はじめに
Azure Cognitive Search は オープンソースの全文検索エンジンライブラリである Apache Lucene をベースに開発されており、多くの有用なモジュールを Azure Cognitive Search に取り入れています。その中には日本語アナライザーも含まれており、Azure Cognitive Search では日本語アナライザーとして、Lucene の日本語アナライザーと Microsoft Bing をベースとしたアナライザーの 2 種類から選ぶことができます。
これに加えて、Azure Cognitive Search では、カスタムアナライザーという機能を使うと独自のアナライザー(文字フィルター、トークナイザー、トークンフィルターの組み合わせ)を作成することができます。ただし現状はこちらの記事で説明しているとおり、日本語のカスタムアナライザーを実装しようとすると、Apache Lucene Kuromoji における JapaneseBaseFormFilter と JapanesePartOfSpeechStopFilter に相当するフィルターが実装されていないため、痒い所に手が届かないという…
検討
どうすればこの問題を回避できるのか考えてみたのだが、機能として実装してもらう以外にエレガントな解決方法が浮かばない件… もしくは(ry
一つの案として外部に Lucene などのアナライザーを用意してカスタムスキルの WebApiSkill 経由でフィールド値を処理し、whitespace アナライザーを設定したターゲットフィールドに格納するという手を考えたのだが、インデックス時はスペース区切りでトークン分割されるからいいとして、クエリー時にもスペース気にしないといけなくなるじゃないか。。。クエリーテキストにも前処理として同じアナライザーを通せばできなくはないが、作業が増える。
では、analyzer に ja.lucene を指定するか?これだと重複処理になる、せっかく外部アナライザーで残したトークンを消される可能性がある。ja.lucene では除去できないトークンを差分的に除去する目的であれば限定的だが使用できるか?え?nGram でいいって?…
以下、ただの作業メモ
まぁカスタムスキルで外部にオリジナルのアナライザーを置くというのは、azure-search-power-skills にもサンプルがあるとおり NG というわけではなさそうだ。新単語を独自の辞書を使ってトークン分割を行ったり、特定の品詞だけを除去したりしてオリジナルなフィールドを用意するというもの面白いかもしれない。
ということで、Apache Lucene Kuromoji を Azure Functions 上で動かしちゃうか。実装イメージはこんな感じ。。
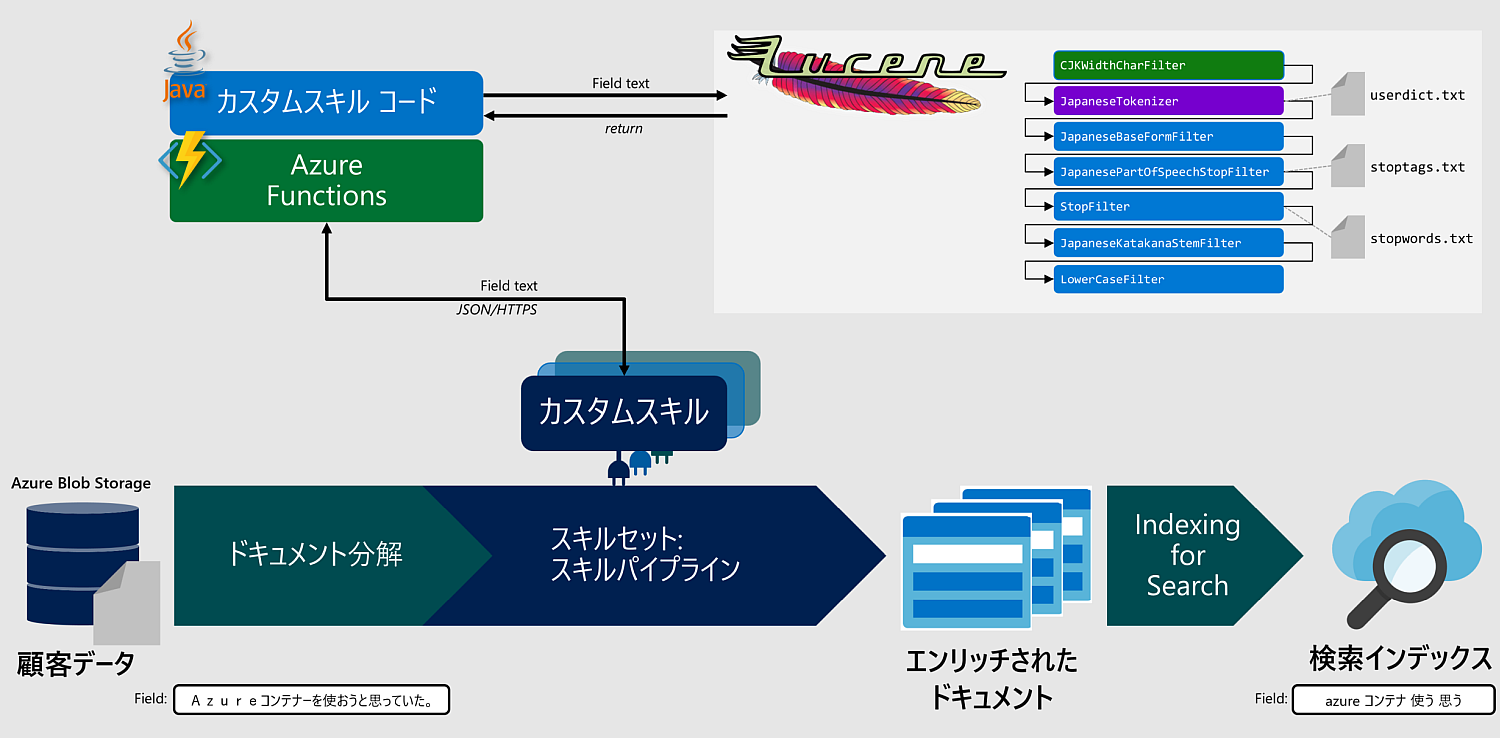
コチラの記事では Python コードを Azure Functions 上で動かしてカスタムスキルとして実装しているけど、Apache Lucene は Java ベースなので今度は Java コードを Azure Functions 上で動かす。今は Python ベースで軽快に動かせる形態素解析器もたくさんあるのでそちらを実装してしまうのもいいかも。
Github に lucene-kuromoji-on-azure-functions のコードを置いておく。
環境構築
- Gradle を利用して Java Functions を作成するサンプルがこちらにあるので、この前提条件をそろえる。
- VS Code で開く場合、Gradle for Java 拡張機能を入れる。
-
lucene-kuromoji-on-azure-functions を Git clone し、
/libディレクトリを作成。 -
Apache Lucene Archiveから、欲しいバージョンのライブラリをダウンロードする。今回は
lucene-8.2.0.zipをダウンロードした。解凍後、ディレクトリ内からlucene-analyzers-common-8.2.0.jar、lucene-analyzers-kuromoji-8.2.0.jar、lucene-core-8.2.0.jarをそれぞれ取り出して/libディレクトリにコピーする。
今回は Lucene Kuromoji の JapaneseAnalyzer.java をもらってきて、色々実験用に CustomJapaneseAnalyzer.java を作成している。
ローカル実行
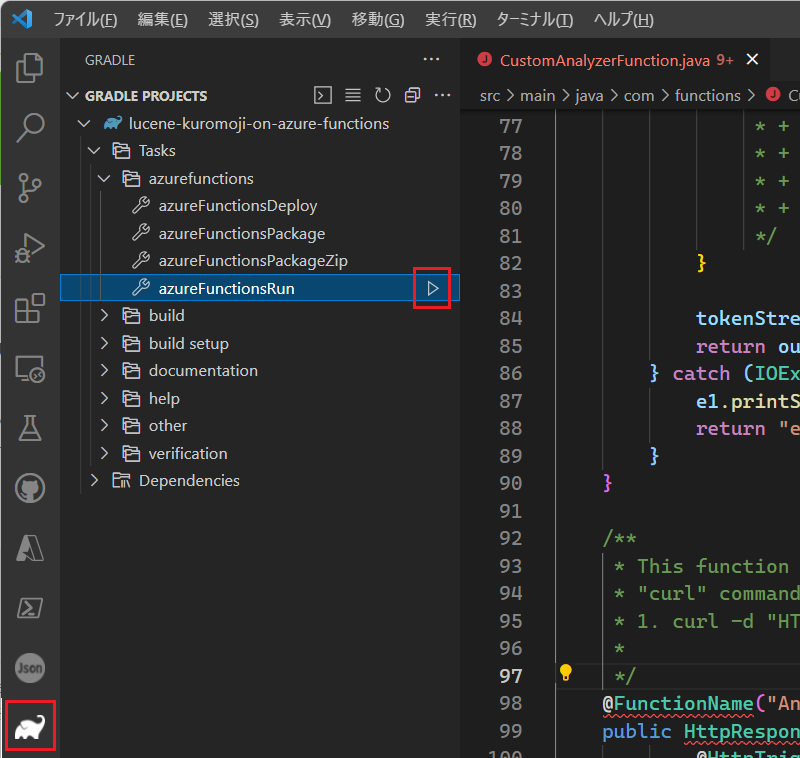
Gradle 拡張メニューから、Tasks -> azurefunctions -> azureFunctionsRun を実行。
Postman などで http://localhost:7071/api/Analyze に対して、以下の body を POST する。フォーマットは Azure Cognitive Search の WebApiSkill 形式になっている。
{
"values": [
{
"recordId": "0",
"data": {
"text": "私はマイクロソフトのAzureコンテナーを使おうと思っていた。"
}
}
]
}
レスポンスは以下のようになる。
{
"values": [
{
"recordId": "0",
"data": {
"words": "私 マイクロソフト azure コンテナ 使う 思う ",
"error": {}
}
}
]
}
自動的にトークンをスペース区切りでつなげるようにしている。あとはこれをインデックスフィールドにマッピングすれば OK!
Azure Functions へデプロイ
build.gradle の azurefunctions 項を自分がデプロイしたい Azure 環境に編集する。
azurefunctions {
resourceGroup = 'lucene-kuromoji-sample'
appName = 'lucene-kuromoji-sample'
pricingTier = 'Consumption'
region = 'westus'
runtime {
os = 'Windows'
javaVersion = 'Java 8'
}
auth {
type = 'azure_cli'
}
localDebug = "transport=dt_socket,server=y,suspend=n,address=5005"
}
Gradle 拡張メニューから、Tasks -> azurefunctions -> azureFunctionsDeploy を実行。
デプロイが完了したら、Azure Portal からも以下のようにリソースが見えるようになっている。
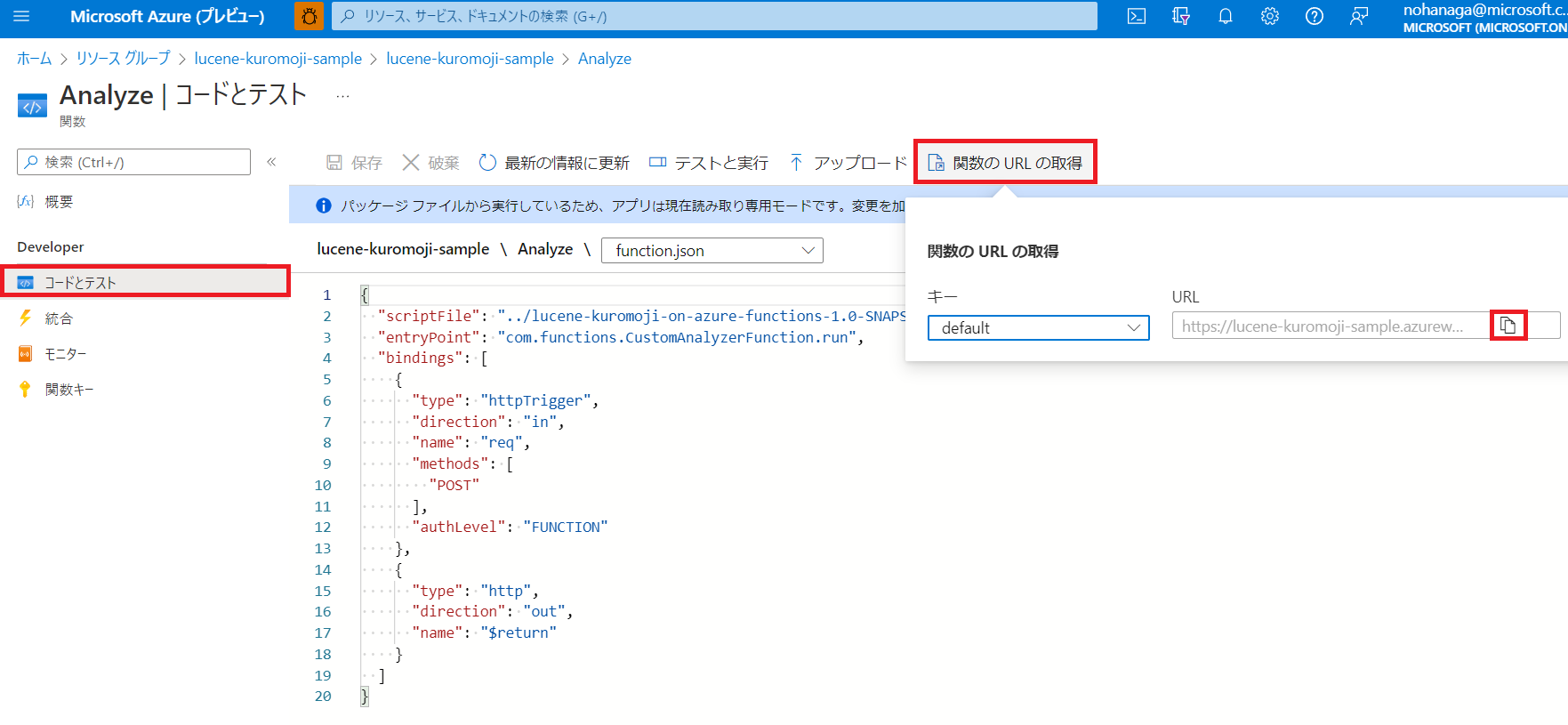
上記のように「関数の URL の取得」からアクセスキー付きエンドポイント URL を取得する。あとはこの URL に Postman から POST すれば OK。Azure Functions を使うと Java のデプロイもめっちゃ簡単なんやな!
カスタムスキル実装
スキルセット定義
{
"@odata.type": "#Microsoft.Skills.Custom.WebApiSkill",
"name": "#8",
"description": null,
"context": "/document/merged_content",
"uri": "https://{YOUR FUNCTIONS NAME}.azurewebsites.net/api/Analyze?code=xxxxxxxxxxxxxxxxxx==",
"httpMethod": "POST",
"timeout": "PT30S",
"batchSize": 1,
"degreeOfParallelism": null,
"inputs": [
{
"name": "text",
"source": "/document/merged_content"
}
],
"outputs": [
{
"name": "words",
"targetName": "words"
}
],
"httpHeaders": {}
}
インデクサー定義
{
"sourceFieldName": "/document/merged_content/words",
"targetFieldName": "words"
}
インデックス定義
フィールド定義
{
"name": "words",
"type": "Edm.String",
"facetable": false,
"filterable": false,
"key": false,
"retrievable": true,
"searchable": true,
"sortable": false,
"analyzer": "CustomJapaneseAnalyzer",
"indexAnalyzer": null,
"searchAnalyzer": null,
"synonymMaps": [],
"fields": []
}
アナライザー定義
"analyzers": [
{
"@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer",
"name": "CustomJapaneseAnalyzer",
"tokenizer": "whitespace",
"tokenFilters": [
"cjk_width",
"lowercase"
],
"charFilters": []
}
]
words フィールドに解析結果を格納している。whitespace アナライザーだけだと、全角/半角文字や大文字小文字の正規化ができないので、cjk_width フィルターと lowercase フィルターも同時に指定している。type は、Collection(Edm.String) でもいいんだけど、@search.highlights をフロントに表示するときに文章風になるようにあえて Edm.String にしている。
日本語アナライザーの編集
org.apache.lucene.analysis.ja.JapaneseAnalyzer.java をベースにして CustomJapaneseAnalyzer.java を作成する。
TokenStream のカスタム
CustomJapaneseAnalyzer.java の 101 行目付近では、JapaneseTokenizer とそれに続くフィルター処理の流れが記述されているのでここで減らしたり増やしたりできる。参考:Luceneフィルタ一覧
@Override
protected TokenStreamComponents createComponents(String fieldName) {
Tokenizer tokenizer = new JapaneseTokenizer(userDict, true, mode);
TokenStream stream = new JapaneseBaseFormFilter(tokenizer);
stream = new JapanesePartOfSpeechStopFilter(stream, stoptags);
stream = new StopFilter(stream, stopwords);
stream = new JapaneseKatakanaStemFilter(stream);
stream = new LowerCaseFilter(stream);
return new TokenStreamComponents(tokenizer, stream);
}
上記のほかにもいろいろ使えそうなフィルターが用意されている。
-
JapaneseReadingFormFilter
日本語トークンの読みをカタカナまたはローマ字に変換するトークンフィルター。例:漢字→カンジ -
JapaneseNumberFilter
日本語の漢数字をアラビア数字に正規化するトークンフィルター。例:壱万円→10000円 -
JapaneseIterationMarkCharFilter
日本語の繰り返し記号(踊り字)を展開した形に正規化する文字フィルター。例:学問のすゝめ→学問のすすめ
※これは文字フィルターなのでReaderに対して使用
ほーこれは面白いやん。
ユーザー辞書をカスタムする
デフォルトでうまく分割されない用語を登録するには、ユーザー辞書を使う。ファイルはsrc\main\resources\com\functions\userdict.txt にある。
# Custom segmentation for long entries
# 単語, 単語分割表現, よみがな, 品詞名
日本経済新聞,日本 経済 新聞,ニホン ケイザイ シンブン,カスタム名詞
関西国際空港,関西 国際 空港,カンサイ コクサイ クウコウ,テスト名詞
アジュールコグニティブサービス,アジュール コグニティブ サービス,アジュール コグニティブ サービス,カスタム名詞
例:「アジュールコグニティブサービス」は ja.lucene ではトークン分割されない。つまり「アジュール」や「コグニティブ」ではヒットしないので、分割表現をスペース区切りで登録してあげることでヒットできるようにする。既定の辞書とユーザー辞書に同じ単語があった場合、ユーザー辞書が優先される。
ストップタグをカスタムする
特定の品詞を除去したい場合、ストップタグを使用する。ファイルは、src\main\resources\com\functions\stoptags.txt にある。削除したい品詞はコメントを外す。
例:特定品詞だけが含まれるフィールドを作成する
ストップワードをカスタムする
一般的に検索には役に立たないが、ランキングには悪影響を与えるような単語「ストップワード」を削除する。ストップワードリストは、src\main\resources\com\functions\stopwords.txt にある。
IPAdic-NEologd 辞書を使う
新語の対応に定評のある、Neologd 辞書に対応した Lucene Kuromoji を使うこともできる。lucene-analyzers-kuromoji-ipadic-neologd のアーカイブから、lucene-analyzers-kuromoji-ipadic-neologd-x.x.x-MMMMYYDD.jar をダウンロードして /lib ディレクトリに格納する。
CustomJapaneseAnalyzer.java の import を以下のように切り替える。
import org.codelibs.neologd.ipadic.lucene.analysis.ja.JapaneseBaseFormFilter;
import org.codelibs.neologd.ipadic.lucene.analysis.ja.JapaneseKatakanaStemFilter;
import org.codelibs.neologd.ipadic.lucene.analysis.ja.JapanesePartOfSpeechStopFilter;
import org.codelibs.neologd.ipadic.lucene.analysis.ja.JapaneseTokenizer;
import org.codelibs.neologd.ipadic.lucene.analysis.ja.JapaneseTokenizer.Mode;
import org.codelibs.neologd.ipadic.lucene.analysis.ja.dict.UserDictionary;
IPAdic-NEologd 辞書にすると、「アジュールコグニティブサービス」は、以下のように解析される。
azure 0-5,名詞-固有名詞-一般,null,null,Azure,アジュール,アジュール
アジュールコグニティブサービス 0-15,名詞-固有名詞-組織,null,null,null,null,null
コグニティブサービス 5-15,名詞-一般,null,null,null,null,null
おおっ、「アジュール」が「azure」でも検索できるのは素晴らしい!これだよこれ。ただ、上記だと「アジュール」では結局検索にヒットしない。
解析のされ方や品詞名、原形などを出力するには、CustomAnalyzerFunction.java の tokenStream.addAttribute 関連のコメントアウトを外す。下記コードは Lucene Kuromoji から引用させてもらった。
System.out.println(term.toString() + "\t" // 表層形
+ offset.startOffset() + "-" + offset.endOffset() + "," // 文字列中の位置
+ partOfSpeech.getPartOfSpeech() + "," // 品詞-品詞細分類1-品詞細分類2
+ inflection.getInflectionType() + "," // 活用型
+ inflection.getInflectionForm() + "," // 活用形
+ baseForm.getBaseForm() + "," // 原形 (活用しない語では null)
+ reading.getReading() + "," // 読み
+ reading.getPronunciation()); // 発音
検索クエリーどないしよ…
外部にアナライザーを持ってしまったため、検索クエリーに対しての解析が既定の機能ではできない。検索クエリーに対して Azure Cognitive Search の Search API をコールする前にアプリケーション側で外部アナライザーと同じ処理をすれば可能ではある。分割結果に対しては searchMode も考慮する。もし記号や論理式が入っている場合は…。oO(ちゃんと作ろう)
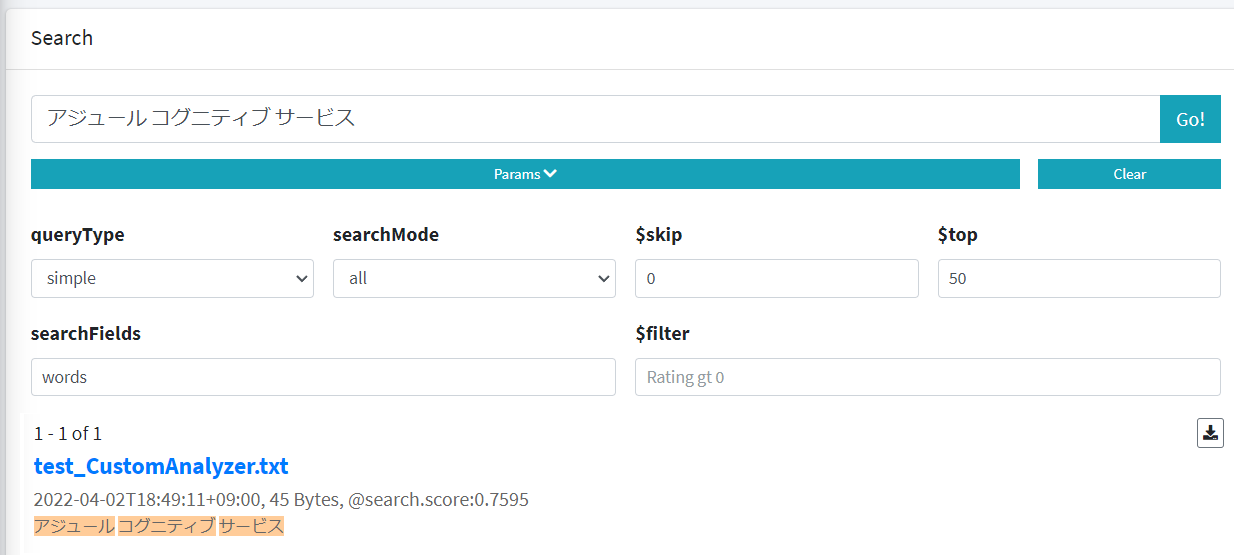
いちおう、上記条件で ja.lucene で検索できなかったドキュメントを検索できた。検索パラメータの指定は Simple-Cognitive-Search-Tester を使うと便利。
whitespace アナライザーフィールドの場合、@search.highlights データを取得したときの強調表示タグの周囲の抽出がピンポイントではないため、先頭で3行とかで表示しようとしたときに強調タグが表示されない場合がある。フロント部分で調整する必要がありそうだ。
まとめ
まぁそもそも Azure Cognitive Search はノーコードで簡単に埋め込みの日本語アナライザーが 2 種類も使えるというのが魅力なので、そっちのフィールドをメインにしつつ、カスタムしたフィールドを補助的に用いるのがよさそう。ただ当然インデックスサイズは増大するし、実装時には精度の検証も必要だ。
参考記事
Azure Cognitive Search を使って簡単ナレッジマイニングハンズオン(日本語対応)
Azure Cognitive Search のカスタムスキルを作成しよう
Azure Cognitive Search のデバッグセッションを使ってカスタムスキルを追加しよう