はじめに
組織内に貯まっている大量な構造化・非構造化データから、新たな価値を見出すためのフルマネージド全文検索サービスである Azure Cognitive Search を使えば、誰でも簡単に AI 搭載検索エンジンを開発することができます。今回はノーコード、画面上の操作だけで簡単に検索インデックスを作成する手順をハンズオン形式でご紹介します。
2021/07/01 Updates🎉
Azure Cognitive Search の検索機能を重点的に理解することにフォーカスを当てた新たなワークショップを公開しましたのでこちらもご覧ください。
目次
- Azure Cognitive Search とは
- 検索サービスの作成
- Azure Blob Storage の作成
- インデックスの作成
- インデクサーの作成
- インデクサーの実行
- スキルセットの修正
- デモアプリの作成
- 参考リンク
Azure Cognitive Search とは
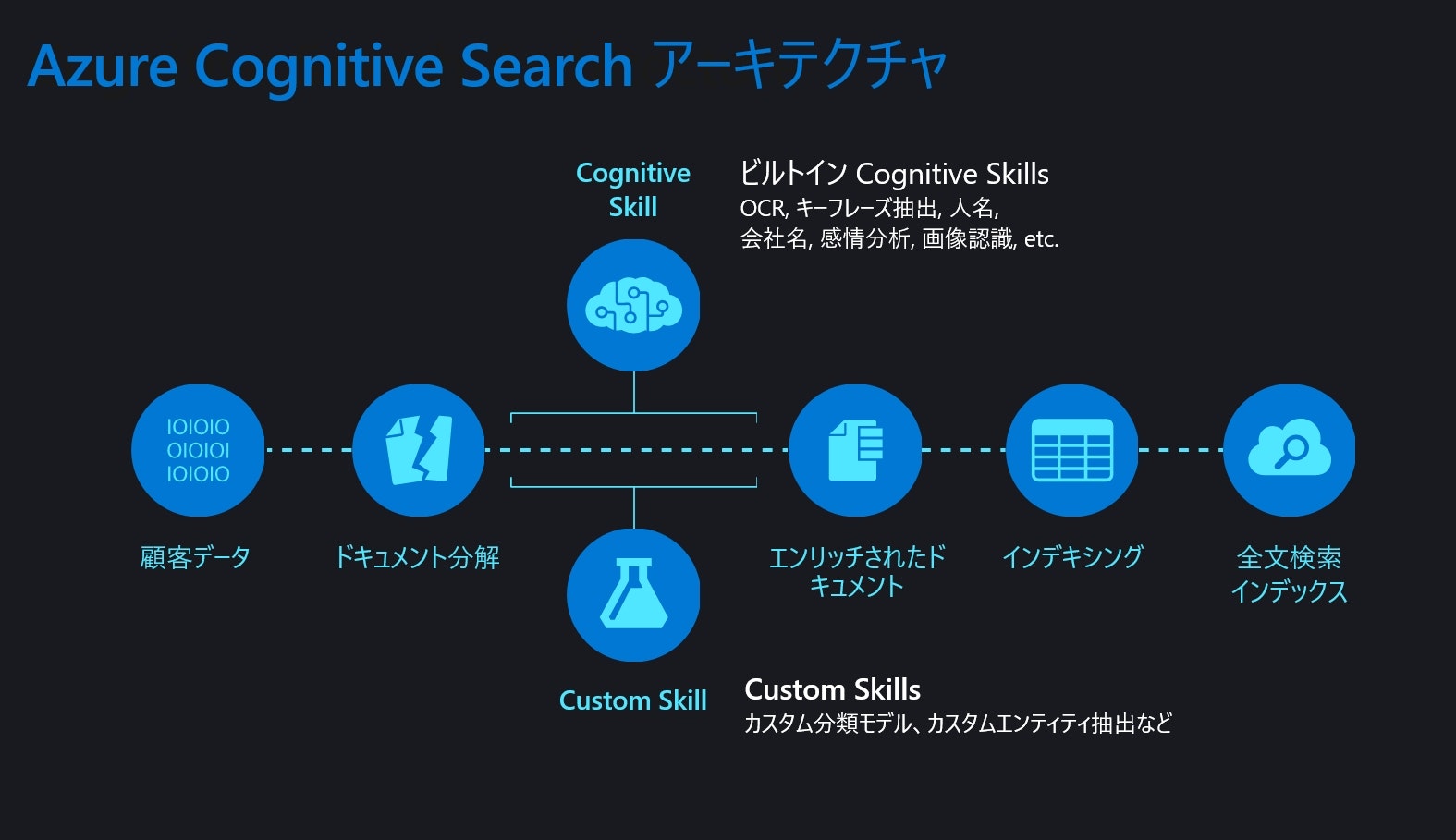
Azure Cognitive Search は、クラウド上に貯まった様々なデータから、Microsoft の最先端の AI 技術を使って様々なメタデータを抽出し、それを検索インデックスにして検索できるようにするサービスです。構造化データや内部解析可能なドキュメントファイルから中身を取り出すことは簡単ですが、Azure Cognitive Search では上図のような Cognitive Skill や Custom Skill を使って取り出す能力を拡張できるというのが大きな価値となります。
私が Azure Cognitive Search の概要を 30 分にまとめたビデオがありますので、必要であればご覧ください。
検索サービスの作成
Azure Portal にログインし、新規でリソースグループを作成します。
作成したリソースグループの中に、検索サービスを追加します。マーケットプレイスで、「Azure Cognitive Search」と検索してください。

新しい検索サービスウィザードで、必要事項を入力します。価格レベルでは、必要なプランを選択します。こちらの料金表も参考にしてください。無料プランで始めることもできます。

デプロイが完了し、作成された検索サービスをクリックすると、以下のようなポータル画面が表示されます。

このポータル画面上でインデックス、インデクサー、データソース、スキルセットの作成や編集を行うことができます。
Azure Blob Storage の作成
ここで一旦リソースグループに戻り、検索対象のデータを保管するためのストレージアカウントを追加します。
マーケットプレイスで、「ストレージ」と入れて検索してください。

今回は、ドキュメントファイルや画像データを保管できるシンプルな Blob Storage があればよいので、以下のように設定します。

ストレージアカウントのデプロイが完了しましたら、ストレージアカウントの左メニューから「コンテナー」を選択し、以下のように新しいコンテナーを作成します。

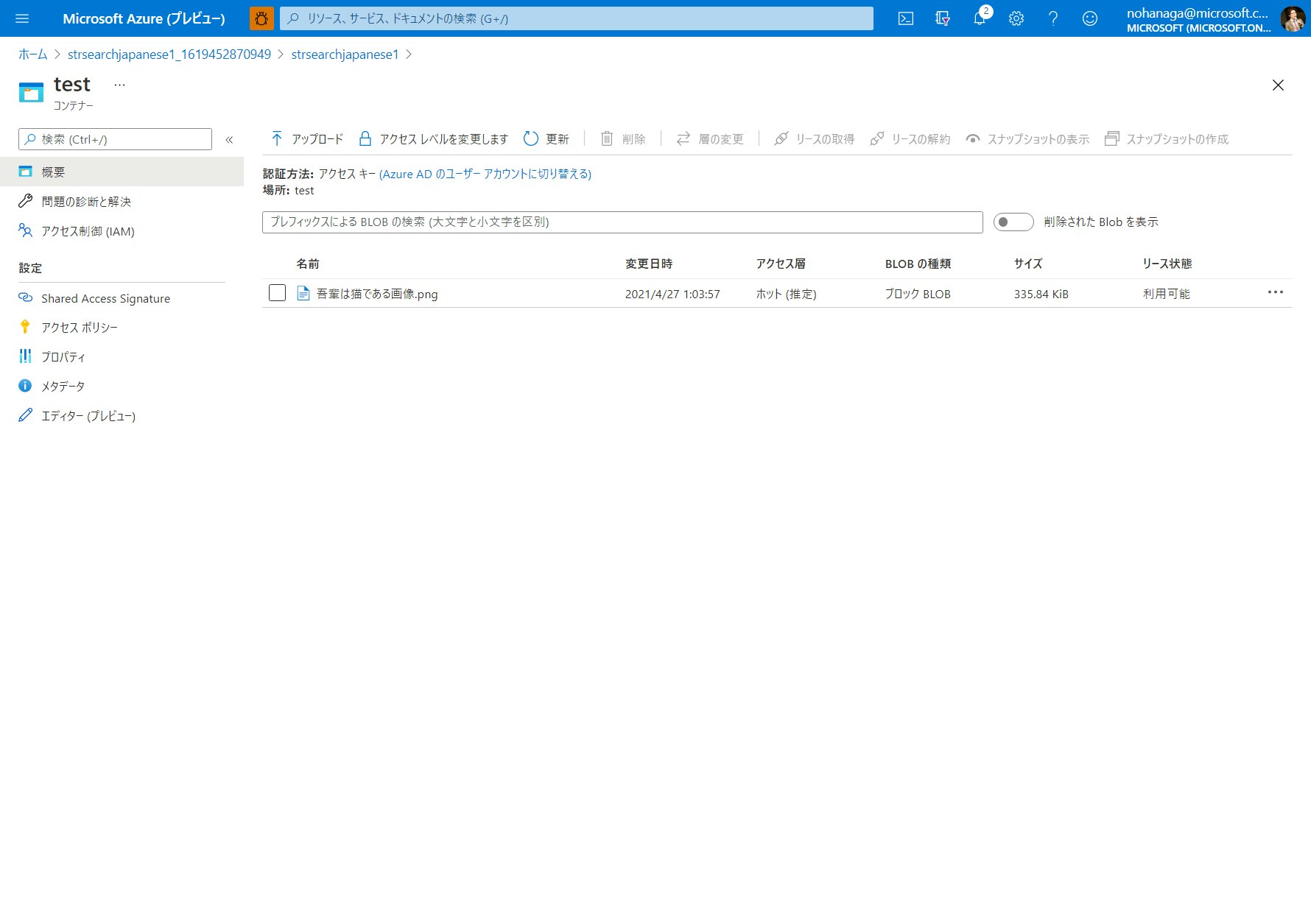
作成したコンテナーの中に入り、サンプル画像ファイルを 1 枚アップロードします。PDF やワード、エクセルなど他にも検索してみたいファイルがある方は、こちらにアップロードしてください。ファイルが大量にある場合は、Azure Storage Explorer を使ってアップロードすることもできます。
サポートしているファイルフォーマットの一覧はこちらを参照してください。

このハンズオンでは、青空文庫の「吾輩は猫である」のスキャン画像を利用します。
インデックスの作成
それでは、先ほど作成した Blob Storage 内を検索するためのインデックスの作成を行います。
1. データに接続

検索サービスのポータルに戻り、ツールバーの「データのインポート」をクリックします。
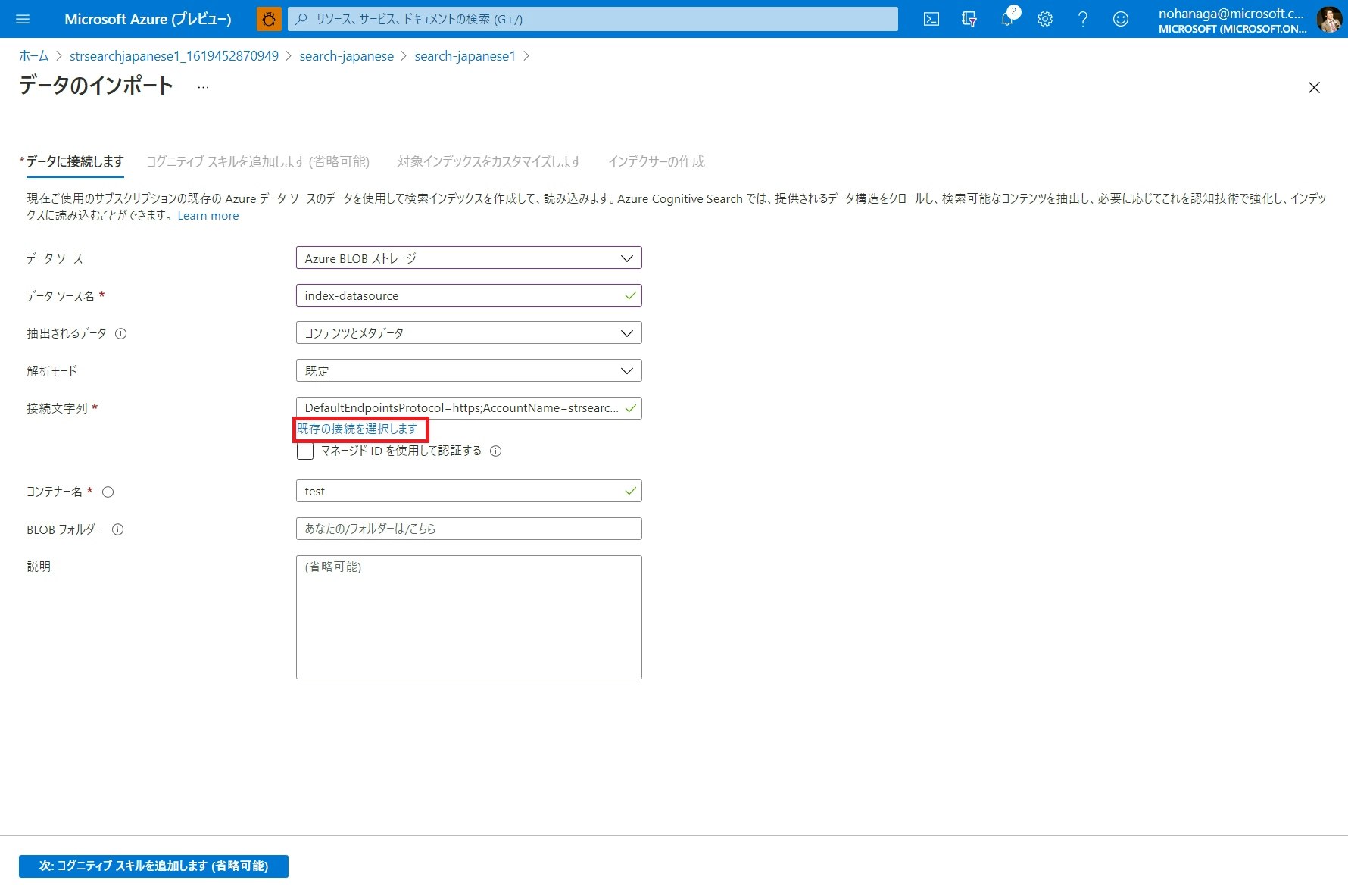
データのインポートウィザードでは、データソースに「Azure BLOB ストレージ」を選択し、データソース名を入力し、「既存の接続を選択します」リンクをクリックします。
ちなみに Azure Cognitive Search が対応しているデータソースには、Azure Cosmos DB や Azure SQL Database などがあり、2021 年 3 月には、SharePoint Online (Preview) にも対応しました。サポートしているデータソースの一覧はこちらにあります。

すると、ストレージアカウント選択画面が開くので、左メニューから、先ほど作成したストレージアカウントを選択し、ファイルが保存されているコンテナーを選択します。
先ほどのデータのインポート画面のコンテナー名に、選択したコンテナーが自動で入力されたことを確認し、「次:コグニティブ スキルを追加します(省略可能)」ボタンをクリックします。
2. コグニティブ スキルの追加
ここでは、検索インデックスをより豊かにするための、AI エンリッチメントを追加できます。AI エンリッチメントでは、Azure Cognitive Services の機能が使われるため、基本的に利用料がかかります。ただし今回はハンズオンですので、「Cognitive Services をアタッチする」では設定を行いません。そうすると自動で無料 (制限付きのエンリッチメント) リソースがセットされます。ただしインデクサーごとに、1 日あたり 20 ドキュメントまでのエンリッチに制限されます。

今回は、上図のようにチェックしてください。サンプル画像から、OCR を使って文字を読み取り、その文字に対して、エンティティの抽出等のテキスト解析を行います。また写真ファイルをアップロードする場合には、画像認識のスキルを有効化しておくことで画像からメタデータを抽出できます。
チェックが完了したら、「次:対象インデックスをカスタマイズします」をクリックします。
3. インデックスのカスタマイズ
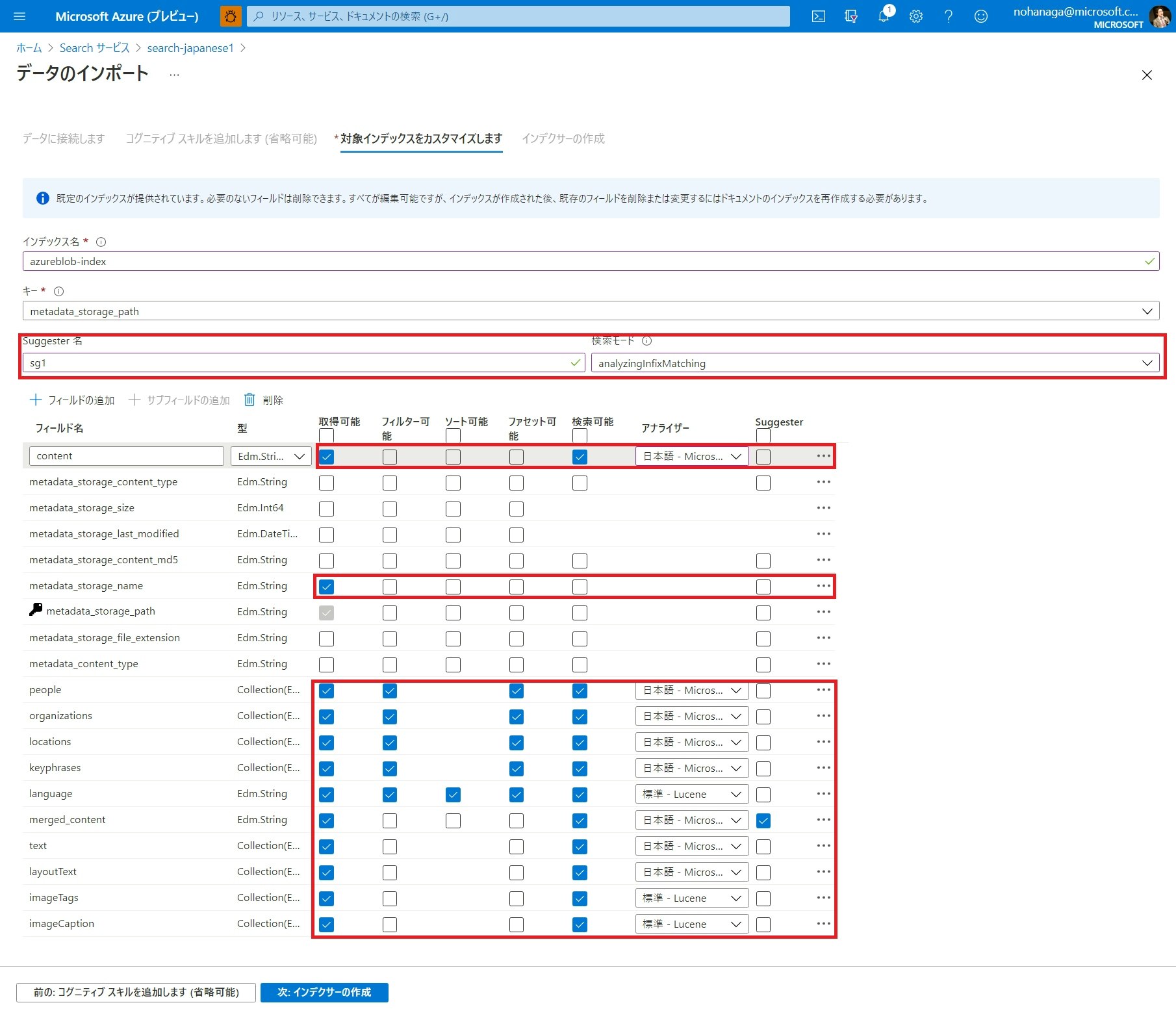
対象インデックスのカスタマイズウィザードでは、検索インデックスとして格納するフィールドごとに、取得可能、フィルター可能、ソート可能、ファセット可能、検索可能、アナライザー、サジェスターという一般的な検索インデックスとしての設定を行う必要があります。各機能の説明は冒頭の動画でするとして、今回は上図のようにチェックしてください。
アナライザーにはデフォルトで、標準 Lucene アナライザーがセットされていますが、これは西洋語用のもので日本語の解析に対応していませんので、日本語の解析が必要なフィールドには、日本語アナライザーを設定する必要があります。日本語のアナライザーには Lucene アナライザーと、Microsoft アナライザーの 2 種類が用意されていますが、それぞれトークナイズの手法に違いがあるので、要件によって選択するようにしてください。
-
content: ドキュメントの本文が格納されます。文字解析可能なドキュメントはここに値が格納されます。中身は日本語として解析される必要があるため、日本語 Microsoft アナライザーをセットします。 -
metadata_storage_name: ドキュメントのファイル名です。今回は検索結果に表示するために、取得可能にチェックします。 -
people: 人物エンティティが格納されます。日本語で解析できるようにします。 -
organizations: 組織エンティティが格納されます。日本語で解析できるようにします。 -
locations: 位置エンティティが格納されます。日本語で解析できるようにします。 -
keyphrases: 重要語が格納されます。日本語で解析できるようにします。 -
language: 言語検出スキルによる言語推定結果が格納されます。ISO 3166-1 alpha-2 の 2 文字の国番号が入るのでアナライザーはデフォルトにしておきます。 -
merged_content: ドキュメントの本文と、OCR による読み取り結果をマージした結果が格納されます。日本語で解析できるようにします。Suggester にチェックをいれることで、このフィールドがオートコンプリートとサジェスト機能対応になります。 -
text: OCR スキルの読み取り結果が格納されます。日本語で解析できるようにします。 -
layoutText: OCR スキル で抽出されたテキストと、そのテキストが検出された座標を記述した配列が格納されます。日本語で解析できるようにします。 -
imageTags: 画像解析して画像のコンテンツに関係する単語の一覧が格納されます。今回は設定省略します。(日本語にも対応しています) -
imageCaption: 画像解析して画像のコンテンツを説明するための文が格納されます。今回は設定省略します。(日本語にも対応しています)
フィールドごとに一つ一つ設定していくのが面倒くさいと思った方はご安心ください。これらの設定はすべて JSON 形式でエクスポートできますので、JSON 形式で編集などをして、Postman を使って REST API 経由でインデックスに登録することができます。こちらは別記事にて紹介いたします。
設定が完了しましたら、「次:インデクサーの作成」をクリックしてください。
4. インデクサーの作成
最後にインデクサーの作成を行います。インデクサーは、外部データソースから検索サービスの検索インデックスにドキュメントとコンテンツを転送するための、自動化されたワークフローを提供します。ここでは、データをプルする頻度をスケジューリングすることや、検索対象のファイルに対する処理の各種設定を行うことができます。

今回は、metadata_storage_path をドキュメントキーとしているため、Base-64 エンコード キー にチェックを入れておきます。
また、スケジュール設定はせず、デフォルトの 1度 にセットしておきます。
設定が完了したら、「送信」ボタンをクリックします。
インデクサーの実行
さきほどインデクサーの実行スケジュールを 1度 にしておいたため、作成直後に自動的に 1 度だけ実行されます。

「インデクサー」タブの対象インデクサーのステータスが 実行中 となっていると思います。これが 成功 となればインデキシング完了です。
インデックスの検索
作成したインデックスの中身は、ポータル上で検索することができます。

「インデックス」タブをクリックし、インデックス名を選択します。

すると検索エクスプローラー画面が表示されます。ここで、検索クエリーのテストや、実行結果の確認をすることができます。
ひとまずクエリ文字列に何も入れずに「検索」ボタンをクリックしてみてください。全件が検索されます。
文字化け?してるんじゃないかというような検索結果が表示されると思います。これは OCR スキル のデフォルト言語設定が英語になっているため、正常に認識されていないことが原因です。
日本語 OCR 機能を利用しない場合は、ここまでの設定で完了です。PDF やワード、エクセルファイルなどの中身が検索できているかと思います。
開発者の方は、アプリケーションから以下のような検索クエリを発行して検索結果を得ます。検索クエリーの発行のしかたは、ドキュメントを参照してください。
POST https://[service name].search.windows.net/indexes/[index-name]/docs/search?api-version=2020-06-30
{
"search": "NY +view",
"queryType": "simple",
"searchMode": "all",
"searchFields": "HotelName, Description, Address/City, Address/StateProvince, Tags",
"select": "HotelName, Description, Address/City, Address/StateProvince, Tags",
"count": "true"
}
スキルセットの修正
OCR スキルを日本語に対応させる場合は一度ポータルに戻り、「スキルセット」タブをクリックし、スキルセット名を選択してください。
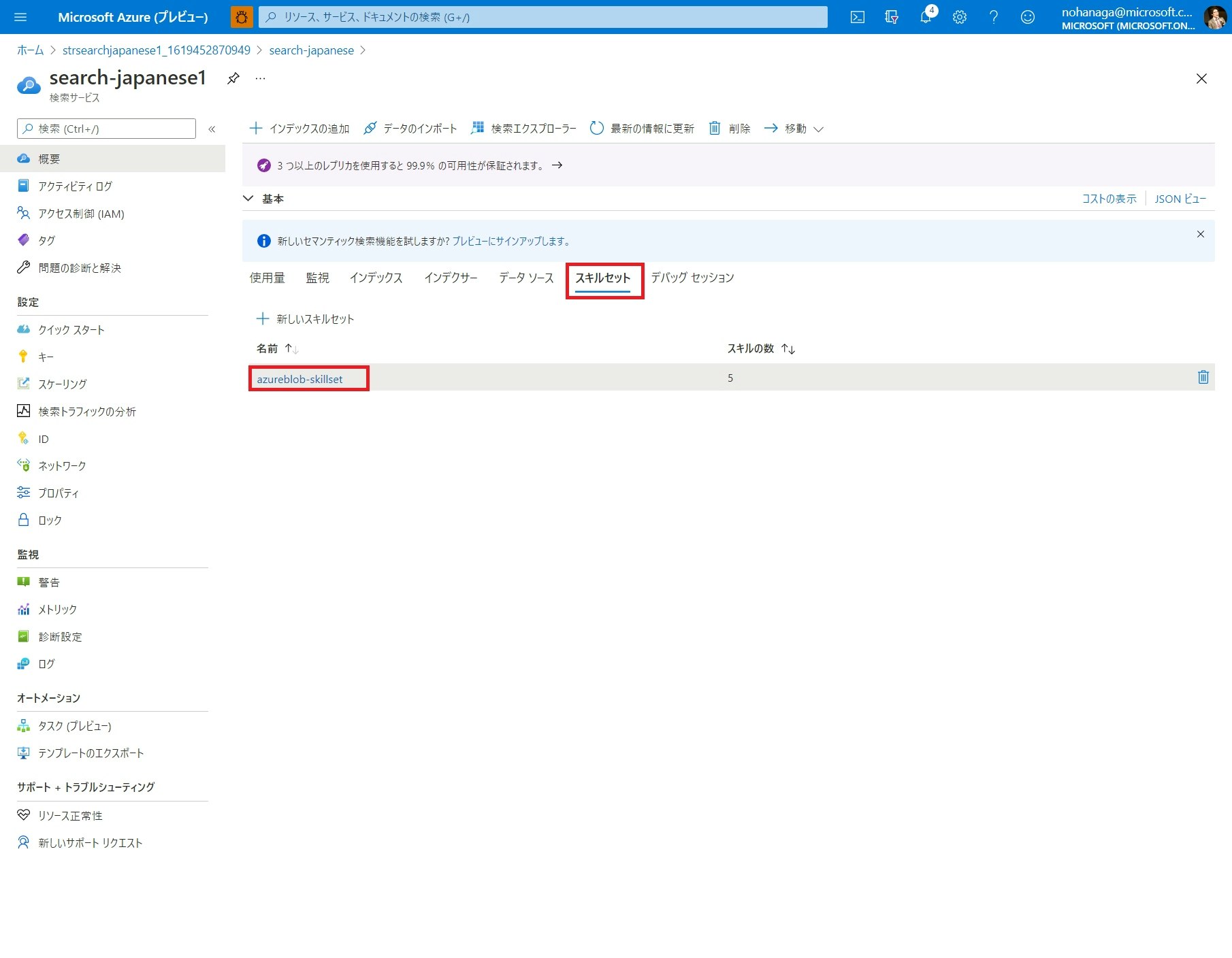
スキルセットは、各スキルの定義とその実行順を JSON 形式で定義したものです。ポータル画面から、閲覧と直接編集を行えます。
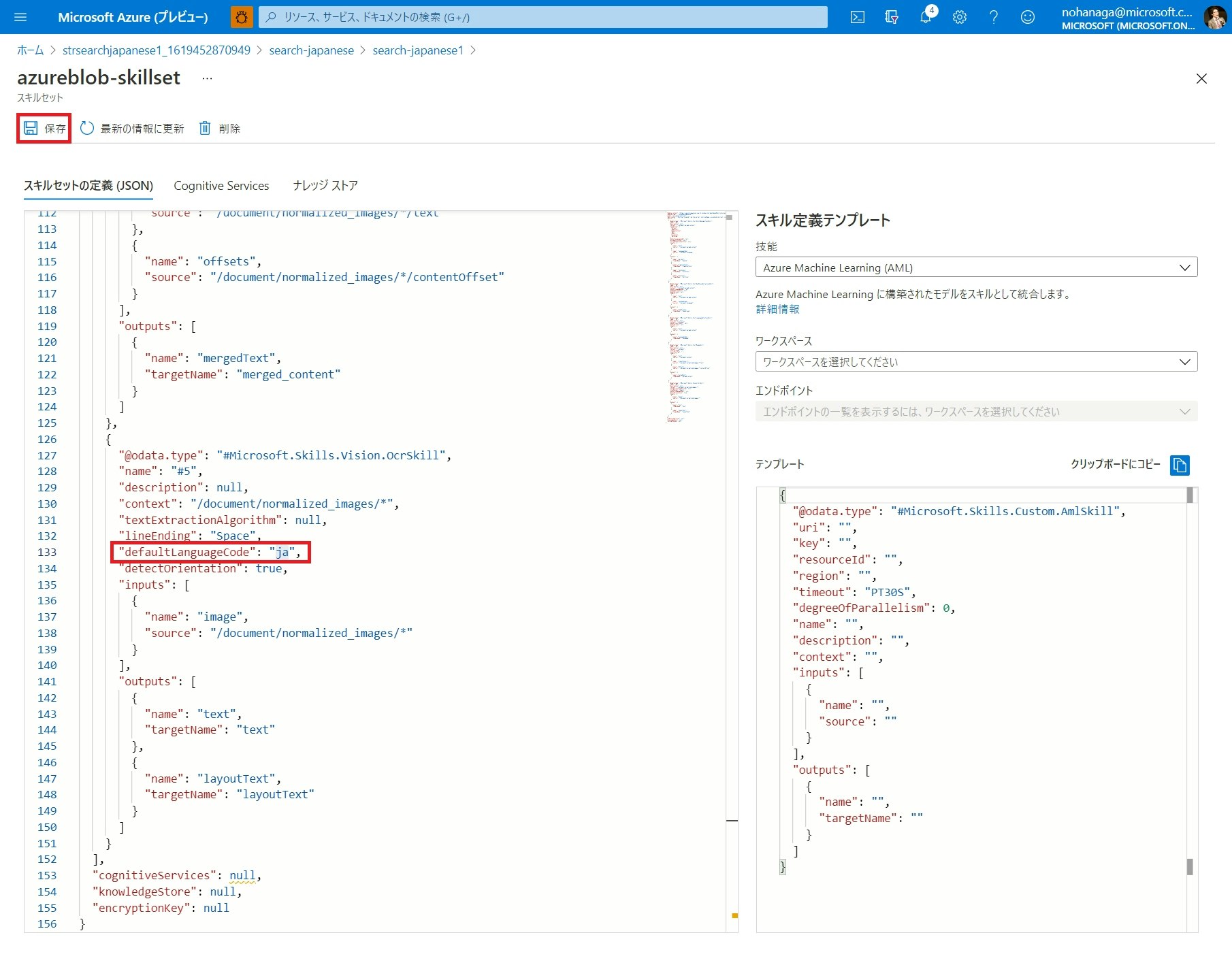
以下のように、#Microsoft.Skills.Vision.OcrSkill の部分の、defaultLanguageCode を ja に変更し、「保存」ボタンをクリックします。もし OCR したいドキュメントの言語がこの時点で不明の場合、unk と設定することで、言語が自動検出されます。
{
"@odata.type": "#Microsoft.Skills.Vision.OcrSkill",
...
"defaultLanguageCode": "ja",
...
}
保存が完了したら、今度はポータルからインデクサーを開き、「リセット」ボタンを押してから「実行」ボタンを押します。
リセットを行うことで、一度インデキシングされたデータをクリアして、再度インデキシングすることができるようになります。
インデックスの検索(日本語 OCR)
インデクサーの実行が成功したら、再度インデックスの検索エクスプローラー画面を開きます。

今度はどうでしょうか?しっかりと merged_content や text フィールドに日本語で検索結果が入っていることが確認できます。
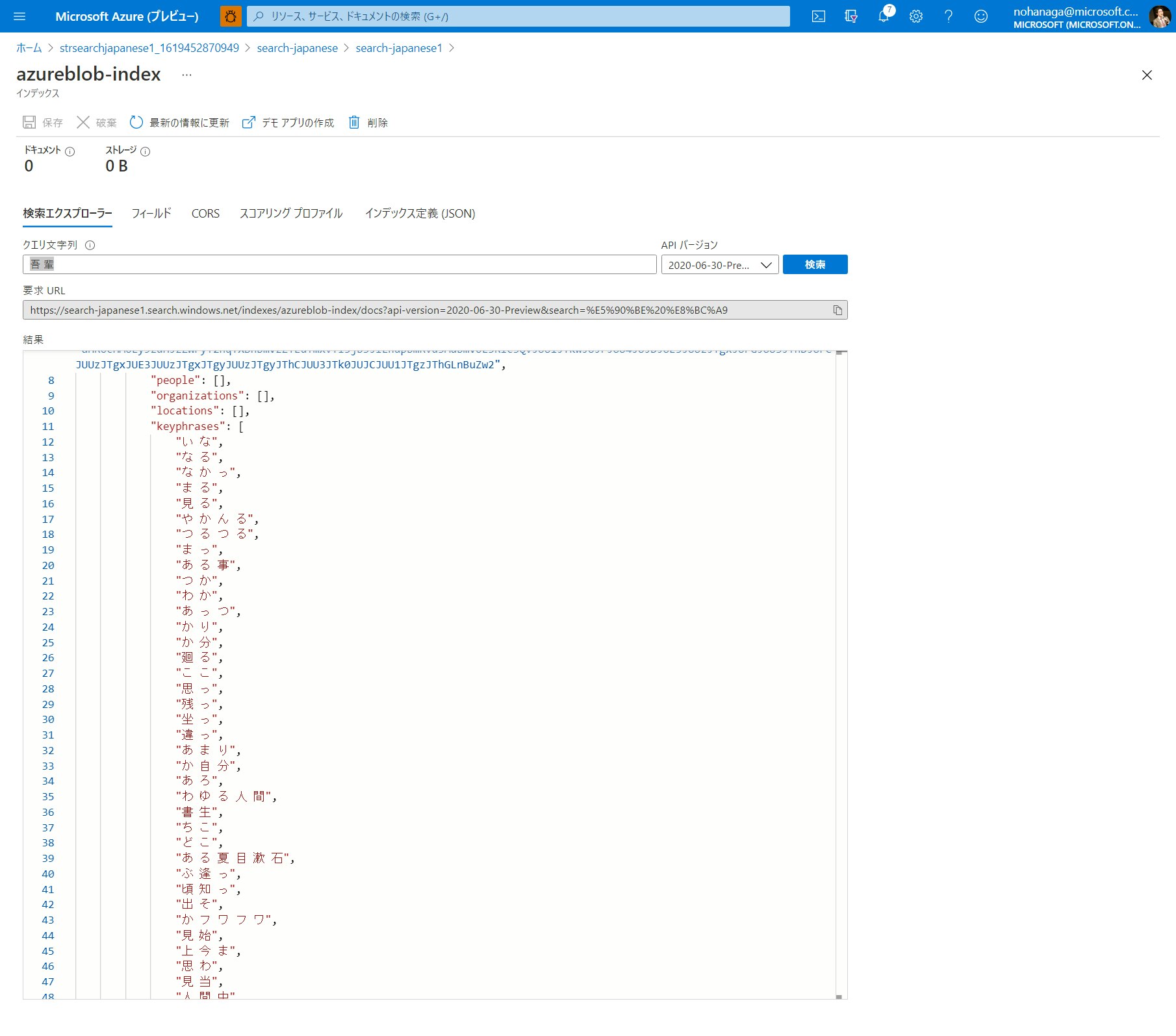
keyphrases フィールドにも単語が入っていることが分かります。
うん、分かるのですが、なんかおかしい。。。
全然日本語じゃないし。。。しかも空白が入ってて、うまく検索できないし。
はい、2021 年 4 月現在、日本語 OCR にはコチラで解説しているような問題があるんです。これを迂回するためのトリックはリンク先にて紹介しているのですが、そこではカスタムスキルという機能を使います。
カスタムスキルというのは Azure Cognitive Search の重要な機能の一つでして、オリジナルの検索インデックスを作るために必要となります。仕組みとして、インデクサーがスキャンしたデータを外部 Web API に飛ばすことができるので、外部にテキスト分類機械学習モデルや要約モデル、画像分類モデルなどをデプロイしておけば、オリジナルの AI エンリッチメントパイプラインを構築することができます。
この後、カスタムスキルを使って上記日本語 OCR 問題を何とかするハンズオンを用意いたします。テキスト処理するだけのめちゃくちゃシンプルな作りなので、カスタムスキルの学習用として有用かと思います。
デモアプリの作成
Azure Cognitive Search の機能は基本的に REST API での提供となりますが、デモのために簡易的な Web 検索フロントエンドを作成してくれる機能があります。検索エクスプローラー画面の上にある「デモ アプリの作成」ボタンをクリックしてください。
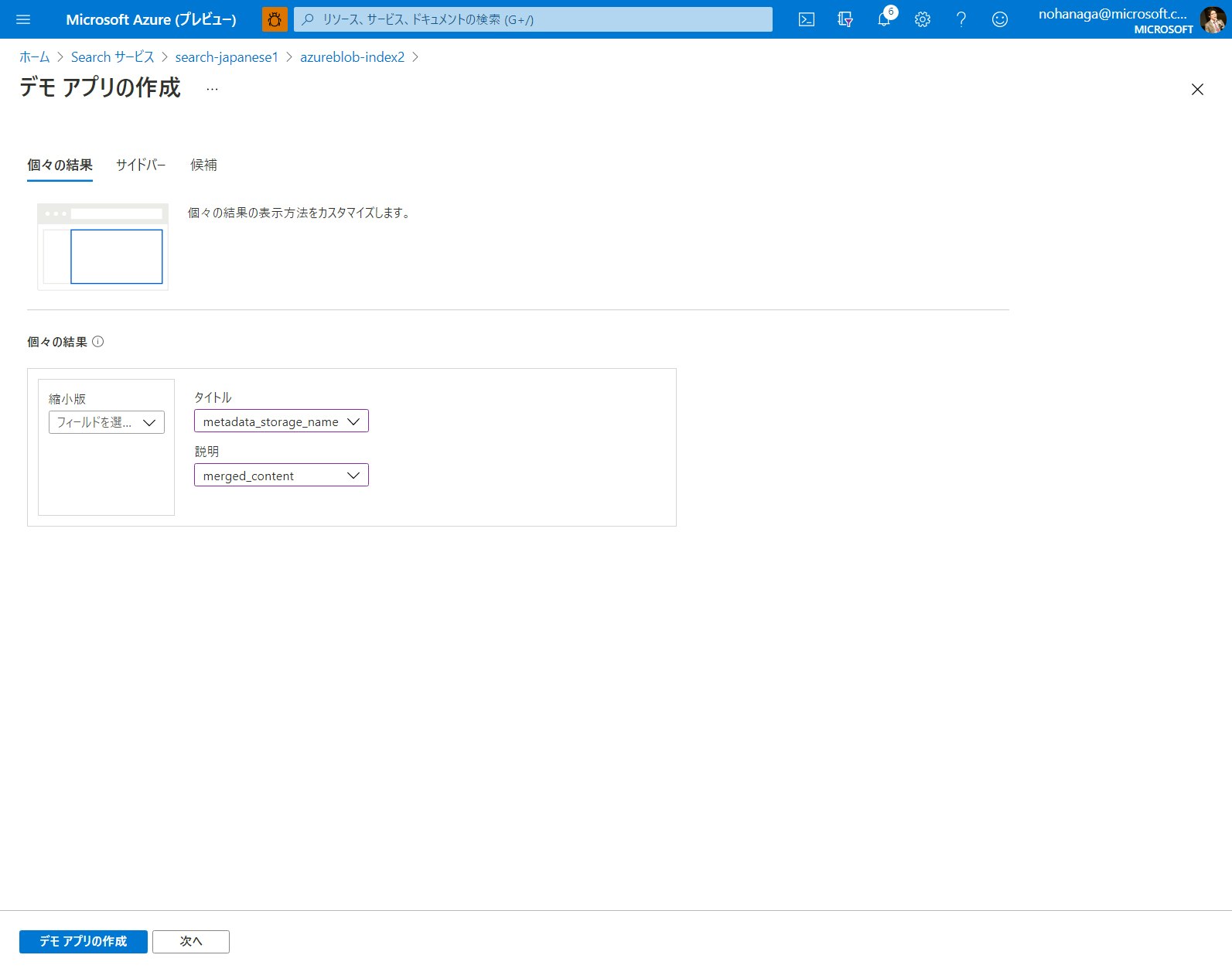
デモ アプリの作成ウィザードでは、検索画面に表示するフィールドの設定を行うことができます。
まずは検索結果画面に表示したいフィールドを選択して「次へ」をクリックします。

サイドバー設定では、検索画面の左側に表示されるフィルター項目を設定することができます。この設定を行えば、ファセットフィルター機能のデモをすることができます。

インデックスのカスタマイズセクションで、Suggester の設定を行っていたので、この画面でサジェスト対象のフィールド merged_content を選択します。
最後に、「デモ アプリの作成」ボタンをクリックすれば、デモ用の HTML ファイルがダウンロードできます。

ローカルでダウンロードした HTML ファイルをブラウザで開き、上部の検索ボックスにキーワードを入れると、このように検索結果が表示されます。簡易的ですが、検索デモとして使うことができます。左ペインは、検索結果に応じて動的に生成されるファセットフィルターです。検索ボックスに何か単語を入力すると、サジェスト機能によるドロップダウンが表示されます。
※注意:HTML ファイル内に接続情報を含んでいるため、このファイルをそのまま運用環境に用いることはできません。
まとめ
以上で、Azure Portal 上で Azure Cognitive Search のインデックス作成から検索までの流れを体験いただきました。
この次は、Postman を使った REST API 経由での作成方法や、デバッグセッション機能を使ったカスタムスキル開発についてご紹介したいと思います。
参考リンク
Azure Cognitive Search のカスタムスキルを作成しよう
Azure Cognitive Search のデバッグセッションを使ってカスタムスキルを追加しよう
Azure Cognitive Search の OCR を日本語環境で使えるようにする Tips
ナレッジマイニング ソリューションアクセラレーター