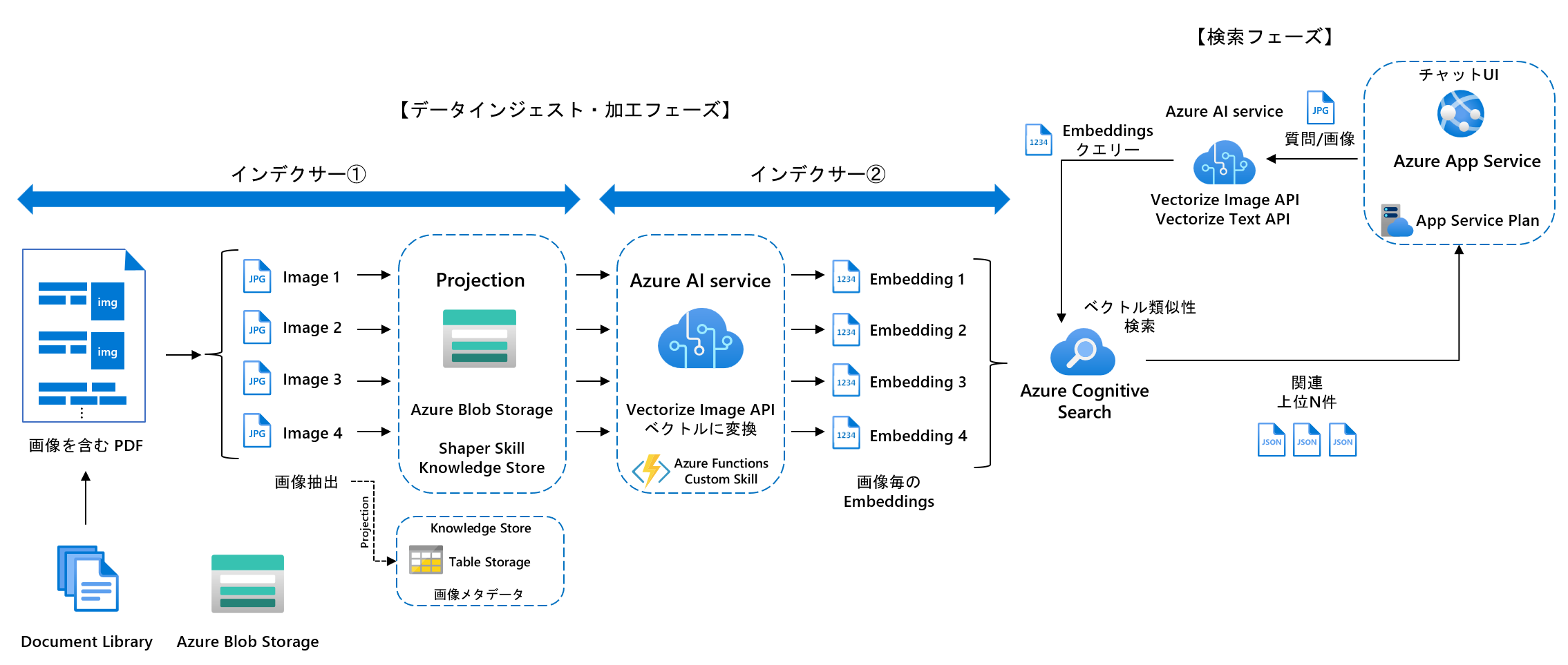
今回は PDF から画像を抽出するインデクサー①と抽出された画像を Embeddings に変換するインデクサー②の 2 つに分けて非同期で実行させる構成にしました。インデクサーもドキュメント用と埋め込み画像用の 2 つに分けています。このような構成にした理由は、ドキュメントと埋め込み画像の関係が 1:N であり、N 個生成される Embeddings を 1 つのドキュメント内に保存し、検索することが現在の Azure Cognitive Search のベクトル検索の仕様上不可能であるためです。
上記のアーキテクチャは一例であり、カスタムスキルによってプロジェクションの処理を代替させて 1 つのインデクサーで同期的に処理することも可能です。
1. データインジェストフェーズ
インデクサー①
Azure Cognitive Search のインデクサーの機能を使ってドキュメントから画像を抽出します。これはインデクサー設定で imageAction パラメータを generateNormalizedImages に設定することで実現できます。
"configuration": {
"dataToExtract": "contentAndMetadata",
"parsingMode": "default",
"imageAction": "generateNormalizedImages"
}
抽出した画像を Blob Storage へ保存するために Shaper Skill とナレッジストアへのプロジェクション(射影)機能を使って実現しています。ファイルプロジェクションは正規化画像 /document/normalized_images/* の射影のために用意された機能です。
"knowledgeStore": {
"storageConnectionString": "",
"identity": null,
"projections": [
"files": [
{
"storageContainer": "crossimages",
"referenceKeyName": null,
"generatedKeyName": "crossimages",
"source": "/document/crossProjection/images/*/image",
"sourceContext": null,
"inputs": []
}
]
]
}
上記のように設定することで、事前に準備された Blob Storage のコンテナに画像が出力されます。各画像のディレクトリ名には抽出元ドキュメントの Key が Base64 エンコードされた形でセットされるため、画像ファイルから抽出元へ辿ることができます。また、画像ファイルのメタデータに id がセットされ、この中にも Key が格納されます。さらにテーブル プロジェクションを使うことで、エンリッチされたデータ構造を列形式で射影できるため後段処理から必要に応じて参照することができます。
インデクサー②
インデクサー①によって Blob Storage に画像が保存されていますので、これをインデクサー②でクロールして画像ベクトル検索用のインデックスへ画像ファイル単位で Embeddings を保存します。Embeddings への変換は以下のようなカスタムスキルを用意しています。
{
"@odata.type": "#Microsoft.Skills.Custom.WebApiSkill",
"name": "GenerateImageEmbeddingsSkill",
"description": "Convert an image to a vector using the Vectorize Image API.",
"uri": "[AzureFunctionEndpointUrl]/api/GenerateImageEmbeddings?code=[AzureFunctionDefaultHostKey]",
"context": "/document/normalized_images/*",
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [
{
"name": "embeddings",
"targetName": "embeddings"
}
]
}
このカスタムスキルを Azure Functions へデプロイして Embeddings 変換用 API として稼働させます。インプットは正規化済み画像のバイナリで、アウトプットは 1,024 次元の float です。これを画像ドキュメントの embeddings フィールドにマッピングします。Azure Cognitive Search の仕様では最大 2,048 次元まで格納可能です。
Vectorize Image API
Azure AI services の Azure AI Vision Image Analysis サービスには、画像をベクトルに変換する機能があり、イメージ取得 API として Vectorize Image API と Vectorize Text API を使用して、画像またはテキストから特徴ベクトルを抽出できます。(引用)

カスタムスキルの /computervision/retrieval:vectorizeImage エンドポイントの呼び出しは以下のように行います。
def generate_embeddings(stream, aiVisionEndpoint, aiVisionApiKey):
logging.info("Generating embeddings...")
url = f"{aiVisionEndpoint}/computervision/retrieval:vectorizeImage"
params = {
"api-version": "2023-02-01-preview",
"modelVersion": "latest"
}
headers = {
"Content-Type": "application/octet-stream",
"Ocp-Apim-Subscription-Key": aiVisionApiKey
}
response = requests.post(url, params=params, headers=headers, data=stream)
if response.status_code == 200:
logging.info("Embeddings generated successfully")
embeddings = response.json()["vector"]
return embeddings
else:
logging.error(f'generate_embeddings Error {response.status_code}: {response.text}')
return None
2. 検索フェーズ
ユーザーからのクエリーは画像もしくはテキストで、それぞれ Vectorize Image API もしくは Vectorize Text API を使用して Embeddings に変換してからベクトル検索クエリーを送信します。
今回は画像ベクトル検索の試験のために私が開発している Simple-Cognitive-Search-Tester に画像ベクトル検索機能を搭載しました。試験に使うテストデータは美術展覧会のリーフレットの PDF ファイルを使用します。え、今回は戦国武将ではないって?私は美術展覧会が好きなのです。好きすぎて昔「あの展覧会混んでる?(サービス終了)」という Web サービスを運営していたほどです。
2.1. 画像から検索
「ひまわり」画像を画像クエリーで特定する
2023年10月17日~2024年1月21日に SOMPO 美術館で開催中の「ゴッホと静物画――伝統から革新へ」展のリーフレットの中の「ひまわり」(SOMPO 美術館所有)をピンポイントで特定します。

クエリーは、わざと正解画像とは異なるロンドン・ナショナル・ギャラリーが所有する 15 本バージョンのひまわりを使用します。

上記の画像を Simple-Cognitive-Search-Tester の Image Vector Search 機能からファイルを指定して「Get Embeddings」でまず Embeddings を取得します。その後、「Search!」ボタンを押下すると以下のように検索できます。
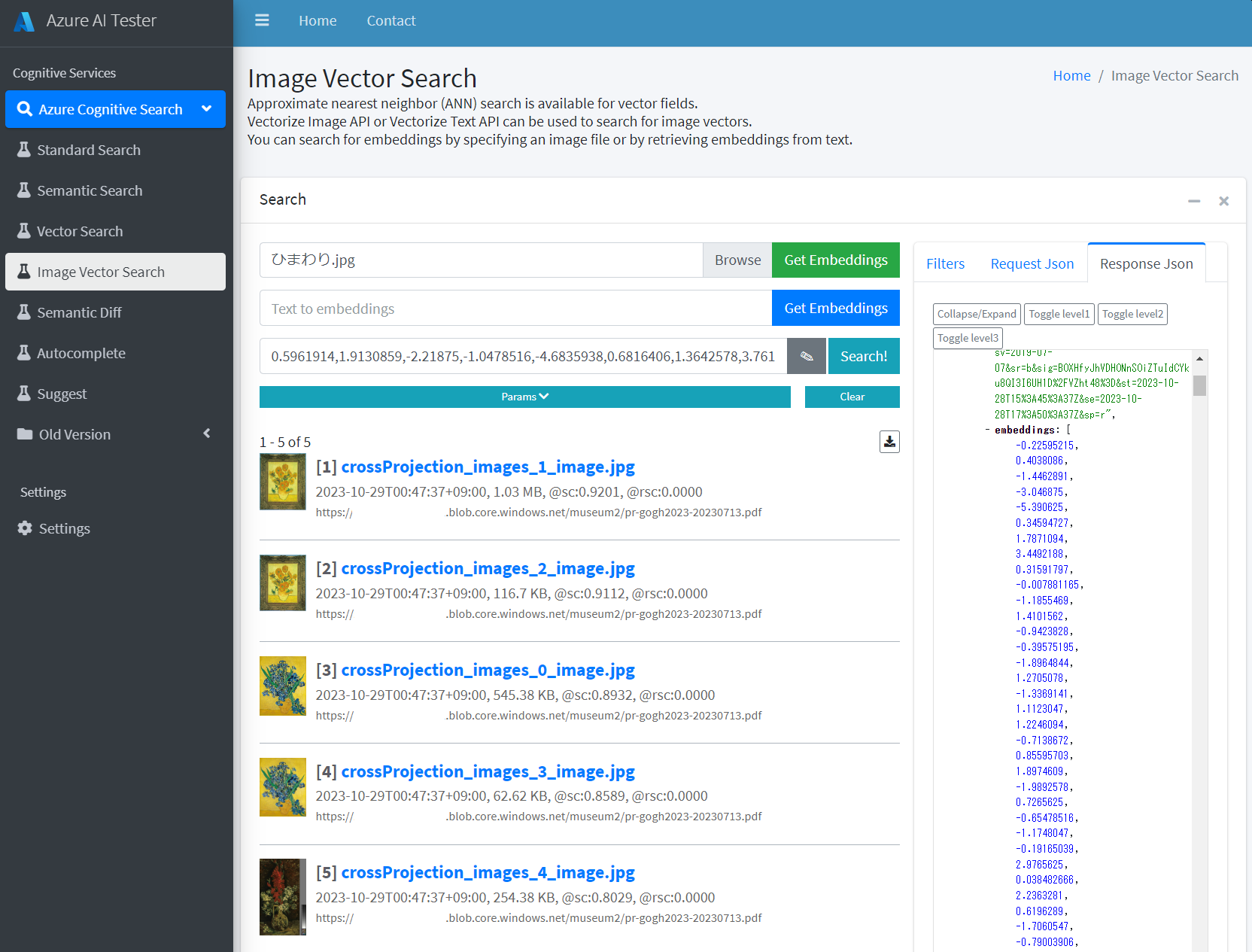
はい、欲しかった画像がコサイン類似度 0.92 で得られました。k = 5 件で検索していますが、ベクトル検索の場合、フルテキスト検索とは異なりインデックスに十分なドキュメントがある限り常に k 件の一致を返す点に注意してください。コサイン類似度の値に適切な閾値の設定が必要になるケースがあります。

画像プレビュー機能もあります。埋め込み画像は額付きで挿入されていたんですね。
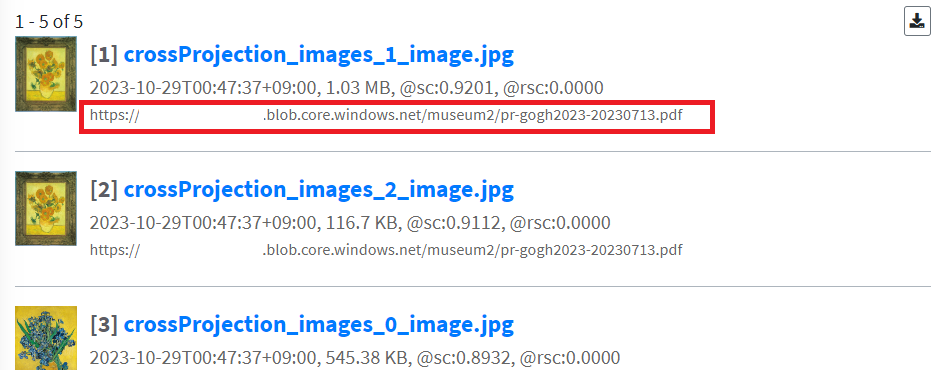
検索結果には抽出元ドキュメントのパスも表示しています。画像から抽出元ドキュメントへの参照を行ったり、UI に結果を組み合わせることも可能かと思います。
2.2. テキストから検索
①「ひまわり」画像をテキストクエリーで特定する
今度はテキストを Vectorize Text API を利用して Embeddings に変換して検索してみましょう。Text to Embeddings 欄に「sunflower」と入力して検索します。クエリーは英語である必要があります。日本語の場合は間に翻訳を挟む必要がありますが、OpenAI があれば造作もないことですね。
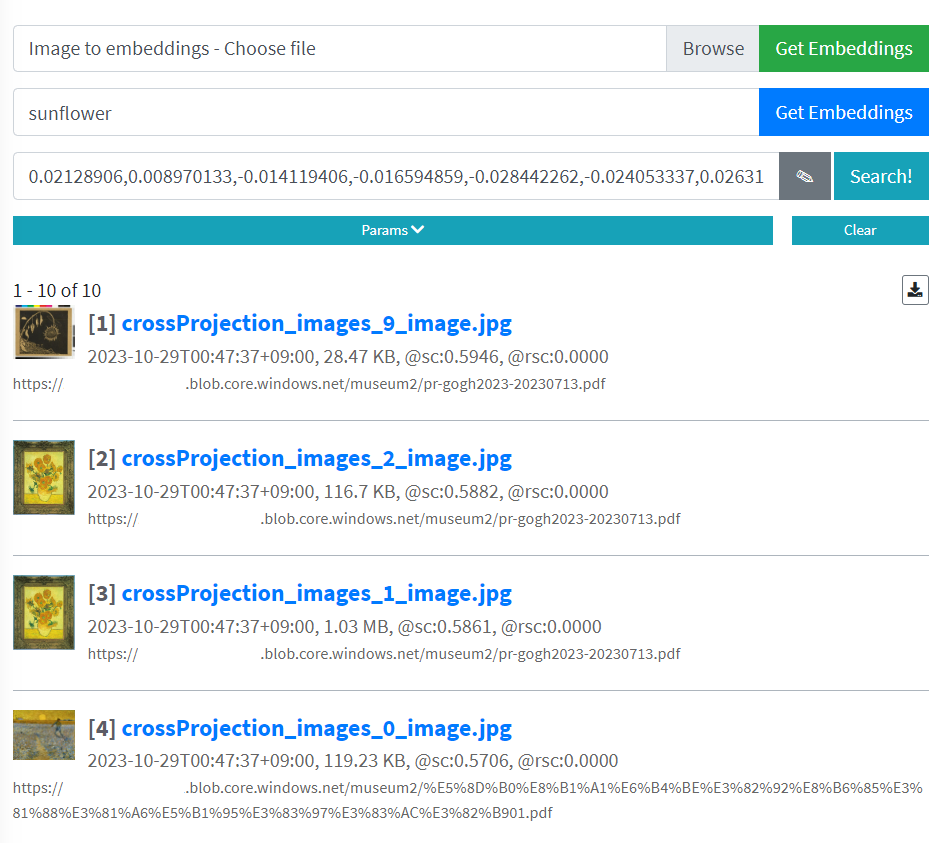
テキストからもうまく「ひまわり」が検索できていますね。今度は 1 位に枯れてるひまわりがヒットしました。これはリーフレットの以下の部分の画像がヒットしていることが分かります。

コサイン類似度を見ると 0.59~0.57 となっており固定閾値では判断が難しいです。
② モンドリアンの画像をテキストクエリーで特定する
「印象派を超えて 点描の画家たち」展ではゴッホやモネ、スーラからモンドリアンまで展示されたのですが、画家の名前をクエリーにして、その画家の絵画を検索できるのかどうかを検証します。

あ、できてしまいました。画家の名前で検索して、その人の絵がヒットするってすごくないですか?
接続設定
「Settings」メニューから Azure AI services セクションの AZURE_AI_SERVICES_ENDPOINT と AZURE_AI_SERVICES_KEY を設定します。これらの値は Azure Portal の Azure AI services リソースの「リソース管理」メニューの「キーとエンドポイント」から取得できます。
ファイル実体へのアクセス
今回はテスト利用ですのでプレビュー機能でアクセスする画像ファイルへのアクセス権限はインデクサーが一時的に発行する metadata_storage_sas_token を使用しています。インデックスフィールドに metadata_storage_sas_token を追加すると、自動的にインデクサーの Azure Blob コネクターが一時的に利用可能な SAS トークンを発行して格納します。一時的とは実際には 2 時間 5 分間だけ有効なトークンであり、カスタムスキルなどの利用のための非永続的なトークンです。
運用環境では必ず Microsoft Entra セキュリティ ID 等を用いたセキュリティフィルターの利用を検討してください。
画像と PDF の対応付けの限界
優秀な UI であれば、ヒットした画像と抽出元の PDF ドキュメントとの位置関係をリンクさせたいと考えるはずでしょう。標準でインデクサーが PDF ファイルから抽出する画像のメタデータは以下のようなものがあります。
{
"$type": "file",
"data": "/9j/4AA/2Q==",
"width": 574,
"height": 758,
"originalWidth": 574,
"originalHeight": 758,
"rotationFromOriginal": 0,
"contentOffset": 0,
"pageNumber": 0,
"contentType": "image/jpeg"
}
使えそうなデータが pageNumber くらいしかありません。高精度なリンクを実現するには工夫が必要ですね。
ハイブリッド検索
抽出元ドキュメントの本文と画像ファイルのインデックスが異なるため、単一のクエリーでハイブリッド検索を用いることができません。ただし独自に双方の検索ランキングを取得し RRF を計算することで実装は可能です。
Azure OpenAI Service との組み合わせ
今回は時間が無かったためチャット UI への画像アップロード機能や回答機能は実装していませんが、実際に UI まで含めたソリューションを検討されている方は Azure-Samples/azure-search-openai-demo などをベースに実装するのが楽かなと思います。